
प्रोफ़ाइल जीपीयू रेंडरिंग टूल, हर चरण में लगने वाले समय की जानकारी देता है रेंडर करने की प्रोसेस, पिछले फ़्रेम को रेंडर करने के लिए काम करती है. यह ज्ञान उन रुकावटों की पहचान करने में आपकी मदद कर सकता है, यह जान सकता है कि अपने ऐप्लिकेशन की रेंडरिंग परफ़ॉर्मेंस को बेहतर बनाने के लिए क्या ऑप्टिमाइज़ करना है.
इस पेज पर यह जानकारी दी गई है कि पाइपलाइन के हर चरण के दौरान क्या होता है, और उन समस्याओं पर चर्चा करता है जिनकी वजह से रुकावटें पैदा हो सकती हैं. पढ़ने से पहले आपको इस पेज में दी गई जानकारी के बारे में प्रोफ़ाइल का जीपीयू रेंडरिंग. इसके अलावा, सभी चरणों को एक-दूसरे से जोड़ने के तरीके को समझने के लिए, रेंडरिंग पाइपलाइन के काम करने का तरीका क्या है.
विज़ुअल प्रज़ेंटेशन
प्रोफ़ाइल जीपीयू रेंडरिंग टूल, ग्राफ़ का रूप: कलर-कोडेड हिस्टोग्राम. पहली इमेज में डिसप्ले करने की ज़रूरत नहीं.
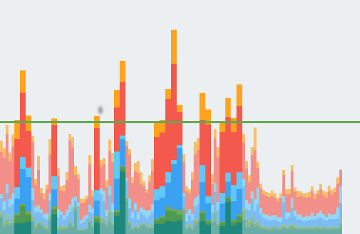
पहला डायग्राम. प्रोफ़ाइल जीपीयू रेंडरिंग ग्राफ़
हर वर्टिकल बार का हर सेगमेंट, प्रोफ़ाइल जीपीयू रेंडरिंग में दिखाया जाता है ग्राफ़, पाइपलाइन के एक चरण को दिखाता है और उसे किसी खास रंग में करके बार ग्राफ़ बनाया जा सकता है. दूसरी इमेज में, दिखाए गए हर रंग के मतलब की कुंजी दिखाई गई है.

दूसरा डायग्राम. प्रोफ़ाइल जीपीयू रेंडरिंग ग्राफ़ लेजेंड
हर रंग का मतलब समझने के बाद, आपके पास अपनी रणनीतियों के खास पहलुओं को टारगेट करने का विकल्प होता है. ऐप्लिकेशन की रेंडरिंग परफ़ॉर्मेंस को ऑप्टिमाइज़ करने की कोशिश की.
स्टेज और उनके मतलब
इस सेक्शन में बताया गया है कि संबंधित चरण में क्या होता है इमेज 2 में दिखाए गए हैं.
इनपुट हैंडलिंग
पाइपलाइन के इनपुट हैंडलिंग स्टेज से पता चलता है कि ऐप्लिकेशन कितनी देर तक काम करता है इनपुट इवेंट को हैंडल करने में खर्च किया जाता है. इस मेट्रिक से पता चलता है कि ऐप्लिकेशन इनपुट इवेंट कॉलबैक से, कोड को एक्ज़ीक्यूट करने पर खर्च किया गया.
जब यह सेगमेंट बड़ा हो
इस क्षेत्र में उच्च मान आमतौर पर बहुत ज़्यादा काम की वजह से होता है या इनपुट-हैंडलर इवेंट कॉलबैक के अंदर होने वाला, बहुत जटिल काम. ये कॉलबैक हमेशा मुख्य थ्रेड पर होते हैं. इसलिए, इसे हल करें काम को सीधे तौर पर ऑप्टिमाइज़ करने पर या काम को दूसरा थ्रेड.
यह बात भी ध्यान में रखें कि
RecyclerView अभी तक किसी भी व्यक्ति ने चेक इन नहीं किया है
इस चरण में स्क्रोलिंग दिख सकती है.
RecyclerView अभी तक किसी भी व्यक्ति ने चेक इन नहीं किया है
टच इवेंट का इस्तेमाल करते ही स्क्रोल करता है. इस वजह से,
इससे आइटम के नए व्यू बढ़ सकते हैं या उनकी जानकारी अपने-आप भर सकती है. इस वजह से, यह ज़रूरी है कि
इस कार्रवाई को जल्द से जल्द करें. प्रोफ़ाइलिंग टूल, जैसे कि Traceview या
Systrace की मदद से आगे की जांच में आपकी मदद की जा सकती है.
ऐनिमेशन
ऐनिमेशन वाले चरण से आपको पता चलता है कि सभी इवेंट का आकलन करने में कितना समय लगा
जो उस फ़्रेम में चल रहे थे. सबसे ज़्यादा इस्तेमाल किए जाने वाले ऐनिमेटर हैं
ObjectAnimator,
ViewPropertyAnimator, और
ट्रांजिशन.
जब यह सेगमेंट बड़ा हो
इस क्षेत्र में ज़्यादा वैल्यू, आम तौर पर उस काम की वजह से होती हैं जिसे लागू किया जा रहा है
की वजह से प्रॉपर्टी में बदलाव हो सकता है. उदाहरण के लिए, फ़्लिंग ऐनिमेशन,
जो आपके ListView को स्क्रोल करता है या
RecyclerView,
की वजह से बड़ी संख्या में व्यू में बढ़ोतरी होती है और लोग बड़ी संख्या में होते हैं.
मेज़रमेंट/लेआउट
Android, स्क्रीन पर आपके व्यू आइटम ड्रॉ कर सके, इसके लिए ज़रूरी है कि आपके व्यू हैरारकी (व्यू और व्यू ग्रुप के लेआउट का क्रम) में, लेआउट और व्यू के लिए दो खास ऑपरेशन.
सबसे पहले, सिस्टम व्यू आइटम का आकलन करता है. हर व्यू और लेआउट में यह स्क्रीन पर मौजूद ऑब्जेक्ट के साइज़ के बारे में जानकारी देता है. कुछ दृश्य इनका कोई खास साइज़ हो सकता है; दूसरों के पास एक साइज़ होता है, जो साइज़ के हिसाब से बदलता है पैरंट लेआउट कंटेनर का
दूसरा, सिस्टम व्यू आइटम लेआउट करता है. सिस्टम हिसाब लगाने के बाद बच्चों को मिले व्यू की संख्या के हिसाब से, सिस्टम अलग-अलग लेआउट और साइज़ और स्क्रीन पर व्यू की जगह तय करना.
सिस्टम, न सिर्फ़ ड्रॉ किए जाने वाले व्यू के लिए, बल्कि माप और लेआउट का भी काम करता है. बल्कि उन व्यू के पैरंट क्रम के लिए भी, सीधे किताब के मूल आंकड़ों तक व्यू.
जब यह सेगमेंट बड़ा हो
अगर आपका ऐप्लिकेशन इस इलाके में एक फ़्रेम के अंदर बहुत ज़्यादा समय बिताता है, तो आम तौर पर, ऐसा व्यू की संख्या में बदलाव होने की वजह से होता है. या समस्याओं को दोहरा टैक्स देना: हैरारकी है. इनमें से किसी भी मामले में, परफ़ॉर्मेंस बेहतर करने में सुधार करना आपके व्यू हैरारकी (व्यू और व्यू ग्रुप के लेआउट का क्रम) की परफ़ॉर्मेंस.
वह कोड जिसमें आपने जोड़ा है
onLayout(boolean, int, int, int, int) या
onMeasure(int, int)
परफ़ॉर्मेंस को बेहतर बनाने
समस्याएं. Traceview और
Systrace की मदद से, जांच की जा सकती है
कॉलस्टैक का इस्तेमाल करके, अपने कोड की समस्याओं का पता लगाएं.
जगह बदलना
ड्रॉ चरण में, व्यू की रेंडरिंग ऑपरेशन को दिखाया जाता है. जैसे- ड्रॉइंग नेटिव ड्रॉइंग कमांड के क्रम में, बैकग्राउंड या ड्रॉइंग टेक्स्ट. सिस्टम इन कमांड को एक डिसप्ले लिस्ट में कैप्चर करता है.
ड्रॉ बार रिकॉर्ड करता है कि कमांड कैप्चर करने में कितना समय लगता है
डिसप्ले सूची में, उन सभी व्यू के लिए जिन्हें स्क्रीन पर अपडेट करने की ज़रूरत है
करें. मापा गया समय, यूज़र इंटरफ़ेस (यूआई) में जोड़े गए किसी भी कोड पर लागू होता है
चीज़ें मौजूद हैं. ऐसे कोड के उदाहरण ये हो सकते हैं:
onDraw(),
dispatchDraw(),
और अलग-अलग draw ()methods
Drawable क्लास.
जब यह सेगमेंट बड़ा हो
आसान शब्दों में कहें, तो इस मेट्रिक को यह समझने में मदद मिलती है कि डेटा इकट्ठा करने में कितना समय लगा
को सभी कॉल चलाने के लिए
onDraw() अभी तक किसी भी व्यक्ति ने चेक इन नहीं किया है
अमान्य ट्रैफ़िक के हर व्यू के लिए. यह
इसमें बच्चों को ड्रॉ के निर्देश भेजने में लगने वाला समय और
ड्रॉ करने लायक चीज़ें भी शामिल की जा सकती हैं. इसी वजह से, जब आपको बार में यह बढ़ोतरी दिखती है,
इसकी वजह यह हो सकती है कि कुछ व्यू अचानक अमान्य हो गए हों. अमान्य करना
इससे व्यू को फिर से जनरेट करना ज़रूरी हो जाता है' सूचियां दिखाएं. इसके अलावा,
लंबे समय में, ऐसे कस्टम व्यू की वजह से हो सकता है जो बहुत ज़्यादा
जटिल लॉजिक को उनकी
onDraw() तरीके.
सिंक करें/अपलोड करें
सिंक और अपलोड मेट्रिक से, ट्रांसफ़र होने में लगने वाले समय का पता चलता है मौजूदा फ़्रेम के दौरान, सीपीयू मेमोरी से जीपीयू मेमोरी तक बिटमैप ऑब्जेक्ट.
अलग-अलग प्रोसेसर के तौर पर, सीपीयू और जीपीयू में अलग-अलग रैम होती है पूरी तरह से प्रोसेस करने के लिए डिज़ाइन किया गया है. जब Android पर बिट मैप बनाया जाता है, तो सिस्टम बिट मैप को जीपीयू मेमोरी में ट्रांसफ़र करता है, इससे पहले कि जीपीयू उसे स्क्रीन. इसके बाद, जीपीयू बिट मैप को कैश मेमोरी में सेव कर देता है, ताकि सिस्टम को डेटा को फिर से ट्रांसफ़र करें. ऐसा तब तक करें, जब तक कि जीपीयू टेक्सचर से टेक्सचर न हटा दिया जाए कैश मेमोरी.
ध्यान दें: Lollipop डिवाइसों पर, यह चरण बैंगनी.
जब यह सेगमेंट बड़ा हो
एक फ़्रेम के लिए सभी संसाधनों को जीपीयू मेमोरी में रखना ज़रूरी है. इसके बाद ही ये संसाधन बनाए जा सकते हैं का इस्तेमाल फ़्रेम बनाने के लिए किया जाता है. इसका मतलब है कि इस मेट्रिक के लिए ज़्यादा वैल्यू देने का मतलब बहुत सारे छोटे संसाधन लोड होते हैं या बहुत कम संसाधन. एक सामान्य स्थिति तब होती है जब कोई एप्लिकेशन एक ऐसा बिट मैप दिखाता है जो स्क्रीन के साइज़ के करीब ले जाते हैं. दूसरा मामला यह है कि जब कोई ऐप्लिकेशन किसी बहुत ज़्यादा थंबनेल हो.
इस बार को छोटा करने के लिए, आप इन तकनीकों का इस्तेमाल कर सकते हैं:
- यह पक्का करना कि आपके बिट मैप रिज़ॉल्यूशन, उनके साइज़ से ज़्यादा बड़े न हों के उदाहरण दिखाए जाएंगे. उदाहरण के लिए, आपके ऐप्लिकेशन को 1024x1024 नहीं दिखाना चाहिए 48x48 वाली इमेज.
-
prepareToDraw()का फ़ायदा लिया जा रहा है का इस्तेमाल करें.
समस्या से जुड़े निर्देश
समस्या से जुड़े निर्देश सेगमेंट में, सभी रिपोर्ट जारी करने में लगने वाले समय के बारे में बताया जाता है कमांड देता है.
सिस्टम को डिसप्ले सूचियां बनाने के लिए, स्क्रीन पर के लिए ज़रूरी कमांड देते हैं. आम तौर पर, यह OpenGL ES एपीआई.
इस प्रोसेस में कुछ समय लगता है, क्योंकि सिस्टम आखिरी बदलाव करता है और जीपीयू को निर्देश भेजने से पहले, हर कमांड को क्लिप करें. अन्य जानकारी फिर जीपीयू साइड पर दिखता है, जो आखिरी निर्देशों की गिनती करता है. ये कमांड में आखिरी बदलाव और अतिरिक्त क्लिपिंग शामिल हैं.
जब यह सेगमेंट बड़ा हो
इस चरण में लगने वाला समय, प्रॉडक्ट की जटिलता और उसे इस्तेमाल करने में आने वाली दिक्कतों को डिसप्ले सूचियों की संख्या जिन्हें सिस्टम किसी दिए गए फ़ॉर्मैट में रेंडर करता है फ़्रेम. उदाहरण के लिए, ड्रॉ के कई काम करना, खास तौर पर उन मामलों में जहां हर शुरुआती ड्रॉ की लागत थोड़ी कम होती है. इसलिए, इस बार यह कीमत बढ़ सकती है. उदाहरण के लिए:
Kotlin
for (i in 0 until 1000) { canvas.drawPoint() }
Java
for (int i = 0; i < 1000; i++) { canvas.drawPoint() }
जारी करने की तुलना में बहुत महंगा होता है:
Kotlin
canvas.drawPoints(thousandPointArray)
Java
canvas.drawPoints(thousandPointArray);
जारी करने वाले निर्देशों और डिसप्ले सूचियां बना रहे हैं. समस्या से जुड़े निर्देशों के उलट, इसकी मदद से, जीपीयू को ड्रॉइंग के निर्देश भेजने में लगने वाला समय कैप्चर किया जाता है. ड्रॉ मेट्रिक से पता चलता है कि जारी किए गए दस्तावेज़ को कैप्चर करने में कितना समय लगा निर्देशों को डिसप्ले सूची में शामिल करें.
यह अंतर इसलिए दिखता है, क्योंकि डिसप्ले सूचियों को कैश मेमोरी में सेव किया जाता है लागू कर सकते हैं. इस वजह से, कुछ मामलों में या ऐनिमेशन अपलोड करने के लिए, सिस्टम को डिसप्ले फिर से भेजना पड़ता है सूची बनाएं, लेकिन असल में इसे फिर से बनाने की ज़रूरत नहीं है—ड्रॉइंग को फिर से कैप्चर करें शुरुआत से. इस वजह से, आपको बड़ी संख्या में “समस्या निर्देश” बार देख सकते हैं, लेकिन आपको निर्देश बनाएं बार नहीं दिखेगा.
बफ़र को प्रोसेस करें/स्वैप करें
जब Android, जीपीयू पर डिसप्ले की सभी सूची सबमिट कर देता है, सिस्टम एक अंतिम आदेश जारी करके ग्राफ़िक्स ड्राइवर को यह बताता है कि यह मौजूदा फ़्रेम के साथ किया जाता है. इसके बाद, ड्राइवर आपकी स्क्रीन शेयर कर सकता है अपडेट की गई इमेज को स्क्रीन पर दिखाता है.
जब यह सेगमेंट बड़ा हो
यह समझना ज़रूरी है कि जीपीयू, सीपीयू. Android सिस्टम की समस्याएं, जीपीयू के लिए निर्देश बनाती हैं और फिर, ऐंबियंट डिसप्ले के साथ काम करती हैं अगले टास्क पर जाएं. जीपीयू, सूची में मौजूद ड्रॉ के निर्देशों को पढ़ता है और प्रोसेस करता है उन्हें.
ऐसी स्थितियों में, जहां सीपीयू के निर्देश जीपीयू से ज़्यादा तेज़ काम करते हैं उनका इस्तेमाल करता है, तो प्रोसेसर के बीच संचार सूची बन सकती है भर गया है. ऐसा होने पर सीपीयू ब्लॉक हो जाता है और तब तक इंतज़ार करता है, जब तक कि अगला निर्देश देने के लिए क़तार. पूरी सूची बनाने की यह स्थिति अक्सर बफ़र स्वैप करना स्टेज की वजह से हो सकता है कि उस समय, एक पूरे फ़्रेम की आदेश सबमिट कर दिए गए हैं.
इस समस्या को कम करने के लिए मुख्य बात यह है कि काम में आने वाली जटिलता को कम करना ठीक उसी तरह जैसा आप “समस्या से जुड़े निर्देश” के लिए करते हैं फ़ेज़.
अन्य चीज़ें
रेंडरिंग सिस्टम को अपना काम करने में लगने वाले समय के अलावा, काम का एक और सेट मुख्य थ्रेड पर होता है और उसमें रेंडरिंग से कोई लेना-देना नहीं है. इस काम में लगने वाला समय इस रूप में रिपोर्ट किया जाता है विविध समय. आम तौर पर, दूसरे कामों में लगने वाला समय, होने वाले काम के बारे में बताता है यूज़र इंटरफ़ेस (यूआई) थ्रेड पर, रेंडरिंग के लगातार दो फ़्रेम के बीच.
जब यह सेगमेंट बड़ा हो
अगर यह वैल्यू ज़्यादा है, तो हो सकता है कि आपके ऐप्लिकेशन में कॉलबैक, इंटेंट या किया जा सकता है जो किसी दूसरे थ्रेड पर होने चाहिए. ऐसे टूल तरीका ट्रेसिंग या Systrace की मदद से दी जा सकती है चल रहे टास्क को देखने की सुविधा मुख्य थ्रेड. इस जानकारी की मदद से, परफ़ॉर्मेंस को बेहतर बनाया जा सकता है.