
Android Neural Networks API(NNAPI)는 Android 기기에서의 머신러닝을 위해 계산 집약적인 연산을 실행하도록 설계된 Android C API입니다. NNAPI는 신경망을 빌드하고 학습시키는 더 높은 수준의 머신러닝 프레임워크(예: TensorFlow Lite, Caffe2 등)에 필요한 기본 기능 레이어를 제공하도록 설계되었습니다. 이 API는 Android 8.1 (API 수준 27) 이상을 실행하는 모든 Android 기기에서 사용할 수 있지만 Android 15에서 지원 중단되었습니다.
추론을 지원하기 위해 NNAPI는 Android 기기의 데이터를 이전에 학습된 개발자 정의 모델에 적용합니다. 추론의 예로는 이미지 분류, 사용자 동작 예측, 검색어에 대한 적절한 응답 선택 등이 포함됩니다.
온디바이스 추론은 다음과 같은 여러 이점이 있습니다.
- 지연 시간: 네트워크 연결을 통해 요청을 보내고 응답을 기다릴 필요가 없습니다. 이는 예를 들어 카메라로부터 들어오는 연속적인 프레임을 처리하는 동영상 애플리케이션에 매우 중요할 수 있습니다.
- 가용성: 네트워크 범위를 벗어나더라도 애플리케이션이 실행됩니다.
- 속도: 신경망 처리에 특별히 사용되는 새로운 하드웨어는 범용 CPU만 사용하는 것보다 훨씬 더 빠른 계산 성능을 제공합니다.
- 개인정보 보호: Android 기기에서 데이터가 유출되지 않습니다.
- 비용: 모든 계산이 Android 기기에서 실행되므로 서버 팜이 필요하지 않습니다.
또한 개발자는 다음과 같은 단점을 명심해야 합니다.
- 시스템 활용: 신경망을 평가하는 과정에서 수많은 계산이 실행되므로 배터리 전원 사용량이 늘어날 수 있습니다. 특히 장시간 실행되는 연산의 경우 앱에 문제가 된다면 배터리 상태 모니터링을 고려해야 합니다.
- 애플리케이션 크기: 모델의 크기에 주의를 기울이세요. 모델은 수 메가바이트의 공간을 차지할 수도 있습니다. APK에 대형 모델을 번들로 묶으면 사용자에게 악영향을 주는 경우 앱 설치 후에 모델을 다운로드하거나 더 작은 모델을 사용하거나 클라우드에서 연산을 실행하도록 고려할 수 있습니다. NNAPI는 클라우드에서 모델을 실행하는 데 필요한 기능은 제공하지 않습니다.
NNAPI를 사용하는 방법의 한 가지 예는 Android Neural Networks API 샘플을 참고하세요.
Neural Networks API 런타임 이해
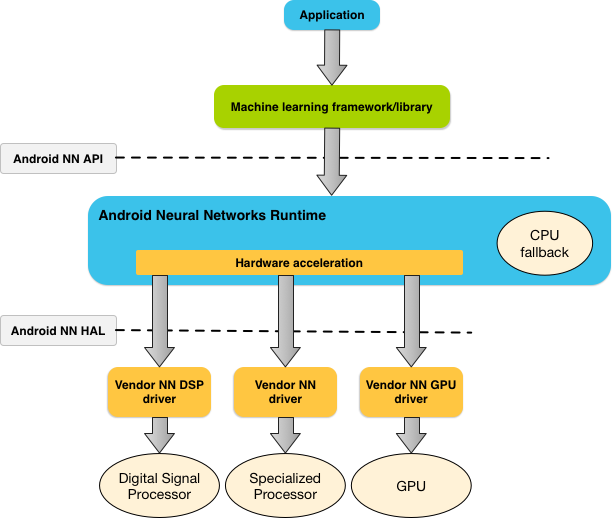
NNAPI는 머신러닝 라이브러리, 프레임워크 및 도구에 의해 호출되며 개발자는 이들을 이용해 기기를 벗어나 모델을 학습시키고 Android 기기에 배포할 수 있습니다. 일반적으로 앱은 NNAPI를 직접 사용하지 않는 대신 더 상위 수준의 머신러닝 프레임워크를 사용합니다. 이 프레임워크는 NNAPI를 사용하여 지원되는 기기에서 하드웨어 가속 추론 연산을 실행할 수 있습니다.
앱의 요구사항과 Android 기기의 하드웨어 성능에 따라 Android의 신경망 런타임은 전용 신경망 하드웨어, 그래픽 처리 장치(GPU), 디지털 신호 프로세서(DSP) 등의 사용 가능한 온디바이스 프로세서에 계산 워크로드를 효율적으로 분산시킬 수 있습니다.
전문 공급업체 드라이버가 없는 Android 기기의 경우 NNAPI 런타임이 CPU에서 요청을 실행합니다.
그림 1은 NNAPI의 개략적인 시스템 아키텍처를 나타냅니다.
Neural Networks API 프로그래밍 모델
NNAPI를 사용하여 계산하려면 먼저 실행할 계산을 정의하는 방향 그래프를 만들어야 합니다. 이 계산 그래프는 입력 데이터(예: 머신러닝 프레임워크로부터 전달된 가중치 및 편향)와 함께 결합되어 NNAPI 런타임 평가를 위한 모델을 구성합니다.
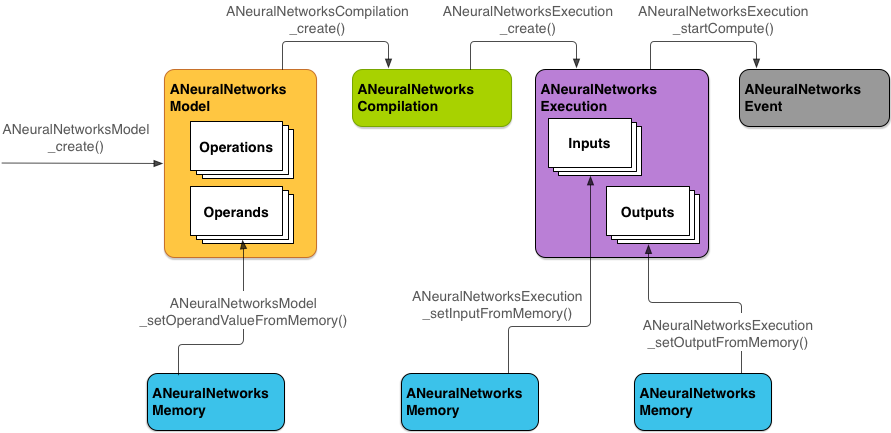
NNAPI는 다음 4가지 주요 추상화를 사용합니다.
- 모델: 학습 프로세스를 통해 학습된 수학 연산과 상수 값의 계산 그래프입니다. 이 연산은 신경망에만 적용됩니다. 이러한 연산에는 2차원(2D) 컨볼루션, 로지스틱(시그모이드) 활성화, ReLU(Rectified Linear Unit) 활성화 등이 포함됩니다. 모델 생성은 동기 작업입니다.
성공적으로 생성된 모델은 스레드와 컴파일에서 재사용될 수 있습니다.
NNAPI에서는 모델이
ANeuralNetworksModel인스턴스로 나타납니다. - 컴파일: NNAPI 모델을 하위 수준의 코드로 컴파일하기 위한 구성을 나타냅니다. 컴파일 생성은 동기 작업입니다. 성공적으로 생성된 컴파일은 스레드와 실행에서 재사용될 수 있습니다. NNAPI에서는 각 컴파일이
ANeuralNetworksCompilation인스턴스로 나타납니다. - 메모리: 공유 메모리, 메모리 매핑 파일 및 유사한 메모리 버퍼를 나타냅니다. 메모리 버퍼를 사용할 경우 NNAPI 런타임이 데이터를 더 효율적으로 드라이버에 전송할 수 있습니다. 일반적으로 앱은 모델을 정의하는 데 필요한 모든 텐서가 포함된 하나의 공유 메모리 버퍼를 만듭니다. 또한 메모리 버퍼를 사용하여 실행 인스턴스의 입력과 출력을 저장할 수도 있습니다. NNAPI에서는 각 메모리 버퍼가
ANeuralNetworksMemory인스턴스로 나타납니다. 실행: NNAPI 모델을 특정 입력 세트에 적용하고 결과를 수집하기 위한 인터페이스입니다. 실행은 동기식 또는 비동기식으로 이루어질 수 있습니다.
비동기식 실행의 경우 동일한 실행에서 여러 스레드가 대기할 수 있습니다. 이 실행이 완료되면 모든 스레드가 해제됩니다.
NNAPI에서는 각 실행이
ANeuralNetworksExecution인스턴스로 나타납니다.
그림 2는 기본적인 프로그래밍 흐름을 나타냅니다.
이 섹션의 나머지 부분에서는 계산을 실행하고 모델을 컴파일하고 컴파일된 모델을 실행하도록 NNAPI 모델을 설정하는 단계에 관해 설명합니다.
학습 데이터에 액세스
학습된 가중치 및 편향 데이터는 대개 파일에 저장됩니다. NNAPI 런타임이 이 데이터에 효율적으로 액세스하도록 하려면 ANeuralNetworksMemory_createFromFd() 함수를 호출하고 열린 데이터 파일의 파일 설명자에 전달하여 ANeuralNetworksMemory 인스턴스를 만듭니다. 또한 파일에서 공유 메모리 영역이 시작되는 오프셋과 메모리 보호 플래그를 지정할 수도 있습니다.
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
이 예에서는 모든 가중치에 하나의 ANeuralNetworksMemory 인스턴스만 사용하지만 여러 파일에 ANeuralNetworksMemory 인스턴스 둘 이상을 사용할 수도 있습니다.
네이티브 하드웨어 버퍼 사용
모델 입력, 출력 및 상수 피연산자 값에 네이티브 하드웨어 버퍼를 사용할 수 있습니다. 경우에 따라 드라이버가 데이터를 복사할 필요 없이 NNAPI 액셀러레이터가 AHardwareBuffer 객체에 액세스할 수 있습니다. AHardwareBuffer에는 다양한 구성이 있으며 모든 NNAPI 액셀러레이터가 이러한 구성을 모두 지원하지는 않습니다. 이러한 제한이 있으므로 ANeuralNetworksMemory_createFromAHardwareBuffer 참조 문서에 나열된 제약 조건을 참조하고 기기 할당을 통해 액셀러레이터를 지정하고 대상 기기에서 미리 테스트하여 AHardwareBuffer를 사용하는 컴파일 및 실행이 예상대로 작동하는지 확인하세요.
NNAPI 런타임이 AHardwareBuffer 객체에 액세스하도록 하려면 ANeuralNetworksMemory_createFromAHardwareBuffer 함수를 호출하고 AHardwareBuffer 객체에 전달하여 ANeuralNetworksMemory 인스턴스를 만듭니다. 다음 코드 샘플을 참조하세요.
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
NNAPI가 더 이상 AHardwareBuffer 객체에 액세스할 필요가 없으면 해당하는 ANeuralNetworksMemory 인스턴스를 해제합니다.
ANeuralNetworksMemory_free(mem2);
참고:
AHardwareBuffer는 전체 버퍼에만 사용할 수 있으며ARect매개변수와 함께 사용할 수 없습니다.- NNAPI 런타임은 버퍼를 플러시하지 않습니다. 실행을 예약하기 전에 입력 및 출력 버퍼에 액세스할 수 있는지 확인해야 합니다.
- 동기화 펜스 파일 설명자를 지원하지 않습니다.
- 공급업체별 형식 및 사용 비트가 있는
AHardwareBuffer의 경우 공급업체 구현에 따라 클라이언트 또는 드라이버가 캐시를 플러시하는지 여부가 결정됩니다.
모델
모델은 NNAPI에서 계산의 기본 단위입니다. 각 모델은 하나 이상의 피연산자와 연산으로 정의됩니다.
피연산자
피연산자는 그래프를 정의할 때 사용되는 데이터 객체입니다. 피연산자에는 모델의 입력과 출력, 한 연산에서 다른 연산으로의 데이터 흐름을 포함하는 중간 노드 그리고 이들 연산으로 전달되는 상수가 포함됩니다.
NNAPI 모델에 추가될 수 있는 피연산자의 두 가지 유형은 스칼라와 텐서입니다.
스칼라는 단일 값을 나타냅니다. NNAPI는 부울, 16비트 부동 소수점 형식, 32비트 부동 소수점 형식, 32비트 정수 형식 및 부호 없는 32비트 정수 형식으로 스칼라 값을 지원합니다.
대부분의 NNAPI 연산에는 텐서가 관련됩니다. 텐서는 N차원 배열입니다. NNAPI는 16비트 부동 소수점 값, 32비트 부동 소수점 값, 8비트 양자화 값, 16비트 양자화 값, 32비트 정수 값 및 8비트 부울 값으로 텐서를 지원합니다.
예를 들어 그림 3은 덧셈 다음에 곱셈이 나오는 2개의 연산이 있는 모델을 나타냅니다. 이 모델은 하나의 입력 텐서를 취하고 하나의 출력 텐서를 생성합니다.
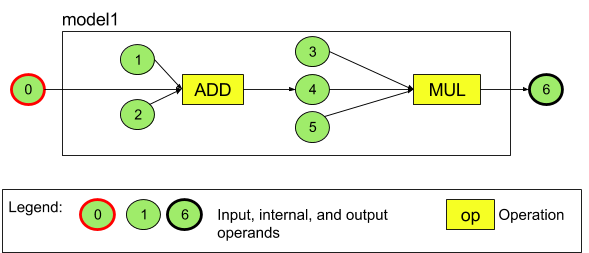
위 모델에는 7개의 피연산자가 있습니다. 이들 피연산자는 모델에 추가되는 순서 색인에 따라 암시적으로 식별됩니다. 추가되는 첫 번째 피연산자의 색인은 0, 두 번째의 색인은 1이 되는 식입니다. 피연산자 1, 2, 3, 5는 상수 피연산자입니다.
피연산자가 추가되는 순서는 중요하지 않습니다. 예를 들어 모델 출력 피연산자를 첫 번째 피연산자로 추가할 수 있습니다. 중요한 점은 피연산자를 참조할 때 올바른 색인 값을 사용하는 것입니다.
피연산자에는 유형이 있습니다. 유형은 피연산자가 모델에 추가될 때 지정됩니다.
하나의 피연산자를 모델의 입력과 출력에 동시에 사용할 수 없습니다.
모든 피연산자는 모델 입력, 상수 또는 정확히 한 연산의 출력 피연산자여야 합니다.
피연산자 사용에 관한 자세한 내용은 피연산자에 관해 자세히 알아보기를 참조하세요.
연산
연산은 실행하려는 계산을 지정합니다. 각 연산은 다음과 같은 요소로 구성됩니다.
- 연산 유형(예: 덧셈, 곱셈, 컨볼루션)
- 연산이 입력에 사용하는 피연산자의 색인 목록
- 연산이 출력에 사용하는 피연산자의 색인 목록
이러한 목록에서는 요소의 순서가 중요합니다. 각 연산 유형의 예상 입력 및 출력은 NNAPI API 참조를 확인하세요.
어떤 연산을 추가하기 전에 먼저 이 연산이 사용하거나 생성하는 피연산자를 모델에 추가해야 합니다.
연산을 추가하는 순서는 중요하지 않습니다. 연산이 실행되는 순서를 파악하기 위해 NNAPI는 연산과 피연산자의 계산 그래프에 의해 구성된 종속 항목을 사용합니다.
아래 표에 NNAPI가 지원하는 연산이 요약되어 있습니다.
API 수준 28의 알려진 문제: ANEURALNETWORKS_TENSOR_QUANT8_ASYMM 텐서를 Android 9(API 수준 28) 이상에서 사용 가능한 ANEURALNETWORKS_PAD 연산으로 전달할 때 NNAPI의 출력이 TensorFlow Lite와 같이 더 높은 수준의 머신러닝 프레임워크의 출력과 일치하지 않을 수 있습니다. 대신 ANEURALNETWORKS_TENSOR_FLOAT32만 전달해야 합니다.
이 문제는 Android 10(API 수준 29) 이상에서 해결되었습니다.
모델 빌드
다음 예에서는 그림 3에 있는 2연산 모델을 만듭니다.
모델을 빌드하려면 다음 단계를 따르세요.
ANeuralNetworksModel_create()함수를 호출하여 빈 모델을 정의합니다.ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
ANeuralNetworks_addOperand()를 호출하여 피연산자를 모델에 추가합니다. 피연산자의 데이터 유형은ANeuralNetworksOperandType데이터 구조를 사용하여 정의됩니다.// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6앱이 학습 프로세스에서 가져온 가중치 및 편향과 같은 상수 값이 있는 피연산자의 경우
ANeuralNetworksModel_setOperandValue()및ANeuralNetworksModel_setOperandValueFromMemory()함수를 사용합니다.다음 예에서는 학습 데이터에 액세스에서 만든 메모리 버퍼에 상응하는 학습 데이터 파일로부터 상수 값을 설정합니다.
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));방향 그래프에서 계산하려는 각 연산에 관해
ANeuralNetworksModel_addOperation()함수를 호출하여 연산을 모델에 추가합니다.앱에서 이 호출의 매개변수로 다음과 같은 항목을 제공해야 합니다.
- 연산 유형
- 입력 값의 카운트
- 입력 피연산자의 색인 배열
- 출력 값의 카운트
- 출력 피연산자의 색인 배열
참고로 하나의 피연산자를 동일 연산의 입력과 출력 모두에 사용할 수는 없습니다.
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);ANeuralNetworksModel_identifyInputsAndOutputs()함수를 호출하여 모델이 입력 및 출력으로 처리해야 할 피연산자를 식별합니다.// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
선택적으로
ANeuralNetworksModel_relaxComputationFloat32toFloat16()을 호출하여 IEEE 754 16비트 부동 소수점 형식만큼 낮은 범위나 정밀도로ANEURALNETWORKS_TENSOR_FLOAT32를 계산할 수 있는지 지정합니다.ANeuralNetworksModel_finish()를 호출하여 모델 정의를 마무리합니다. 오류가 없는 경우 이 함수는ANEURALNETWORKS_NO_ERROR의 결과 코드를 반환합니다.ANeuralNetworksModel_finish(model);
모델을 만든 후에는 횟수에 제한 없이 모델을 컴파일할 수 있고 횟수에 제한 없이 각 컴파일을 실행할 수 있습니다.
제어 흐름
NNAPI 모델에 제어 흐름을 통합하려면 다음을 실행하세요.
상응하는 실행 하위 그래프(
IF문의then및else하위 그래프,WHILE루프의condition및body하위 그래프)를 독립형ANeuralNetworksModel*모델로 구성합니다.ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
제어 흐름이 포함된 모델 내에서 이러한 모델을 참조하는 피연산자를 만듭니다.
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
제어 흐름 작업을 추가합니다.
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
컴파일
컴파일 단계에서는 모델이 실행될 프로세서를 판단하고 상응하는 드라이버에 모델 실행을 준비하도록 요청합니다. 이 단계에는 모델이 실행될 프로세서에 특정한 기계어 코드 생성이 포함될 수 있습니다.
모델을 컴파일하려면 다음 단계를 따르세요.
ANeuralNetworksCompilation_create()함수를 호출하여 새 컴파일 인스턴스를 만듭니다.// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
선택적으로 기기 할당을 사용하여 실행할 기기를 명시적으로 선택할 수 있습니다.
선택적으로 런타임이 배터리 전원 사용량과 실행 속도 간에 절충하는 방식에 영향을 줄 수 있습니다. 그러려면
ANeuralNetworksCompilation_setPreference()를 호출하면 됩니다.// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
지정할 수 있는 환경설정은 다음과 같습니다.
ANEURALNETWORKS_PREFER_LOW_POWER: 배터리 소모를 최소화하는 방식으로 실행합니다. 이 환경설정은 자주 실행되는 컴파일에 적합합니다.ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: 더 많은 전력을 소비하더라도 최대한 빠르게 단일 답변을 반환합니다. 이는 기본값입니다.ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: 카메라로부터 들어오는 연속 프레임을 처리하는 경우와 같이 연속 프레임 처리량을 최대화합니다.
선택적으로
ANeuralNetworksCompilation_setCaching을 호출하여 컴파일 캐싱을 설정할 수 있습니다.// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
cacheDir에getCodeCacheDir()을 사용합니다. 지정되는token은 애플리케이션 내의 모델마다 고유해야 합니다.ANeuralNetworksCompilation_finish()를 호출하여 컴파일 정의를 마무리합니다. 오류가 없는 경우 이 함수는ANEURALNETWORKS_NO_ERROR의 결과 코드를 반환합니다.ANeuralNetworksCompilation_finish(compilation);
기기 검색 및 할당
Android 10(API 수준 29) 이상을 실행하는 Android 기기에서 NNAPI는 머신러닝 프레임워크 라이브러리 및 앱이 사용 가능한 기기에 관한 정보를 얻고 실행에 사용될 기기를 지정할 수 있는 기능을 제공합니다. 사용 가능한 기기에 관한 정보를 제공하면 앱에서 알려진 비호환성을 피하기 위해 기기에 있는 드라이버의 정확한 버전을 얻을 수 있습니다. 모델의 다른 섹션을 실행할 기기를 지정할 수 있는 기능을 앱에 제공하면 배포된 Android 기기에 맞게 앱을 최적화할 수 있습니다.
기기 검색
ANeuralNetworks_getDeviceCount를 사용하여 사용 가능한 기기의 수를 가져옵니다. 각 기기에 관해 ANeuralNetworks_getDevice를 사용하여 ANeuralNetworksDevice 인스턴스를 기기의 참조로 설정합니다.
기기 참조가 있으면 다음 함수를 사용하여 기기에 관한 추가 정보를 확인할 수 있습니다.
ANeuralNetworksDevice_getFeatureLevelANeuralNetworksDevice_getNameANeuralNetworksDevice_getTypeANeuralNetworksDevice_getVersion
기기 할당
ANeuralNetworksModel_getSupportedOperationsForDevices를 사용하여 특정 기기에서 실행할 수 있는 모델의 연산을 탐색합니다.
실행에 사용할 액셀러레이터를 제어하려면 ANeuralNetworksCompilation_create 대신 ANeuralNetworksCompilation_createForDevices를 호출하세요.
결과 ANeuralNetworksCompilation 객체를 일반적인 경우와 같이 사용하세요.
제공된 모델에 선택한 기기에서 지원되지 않는 연산이 포함되어 있는 경우 이 함수가 오류를 반환합니다.
여러 기기가 지정되면 런타임이 작업을 기기에 배포합니다.
다른 기기와 마찬가지로 NNAPI CPU 구현은 ANeuralNetworksDevice에서 이름 nnapi-reference 및 유형 ANEURALNETWORKS_DEVICE_TYPE_CPU로 표시됩니다. ANeuralNetworksCompilation_createForDevices를 호출할 때 CPU 구현이 모델 컴파일 및 실행의 실패 사례를 처리하는 데 사용되지 않습니다.
모델을 지정된 기기에서 실행될 수 있는 하위 모델로 파티션을 나누는 책임은 애플리케이션에 있습니다. 수동으로 파티션을 나눌 필요가 없는 애플리케이션에서 사용 가능한 모든 기기(CPU 포함)를 사용하여 모델을 가속화하려면 더 간단한 ANeuralNetworksCompilation_create를 계속 호출해야 합니다. ANeuralNetworksCompilation_createForDevices를 사용하여 지정한 기기에서 모델을 완전히 지원할 수 없는 경우 ANEURALNETWORKS_BAD_DATA가 반환됩니다.
모델 파티션 나누기
모델에 여러 기기를 사용할 수 있는 경우 NNAPI 런타임은 여러 기기에 작업을 분산합니다. 예를 들어 ANeuralNetworksCompilation_createForDevices에 기기 둘 이상이 제공된 경우 작업을 할당할 때 지정된 모든 기기가 고려됩니다. CPU 기기가 목록에 없으면 CPU 실행이 사용 중지됩니다. ANeuralNetworksCompilation_create를 사용하면 CPU를 포함하여 사용 가능한 모든 기기가 고려됩니다.
모델의 연산별로 연산을 지원하고 클라이언트에서 지정된 실행 환경설정에 따라 최상의 성능(가장 빠른 실행 시간 또는 최저 전원 소비)을 선언하는 기기를 가용 기기 목록에서 선택하여 분산이 처리됩니다. 이러한 파티션 나누기 알고리즘은 다양한 프로세서 사이의 IO로 인해 발생할 수 있는 비효율을 고려하지 않으므로 여러 프로세서를 지정(ANeuralNetworksCompilation_createForDevices를 사용해 명시적으로 또는 ANeuralNetworksCompilation_create를 사용해 암시적으로)할 때는 결과 애플리케이션을 프로파일링하는 것이 중요합니다.
NNAPI로 모델이 파티션된 방식을 이해하려면 Android 로그에서 메시지(INFO 레벨에 있으며 ExecutionPlan 태그가 있음)를 확인합니다.
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name은 그래프에서 연산을 설명하는 이름이고 device-index는 기기 목록에 있는 후보 기기의 색인입니다.
이 목록은 ANeuralNetworksCompilation_createForDevices에 제공된 입력이거나 ANeuralNetworksCompilation_createForDevices를 사용 중인 경우 ANeuralNetworks_getDeviceCount 및 ANeuralNetworks_getDevice를 사용해 모든 기기를 반복할 때 반환되는 기기 목록입니다.
메시지는 다음과 같습니다(INFO 레벨에 있으며 ExecutionPlan 태그가 있음).
ModelBuilder::partitionTheWork: only one best device: device-name
이 메시지는 device-name 기기에서 전체 그래프가 가속화되었음을 나타냅니다.
실행
실행 단계에서는 모델을 입력 세트에 적용하고 앱에서 할당한 하나 이상의 사용자 버퍼나 메모리 공간에 계산 출력을 저장합니다.
컴파일된 모델을 실행하려면 다음 단계를 따르세요.
ANeuralNetworksExecution_create()함수를 호출하여 새 실행 인스턴스를 만듭니다.// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
앱이 계산을 위한 입력 값을 읽는 위치를 지정합니다. 앱은
ANeuralNetworksExecution_setInput()또는ANeuralNetworksExecution_setInputFromMemory()를 호출하여 각각 사용자 버퍼 또는 할당된 메모리 공간으로부터 입력 값을 읽을 수 있습니다.// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
앱이 출력 값을 쓰는 위치를 지정합니다. 앱은
ANeuralNetworksExecution_setOutput()또는ANeuralNetworksExecution_setOutputFromMemory()를 호출하여 각각 사용자 버퍼 또는 할당된 메모리 공간에 출력 값을 쓸 수 있습니다.// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
ANeuralNetworksExecution_startCompute()함수를 호출하여 실행 시작 일정을 예약합니다. 오류가 없는 경우 이 함수는ANEURALNETWORKS_NO_ERROR의 결과 코드를 반환합니다.// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
ANeuralNetworksEvent_wait()함수를 호출하여 실행이 완료될 때까지 대기합니다. 실행에 성공하면 이 함수는ANEURALNETWORKS_NO_ERROR의 결과 코드를 반환합니다. 실행을 시작한 스레드가 아닌 다른 스레드에서 대기할 수도 있습니다.// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
선택적으로 동일한 컴파일 인스턴스를 사용하여 새
ANeuralNetworksExecution인스턴스를 생성함으로써 다양한 입력 세트를 컴파일된 모델에 적용할 수 있습니다.// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
동기 실행
동기 실행은 스레드를 생성하고 동기화하는 데 시간을 소모합니다. 또한 지연 시간은 매우 가변적일 수 있으며 가장 긴 지연 시간은 스레드가 알림을 받거나 절전 모드에서 해제되는 시간과 최종적으로 CPU 코어에 바인딩되는 시간 사이의 최대 500마이크로초에 이르는 지연 시간입니다.
지연 시간을 줄이려면 런타임에 동기 추론 호출을 실행하도록 애플리케이션에 지시하세요. 이 호출은 추론이 시작된 후 반환되지 않고 추론이 완료된 후에만 반환됩니다. 런타임의 비동기 추론 호출을 위해 ANeuralNetworksExecution_startCompute를 호출하는 대신 애플리케이션이 ANeuralNetworksExecution_compute를 호출하여 런타임의 동기 호출을 실행합니다. ANeuralNetworksExecution_compute 호출은 ANeuralNetworksEvent를 사용하지 않고 ANeuralNetworksEvent_wait 호출과 페어링되지 않습니다.
버스트 실행
Android 10(API 수준 29) 이상을 실행하는 Android 기기에서 NNAPI는 ANeuralNetworksBurst 객체를 통해 버스트 실행을 지원합니다. 버스트 실행은 카메라 캡처 프레임 또는 연속적인 오디오 샘플에서 작동하는 실행과 같이 빠르게 연속해서 발생하는 동일한 컴파일의 실행 시퀀스입니다. ANeuralNetworksBurst 객체는 실행 간에 리소스를 재사용할 수 있고 버스트 지속 시간 동안 액셀러레이터가 고성능 상태로 유지되어야 한다고 액셀러레이터에 표시하기 때문에 이 객체를 사용하면 실행 속도가 빨라질 수 있습니다.
ANeuralNetworksBurst는 정상 실행 경로를 약간만 변경합니다. 다음 코드 스니펫에서와 같이 ANeuralNetworksBurst_create를 사용하여 버스트 객체를 만듭니다.
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
버스트 실행은 동기식입니다. 그러나 ANeuralNetworksExecution_compute를 사용하여 각 추론을 실행하는 대신 ANeuralNetworksExecution_burstCompute 함수 호출에서 다양한 ANeuralNetworksExecution 객체를 동일한 ANeuralNetworksBurst와 페어링합니다.
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
ANeuralNetworksBurst 객체가 더 이상 필요하지 않으면 ANeuralNetworksBurst_free를 사용하여 해제합니다.
// Cleanup ANeuralNetworksBurst_free(burst);
비동기 명령어 대기열 및 분리(fenced) 실행
Android 11 이상에서는 NNAPI가 ANeuralNetworksExecution_startComputeWithDependencies() 메서드를 통해 비동기 실행을 예약하는 추가적인 방법을 지원합니다. 이 메서드를 사용할 때 실행은 평가를 시작하기 전에 종속 이벤트가 모두 신호를 받도록 대기합니다. 실행이 완료되고 출력을 사용할 준비가 되면 반환된 이벤트가 신호를 받습니다.
실행을 처리하는 기기에 따라 이벤트는 동기화 펜스로 지원할 수 있습니다. ANeuralNetworksEvent_wait()를 호출하여 이벤트를 대기하고 실행에 사용된 리소스를 회수해야 합니다. ANeuralNetworksEvent_createFromSyncFenceFd()를 사용하여 동기화 펜스를 이벤트 객체로 가져오고 ANeuralNetworksEvent_getSyncFenceFd()를 사용하여 동기화 펜스를 이벤트 객체에서 내보낼 수 있습니다.
동적으로 크기 조정된 출력
출력 크기가 입력 데이터에 따라 달라지는 모델(즉, 모델 실행 시 크기를 판단할 수 없는 모델)을 지원하려면 ANeuralNetworksExecution_getOutputOperandRank 및 ANeuralNetworksExecution_getOutputOperandDimensions를 사용합니다.
다음 코드 샘플은 이를 위한 방법을 보여줍니다.
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
정리
정리 단계에서는 계산에 사용된 내부 리소스의 해제를 다룹니다.
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
오류 관리 및 CPU 대체
파티션 나누기 중에 오류가 발생하거나 드라이버가 모델(의 일부)을 컴파일하지 못하거나 드라이버가 컴파일된 모델(의 일부)을 실행하지 못하는 경우 NNAPI는 연산 하나 이상의 자체 CPU 구현으로 대체될 수 있습니다.
NNAPI 클라이언트에 최적화된 버전의 연산이 포함된 경우(예: TFLite) CPU 대체를 사용 중지하고 클라이언트의 최적화된 연산 구현을 통해 오류를 처리하는 것이 유용할 수 있습니다.
Android 10에서 ANeuralNetworksCompilation_createForDevices를 사용하여 컴파일이 실행되는 경우 CPU 대체가 사용 중지됩니다.
Android P에서는 드라이버에서 실행이 실패하면 NNAPI 실행이 CPU로 대체됩니다.
Android 10에서도 ANeuralNetworksCompilation_createForDevices가 아니라 ANeuralNetworksCompilation_create가 사용될 때는 마찬가지입니다.
첫 번째 실행이 이 단일 파티션으로 대체되고 이 실행도 실패하면 CPU에서 전체 모델을 다시 시도합니다.
파티션 나누기나 컴파일이 실패하면 CPU에서 전체 모델이 시도됩니다.
CPU에서 일부 연산이 지원되지 않는 경우가 있으며 이때는 컴파일이나 실행이 대체되지 않고 실패합니다.
CPU 대체를 사용 중지한 후에도 모델에는 CPU에 예약된 연산이 남아 있을 수 있습니다. ANeuralNetworksCompilation_createForDevices에 제공된 프로세서 목록에 포함되어 있고 이러한 연산을 지원하는 유일한 프로세서이거나 최상의 연산 성능을 요구하는 프로세서인 CPU는 대체가 아니라 기본 실행자로 선택됩니다.
CPU 실행이 이루어지지 않도록 하려면 기기 목록에서 nnapi-reference를 제외하고 ANeuralNetworksCompilation_createForDevices를 사용합니다.
Android P부터는 debug.nn.partition 속성을 2로 설정하여 디버그 빌드에서 실행 시 대체를 사용 중지할 수 있습니다.
메모리 도메인
Android 11 이상에서는 NNAPI가 불투명한 메모리에 할당자 인터페이스를 제공하는 메모리 도메인을 지원합니다. 이를 통해 애플리케이션은 기기 네이티브 메모리를 실행 간에 전달할 수 있으므로 NNAPI가 동일한 드라이버에서 연속 실행 시 불필요하게 데이터를 복사하거나 변환하지 않습니다.
메모리 도메인 기능은 주로 드라이버 내부에 있고 클라이언트 측에 자주 액세스하지 않아도 되는 텐서용입니다. 이러한 텐서의 예로는 시퀀스 모델의 상태 텐서가 있습니다. 클라이언트 측에서 CPU 액세스가 자주 필요한 텐서의 경우 대신 공유 메모리 풀을 사용합니다.
불투명한 메모리를 할당하려면 다음 단계를 따르세요.
ANeuralNetworksMemoryDesc_create()함수를 호출하여 새 메모리 설명어를 만듭니다.// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
ANeuralNetworksMemoryDesc_addInputRole()과ANeuralNetworksMemoryDesc_addOutputRole()을 호출하여 의도된 입력과 출력 역할을 모두 지정합니다.// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
선택적으로
ANeuralNetworksMemoryDesc_setDimensions()를 호출하여 메모리 크기를 지정합니다.// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
ANeuralNetworksMemoryDesc_finish()를 호출하여 설명어 정의를 마무리합니다.ANeuralNetworksMemoryDesc_finish(desc);
설명어를
ANeuralNetworksMemory_createFromDesc()에 전달하여 필요한 만큼 메모리를 할당합니다.// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
더 이상 필요하지 않을 때 메모리 설명어를 해제합니다.
ANeuralNetworksMemoryDesc_free(desc);
클라이언트는 ANeuralNetworksMemoryDesc 객체에서 지정된 역할에 따라 만들어진 ANeuralNetworksMemory 객체만 ANeuralNetworksExecution_setInputFromMemory()나 ANeuralNetworksExecution_setOutputFromMemory()와 함께 사용할 수 있습니다. offset과 length 인수는 0으로 설정하여 전체 메모리가 사용된다고 나타내야 합니다. 클라이언트는 ANeuralNetworksMemory_copy()를 사용하여 메모리의 콘텐츠를 명시적으로 설정하거나 추출할 수도 있습니다.
지정되지 않은 크기나 순위의 역할로 불투명한 메모리를 만들 수 있습니다.
이 경우 메모리 만들기가 기본 드라이버에서 지원되지 않으면 ANEURALNETWORKS_OP_FAILED 상태로 실패할 수 있습니다. 클라이언트는 Ashmem 또는 BLOB 모드 AHardwareBuffer에서 지원하는 충분히 큰 버퍼를 할당하여 대체 로직을 구현하는 것이 좋습니다.
NNAPI가 더 이상 불투명한 메모리 객체에 액세스할 필요가 없을 때 상응하는 ANeuralNetworksMemory 인스턴스를 해제합니다.
ANeuralNetworksMemory_free(opaqueMem);
실적 측정
실행 시간을 측정하거나 프로파일링하여 앱 성능을 평가할 수 있습니다.
실행 시간
런타임을 통해 총 실행 시간을 확인하려면 동기 실행 API를 사용하여 호출에 소요된 시간을 측정하면 됩니다. 더 낮은 수준의 소프트웨어 스택을 통해 총 실행 시간을 확인하려면 ANeuralNetworksExecution_setMeasureTiming 및 ANeuralNetworksExecution_getDuration을 통해 다음을 가져오면 됩니다.
- 액셀러레이터(호스트 프로세서에서 실행되는 드라이버가 아님)에서의 실행 시간
- 드라이버의 실행 시간(액셀러레이터에서의 시간 포함)
런타임 자체의 실행 시간과 같은 오버헤드 및 런타임이 드라이버와 통신하는 데 필요한 IPC는 드라이버의 실행 시간에서 제외됩니다.
이러한 API는 드라이버 또는 액셀러레이터가 컨텍스트 전환에 의해 중단될 수도 있는 추론을 실행하는 데 할애하는 시간이 아니라 작업 제출 및 작업 완료 이벤트 사이의 지속 시간을 측정합니다.
예를 들어 추론 1이 시작된 후 드라이버가 추론 2를 실행하기 위해 작업을 중지한 다음 추론 1을 재개하고 완료하는 경우 추론 1의 실행 시간에 추론 2를 실행하기 위해 작업이 중지된 시간이 포함됩니다.
이 타이밍 정보는 애플리케이션의 프로덕션 배포 시 오프라인에서 사용할 수 있도록 원격 분석을 수집하는 데 유용할 수 있습니다. 성능을 높이기 위해 타이밍 데이터를 사용하여 앱을 수정할 수 있습니다.
이 기능을 사용할 때 다음에 유의하세요.
- 타이밍 정보를 수집할 때 성능 비용이 발생할 수 있습니다.
- 드라이버는 NNAPI 런타임 및 IPC에서 소요된 시간을 제외하고 드라이버 자체 또는 액셀러레이터에서 소요된 시간만 계산할 수 있습니다.
- 이러한 API는
ANeuralNetworksCompilation_createForDevices를 사용하여(numDevices = 1지정) 만든ANeuralNetworksExecution에만 사용할 수 있습니다. - 타이밍 정보를 보고하기 위해 드라이버가 필요하지 않습니다.
Android Systrace로 애플리케이션 프로파일링
Android 10부터 NNAPI는 애플리케이션을 프로파일링하는 데 사용할 수 있는 systrace 이벤트를 자동으로 생성합니다.
NNAPI 소스에는 애플리케이션에서 생성한 systrace 이벤트를 처리하고 모델 수명 주기의 다양한 단계(인스턴스화, 준비, 컴파일 실행 및 종료) 및 다양한 애플리케이션 레이어에서 소요된 시간을 보여주는 표 보기를 생성하는 parse_systrace 유틸리티가 제공됩니다. 애플리케이션이 분할되는 레이어는 다음과 같습니다.
Application: 기본 애플리케이션 코드Runtime: NNAPI 런타임IPC: NNAPI 런타임과 드라이버 코드 사이의 프로세스 간 통신Driver: 액셀러레이터 드라이버 프로세스
프로파일링 분석 데이터 생성
$ANDROID_BUILD_TOP에서 AOSP 소스 트리를 확인하고 TFLite 이미지 분류 예를 타겟 애플리케이션으로 사용한다고 가정하면 다음 단계를 통해 NNAPI 프로파일링 데이터를 생성할 수 있습니다.
- 다음 명령을 사용하여 Android systrace를 시작합니다.
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
-o trace.html 매개변수는 트레이스가 trace.html에 작성됨을 나타냅니다. 자체 애플리케이션을 프로파일링할 때 org.tensorflow.lite.examples.classification을 앱 매니페스트에 지정된 프로세스 이름으로 바꿔야 합니다.
이렇게 하면 셸 콘솔 중 하나가 계속 사용됩니다. 대화식으로 enter가 종료될 때까지 기다리므로 백그라운드에서 명령어를 실행하지 마세요.
- systrace 수집기가 시작된 후 앱을 시작하고 벤치마크 테스트를 실행합니다.
앱이 이미 설치되었다면 Android 스튜디오에서 또는 테스트 전화 UI에서 직접 이미지 분류 앱을 시작할 수 있습니다. 일부 NNAPI 데이터를 생성하려면 앱 구성 대화상자에서 NNAPI를 대상 기기로 선택하여 NNAPI를 사용하도록 앱을 구성해야 합니다.
테스트가 완료되면 1단계 이후 활성화된 콘솔 터미널에서
enter를 눌러 systrace를 종료합니다.다음과 같이
systrace_parser유틸리티를 실행하여 누적 통계를 생성합니다.
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
파서는 다음 매개변수를 허용합니다. - --total-times: 기본 레이어 호출에서 실행 대기 시간을 포함하여 레이어에 소요된 총 시간을 표시합니다. - --print-detail: systrace에서 수집한 모든 이벤트를 인쇄합니다. - --per-execution: 모든 단계의 통계 대신 실행 및 하위 단계만(실행 시간에 따라) 인쇄합니다. - --json: JSON 형식으로 출력을 생성합니다.
출력의 예는 다음과 같습니다.
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
수집된 이벤트가 완전한 애플리케이션 트레이스를 나타내지 않으면 파서가 실패할 수 있습니다. 특히 섹션의 끝을 표시하기 위해 생성된 systrace 이벤트가 관련 섹션 시작 이벤트 없이 트레이스에 존재하면 파서가 실패할 수 있습니다. 이는 일반적으로 systrace 수집기를 시작할 때 이전 프로파일링 세션의 일부 이벤트가 생성되면 발생합니다. 이 때 프로파일링을 다시 실행해야 합니다.
systrace_parser 출력에 애플리케이션 코드의 통계 추가
parse_systrace 애플리케이션은 내장 Android systrace 기능에 기반합니다. 맞춤 이벤트 이름과 함께 systrace API(자바용, 네이티브 애플리케이션용)를 사용하여 앱의 특정 작업에 트레이스를 추가할 수 있습니다.
맞춤 이벤트를 애플리케이션 수명 주기 단계와 연결하려면 이벤트 이름 앞에 다음 문자열 중 하나를 추가합니다.
[NN_LA_PI]: 초기화를 위한 애플리케이션 수준 이벤트[NN_LA_PP]: 준비를 위한 애플리케이션 수준 이벤트[NN_LA_PC]: 컴파일을 위한 애플리케이션 수준 이벤트[NN_LA_PE]: 실행을 위한 애플리케이션 수준 이벤트
다음은 Execution 단계의 runInferenceModel 섹션을 추가하고 NNAPI 트레이스에서 고려되지 않는 다른 섹션 preprocessBitmap을 포함하는 Application 레이어를 추가하여 TFLite 이미지 분류 예 코드를 변경하는 방법에 관한 예입니다. runInferenceModel 섹션은 nnapi systrace 파서가 처리하는 systrace 이벤트의 일부입니다.
Kotlin
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
자바
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
서비스 품질
Android 11 이상에서 NNAPI를 사용하면 애플리케이션이 모델의 상대적 우선순위, 지정된 모델을 준비하는 데 예상되는 최대 시간, 지정된 계산을 완료하는 데 예상되는 최대 시간을 표시할 수 있어 더 나은 서비스 품질(QoS)을 제공합니다. Android 11에는 애플리케이션이 실행 기한 누락과 같은 장애를 파악할 수 있도록 하는 추가적인 NNAPI 결과 코드도 도입되었습니다.
워크로드 우선순위 설정
NNAPI 워크로드의 우선순위를 설정하려면 ANeuralNetworksCompilation_finish()를 호출하기 전에 ANeuralNetworksCompilation_setPriority()를 호출합니다.
기한 설정
애플리케이션은 모델 컴파일과 추론의 기한을 설정할 수 있습니다.
- 컴파일 시간 제한을 설정하려면
ANeuralNetworksCompilation_finish()를 호출하기 전에ANeuralNetworksCompilation_setTimeout()을 호출합니다. - 추론 시간 제한을 설정하려면 컴파일을 시작하기 전에
ANeuralNetworksExecution_setTimeout()을 호출합니다.
피연산자에 관해 자세히 알아보기
다음 섹션에서는 피연산자 사용에 관한 고급 정보를 다룹니다.
양자화 텐서
양자화 텐서는 N차원 배열의 부동 소수점 값을 표현하는 간단한 방법입니다.
NNAPI는 8비트 비대칭 양자화 텐서를 지원합니다. 이러한 텐서의 경우 각 셀의 값은 8비트 정수로 나타냅니다. 텐서와 연관된 값은 scale 및 zeroPoint 값입니다. 이들은 8비트 정수를 부동 소수점 값으로 변환하여 표시하는 데 사용됩니다.
공식은 다음과 같습니다.
(cellValue - zeroPoint) * scale
여기서 zeroPoint 값은 32비트 정수이고 scale은 32비트 부동 소수점 값입니다.
32비트 부동 소수점 값의 텐서에 비해 8비트 양자화 텐서에는 다음과 같은 두 가지 이점이 있습니다.
- 학습된 가중치는 32비트 텐서 크기의 1/4에 불과하므로 애플리케이션이 더 작습니다.
- 계산 속도는 대개 더 빠릅니다. 그 이유는 메모리로부터 가져와야 하는 데이터 크기가 더 작고 정수 계산을 하는 DSP와 같은 프로세서가 효율적이기 때문입니다.
부동 소수점 모델을 양자화 모델로 변환하는 것도 가능하지만 경험에 따르면 양자화 모델을 직접 학습시키는 것이 더 나은 결과를 달성했습니다. 실제로 신경망은 각 값의 미세한 증가량을 보정하는 방법을 학습합니다. 각 양자화 텐서의 경우 scale 및 zeroPoint 값은 학습 프로세스 중에 결정됩니다.
NNAPI에서는 ANeuralNetworksOperandType 데이터 구조의 유형 필드를 ANEURALNETWORKS_TENSOR_QUANT8_ASYMM으로 설정하여 양자화 텐서 유형을 정의합니다.
이 데이터 구조에서 텐서의 scale 및 zeroPoint 값을 지정할 수도 있습니다.
또한 NNAPI는 8비트 비대칭 양자화 텐서 외에도 다음을 지원합니다.
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL:CONV/DEPTHWISE_CONV/TRANSPOSED_CONV연산에 가중치를 나타내는 데 사용할 수 있습니다.ANEURALNETWORKS_TENSOR_QUANT16_ASYMM:QUANTIZED_16BIT_LSTM의 내부 상태에 사용할 수 있습니다.ANEURALNETWORKS_TENSOR_QUANT8_SYMM:ANEURALNETWORKS_DEQUANTIZE의 입력이 될 수 있습니다.
선택적 피연산자
ANEURALNETWORKS_LSH_PROJECTION과 같은 일부 연산에서는 선택적 피연산자를 사용합니다. 모델에서 선택적 피연산자가 생략되었음을 나타내려면 ANeuralNetworksModel_setOperandValue() 함수를 호출하고 버퍼에는 NULL을, 길이에는 0을 전달합니다.
피연산자의 존재 여부에 관한 결정이 실행마다 달라지는 경우 ANeuralNetworksExecution_setInput() 또는 ANeuralNetworksExecution_setOutput() 함수를 사용하고 버퍼에는 NULL을, 길이에는 0을 전달하여 피연산자가 생략되었음을 나타냅니다.
순위를 알 수 없는 텐서
Android 9(API 수준 28)에서 차원을 알 수 없지만 순위(차원의 수)는 알려진 모델 피연산자가 도입되었습니다. Android 10(API 수준 29)에서는 ANeuralNetworksOperandType에 표시된 것처럼 순위를 알 수 없는 텐서가 도입되었습니다.
NNAPI 벤치마크
NNAPI 벤치마크는 platform/test/mlts/benchmark(벤치마크 앱) 및 platform/test/mlts/models(모델 및 데이터세트)의 AOSP에서 사용할 수 있습니다.
벤치마크는 지연 시간과 정확성을 평가하고 동일한 모델 및 데이터세트에 관해 CPU에서 실행되는 Tensorflow Lite를 사용하여 실행된 동일한 작업과 드라이버를 비교합니다.
벤치마크를 사용하려면 다음 단계를 따르세요.
대상 Android 기기를 컴퓨터에 연결한 후 터미널 창을 열고 adb를 통해 기기에 연결할 수 있는지 확인합니다.
둘 이상의 Android 기기가 연결된 경우 대상 기기
ANDROID_SERIAL환경 변수를 내보냅니다.Android 최상위 소스 디렉터리로 이동합니다.
다음 명령어를 실행합니다.
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
벤치마크 실행이 끝나면 결과가
xdg-open에 전달되는 HTML 페이지로 표시됩니다.
NNAPI 로그
NNAPI는 유용한 진단 정보를 시스템 로그에 생성합니다. 로그를 분석하려면 logcat 유틸리티를 사용하세요.
debug.nn.vlog 속성을 공백, 콜론, 쉼표로 구분해 다음 값으로 설정(adb shell 사용)하여 특정 단계나 구성요소에 관한 상세한 NNAPI 로깅을 사용 설정합니다.
model: 모델 빌드compilation: 모델 실행 계획 및 컴파일 생성execution: 모델 실행cpuexe: NNAPI CPU 구현을 사용하여 연산 실행manager: NNAPI 확장 프로그램, 사용 가능한 인터페이스, 기능 관련 정보all또는1: 위의 모든 요소
예를 들어 전체 상세 로깅을 사용 설정하려면 명령어 adb shell setprop debug.nn.vlog all을 사용합니다. 상세 로깅을 사용 중지하려면 명령어 adb shell setprop debug.nn.vlog '""'를 사용합니다.
사용 설정되면 상세 로깅은 단계 또는 구성요소 이름으로 설정된 태그를 사용해 INFO 레벨의 로그 항목을 생성합니다.
debug.nn.vlog 제어 메시지 옆에 NNAPI API 구성요소는 다양한 레벨에서 다른 로그 항목을 제공합니다(로그 항목마다 특정 로그 태그 사용).
구성요소 목록을 가져오려면 다음 표현식을 사용하여 소스 트리를 검색합니다.
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
이 표현식은 현재 다음과 같은 태그를 반환합니다.
- BurstBuilder
- 콜백
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- 관리자
- 메모리
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- 연산
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
logcat에서 표시하는 로그 메시지의 레벨을 제어하려면 환경 변수 ANDROID_LOG_TAGS를 사용합니다.
전체 NNAPI 로그 메시지를 표시하고 다른 메시지를 사용 중지하려면 ANDROID_LOG_TAGS를 다음과 같이 설정합니다.
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
다음 명령어를 사용하여 ANDROID_LOG_TAGS를 설정할 수 있습니다.
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
이 명령어는 logcat에 적용되는 필터에 불과하며, debug.nn.vlog 속성을 all로 설정해야 상세 로그 정보가 생성됩니다.