


Nhóm Android Runtime (ART) đã giảm thời gian biên dịch xuống 18% mà không ảnh hưởng đến mã đã biên dịch hoặc bất kỳ mức hồi quy bộ nhớ đỉnh nào. Việc cải thiện này là một phần trong sáng kiến năm 2025 của chúng tôi nhằm cải thiện thời gian biên dịch mà không làm giảm mức sử dụng bộ nhớ hoặc chất lượng của mã đã biên dịch.
Việc tối ưu hoá tốc độ biên dịch là yếu tố then chốt đối với ART. Ví dụ: khi biên dịch tức thì (JIT), quá trình này sẽ ảnh hưởng trực tiếp đến hiệu quả của các ứng dụng và hiệu suất tổng thể của thiết bị. Việc biên dịch nhanh hơn sẽ giảm thời gian trước khi các hoạt động tối ưu hoá bắt đầu, mang lại trải nghiệm mượt mà và phản hồi nhanh hơn cho người dùng. Hơn nữa, đối với cả JIT và AOT, những điểm cải tiến về tốc độ biên dịch sẽ giúp giảm mức tiêu thụ tài nguyên trong quá trình biên dịch, mang lại lợi ích cho thời lượng pin và nhiệt độ của thiết bị, đặc biệt là trên các thiết bị cấp thấp.
Một số điểm cải thiện về tốc độ biên dịch này đã được ra mắt trong bản phát hành Android tháng 6 năm 2025 và những điểm còn lại sẽ có trong bản phát hành Android vào cuối năm. Ngoài ra, tất cả người dùng Android từ phiên bản 12 trở lên đều đủ điều kiện nhận những điểm cải tiến này thông qua các bản cập nhật chính.
Tối ưu hoá trình biên dịch tối ưu hoá
Việc tối ưu hoá trình biên dịch luôn là một trò chơi đánh đổi. Bạn không thể có được tốc độ miễn phí; bạn phải từ bỏ một thứ gì đó. Chúng tôi đặt ra một mục tiêu rất rõ ràng và đầy thách thức cho chính mình: làm cho trình biên dịch nhanh hơn, nhưng không làm giảm bộ nhớ và quan trọng nhất là không làm giảm chất lượng của mã mà trình biên dịch tạo ra. Nếu trình biên dịch nhanh hơn nhưng các ứng dụng chạy chậm hơn, thì chúng tôi đã thất bại.
Nguồn lực duy nhất mà chúng tôi sẵn sàng bỏ ra là thời gian phát triển của chính mình để tìm hiểu kỹ lưỡng, điều tra và tìm ra các giải pháp thông minh đáp ứng những tiêu chí nghiêm ngặt này. Hãy cùng xem xét kỹ hơn cách chúng tôi tìm ra những điểm cần cải thiện, cũng như tìm ra giải pháp phù hợp cho nhiều vấn đề.
Tìm những điểm tối ưu hoá có giá trị
Trước khi có thể bắt đầu tối ưu hoá một chỉ số, bạn phải đo lường được chỉ số đó. Nếu không, bạn sẽ không bao giờ biết chắc liệu mình đã cải thiện được hay chưa. May mắn là tốc độ thời gian biên dịch khá nhất quán, miễn là bạn thực hiện một số biện pháp phòng ngừa như sử dụng cùng một thiết bị mà bạn dùng để đo trước và sau khi thay đổi, đồng thời đảm bảo bạn không điều tiết thiết bị của mình. Ngoài ra, chúng tôi cũng có các phép đo mang tính xác định như số liệu thống kê của trình biên dịch giúp chúng tôi hiểu rõ những gì đang diễn ra.
Vì nguồn lực mà chúng tôi hy sinh cho những cải tiến này là thời gian phát triển, nên chúng tôi muốn có thể lặp lại nhanh nhất có thể. Điều này có nghĩa là chúng tôi đã chọn một số ứng dụng tiêu biểu (bao gồm cả ứng dụng bên thứ nhất, ứng dụng bên thứ ba và chính hệ điều hành Android) để tạo mẫu giải pháp. Sau đó, chúng tôi đã xác minh rằng việc triển khai cuối cùng là xứng đáng bằng cả kiểm thử thủ công và tự động trên diện rộng.
Với bộ apk được chọn lọc đó, chúng tôi sẽ kích hoạt quá trình biên dịch thủ công cục bộ, nhận được hồ sơ biên dịch và sử dụng pprof để hình dung nơi chúng tôi đang dành thời gian.
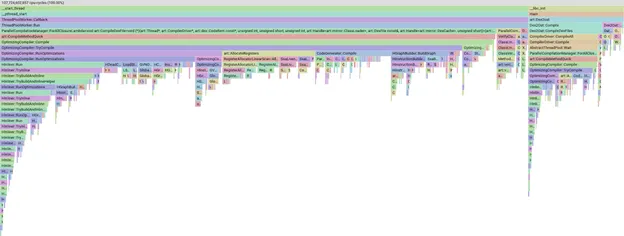
Ví dụ về biểu đồ ngọn lửa của một hồ sơ trong pprof
Công cụ pprof rất mạnh mẽ và cho phép chúng ta phân tích, lọc và sắp xếp dữ liệu để xem, ví dụ: giai đoạn hoặc phương thức trình biên dịch nào mất nhiều thời gian nhất. Chúng ta sẽ không đi sâu vào bản thân pprof; chỉ cần biết rằng nếu thanh này lớn hơn thì có nghĩa là quá trình biên dịch mất nhiều thời gian hơn.
Một trong những chế độ xem này là chế độ xem "từ dưới lên", trong đó bạn có thể thấy phương thức nào đang chiếm phần lớn thời gian. Trong hình ảnh bên dưới, chúng ta có thể thấy một phương thức có tên là Kill, chiếm hơn 1% thời gian biên dịch. Một số phương pháp hàng đầu khác cũng sẽ được thảo luận sau trong bài đăng trên blog.
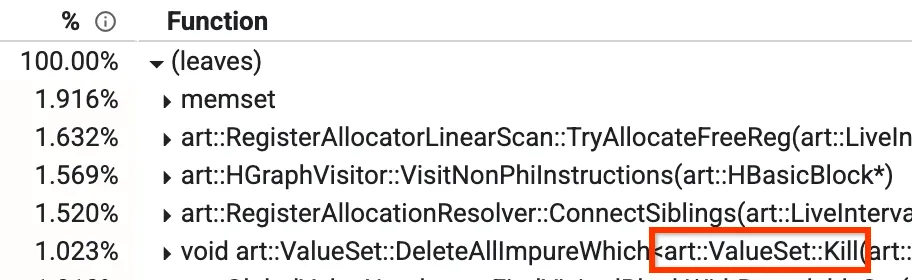
Chế độ xem từ dưới lên của một hồ sơ
Trong trình biên dịch tối ưu hoá của chúng tôi, có một giai đoạn được gọi là Đánh số giá trị toàn cục (GVN). Bạn không cần lo lắng về những gì nó làm nói chung, nhưng phần có liên quan là biết rằng nó có một phương thức gọi là "Kill" (Huỷ) để xoá một số nút theo bộ lọc. Việc này tốn thời gian vì phải lặp lại qua tất cả các nút và kiểm tra từng nút một. Chúng tôi nhận thấy có một số trường hợp mà chúng tôi biết trước rằng quy trình kiểm tra sẽ không thành công, bất kể số lượng nút đang hoạt động tại thời điểm đó. Trong những trường hợp này, chúng ta có thể bỏ qua hoàn toàn việc lặp lại, giảm từ 1,023% xuống còn khoảng 0,3% và cải thiện thời gian chạy của GVN thêm khoảng 15%.
Triển khai các hoạt động tối ưu hoá đáng giá
Chúng ta đã tìm hiểu cách đo lường và cách phát hiện thời gian đang được sử dụng ở đâu, nhưng đây chỉ là bước khởi đầu. Bước tiếp theo là cách tối ưu hoá thời gian dành cho việc biên dịch.
Thông thường, trong trường hợp như `Kill` ở trên, chúng ta sẽ xem xét cách lặp lại các nút và thực hiện nhanh hơn bằng cách, chẳng hạn như thực hiện song song hoặc cải thiện chính thuật toán. Trên thực tế, đó là những gì chúng tôi đã thử lúc đầu và chỉ khi không tìm được việc gì để làm, chúng tôi mới nhận ra rằng giải pháp là (trong một số trường hợp) không cần lặp lại! Khi thực hiện những loại hoạt động tối ưu hoá này, bạn rất dễ bỏ lỡ những điều quan trọng.
Trong các trường hợp khác, chúng tôi đã sử dụng một số kỹ thuật khác nhau, bao gồm:
- sử dụng phương pháp phỏng đoán để quyết định xem một quy trình tối ưu hoá có mang lại kết quả xứng đáng hay không và do đó có thể bỏ qua
- sử dụng các cấu trúc dữ liệu bổ sung để lưu vào bộ nhớ đệm dữ liệu đã tính toán
- thay đổi cấu trúc dữ liệu hiện tại để tăng tốc độ
- tính toán kết quả một cách lười biếng để tránh các chu kỳ trong một số trường hợp
- sử dụng mức độ trừu tượng phù hợp – các tính năng không cần thiết có thể làm chậm mã
- tránh phải tìm kiếm một con trỏ thường dùng qua nhiều lần tải
Làm cách nào để biết liệu có nên theo đuổi các hoạt động tối ưu hoá hay không?
Đó là phần hay nhất, bạn không cần làm gì cả. Sau khi phát hiện thấy một khu vực đang tiêu tốn nhiều thời gian biên dịch và sau khi dành thời gian phát triển để cố gắng cải thiện khu vực đó, đôi khi bạn không thể tìm ra giải pháp. Có thể không cần làm gì cả, việc triển khai sẽ mất quá nhiều thời gian, việc này sẽ làm giảm đáng kể một chỉ số khác, làm tăng độ phức tạp của cơ sở mã, v.v. Đối với mỗi hoạt động tối ưu hoá thành công mà bạn có thể thấy trong bài đăng này trên blog, hãy biết rằng có vô số hoạt động khác không mang lại kết quả.
Nếu bạn đang ở trong tình huống tương tự, hãy cố gắng ước tính mức độ cải thiện chỉ số bằng cách làm ít việc nhất có thể. Điều này có nghĩa là theo thứ tự:
- Ước tính bằng các chỉ số bạn đã thu thập hoặc chỉ dựa vào cảm tính
- Ước tính bằng một nguyên mẫu nhanh và đơn giản
- Triển khai một giải pháp.
Đừng quên xem xét việc ước tính những hạn chế của giải pháp. Ví dụ: nếu bạn định dựa vào các cấu trúc dữ liệu bổ sung, thì bạn sẵn sàng sử dụng bao nhiêu bộ nhớ?
Tìm hiểu sâu hơn
Không dông dài nữa, hãy cùng xem một số thay đổi mà chúng tôi đã triển khai.
Chúng tôi đã triển khai một thay đổi để tối ưu hoá một phương thức có tên là FindReferenceInfoOf. Phương thức này đang thực hiện một tìm kiếm tuyến tính của một vectơ để tìm một mục. Chúng tôi đã cập nhật cấu trúc dữ liệu đó để được lập chỉ mục theo mã nhận dạng của chỉ dẫn, nhờ đó FindReferenceInfoOf sẽ là O(1) thay vì O(n). Ngoài ra, chúng tôi đã phân bổ trước vectơ để tránh đổi kích thước. Chúng tôi đã tăng nhẹ bộ nhớ vì phải thêm một trường bổ sung để đếm số lượng mục mà chúng tôi đã chèn vào vectơ, nhưng đó là một sự hy sinh nhỏ vì bộ nhớ đỉnh không tăng. Điều này giúp tăng tốc giai đoạn LoadStoreAnalysis từ 34% đến 66%, từ đó cải thiện thời gian biên dịch từ 0,5% đến 1,8%.
Chúng tôi có một cách triển khai HashSet tuỳ chỉnh mà chúng tôi sử dụng ở một số nơi. Việc tạo cấu trúc dữ liệu này mất khá nhiều thời gian và chúng tôi đã tìm ra lý do. Nhiều năm trước, cấu trúc dữ liệu này chỉ được dùng ở một số nơi sử dụng HashSet rất lớn và được điều chỉnh để tối ưu hoá cho cấu trúc đó. Tuy nhiên, ngày nay, nó được dùng theo hướng ngược lại, chỉ có một vài mục nhập và có tuổi thọ ngắn. Điều này có nghĩa là chúng ta đang lãng phí các chu kỳ bằng cách tạo HashSet khổng lồ này nhưng chỉ sử dụng nó cho một vài mục trước khi loại bỏ. Với thay đổi này, chúng tôi đã cải thiện thời gian biên dịch từ 1,3% đến 2%. Ngoài ra, mức sử dụng bộ nhớ đã giảm khoảng 0,5 – 1% vì chúng tôi không sử dụng các cấu trúc dữ liệu lớn như trước.
Chúng tôi đã cải thiện thời gian biên dịch từ 0,5 đến 1% bằng cách truyền cấu trúc dữ liệu theo tham chiếu đến lambda để tránh sao chép chúng. Đây là một vấn đề bị bỏ sót trong quy trình đánh giá ban đầu và tồn tại trong cơ sở mã của chúng tôi trong nhiều năm. Nhờ xem xét các hồ sơ trong pprof, chúng tôi nhận thấy những phương thức này đang tạo và huỷ rất nhiều cấu trúc dữ liệu, điều này khiến chúng tôi phải điều tra và tối ưu hoá chúng.
Chúng tôi đã tăng tốc giai đoạn ghi đầu ra đã biên dịch bằng cách lưu vào bộ nhớ đệm các giá trị đã tính toán, giúp cải thiện tổng thời gian biên dịch từ 1,3% đến 2,8%. Rất tiếc, việc ghi sổ bổ sung này đã vượt quá khả năng và quy trình kiểm thử tự động của chúng tôi đã cảnh báo về tình trạng giảm bộ nhớ. Sau đó, chúng tôi xem xét lại cùng một đoạn mã và triển khai một phiên bản mới. Phiên bản này không chỉ xử lý vấn đề giảm bộ nhớ mà còn cải thiện thời gian biên dịch thêm khoảng 0,5 – 1,8%! Trong lần thay đổi thứ hai này, chúng tôi phải tái cấu trúc và hình dung lại cách giai đoạn này hoạt động để loại bỏ một trong hai cấu trúc dữ liệu.
Chúng tôi có một giai đoạn trong trình biên dịch tối ưu hoá để nội tuyến các lệnh gọi hàm nhằm đạt được hiệu suất tốt hơn. Để chọn phương thức nội tuyến, chúng ta sử dụng cả phương pháp phỏng đoán trước khi thực hiện bất kỳ phép tính nào và các bước kiểm tra cuối cùng sau khi thực hiện công việc nhưng ngay trước khi hoàn tất quy trình nội tuyến. Nếu bất kỳ chỉ số nào trong số đó phát hiện thấy việc nội tuyến không đáng (ví dụ: sẽ có quá nhiều chỉ dẫn mới được thêm vào), thì chúng ta sẽ không nội tuyến lệnh gọi phương thức.
Chúng tôi đã chuyển 2 bước kiểm tra từ danh mục "kiểm tra cuối cùng" sang danh mục "kinh nghiệm" để ước tính xem việc nội tuyến có thành công hay không trước khi thực hiện bất kỳ phép tính tốn thời gian nào. Vì đây là một số liệu ước tính nên không thể hoàn hảo, nhưng chúng tôi đã xác minh rằng các phương pháp phỏng đoán mới của chúng tôi bao gồm 99,9% những gì đã được nội tuyến trước đây mà không ảnh hưởng đến hiệu suất. Một trong những phương pháp phỏng đoán mới này là về các thanh ghi DEX cần thiết (cải thiện khoảng 0,2 – 1,3%) và phương pháp còn lại là về số lượng chỉ dẫn (cải thiện khoảng 2%).
Chúng tôi có một chế độ triển khai BitVector tuỳ chỉnh mà chúng tôi sử dụng ở một số nơi. Chúng tôi đã thay thế lớp BitVector có thể đổi kích thước bằng BitVectorView đơn giản hơn cho một số vectơ bit có kích thước cố định. Điều này giúp loại bỏ một số gián tiếp và kiểm tra phạm vi thời gian chạy, đồng thời tăng tốc quá trình tạo các đối tượng vectơ bit.
Hơn nữa, lớp BitVectorView được tạo mẫu trên loại bộ nhớ cơ bản (thay vì luôn sử dụng uint32_t làm BitVector cũ). Điều này cho phép một số thao tác (ví dụ: Union()) xử lý cùng lúc số lượng bit gấp đôi trên các nền tảng 64 bit. Tổng số mẫu của các hàm bị ảnh hưởng đã giảm hơn 1% khi biên dịch hệ điều hành Android. Việc này được thực hiện qua một số thay đổi [1, 2, 3, 4, 5, 6]
Nếu nói chi tiết về tất cả các hoạt động tối ưu hoá, chúng ta sẽ phải ở đây cả ngày! Nếu bạn quan tâm đến một số điểm tối ưu hoá khác, hãy xem một số thay đổi khác mà chúng tôi đã triển khai:
- Thêm tính năng ghi sổ sách để cải thiện thời gian biên dịch từ 0,6 đến 1,6%.
- Tính toán dữ liệu một cách chậm rãi để tránh các chu kỳ, nếu có thể.
- Cải tiến mã để bỏ qua công việc tính toán trước khi không dùng đến.
- Tránh một số chuỗi tải phụ thuộc khi bạn có thể dễ dàng lấy trình phân bổ từ những nơi khác.
- Một trường hợp khác là thêm một bước kiểm tra để tránh thực hiện công việc không cần thiết.
- Tránh phân nhánh thường xuyên trên loại đăng ký (core/FP) trong trình phân bổ đăng ký.
- Đảm bảo một số mảng được khởi tạo tại thời điểm biên dịch. Đừng dựa vào clang để thực hiện việc này.
- Dọn dẹp một số vòng lặp. Sử dụng các vòng lặp phạm vi mà clang có thể tối ưu hoá tốt hơn vì không cần tải lại các con trỏ nội bộ của vùng chứa do các tác dụng phụ của vòng lặp. Tránh gọi hàm ảo "HInstruction::GetInputRecords()" trong vòng lặp thông qua "InputAt(.)" nội tuyến cho mỗi đầu vào.
- Tránh các hàm Accept() cho mẫu khách truy cập bằng cách khai thác một hoạt động tối ưu hoá trình biên dịch.
Kết luận
Nhờ nỗ lực cải thiện tốc độ biên dịch của ART, chúng tôi đã đạt được những tiến bộ đáng kể, giúp Android hoạt động mượt mà và hiệu quả hơn, đồng thời góp phần cải thiện thời lượng pin và nhiệt độ của thiết bị. Bằng cách siêng năng xác định và triển khai các hoạt động tối ưu hoá, chúng tôi đã chứng minh rằng có thể đạt được những lợi ích đáng kể tại thời gian biên dịch mà không ảnh hưởng đến mức sử dụng bộ nhớ hoặc chất lượng mã.
Hành trình của chúng tôi bao gồm việc lập hồ sơ bằng các công cụ như pprof, sẵn sàng lặp lại và đôi khi thậm chí từ bỏ những hướng đi ít hiệu quả. Những nỗ lực tập thể của nhóm ART không chỉ giảm thời gian biên dịch xuống một tỷ lệ đáng kể mà còn đặt nền móng cho những tiến bộ trong tương lai.
Tất cả những điểm cải tiến này đều có trong bản cập nhật Android cuối năm 2025 và đối với Android 12 trở lên thông qua các bản cập nhật chính. Chúng tôi hy vọng bài viết nghiên cứu chuyên sâu này về quy trình tối ưu hoá của chúng tôi sẽ cung cấp thông tin chi tiết có giá trị về sự phức tạp và lợi ích của kỹ thuật trình biên dịch!
Tác giả:
Tiếp tục đọc
-


Tin tức về sản phẩm
Chúng tôi rất vui mừng thông báo rằng Android XR đã chính thức hỗ trợ Unreal Engine và Godot. Chúng tôi cũng ra mắt các công cụ mới được thiết kế để tăng năng suất và cho phép các chức năng XR mới: Android XR Engine Hub và Android XR Interaction Framework.
Luke Hopkins • Đọc trong 4 phút
-


Tin tức về sản phẩm
Với việc phát hành Android 17, chúng tôi đang chuyển sang tiêu chuẩn phát triển thích ứng. Người dùng không còn chỉ dựa vào một kiểu dáng thiết bị duy nhất nữa; họ chuyển đổi giữa điện thoại, thiết bị có thể gập lại, máy tính bảng, máy tính xách tay, màn hình ô tô và môi trường XR sống động trong suốt cả ngày.
Fahd Imtiaz • Đọc trong 4 phút
-


Tin tức về sản phẩm
Chúng tôi rất vui khi chia sẻ các tính năng của Google TV và công cụ dành cho nhà phát triển được thiết kế để tăng khả năng hiển thị nội dung của bạn và chuẩn bị ứng dụng cho trải nghiệm xem truyền hình trong tương lai.
Paul Lammertsma • Đọc trong 4 phút
Nhận thông tin cập nhật
Nhận thông tin chi tiết mới nhất về hoạt động phát triển trên Android trong hộp thư đến của bạn mỗi tuần.
