
Mit WorkManager können Sie eine Kette von Aufgaben erstellen und in die Warteschlange stellen, in der mehrere abhängige Aufgaben und die Reihenfolge, in der sie ausgeführt werden sollen, angegeben werden. Diese Funktion ist besonders nützlich, wenn Sie mehrere Aufgaben in einer bestimmten Reihenfolge ausführen müssen.
Um eine Kette von Aufgaben zu erstellen, können Sie WorkManager.beginWith(OneTimeWorkRequest) oder WorkManager.beginWith(List<OneTimeWorkRequest>) verwenden, die jeweils eine Instanz von WorkContinuation zurückgeben.
Mit einem WorkContinuation können dann abhängige OneTimeWorkRequest-Instanzen mit then(OneTimeWorkRequest) oder then(List<OneTimeWorkRequest>) hinzugefügt werden.
Bei jedem Aufruf von WorkContinuation.then(...) wird eine neue Instanz von WorkContinuation zurückgegeben. Wenn Sie ein List von OneTimeWorkRequest Instanzen hinzufügen, können diese Anfragen potenziell parallel ausgeführt werden.
Schließlich können Sie die Methode WorkContinuation.enqueue() verwenden, um die Kette von WorkContinuations zu enqueue().
Sehen wir uns ein Beispiel an. In diesem Beispiel sind drei verschiedene Worker-Jobs konfiguriert, die (potenziell parallel) ausgeführt werden. Die Ergebnisse dieser Worker werden dann zusammengeführt und an einen Caching-Worker-Job übergeben. Schließlich wird die Ausgabe dieses Jobs an einen Upload-Worker übergeben, der die Ergebnisse auf einen Remote-Server hochlädt.
Kotlin
WorkManager.getInstance(myContext) // Candidates to run in parallel .beginWith(listOf(plantName1, plantName2, plantName3)) // Dependent work (only runs after all previous work in chain) .then(cache) .then(upload) // Call enqueue to kick things off .enqueue()
Java
WorkManager.getInstance(myContext) // Candidates to run in parallel .beginWith(Arrays.asList(plantName1, plantName2, plantName3)) // Dependent work (only runs after all previous work in chain) .then(cache) .then(upload) // Call enqueue to kick things off .enqueue();
Input Mergers
Wenn Sie OneTimeWorkRequest-Instanzen verketten, wird die Ausgabe übergeordneter Arbeitsanfragen als Eingabe an die untergeordneten Anfragen übergeben. Im obigen Beispiel werden die Ausgaben von plantName1, plantName2 und plantName3 als Eingaben für die cache-Anfrage übergeben.
Um Eingaben aus mehreren übergeordneten Arbeitsanfragen zu verwalten, verwendet WorkManager InputMerger.
WorkManager bietet zwei verschiedene Arten von InputMerger:
OverwritingInputMergerversucht, alle Schlüssel aus allen Eingaben in die Ausgabe aufzunehmen. Bei Konflikten werden die zuvor festgelegten Schlüssel überschrieben.ArrayCreatingInputMergerversucht, die Eingaben zusammenzuführen und bei Bedarf Arrays zu erstellen.
Wenn Sie einen spezifischeren Anwendungsfall haben, können Sie Ihre eigene Klasse schreiben, indem Sie InputMerger unterteilen.
OverwritingInputMerger
OverwritingInputMerger ist die Standardmethode zum Zusammenführen. Wenn es beim Zusammenführen zu Schlüsselkonflikten kommt, wird der letzte Wert für einen Schlüssel alle vorherigen Versionen in den resultierenden Ausgabedaten überschreiben.
Wenn die Anlagen-Eingaben beispielsweise jeweils einen Schlüssel haben, der mit den entsprechenden Variablennamen übereinstimmt ("plantName1", "plantName2" und "plantName3"), enthalten die an den cache-Worker übergebenen Daten drei Schlüssel/Wert-Paare.
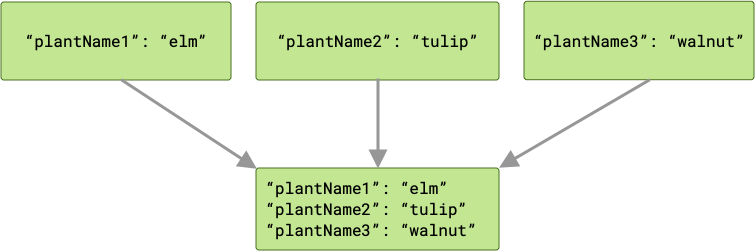
Bei einem Konflikt „gewinnt“ der letzte Worker, der die Aufgabe abgeschlossen hat, und sein Wert wird an cache übergeben.
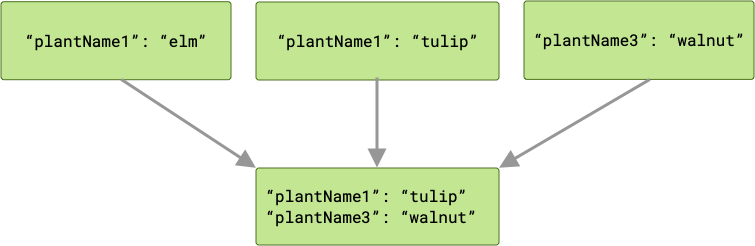
Da Ihre Arbeitsanfragen parallel ausgeführt werden, gibt es keine Garantie für die Reihenfolge, in der sie ausgeführt werden. Im obigen Beispiel kann plantName1 entweder den Wert "tulip" oder "elm" haben, je nachdem, welcher Wert zuletzt geschrieben wurde. Wenn die Wahrscheinlichkeit eines Schlüsselkonflikts besteht und Sie alle Ausgabedaten bei einem Merge beibehalten müssen, ist ArrayCreatingInputMerger möglicherweise die bessere Option.
ArrayCreatingInputMerger
Im obigen Beispiel möchten wir die Ausgaben aller Worker für Pflanzennamen beibehalten. Daher sollten wir ArrayCreatingInputMerger verwenden.
Kotlin
val cache: OneTimeWorkRequest = OneTimeWorkRequestBuilder<PlantWorker>() .setInputMerger(ArrayCreatingInputMerger::class) .setConstraints(constraints) .build()
Java
OneTimeWorkRequest cache = new OneTimeWorkRequest.Builder(PlantWorker.class) .setInputMerger(ArrayCreatingInputMerger.class) .setConstraints(constraints) .build();
Mit ArrayCreatingInputMerger wird jedem Schlüssel ein Array zugeordnet. Wenn jeder der Schlüssel eindeutig ist, besteht das Ergebnis aus einer Reihe von Arrays mit einem Element.
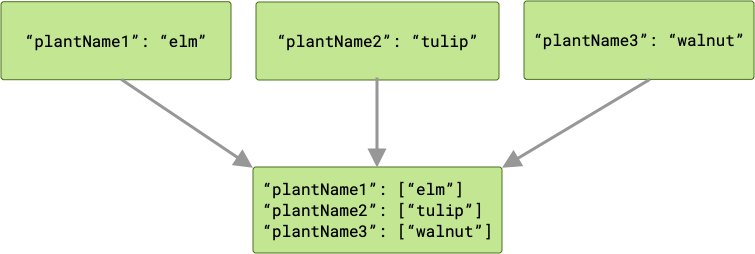
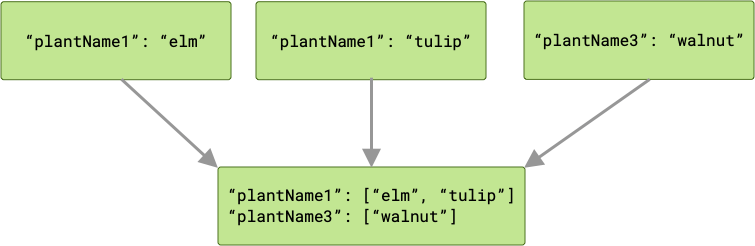
Bei Schlüsselkollisionen werden alle entsprechenden Werte in einem Array zusammengefasst.
Verkettung und Arbeitsstatus
Ketten von OneTimeWorkRequest werden sequenziell ausgeführt, solange ihre Arbeit erfolgreich abgeschlossen wird (d. h., sie geben ein Result.success() zurück). Arbeitsanfragen können während der Ausführung fehlschlagen oder abgebrochen werden, was sich auf abhängige Arbeitsanfragen auswirkt.
Wenn die erste OneTimeWorkRequest in eine Kette von Arbeitsanfragen eingereiht wird, werden alle nachfolgenden Arbeitsanfragen blockiert, bis die Arbeit dieser ersten Arbeitsanfrage abgeschlossen ist.
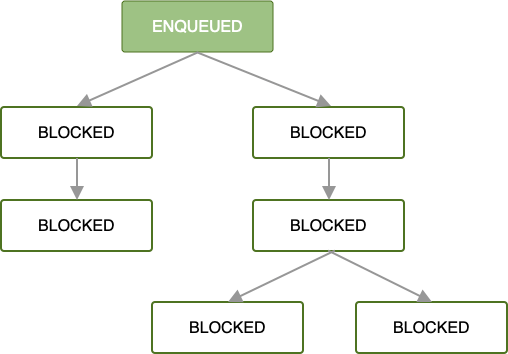
Sobald die erste Arbeitsanfrage in die Warteschlange gestellt wurde und alle Arbeitsbeschränkungen erfüllt sind, wird sie ausgeführt. Wenn die Arbeit im Stammverzeichnis OneTimeWorkRequest oder List<OneTimeWorkRequest> erfolgreich abgeschlossen wird (d. h., es wird ein Result.success() zurückgegeben), wird die nächste Gruppe abhängiger Arbeitsanfragen in die Warteschlange gestellt.
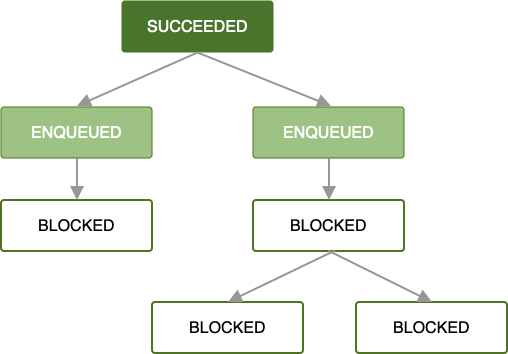
Solange jede Arbeitsanfrage erfolgreich abgeschlossen wird, setzt sich dieses Muster durch den Rest Ihrer Kette von Arbeitsanfragen fort, bis alle Arbeiten in der Kette abgeschlossen sind. Das ist zwar der einfachste und oft bevorzugte Fall, aber Fehlerzustände sind genauso wichtig.
Wenn bei der Verarbeitung Ihrer Arbeitsanfrage durch einen Worker ein Fehler auftritt, können Sie die Anfrage gemäß einer von Ihnen definierten Backoff-Richtlinie noch einmal versuchen. Wenn Sie eine Anfrage wiederholen, die Teil einer Kette ist, wird nur diese Anfrage mit den ihr zur Verfügung gestellten Eingabedaten wiederholt. Parallel ausgeführte Vorgänge sind davon nicht betroffen.
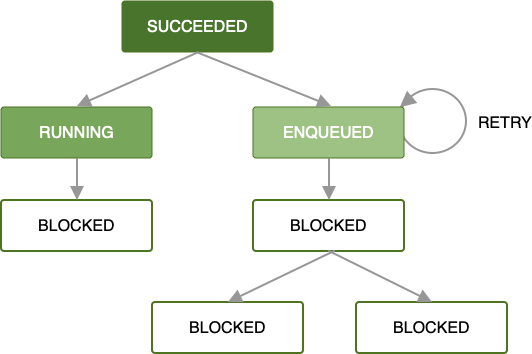
Weitere Informationen zum Definieren benutzerdefinierter Wiederholungsstrategien finden Sie unter Retry and Backoff Policy.
Wenn diese Richtlinie für Wiederholungsversuche nicht definiert oder erschöpft ist oder Sie anderweitig einen Zustand erreichen, in dem ein OneTimeWorkRequest Result.failure() zurückgibt, werden diese Arbeitsanfrage und alle abhängigen Arbeitsanfragen als FAILED. markiert.
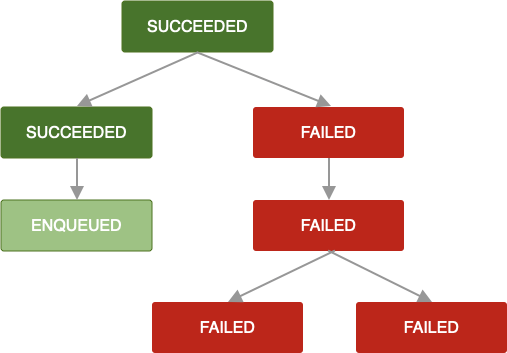
Dieselbe Logik gilt, wenn ein OneTimeWorkRequest gekündigt wird. Alle Anfragen für abhängige Aufgaben werden ebenfalls mit CANCELLED gekennzeichnet und die Aufgaben werden nicht ausgeführt.
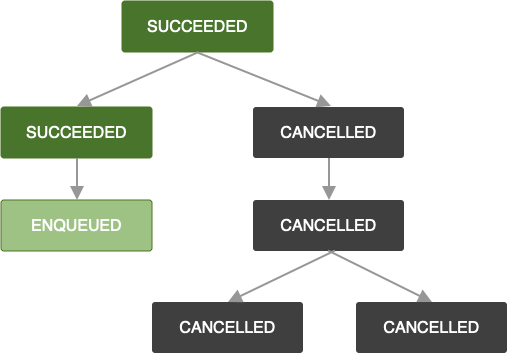
Wenn Sie einer Kette, bei der Arbeitsanfragen fehlgeschlagen oder abgebrochen wurden, weitere Arbeitsanfragen hinzufügen, werden diese ebenfalls mit FAILED bzw. CANCELLED gekennzeichnet. Wenn Sie die Arbeit einer vorhandenen Kette erweitern möchten, sehen Sie sich APPEND_OR_REPLACE in ExistingWorkPolicy an.
Beim Erstellen von Ketten von Arbeitsanfragen sollten für abhängige Arbeitsanfragen Richtlinien für Wiederholungsversuche definiert werden, damit die Arbeit immer rechtzeitig abgeschlossen wird. Fehlgeschlagene Arbeitsanfragen können zu unvollständigen Ketten und/oder einem unerwarteten Status führen.
Weitere Informationen finden Sie unter Arbeit abbrechen und beenden.