
Android Neural Networks API (NNAPI) เป็น Android C API ที่ออกแบบมาเพื่อเรียกใช้ การดำเนินการที่ต้องใช้การคำนวณจำนวนมากสำหรับแมชชีนเลิร์นนิงในอุปกรณ์ Android NNAPI ออกแบบมาเพื่อเป็นเลเยอร์พื้นฐานของฟังก์ชันการทำงานสำหรับเฟรมเวิร์กแมชชีนเลิร์นนิงระดับสูง เช่น TensorFlow Lite และ Caffe2 ซึ่งสร้างและฝึกโครงข่ายประสาทเทียม API นี้พร้อมใช้งาน ในอุปกรณ์ Android ทั้งหมดที่ใช้ Android 8.1 (ระดับ API 27) ขึ้นไป แต่เลิกใช้งานแล้วใน Android 15
NNAPI รองรับการอนุมานโดยใช้ข้อมูลจากอุปกรณ์ Android กับโมเดลที่ฝึกไว้ก่อนหน้านี้และกำหนดโดยนักพัฒนาแอป ตัวอย่างของการอนุมาน ได้แก่ การจัดประเภทรูปภาพ การคาดการณ์พฤติกรรมของผู้ใช้ และการเลือกคำตอบที่เหมาะสมสำหรับคำค้นหา
การอนุมานในอุปกรณ์มีประโยชน์หลายประการ ดังนี้
- เวลาในการตอบสนอง: คุณไม่จำเป็นต้องส่งคำขอผ่านการเชื่อมต่อเครือข่ายและรอการตอบกลับ เช่น การดำเนินการนี้อาจมีความสำคัญอย่างยิ่งสำหรับแอปพลิเคชันวิดีโอ ที่ประมวลผลเฟรมต่อเนื่องที่มาจากกล้อง
- ความพร้อมใช้งาน: แอปพลิเคชันจะทํางานแม้จะอยู่นอกพื้นที่ครอบคลุมของเครือข่าย
- ความเร็ว: ฮาร์ดแวร์ใหม่ที่ออกแบบมาเพื่อการประมวลผลโครงข่ายระบบประสาทเทียมโดยเฉพาะ ช่วยให้การคำนวณเร็วกว่า CPU แบบอเนกประสงค์เพียงอย่างเดียวอย่างเห็นได้ชัด
- ความเป็นส่วนตัว: ข้อมูลจะไม่ถูกส่งออกจากอุปกรณ์ Android
- ค่าใช้จ่าย: ไม่จำเป็นต้องมีฟาร์มเซิร์ฟเวอร์เมื่อการคำนวณทั้งหมดดำเนินการใน อุปกรณ์ Android
นอกจากนี้ นักพัฒนาแอปควรคำนึงถึงข้อแลกเปลี่ยนต่อไปนี้ด้วย
- การใช้ระบบ: การประเมินโครงข่ายประสาทเทียมต้องใช้การคำนวณจำนวนมาก ซึ่งอาจเพิ่มการใช้พลังงานแบตเตอรี่ คุณควรพิจารณา ตรวจสอบประสิทธิภาพแบตเตอรี่หากแอปของคุณมีข้อกังวลในเรื่องนี้ โดยเฉพาะ การคำนวณที่ใช้เวลานาน
- ขนาดแอปพลิเคชัน: โปรดคำนึงถึงขนาดของโมเดล โมเดลอาจใช้พื้นที่หลายเมกะไบต์ หากการรวมโมเดลขนาดใหญ่ไว้ใน APK จะส่งผลกระทบต่อผู้ใช้มากเกินไป คุณอาจพิจารณาดาวน์โหลด โมเดลหลังการติดตั้งแอป ใช้โมเดลขนาดเล็ก หรือเรียกใช้การคำนวณ ในระบบคลาวด์ NNAPI ไม่มีฟังก์ชันการทำงานสำหรับเรียกใช้โมเดลในระบบคลาวด์
ดูตัวอย่างวิธีใช้ NNAPI ได้ที่ ตัวอย่าง Android Neural Networks API
ทำความเข้าใจรันไทม์ของ Neural Networks API
NNAPI ออกแบบมาเพื่อให้ไลบรารี เฟรมเวิร์ก และเครื่องมือแมชชีนเลิร์นนิงเรียกใช้ ซึ่งช่วยให้นักพัฒนาแอปฝึกโมเดลนอกอุปกรณ์และติดตั้งใช้งานในอุปกรณ์ Android ได้ โดยปกติแล้ว แอปจะไม่ใช้ NNAPI โดยตรง แต่จะใช้เฟรมเวิร์กแมชชีนเลิร์นนิงระดับสูงกว่าแทน ซึ่งเฟรมเวิร์กเหล่านี้จะใช้ NNAPI เพื่อดำเนินการอนุมานที่เร่งด้วยฮาร์ดแวร์ในอุปกรณ์ที่รองรับได้
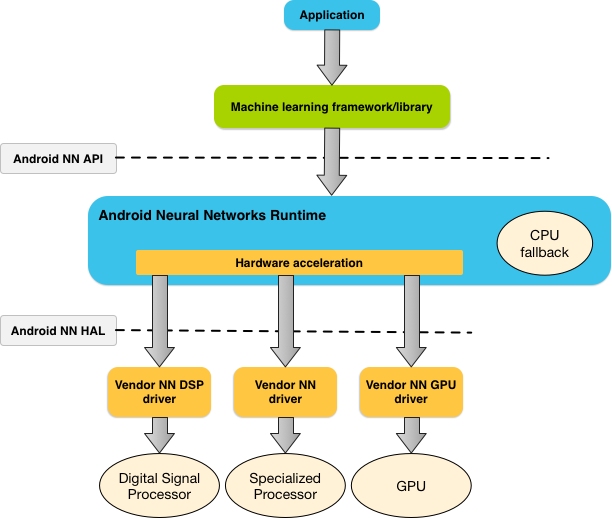
รันไทม์ของโครงข่ายระบบประสาทเทียมของ Android สามารถกระจายภาระงานการคำนวณได้อย่างมีประสิทธิภาพในโปรเซสเซอร์ในอุปกรณ์ที่มีอยู่ ซึ่งรวมถึงฮาร์ดแวร์โครงข่ายระบบประสาทเทียมเฉพาะ หน่วยประมวลผลกราฟิก (GPU) และตัวประมวลผลสัญญาณดิจิทัล (DSP) โดยอิงตามข้อกำหนดของแอปและความสามารถของฮาร์ดแวร์ในอุปกรณ์ Android
สำหรับอุปกรณ์ Android ที่ไม่มีไดรเวอร์ของผู้ให้บริการเฉพาะทาง รันไทม์ NNAPI จะดำเนินการคำขอใน CPU
รูปที่ 1 แสดงสถาปัตยกรรมระบบระดับสูงสำหรับ NNAPI
รูปแบบการเขียนโปรแกรม Neural Networks API
หากต้องการทำการคำนวณโดยใช้ NNAPI คุณต้องสร้างกราฟแบบมีทิศทางที่กำหนดการคำนวณที่จะดำเนินการก่อน กราฟการคำนวณนี้รวมกับข้อมูลอินพุต (เช่น น้ำหนักและความเอนเอียงที่ส่งต่อจากเฟรมเวิร์กแมชชีนเลิร์นนิง) จะสร้างโมเดลสำหรับการประเมินรันไทม์ของ NNAPI
NNAPI ใช้การแยกส่วนหลัก 4 อย่าง ได้แก่
- โมเดล: กราฟการคำนวณของการดำเนินการทางคณิตศาสตร์และค่าคงที่
ที่ได้จากการเรียนรู้ผ่านกระบวนการฝึก การดำเนินการเหล่านี้มีไว้สำหรับ
โครงข่ายประสาทเทียมโดยเฉพาะ ซึ่งรวมถึงการสังวัตนาการแบบ 2 มิติ (2D)
การเปิดใช้งานแบบลอจิสติก
(ซิกมอยด์)
การเปิดใช้งานแบบเชิงเส้นที่แก้ไขแล้ว
(ReLU) และอื่นๆ การสร้างโมเดลเป็นการดำเนินการแบบพร้อมกัน
เมื่อสร้างแล้ว คุณจะนำไปใช้ซ้ำในเธรดและการรวบรวมต่างๆ ได้
ใน NNAPI โมเดลจะแสดงเป็นอินสแตนซ์ของ
ANeuralNetworksModel - การคอมไพล์: แสดงการกำหนดค่าสำหรับการคอมไพล์โมเดล NNAPI เป็น
โค้ดระดับล่าง การสร้างการรวบรวมเป็นดำเนินการแบบพร้อมกัน เมื่อสร้างแล้ว คุณจะนำไปใช้ซ้ำในเธรดและการดำเนินการต่างๆ ได้ ใน
NNAPI การคอมไพล์แต่ละครั้งจะแสดงเป็นอินสแตนซ์
ANeuralNetworksCompilation - หน่วยความจำ: แสดงหน่วยความจำที่แชร์ ไฟล์ที่แมปหน่วยความจำ และบัฟเฟอร์หน่วยความจำที่คล้ายกัน
การใช้บัฟเฟอร์หน่วยความจำช่วยให้รันไทม์ NNAPI โอนข้อมูลไปยังไดรเวอร์
ได้อย่างมีประสิทธิภาพมากขึ้น โดยปกติแล้ว แอปจะสร้างบัฟเฟอร์หน่วยความจำที่แชร์ 1 รายการซึ่งมี Tensor ทั้งหมดที่จำเป็นต่อการกำหนดโมเดล นอกจากนี้ คุณยังใช้บัฟเฟอร์หน่วยความจำ
เพื่อจัดเก็บอินพุตและเอาต์พุตสำหรับอินสแตนซ์การดำเนินการได้ด้วย ใน NNAPI
บัฟเฟอร์หน่วยความจำแต่ละรายการจะแสดงเป็นอินสแตนซ์
ANeuralNetworksMemory การดำเนินการ: อินเทอร์เฟซสำหรับการใช้โมเดล NNAPI กับชุดอินพุตและรวบรวมผลลัพธ์ การดำเนินการสามารถทำได้แบบซิงโครนัสหรืออะซิงโครนัส
สำหรับการดำเนินการแบบไม่พร้อมกัน หลายเทรด สามารถรอการดำเนินการเดียวกันได้ เมื่อการดำเนินการนี้เสร็จสมบูรณ์ ระบบจะปล่อย เทรดทั้งหมด
ใน NNAPI การดำเนินการแต่ละครั้งจะแสดงเป็นอินสแตนซ์
ANeuralNetworksExecution
รูปที่ 2 แสดงโฟลว์การเขียนโปรแกรมพื้นฐาน
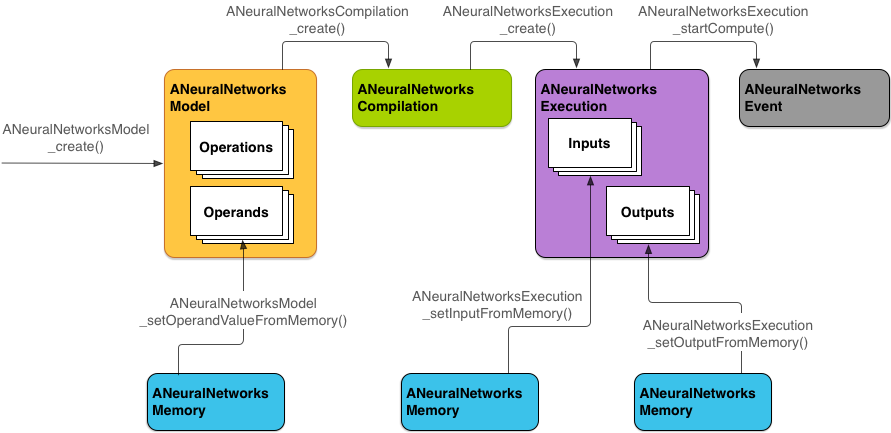
ส่วนที่เหลือของส่วนนี้จะอธิบายขั้นตอนการตั้งค่าโมเดล NNAPI เพื่อ ทำการคำนวณ คอมไพล์โมเดล และเรียกใช้โมเดลที่คอมไพล์แล้ว
ให้สิทธิ์เข้าถึงข้อมูลฝึกฝน
โดยปกติแล้ว ระบบจะจัดเก็บข้อมูลน้ำหนักและความเอนเอียงที่ฝึกแล้วไว้ในไฟล์ หากต้องการให้รันไทม์ NNAPI เข้าถึงข้อมูลนี้ได้อย่างมีประสิทธิภาพ ให้สร้างอินสแตนซ์
ANeuralNetworksMemory
โดยเรียกใช้ฟังก์ชัน
ANeuralNetworksMemory_createFromFd()
และส่งตัวอธิบายไฟล์ของไฟล์ข้อมูลที่เปิด นอกจากนี้ คุณยังระบุแฟล็กการป้องกันหน่วยความจำและออฟเซ็ตที่รีเจียนหน่วยความจำที่แชร์เริ่มต้นในไฟล์ได้ด้วย
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
แม้ว่าในตัวอย่างนี้เราจะใช้ANeuralNetworksMemory
อินสแตนซ์เดียวสำหรับน้ำหนักทั้งหมด แต่ก็สามารถใช้ANeuralNetworksMemoryอินสแตนซ์มากกว่า 1 รายการสำหรับหลายไฟล์ได้
ใช้บัฟเฟอร์ฮาร์ดแวร์เนทีฟ
คุณใช้บัฟเฟอร์ฮาร์ดแวร์ดั้งเดิมสำหรับอินพุต เอาต์พุต และค่าตัวถูกดำเนินการคงที่ของโมเดลได้ ในบางกรณี ตัวเร่ง NNAPI สามารถเข้าถึงออบเจ็กต์
AHardwareBuffer
ได้โดยไม่ต้องให้ไดรเวอร์คัดลอกข้อมูล AHardwareBuffer มีการกำหนดค่าที่แตกต่างกันมากมาย และตัวเร่ง NNAPI บางตัวอาจไม่รองรับการกำหนดค่าทั้งหมดเหล่านี้ เนื่องจากข้อจำกัดนี้ โปรดดูข้อจำกัด
ที่ระบุไว้ในเอกสารอ้างอิงของANeuralNetworksMemory_createFromAHardwareBuffer
และทดสอบล่วงหน้าในอุปกรณ์เป้าหมายเพื่อให้มั่นใจว่าการคอมไพล์และการดำเนินการ
ที่ใช้ AHardwareBuffer จะทำงานตามที่คาดไว้ โดยใช้การกำหนดอุปกรณ์เพื่อระบุตัวเร่ง
หากต้องการอนุญาตให้รันไทม์ NNAPI เข้าถึงออบเจ็กต์ AHardwareBuffer ให้สร้างอินสแตนซ์ ANeuralNetworksMemory โดยเรียกใช้ฟังก์ชัน ANeuralNetworksMemory_createFromAHardwareBuffer และส่งออบเจ็กต์ AHardwareBuffer ดังที่แสดงในตัวอย่างโค้ดต่อไปนี้
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
เมื่อ NNAPI ไม่จำเป็นต้องเข้าถึงออบเจ็กต์ AHardwareBuffer อีกต่อไป ให้ปล่อยอินสแตนซ์ ANeuralNetworksMemory ที่เกี่ยวข้อง
ANeuralNetworksMemory_free(mem2);
หมายเหตุ:
- คุณใช้
AHardwareBufferได้เฉพาะกับบัฟเฟอร์ทั้งหมดเท่านั้น และใช้ร่วมกับ พารามิเตอร์ARectไม่ได้ - รันไทม์ NNAPI จะไม่ล้างบัฟเฟอร์ คุณต้องตรวจสอบว่าบัฟเฟอร์อินพุตและเอาต์พุตสามารถเข้าถึงได้ก่อนกำหนดเวลาการดำเนินการ
- ไม่รองรับตัวอธิบายไฟล์ของ sync fence
- สำหรับ
AHardwareBufferที่มี รูปแบบเฉพาะของผู้ให้บริการและบิตการใช้งาน การติดตั้งใช้งานของผู้ให้บริการ จะเป็นตัวกำหนดว่าไคลเอ็นต์หรือไดรเวอร์เป็นผู้รับผิดชอบในการล้าง แคช
รุ่น
โมเดลคือหน่วยพื้นฐานของการคำนวณใน NNAPI แต่ละโมเดลจะกำหนดโดยตัวถูกดำเนินการและการดำเนินการอย่างน้อย 1 รายการ
ตัวถูกดำเนินการ
ตัวถูกดำเนินการคือออบเจ็กต์ข้อมูลที่ใช้ในการกำหนดกราฟ ซึ่งรวมถึงอินพุต และเอาต์พุตของโมเดล โหนดกลางที่มีข้อมูลที่ ไหลจากการดำเนินการหนึ่งไปยังอีกการดำเนินการหนึ่ง และค่าคงที่ที่ส่งไปยัง การดำเนินการเหล่านี้
ตัวถูกดำเนินการที่เพิ่มลงในโมเดล NNAPI ได้มี 2 ประเภท ได้แก่ สเกลาร์และ เทนเซอร์
สเกลาร์แสดงค่าเดียว NNAPI รองรับค่าสเกลาร์ในรูปแบบบูลีน จุดลอยตัว 16 บิต จุดลอยตัว 32 บิต จำนวนเต็ม 32 บิต และจำนวนเต็ม 32 บิตที่ไม่ใช่ค่าลบ
การดำเนินการส่วนใหญ่ใน NNAPI เกี่ยวข้องกับเทนเซอร์ เทนเซอร์คืออาร์เรย์ n มิติ NNAPI รองรับเทนเซอร์ที่มีจุดลอยตัว 16 บิต จุดลอยตัว 32 บิต Quantized 8 บิต Quantized 16 บิต จำนวนเต็ม 32 บิต และค่าบูลีน 8 บิต
ตัวอย่างเช่น รูปที่ 3 แสดงโมเดลที่มีการดำเนินการ 2 อย่าง ได้แก่ การบวก ตามด้วยการคูณ โมเดลรับ Tensor อินพุตและสร้าง Tensor เอาต์พุต 1 รายการ
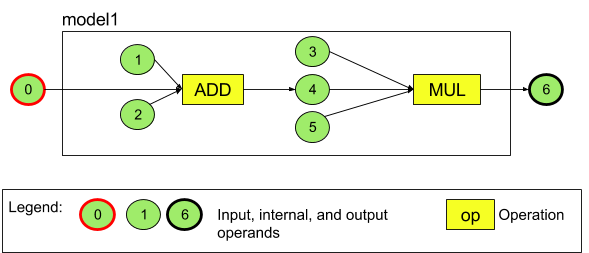
โมเดลด้านบนมีตัวถูกดำเนินการ 7 ตัว ตัวถูกดำเนินการเหล่านี้จะระบุโดยนัยตามดัชนีของลำดับที่เพิ่มลงในโมเดล ตัวถูกดำเนินการแรก ที่เพิ่มจะมีดัชนี 0 ตัวถูกดำเนินการที่สองจะมีดัชนี 1 และอื่นๆ ตัวถูกดำเนินการ 1, 2, 3 และ 5 เป็นตัวถูกดำเนินการคงที่
ลำดับที่คุณเพิ่มตัวถูกดำเนินการไม่มีผล เช่น ตัวถูกดำเนินการเอาต์พุตของโมเดล อาจเป็นตัวแรกที่เพิ่ม ส่วนที่สำคัญคือการใช้ค่าดัชนีที่ถูกต้องเมื่ออ้างอิงถึงตัวถูกดำเนินการ
ตัวถูกดำเนินการมีประเภท โดยจะระบุเมื่อมีการเพิ่มลงในโมเดล
ตัวถูกดำเนินการไม่สามารถใช้เป็นทั้งอินพุตและเอาต์พุตของโมเดล
ตัวถูกดำเนินการทุกตัวต้องเป็นอินพุตของโมเดล ค่าคงที่ หรือตัวถูกดำเนินการเอาต์พุตของการดำเนินการ เพียงรายการเดียว
ดูข้อมูลเพิ่มเติมเกี่ยวกับการใช้ตัวถูกดำเนินการได้ที่ ข้อมูลเพิ่มเติมเกี่ยวกับตัวถูกดำเนินการ
การดำเนินการ
การดำเนินการจะระบุการคำนวณที่จะดำเนินการ การดำเนินการแต่ละอย่างประกอบด้วยองค์ประกอบต่อไปนี้
- ประเภทการดำเนินการ (เช่น การบวก การคูณ การสังวัตนาการ)
- รายการดัชนีของตัวถูกดำเนินการที่การดำเนินการใช้เป็นอินพุต และ
- รายการดัชนีของตัวถูกดำเนินการที่การดำเนินการใช้สำหรับเอาต์พุต
ลำดับในรายการเหล่านี้มีความสำคัญ โปรดดูอินพุตที่คาดไว้และเอาต์พุตของแต่ละประเภทการดำเนินการในเอกสารอ้างอิง API ของ NNAPI
คุณต้องเพิ่มตัวถูกดำเนินการที่การดำเนินการใช้หรือสร้างลงในโมเดล ก่อนที่จะเพิ่มการดำเนินการ
ลำดับที่คุณเพิ่มการดำเนินการไม่มีผล NNAPI อาศัย การอ้างอิงที่สร้างขึ้นโดยกราฟการคำนวณของตัวถูกดำเนินการและการดำเนินการเพื่อ กำหนดลำดับการดำเนินการ
การดำเนินการที่ NNAPI รองรับจะสรุปไว้ในตารางด้านล่าง
ปัญหาที่ทราบในระดับ API 28: เมื่อส่ง
ANEURALNETWORKS_TENSOR_QUANT8_ASYMM
Tensor ไปยังการดำเนินการ
ANEURALNETWORKS_PAD
ซึ่งพร้อมใช้งานใน Android 9 (ระดับ API 28) ขึ้นไป เอาต์พุตจาก NNAPI อาจไม่ตรงกับเอาต์พุตจากเฟรมเวิร์กแมชชีนเลิร์นนิงระดับสูงกว่า เช่น TensorFlow Lite คุณ
ควรส่งเฉพาะ
ANEURALNETWORKS_TENSOR_FLOAT32 แทน
ปัญหานี้ได้รับการแก้ไขแล้วใน Android 10 (ระดับ API 29) ขึ้นไป
สร้างโมเดล
ในตัวอย่างต่อไปนี้ เราจะสร้างโมเดล 2 การดำเนินการที่พบในรูปที่ 3
หากต้องการสร้างโมเดล ให้ทำตามขั้นตอนต่อไปนี้
เรียกใช้ฟังก์ชัน
ANeuralNetworksModel_create()เพื่อกำหนดโมเดลที่ว่างเปล่าANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
เพิ่มตัวถูกดำเนินการลงในโมเดลโดยเรียกใช้
ANeuralNetworks_addOperand()โดยจะกำหนดประเภทข้อมูลโดยใช้โครงสร้างข้อมูลANeuralNetworksOperandType// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6สําหรับตัวถูกดําเนินการที่มีค่าคงที่ เช่น น้ำหนักและอคติที่แอปได้รับจากกระบวนการฝึก ให้ใช้ฟังก์ชัน
ANeuralNetworksModel_setOperandValue()และANeuralNetworksModel_setOperandValueFromMemory()ในตัวอย่างต่อไปนี้ เราจะตั้งค่าคงที่จากไฟล์ข้อมูลฝึกฝน ที่สอดคล้องกับบัฟเฟอร์หน่วยความจำที่เราสร้างขึ้นในให้สิทธิ์เข้าถึง ข้อมูลฝึกฝน
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));สําหรับการดําเนินการแต่ละอย่างในกราฟแบบมีทิศทางที่คุณต้องการคํานวณ ให้เพิ่ม การดําเนินการลงในโมเดลโดยเรียกใช้ฟังก์ชัน
ANeuralNetworksModel_addOperation()แอปของคุณต้องระบุข้อมูลต่อไปนี้เป็นพารามิเตอร์ในการเรียกใช้
- ประเภทการดำเนินการ
- จำนวนค่าอินพุต
- อาร์เรย์ของดัชนีสำหรับตัวถูกดำเนินการอินพุต
- จำนวนค่าเอาต์พุต
- อาร์เรย์ของดัชนีสำหรับตัวถูกดำเนินการเอาต์พุต
โปรดทราบว่าตัวถูกดำเนินการไม่สามารถใช้เป็นทั้งอินพุตและเอาต์พุตของการดำเนินการเดียวกันได้
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);ระบุตัวถูกดำเนินการที่โมเดลควรใช้เป็นอินพุตและเอาต์พุตโดย เรียกใช้ฟังก์ชัน
ANeuralNetworksModel_identifyInputsAndOutputs()// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
ระบุโดยไม่บังคับว่าอนุญาตให้คำนวณ
ANEURALNETWORKS_TENSOR_FLOAT32ด้วยช่วงหรือความแม่นยำต่ำเท่ากับของ รูปแบบจุดลอยตัว 16 บิต IEEE 754 หรือไม่โดยการเรียกใช้ANeuralNetworksModel_relaxComputationFloat32toFloat16()เรียกใช้
ANeuralNetworksModel_finish()เพื่อสรุปคำจำกัดความของโมเดล หากไม่มีข้อผิดพลาด ฟังก์ชันนี้จะแสดงรหัสผลลัพธ์เป็นANEURALNETWORKS_NO_ERRORANeuralNetworksModel_finish(model);
เมื่อสร้างโมเดลแล้ว คุณจะคอมไพล์โมเดลได้กี่ครั้งก็ได้และเรียกใช้การคอมไพล์แต่ละครั้งได้กี่ครั้งก็ได้
ควบคุมโฟลว์
หากต้องการรวมโฟลว์การควบคุมในโมเดล NNAPI ให้ทำดังนี้
สร้างกราฟย่อยการดำเนินการที่เกี่ยวข้อง (กราฟย่อย
thenและelseสำหรับคำสั่งIFกราฟย่อยconditionและbodyสำหรับลูปWHILE) เป็นโมเดลANeuralNetworksModel*แบบสแตนด์อโลนANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
สร้างตัวถูกดำเนินการที่อ้างอิงโมเดลเหล่านั้นภายในโมเดลที่มี โฟลว์ควบคุม:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
เพิ่มการดำเนินการโฟลว์ควบคุม
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
การรวบรวม
ขั้นตอนการคอมไพล์จะกำหนดว่าโปรเซสเซอร์ใดที่จะใช้เรียกใช้โมเดล และขอให้ไดรเวอร์ที่เกี่ยวข้องเตรียมพร้อมสำหรับการเรียกใช้ ซึ่งอาจรวมถึงการสร้างรหัสเครื่องที่เฉพาะเจาะจงสำหรับโปรเซสเซอร์ที่โมเดลจะทำงาน
หากต้องการคอมไพล์โมเดล ให้ทำตามขั้นตอนต่อไปนี้
เรียกใช้ฟังก์ชัน
ANeuralNetworksCompilation_create()เพื่อสร้างอินสแตนซ์การคอมไพล์ใหม่// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
คุณสามารถใช้การกำหนดอุปกรณ์เพื่อเลือกอุปกรณ์ที่จะใช้ดำเนินการได้อย่างชัดเจน (ไม่บังคับ)
คุณเลือกที่จะมีอิทธิพลต่อวิธีที่รันไทม์จะแลกเปลี่ยนระหว่างการใช้พลังงานแบตเตอรี่ และความเร็วในการดำเนินการได้ โดยโทรไปที่
ANeuralNetworksCompilation_setPreference()// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
ค่ากำหนดที่คุณระบุได้มีดังนี้
ANEURALNETWORKS_PREFER_LOW_POWER: ควรดำเนินการในลักษณะที่ลดการใช้แบตเตอรี่ ซึ่งเป็นสิ่งที่ควรทำ สำหรับการคอมไพล์ที่ดำเนินการบ่อยๆANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: ต้องการให้แสดงคำตอบเดียวโดยเร็วที่สุด แม้ว่าวิธีนี้จะทำให้ ใช้พลังงานมากขึ้นก็ตาม โดยตัวเลือกนี้คือค่าเริ่มต้นANEURALNETWORKS_PREFER_SUSTAINED_SPEED: ควรเพิ่มอัตราการส่งข้อมูลของเฟรมต่อเนื่องให้สูงสุด เช่น เมื่อ ประมวลผลเฟรมต่อเนื่องที่มาจากกล้อง
คุณเลือกตั้งค่าการแคชการคอมไพล์ได้โดยเรียกใช้
ANeuralNetworksCompilation_setCaching// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
ใช้
getCodeCacheDir()สำหรับcacheDirtokenที่ระบุต้องไม่ซ้ำกันสำหรับแต่ละโมเดลภายในแอปพลิเคชันกำหนดนิยามการคอมไพล์ให้เสร็จสมบูรณ์โดยเรียกใช้
ANeuralNetworksCompilation_finish()หากไม่มีข้อผิดพลาด ฟังก์ชันนี้จะแสดงรหัสผลลัพธ์เป็นANEURALNETWORKS_NO_ERRORANeuralNetworksCompilation_finish(compilation);
การค้นหาและการกำหนดอุปกรณ์
ในอุปกรณ์ Android ที่ใช้ Android 10 (ระดับ API 29) ขึ้นไป NNAPI มีฟังก์ชันที่ช่วยให้ไลบรารีและแอปเฟรมเวิร์กแมชชีนเลิร์นนิงรับข้อมูลเกี่ยวกับอุปกรณ์ที่พร้อมใช้งานและระบุอุปกรณ์ที่จะใช้สำหรับการดำเนินการได้ การให้ข้อมูลเกี่ยวกับอุปกรณ์ที่พร้อมใช้งานจะช่วยให้แอปได้รับ ไดรเวอร์เวอร์ชันที่แน่นอนซึ่งพบในอุปกรณ์เพื่อหลีกเลี่ยงปัญหาความ เข้ากันไม่ได้ที่ทราบ การให้ความสามารถแก่แอปในการระบุอุปกรณ์ที่จะใช้เรียกใช้ส่วนต่างๆ ของโมเดลจะช่วยให้แอปได้รับการเพิ่มประสิทธิภาพสำหรับอุปกรณ์ Android ที่นำไปใช้งาน
การค้นหาอุปกรณ์
ใช้
ANeuralNetworks_getDeviceCount
เพื่อรับจำนวนอุปกรณ์ที่พร้อมใช้งาน สำหรับอุปกรณ์แต่ละเครื่อง ให้ใช้
ANeuralNetworks_getDevice
เพื่อตั้งค่าอินสแตนซ์ ANeuralNetworksDevice เป็นการอ้างอิงถึงอุปกรณ์นั้น
เมื่อมีข้อมูลอ้างอิงอุปกรณ์แล้ว คุณจะดูข้อมูลเพิ่มเติมเกี่ยวกับ อุปกรณ์นั้นได้โดยใช้ฟังก์ชันต่อไปนี้
ANeuralNetworksDevice_getFeatureLevelANeuralNetworksDevice_getNameANeuralNetworksDevice_getTypeANeuralNetworksDevice_getVersion
การมอบหมายอุปกรณ์
ใช้
ANeuralNetworksModel_getSupportedOperationsForDevices
เพื่อดูว่าการดำเนินการใดของโมเดลที่สามารถเรียกใช้ในอุปกรณ์ที่เฉพาะเจาะจงได้
หากต้องการควบคุมตัวเร่งความเร็วที่จะใช้ในการดำเนินการ ให้เรียกใช้
ANeuralNetworksCompilation_createForDevices
แทน ANeuralNetworksCompilation_create
ใช้ANeuralNetworksCompilationออบเจ็กต์ที่ได้ตามปกติ
ฟังก์ชันจะแสดงข้อผิดพลาดหากโมเดลที่ระบุมีการดำเนินการที่อุปกรณ์ที่เลือกไม่รองรับ
หากระบุอุปกรณ์หลายเครื่อง รันไทม์จะมีหน้าที่กระจาย งานไปยังอุปกรณ์ต่างๆ
การใช้งาน CPU ของ NNAPI จะแสดงด้วย
ANeuralNetworksDevice ที่มีชื่อ nnapi-reference และประเภท
ANEURALNETWORKS_DEVICE_TYPE_CPU เช่นเดียวกับอุปกรณ์อื่นๆ เมื่อเรียกใช้
ANeuralNetworksCompilation_createForDevices ระบบจะไม่ใช้การติดตั้งใช้งาน CPU
เพื่อจัดการกรณีที่คอมไพล์และเรียกใช้โมเดลไม่สำเร็จ
แอปพลิเคชันมีหน้าที่แบ่งพาร์ติชันโมเดลออกเป็นโมเดลย่อยที่สามารถทำงานบนอุปกรณ์ที่ระบุได้ แอปพลิเคชันที่ไม่จำเป็นต้องทำการแบ่งพาร์ติชันด้วยตนเอง
ควรเรียกใช้ANeuralNetworksCompilation_create
ที่ง่ายกว่าต่อไปเพื่อใช้อุปกรณ์ที่มีอยู่ทั้งหมด (รวมถึง CPU) เพื่อเร่งความเร็วโมเดล หากอุปกรณ์ที่คุณระบุไม่รองรับโมเดลอย่างเต็มที่
โดยใช้ ANeuralNetworksCompilation_createForDevices
ระบบจะแสดงผล ANEURALNETWORKS_BAD_DATA
การแบ่งพาร์ติชันโมเดล
เมื่อมีอุปกรณ์หลายเครื่องที่ใช้โมเดลได้ รันไทม์ NNAPI จะกระจายงานไปยังอุปกรณ์ต่างๆ
เช่น หากมีการจัดหาอุปกรณ์มากกว่า 1 เครื่องให้แก่ ANeuralNetworksCompilation_createForDevices ระบบจะพิจารณาอุปกรณ์ที่ระบุทั้งหมดเมื่อจัดสรรงาน โปรดทราบว่า หากอุปกรณ์ CPU ไม่อยู่ในรายการ ระบบจะปิดใช้การดำเนินการ CPU เมื่อใช้ ANeuralNetworksCompilation_create
ระบบจะพิจารณาอุปกรณ์ที่มีอยู่ทั้งหมด รวมถึง CPU
การกระจายจะทำโดยการเลือกจากรายการอุปกรณ์ที่พร้อมใช้งาน สำหรับการดำเนินการแต่ละอย่างในโมเดล อุปกรณ์ที่รองรับการดำเนินการ และการประกาศประสิทธิภาพที่ดีที่สุด เช่น เวลาในการดำเนินการที่เร็วที่สุดหรือการใช้พลังงานต่ำที่สุด ขึ้นอยู่กับค่ากำหนดการดำเนินการที่ไคลเอ็นต์ระบุ อัลกอริทึมการแบ่งพาร์ติชันนี้ไม่ได้คำนึงถึงประสิทธิภาพที่อาจเกิดขึ้น
เนื่องจาก IO ระหว่างโปรเซสเซอร์ต่างๆ ดังนั้นเมื่อ
ระบุโปรเซสเซอร์หลายตัว (ไม่ว่าจะโดยชัดแจ้งเมื่อใช้
ANeuralNetworksCompilation_createForDevices หรือโดยนัยเมื่อใช้
ANeuralNetworksCompilation_create) สิ่งสำคัญคือต้องสร้างโปรไฟล์แอปพลิเคชันที่ได้
หากต้องการทําความเข้าใจวิธีที่ NNAPI แบ่งพาร์ติชันโมเดล ให้ตรวจสอบ
บันทึกของ Android เพื่อหาข้อความ (ที่ระดับ INFO ที่มีแท็ก ExecutionPlan)
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name คือชื่อที่สื่อความหมายของการดำเนินการในกราฟ และ device-index คือดัชนีของอุปกรณ์ที่ต้องการในรายการอุปกรณ์
รายการนี้คืออินพุตที่ระบุให้กับ ANeuralNetworksCompilation_createForDevices
หรือหากใช้ ANeuralNetworksCompilation_createForDevices รายการอุปกรณ์
ที่แสดงเมื่อทำซ้ำอุปกรณ์ทั้งหมดโดยใช้ ANeuralNetworks_getDeviceCount และ
ANeuralNetworks_getDevice
ข้อความ (ที่ระดับ INFO พร้อมแท็ก ExecutionPlan):
ModelBuilder::partitionTheWork: only one best device: device-name
ข้อความนี้ระบุว่ากราฟทั้งหมดได้รับการเร่งความเร็วในอุปกรณ์
device-name
การลงมือปฏิบัติ
ขั้นตอนการดำเนินการจะใช้โมเดลกับชุดอินพุตและจัดเก็บเอาต์พุตการคำนวณไว้ในบัฟเฟอร์ของผู้ใช้หรือพื้นที่หน่วยความจำอย่างน้อย 1 รายการที่แอปของคุณจัดสรร
หากต้องการเรียกใช้โมเดลที่คอมไพล์แล้ว ให้ทำตามขั้นตอนต่อไปนี้
เรียกใช้ฟังก์ชัน
ANeuralNetworksExecution_create()เพื่อสร้างอินสแตนซ์การดำเนินการใหม่// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
ระบุตำแหน่งที่แอปอ่านค่าอินพุตสำหรับการคำนวณ แอปของคุณ สามารถอ่านค่าอินพุตจากบัฟเฟอร์ผู้ใช้หรือพื้นที่หน่วยความจำที่จัดสรร ได้โดยการเรียก
ANeuralNetworksExecution_setInput()หรือANeuralNetworksExecution_setInputFromMemory()ตามลำดับ// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
ระบุตำแหน่งที่แอปเขียนค่าเอาต์พุต แอปของคุณสามารถเขียนค่าเอาต์พุตไปยัง บัฟเฟอร์ผู้ใช้หรือพื้นที่หน่วยความจำที่จัดสรรได้โดยการเรียกใช้
ANeuralNetworksExecution_setOutput()หรือANeuralNetworksExecution_setOutputFromMemory()ตามลำดับ// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
กำหนดเวลาการดำเนินการให้เริ่มต้นโดยการเรียกใช้ฟังก์ชัน
ANeuralNetworksExecution_startCompute()หากไม่มีข้อผิดพลาด ฟังก์ชันนี้จะแสดงรหัสผลลัพธ์เป็นANEURALNETWORKS_NO_ERROR// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
เรียกใช้ฟังก์ชัน
ANeuralNetworksEvent_wait()เพื่อรอให้การดำเนินการเสร็จสมบูรณ์ หากการดำเนินการสำเร็จ ฟังก์ชันนี้จะแสดงรหัสผลลัพธ์เป็นANEURALNETWORKS_NO_ERRORการรอสามารถทำได้ในเทรดอื่นที่ไม่ใช่เทรดที่เริ่มการดำเนินการ// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
คุณเลือกใช้ชุดอินพุตอื่นกับโมเดลที่คอมไพล์ได้โดย ใช้อินสแตนซ์การคอมไพล์เดียวกันเพื่อสร้างอินสแตนซ์
ANeuralNetworksExecutionใหม่// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
การดำเนินการแบบซิงโครนัส
การดำเนินการแบบอะซิงโครนัสจะใช้เวลาในการสร้างและซิงโครไนซ์เธรด นอกจากนี้ เวลาในการตอบสนองยังอาจแตกต่างกันอย่างมาก โดยความล่าช้าที่ยาวนานที่สุดอาจนานถึง 500 ไมโครวินาทีระหว่างเวลาที่เทรดได้รับการแจ้งเตือนหรือปลุกกับเวลาที่เทรดผูกกับคอร์ CPU ในที่สุด
หากต้องการปรับปรุงเวลาในการตอบสนอง คุณสามารถสั่งให้แอปพลิเคชันทำการเรียกใช้การอนุมานแบบซิงโครนัสไปยังรันไทม์แทนได้ การเรียกนั้นจะแสดงผลเมื่อการอนุมานเสร็จสมบูรณ์แล้วเท่านั้น แทนที่จะแสดงผลเมื่อเริ่มการอนุมาน แทนที่จะเรียกใช้
ANeuralNetworksExecution_startCompute
เพื่อเรียกการอนุมานแบบอะซิงโครนัสไปยังรันไทม์ แอปพลิเคชันจะเรียกใช้
ANeuralNetworksExecution_compute
เพื่อเรียกแบบซิงโครนัสไปยังรันไทม์ การโทรไปยัง
ANeuralNetworksExecution_compute จะไม่ใช้ ANeuralNetworksEvent และ
จะไม่จับคู่กับการโทรไปยัง ANeuralNetworksEvent_wait
การดำเนินการแบบกลุ่ม
ในอุปกรณ์ Android ที่ใช้ Android 10 (ระดับ API 29) ขึ้นไป NNAPI รองรับการดำเนินการแบบกลุ่ม ผ่านออบเจ็กต์ ANeuralNetworksBurst การดำเนินการแบบกลุ่มคือลำดับการดำเนินการของการคอมไพล์เดียวกัน
ซึ่งเกิดขึ้นอย่างรวดเร็ว เช่น การดำเนินการในเฟรมของการจับภาพจากกล้อง
หรือตัวอย่างเสียงที่ต่อเนื่องกัน การใช้ออบเจ็กต์ ANeuralNetworksBurst อาจ
ทำให้การดำเนินการเร็วขึ้น เนื่องจากเป็นการระบุให้ตัวเร่งทราบว่าอาจมีการ
นำทรัพยากรกลับมาใช้ซ้ำระหว่างการดำเนินการ และตัวเร่งควรอยู่ใน
สถานะที่มีประสิทธิภาพสูงตลอดระยะเวลาของ Burst
ANeuralNetworksBurst จะทําให้เกิดการเปลี่ยนแปลงเพียงเล็กน้อยในเส้นทางการดําเนินการปกติ
คุณสร้างออบเจ็กต์การระเบิดโดยใช้
ANeuralNetworksBurst_create
ดังที่แสดงในข้อมูลโค้ดต่อไปนี้
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
การดำเนินการแบบกลุ่มจะเป็นแบบซิงโครนัส อย่างไรก็ตาม แทนที่จะใช้
ANeuralNetworksExecution_compute
เพื่อทำการอนุมานแต่ละครั้ง คุณจะจับคู่ออบเจ็กต์ ANeuralNetworksExecution
ต่างๆ กับ ANeuralNetworksBurst เดียวกันในการเรียกฟังก์ชัน
ANeuralNetworksExecution_burstCompute
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
ปลดปล่อยออบเจ็กต์ ANeuralNetworksBurst ด้วย
ANeuralNetworksBurst_free
เมื่อไม่ต้องการใช้งานแล้ว
// Cleanup ANeuralNetworksBurst_free(burst);
คิวคำสั่งแบบไม่พร้อมกันและการดำเนินการที่จำกัด
ใน Android 11 ขึ้นไป NNAPI รองรับอีกวิธีในการกำหนดเวลา
การดำเนินการแบบอะซิงโครนัสผ่านเมธอด
ANeuralNetworksExecution_startComputeWithDependencies()
เมื่อใช้วิธีนี้ การดำเนินการจะรอให้ระบบส่งสัญญาณเหตุการณ์ที่ขึ้นอยู่กับเหตุการณ์นั้นทั้งหมด
ก่อนที่จะเริ่มการประเมิน เมื่อการดำเนินการ
เสร็จสมบูรณ์และเอาต์พุตพร้อมใช้งานแล้ว ระบบจะส่งสัญญาณเหตุการณ์ที่ส่งคืน
เหตุการณ์อาจได้รับการสนับสนุนโดยรั้วการซิงค์ ทั้งนี้ขึ้นอยู่กับอุปกรณ์ที่จัดการการดำเนินการ คุณ
ต้องเรียกใช้
ANeuralNetworksEvent_wait()
เพื่อรอเหตุการณ์และกู้คืนทรัพยากรที่การดำเนินการใช้ คุณ
สามารถนําเข้าฟันดาบการซิงค์ไปยังออบเจ็กต์เหตุการณ์ได้โดยใช้
ANeuralNetworksEvent_createFromSyncFenceFd()
และส่งออกฟันดาบการซิงค์จากออบเจ็กต์เหตุการณ์ได้โดยใช้
ANeuralNetworksEvent_getSyncFenceFd()
เอาต์พุตที่มีขนาดแบบไดนามิก
หากต้องการรองรับโมเดลที่ขนาดเอาต์พุตขึ้นอยู่กับข้อมูลอินพุต
กล่าวคือ ไม่สามารถกำหนดขนาดได้ในเวลาที่เรียกใช้โมเดล
ให้ใช้
ANeuralNetworksExecution_getOutputOperandRank
และ
ANeuralNetworksExecution_getOutputOperandDimensions
ตัวอย่างโค้ดต่อไปนี้แสดงวิธีดำเนินการ
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
ล้างข้อมูล
ขั้นตอนการล้างข้อมูลจะจัดการการปล่อยทรัพยากรภายในที่ใช้สำหรับการคำนวณ
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
การจัดการข้อผิดพลาดและการสำรองข้อมูล CPU
หากเกิดข้อผิดพลาดระหว่างการแบ่งพาร์ติชัน หากไดรเวอร์คอมไพล์โมเดล (ชิ้นส่วนของ) ไม่สำเร็จ หรือหากไดรเวอร์เรียกใช้โมเดล (ชิ้นส่วนของ) ที่คอมไพล์แล้วไม่สำเร็จ NNAPI อาจกลับไปใช้การใช้งาน CPU ของตัวเองสำหรับ การดำเนินการอย่างน้อย 1 รายการ
หากไคลเอ็นต์ NNAPI มีการดำเนินการเวอร์ชันที่เพิ่มประสิทธิภาพแล้ว (เช่น TFLite) การปิดใช้การสำรองข้อมูล CPU และจัดการข้อผิดพลาดด้วยการติดตั้งใช้งานการดำเนินการที่เพิ่มประสิทธิภาพของไคลเอ็นต์อาจเป็นประโยชน์
ใน Android 10 หากมีการคอมไพล์โดยใช้
ANeuralNetworksCompilation_createForDevices ระบบจะปิดใช้การสำรองข้อมูล CPU
ใน Android P การดำเนินการ NNAPI จะกลับไปใช้ CPU หากการดำเนินการในไดรเวอร์ล้มเหลว
และยังใช้ได้กับ Android 10 เมื่อใช้ ANeuralNetworksCompilation_create แทน ANeuralNetworksCompilation_createForDevices ด้วย
การดำเนินการครั้งแรกจะกลับไปใช้พาร์ติชันเดียว และหากยังคง ล้มเหลว ระบบจะลองใช้โมเดลทั้งหมดอีกครั้งใน CPU
หากการแบ่งพาร์ติชันหรือการคอมไพล์ล้มเหลว ระบบจะลองใช้โมเดลทั้งหมดใน CPU
ในบางกรณี ระบบจะไม่รองรับการดำเนินการบางอย่างใน CPU และในสถานการณ์ดังกล่าว การคอมไพล์หรือการดำเนินการจะล้มเหลวแทนที่จะย้อนกลับ
แม้หลังจากปิดใช้การสำรองข้อมูล CPU แล้ว ก็อาจยังมีการดำเนินการในโมเดล
ที่กำหนดเวลาไว้ใน CPU หาก CPU อยู่ในรายการโปรเซสเซอร์ที่จัดหาให้แก่ ANeuralNetworksCompilation_createForDevices และเป็นโปรเซสเซอร์เดียวที่รองรับการดำเนินการเหล่านั้น หรือเป็นโปรเซสเซอร์ที่อ้างว่ามีประสิทธิภาพดีที่สุดสำหรับการดำเนินการเหล่านั้น ระบบจะเลือกให้เป็นตัวดำเนินการหลัก (ไม่ใช่ตัวดำเนินการสำรอง)
หากต้องการให้มั่นใจว่าจะไม่มีการดำเนินการ CPU ให้ใช้ ANeuralNetworksCompilation_createForDevices
ขณะยกเว้น nnapi-reference จากรายการอุปกรณ์
ตั้งแต่ Android P เป็นต้นไป คุณจะปิดใช้การสำรองข้อมูลในเวลาที่เรียกใช้ในบิลด์ DEBUG ได้โดยตั้งค่าพร็อพเพอร์ตี้ debug.nn.partition เป็น 2
โดเมนหน่วยความจำ
ใน Android 11 ขึ้นไป NNAPI รองรับโดเมนหน่วยความจำที่จัดเตรียมอินเทอร์เฟซตัวจัดสรร สำหรับหน่วยความจำแบบทึบแสง ซึ่งจะช่วยให้แอปพลิเคชันส่งหน่วยความจำดั้งเดิมของอุปกรณ์ ข้ามการดำเนินการได้ เพื่อให้ NNAPI ไม่ต้องคัดลอกหรือแปลงข้อมูล โดยไม่จำเป็นเมื่อดำเนินการต่อเนื่องในไดรเวอร์เดียวกัน
ฟีเจอร์โดเมนหน่วยความจำมีไว้สำหรับเทนเซอร์ที่ส่วนใหญ่เป็นภายในไดรเวอร์และไม่จำเป็นต้องเข้าถึงฝั่งไคลเอ็นต์บ่อยๆ ตัวอย่างของเทนเซอร์ดังกล่าว ได้แก่ เทนเซอร์สถานะในโมเดลลำดับ สำหรับเทนเซอร์ที่ต้องเข้าถึง CPU บ่อยครั้งในฝั่งไคลเอ็นต์ ให้ใช้พูลหน่วยความจำที่ใช้ร่วมกันแทน
หากต้องการจัดสรรหน่วยความจำแบบทึบแสง ให้ทำตามขั้นตอนต่อไปนี้
เรียกใช้ฟังก์ชัน
ANeuralNetworksMemoryDesc_create()เพื่อสร้างตัวอธิบายหน่วยความจำใหม่// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
ระบุบทบาทอินพุตและเอาต์พุตที่ต้องการทั้งหมดโดยการเรียก
ANeuralNetworksMemoryDesc_addInputRole()และANeuralNetworksMemoryDesc_addOutputRole()// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
(ไม่บังคับ) ระบุขนาดหน่วยความจำโดยเรียกใช้
ANeuralNetworksMemoryDesc_setDimensions()// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
กำหนดคำอธิบายให้เสร็จสมบูรณ์โดยเรียกใช้
ANeuralNetworksMemoryDesc_finish()ANeuralNetworksMemoryDesc_finish(desc);
จัดสรรหน่วยความจำได้มากเท่าที่ต้องการโดยส่งตัวอธิบายไปยัง
ANeuralNetworksMemory_createFromDesc()// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
ปลดปล่อยตัวอธิบายหน่วยความจำเมื่อไม่ต้องการใช้งานแล้ว
ANeuralNetworksMemoryDesc_free(desc);
ไคลเอ็นต์จะใช้ได้เฉพาะออบเจ็กต์ ANeuralNetworksMemory ที่สร้างขึ้นกับ
ANeuralNetworksExecution_setInputFromMemory() หรือ
ANeuralNetworksExecution_setOutputFromMemory() ตามบทบาท
ที่ระบุไว้ในออบเจ็กต์ ANeuralNetworksMemoryDesc ต้องตั้งค่าอาร์กิวเมนต์ออฟเซ็ตและความยาว เป็น 0 เพื่อระบุว่าใช้หน่วยความจำทั้งหมด ไคลเอ็นต์
อาจตั้งค่าหรือดึงเนื้อหาของหน่วยความจำอย่างชัดเจนโดยใช้
ANeuralNetworksMemory_copy()
คุณสร้างความทรงจำแบบทึบได้โดยมีบทบาทที่มีมิติข้อมูลหรืออันดับที่ไม่ได้ระบุ
ในกรณีดังกล่าว การสร้างหน่วยความจำอาจล้มเหลวโดยมีสถานะเป็น
ANEURALNETWORKS_OP_FAILED หากไดรเวอร์พื้นฐานไม่รองรับ
เราขอแนะนำให้ไคลเอ็นต์ใช้ตรรกะสำรองโดยการจัดสรรบัฟเฟอร์ที่ใหญ่พอซึ่งได้รับการสนับสนุนจาก Ashmem หรือ BLOB-mode AHardwareBuffer
เมื่อ NNAPI ไม่จำเป็นต้องเข้าถึงออบเจ็กต์หน่วยความจำแบบทึบแสงอีกต่อไป ให้ปล่อยอินสแตนซ์ ANeuralNetworksMemory ที่เกี่ยวข้อง
ANeuralNetworksMemory_free(opaqueMem);
วัดประสิทธิภาพ
คุณสามารถประเมินประสิทธิภาพของแอปได้โดยการวัดเวลาในการดำเนินการหรือโดยการ สร้างโปรไฟล์
เวลาดำเนินการ
เมื่อต้องการกำหนดเวลารวมในการดำเนินการผ่านรันไทม์ คุณสามารถใช้
API การดำเนินการแบบซิงโครนัสและวัดเวลาที่ใช้ในการเรียก เมื่อต้องการกำหนดเวลารวมในการดำเนินการผ่านซอฟต์แวร์
สแต็กในระดับที่ต่ำกว่า คุณสามารถใช้
ANeuralNetworksExecution_setMeasureTiming
และ
ANeuralNetworksExecution_getDuration
เพื่อรับข้อมูลต่อไปนี้
- เวลาในการดำเนินการบนตัวเร่ง (ไม่ได้อยู่ในไดรเวอร์ซึ่งทำงานบนโปรเซสเซอร์โฮสต์)
- เวลาในการดำเนินการในไดรเวอร์ รวมถึงเวลาในตัวเร่ง
เวลาในการดำเนินการในไดรเวอร์ไม่รวมค่าใช้จ่ายเพิ่มเติม เช่น ค่าใช้จ่ายของรันไทม์ เองและ IPC ที่จำเป็นสำหรับรันไทม์ในการสื่อสารกับไดรเวอร์
API เหล่านี้จะวัดระยะเวลาระหว่างเหตุการณ์ที่ส่งงานและเหตุการณ์ที่ทำงานเสร็จ ไม่ใช่เวลาที่ไดรเวอร์หรือตัวเร่งใช้ในการดำเนินการอนุมาน ซึ่งอาจถูกขัดจังหวะด้วยการสลับบริบท
ตัวอย่างเช่น หากการอนุมาน 1 เริ่มขึ้น จากนั้นคนขับจะหยุดทำงานเพื่อทำการอนุมาน 2 แล้วกลับมาทำงานต่อและทำการอนุมาน 1 เสร็จสิ้น เวลาดำเนินการสำหรับการอนุมาน 1 จะรวมเวลาที่หยุดทำงานเพื่อทำการอนุมาน 2 ด้วย
ข้อมูลเวลาดังกล่าวอาจมีประโยชน์สำหรับการติดตั้งใช้งานแอปพลิเคชันในสภาพแวดล้อมการผลิตเพื่อรวบรวมข้อมูลการวัดและส่งข้อมูลทางไกลสำหรับการใช้งานแบบออฟไลน์ คุณสามารถใช้ข้อมูลเวลาเพื่อ แก้ไขแอปให้มีประสิทธิภาพสูงขึ้นได้
โปรดคำนึงถึงสิ่งต่อไปนี้เมื่อใช้ฟังก์ชันนี้
- การรวบรวมข้อมูลเวลาอาจทำให้ประสิทธิภาพลดลง
- มีเพียงไดรเวอร์เท่านั้นที่สามารถคำนวณเวลาที่ใช้ในตัวไดรเวอร์เองหรือในตัวเร่ง โดยไม่รวมเวลาที่ใช้ในรันไทม์ของ NNAPI และใน IPC
- คุณจะใช้ API เหล่านี้ได้เฉพาะกับ
ANeuralNetworksExecutionที่สร้างด้วยANeuralNetworksCompilation_createForDevicesที่มีnumDevices = 1เท่านั้น - ไม่จำเป็นต้องมีไดรเวอร์เพื่อรายงานข้อมูลเวลา
ทำโปรไฟล์แอปพลิเคชันด้วย Android Systrace
ตั้งแต่ Android 10 เป็นต้นไป NNAPI จะสร้างเหตุการณ์ systrace โดยอัตโนมัติ ซึ่งคุณใช้เพื่อสร้างโปรไฟล์แอปพลิเคชันได้
แหล่งที่มาของ NNAPI มาพร้อมกับparse_systraceยูทิลิตีเพื่อประมวลผล
เหตุการณ์ systrace ที่แอปพลิเคชันสร้างขึ้น และสร้างมุมมองตารางที่แสดง
เวลาที่ใช้ในระยะต่างๆ ของวงจรโมเดล (การสร้างอินสแตนซ์
การเตรียม การดำเนินการคอมไพล์ และการสิ้นสุด) และเลเยอร์ต่างๆ ของ
แอปพลิเคชัน เลเยอร์ที่แอปพลิเคชันของคุณแบ่งออกเป็นเลเยอร์ต่างๆ มีดังนี้
Application: โค้ดของแอปพลิเคชันหลักRuntime: รันไทม์ของ NNAPIIPC: การสื่อสารระหว่างกระบวนการระหว่างรันไทม์ของ NNAPI กับโค้ดไดรเวอร์Driver: กระบวนการไดรเวอร์ของตัวเร่ง
สร้างข้อมูลการวิเคราะห์การจัดโปรไฟล์
สมมติว่าคุณได้ตรวจสอบแผนผังแหล่งที่มาของ AOSP ที่ $ANDROID_BUILD_TOP และ ใช้ตัวอย่างการแยกประเภทรูปภาพของ TFLite เป็นแอปพลิเคชันเป้าหมาย คุณจะสร้างข้อมูลการจัดทำโปรไฟล์ NNAPI ได้โดยทำตามขั้นตอนต่อไปนี้
- เริ่ม Systrace ของ Android ด้วยคำสั่งต่อไปนี้
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
พารามิเตอร์ -o trace.html ระบุว่าระบบจะเขียนการติดตามใน trace.html เมื่อทำการโปรไฟล์แอปพลิเคชันของคุณเอง คุณจะต้อง
แทนที่ org.tensorflow.lite.examples.classification ด้วยชื่อกระบวนการ
ที่ระบุไว้ในไฟล์ Manifest ของแอป
การดำเนินการนี้จะทำให้คอนโซลเชลล์ตัวใดตัวหนึ่งของคุณทำงานอยู่ตลอดเวลา ดังนั้นอย่าเรียกใช้คำสั่งในเบื้องหลังเนื่องจากคำสั่งจะรอ enter ให้สิ้นสุดการทำงานแบบอินเทอร์แอกทีฟ
- หลังจากเริ่มตัวรวบรวม Systrace แล้ว ให้เริ่มแอปและเรียกใช้ การทดสอบเปรียบเทียบ
ในกรณีของเรา คุณสามารถเริ่มแอปการแยกประเภทรูปภาพจาก Android Studio หรือจาก UI ของโทรศัพท์ที่ใช้ทดสอบโดยตรงได้หากติดตั้งแอปไว้แล้ว หากต้องการสร้างข้อมูล NNAPI บางอย่าง คุณต้องกำหนดค่าแอปให้ใช้ NNAPI โดย เลือก NNAPI เป็นอุปกรณ์เป้าหมายในกล่องโต้ตอบการกำหนดค่าแอป
เมื่อการทดสอบเสร็จสมบูรณ์ ให้สิ้นสุด Systrace โดยกด
enterในเทอร์มินัลคอนโซลที่ใช้งานอยู่ตั้งแต่ขั้นตอนที่ 1เรียกใช้ยูทิลิตี
systrace_parserเพื่อสร้างสถิติสะสม
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
ตัวแยกวิเคราะห์ยอมรับพารามิเตอร์ต่อไปนี้
- --total-times: แสดงเวลาทั้งหมดที่ใช้ในเลเยอร์ รวมถึงเวลา
ที่ใช้รอการดำเนินการในการเรียกไปยังเลเยอร์พื้นฐาน
- --print-detail: พิมพ์เหตุการณ์ทั้งหมดที่รวบรวมจาก Systrace
- --per-execution: พิมพ์เฉพาะการดำเนินการและระยะย่อย (ตามเวลาต่อการดำเนินการ)
แทนที่จะเป็นสถิติสำหรับทุกระยะ
- --json: สร้างเอาต์พุตในรูปแบบ JSON
ตัวอย่างเอาต์พุตแสดงอยู่ด้านล่าง
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
ตัวแยกวิเคราะห์อาจล้มเหลวหากเหตุการณ์ที่รวบรวมไม่ได้แสดงถึงการติดตามแอปพลิเคชันที่สมบูรณ์ โดยเฉพาะอย่างยิ่ง อาจเกิดข้อผิดพลาดหากมีเหตุการณ์ Systrace ที่สร้างขึ้น เพื่อทำเครื่องหมายจุดสิ้นสุดของส่วนในร่องรอยโดยไม่มีเหตุการณ์ เริ่มต้นของส่วนที่เกี่ยวข้อง โดยมักเกิดขึ้นหากมีการสร้างเหตุการณ์บางอย่างจากเซสชันการสร้างโปรไฟล์ก่อนหน้าเมื่อคุณเริ่มตัวรวบรวม Systrace ในกรณีนี้ คุณจะต้องเรียกใช้การสร้างโปรไฟล์อีกครั้ง
เพิ่มสถิติสำหรับโค้ดของแอปพลิเคชันลงในเอาต์พุต systrace_parser
แอปพลิเคชัน parse_systrace อิงตามฟังก์ชันการทำงานของ systrace ในตัวของ Android คุณสามารถเพิ่มการติดตามสำหรับการดำเนินการที่เฉพาะเจาะจงในแอปได้โดยใช้ systrace API (สำหรับ Java , สำหรับแอปพลิเคชันเนทีฟ ) ที่มีชื่อเหตุการณ์ที่กำหนดเอง
หากต้องการเชื่อมโยงเหตุการณ์ที่กําหนดเองกับระยะต่างๆ ของวงจรแอปพลิเคชัน ให้เพิ่มสตริงใดสตริงหนึ่งต่อไปนี้ไว้หน้าชื่อเหตุการณ์
[NN_LA_PI]: เหตุการณ์ระดับแอปพลิเคชันสำหรับการเริ่มต้น[NN_LA_PP]: เหตุการณ์ระดับแอปพลิเคชันสำหรับการเตรียมการ[NN_LA_PC]: เหตุการณ์ระดับแอปพลิเคชันสำหรับการรวบรวม[NN_LA_PE]: เหตุการณ์ระดับแอปพลิเคชันสำหรับการดำเนินการ
ต่อไปนี้เป็นตัวอย่างวิธีแก้ไขโค้ดตัวอย่างการแยกประเภทรูปภาพ TFLite โดยการเพิ่มส่วน runInferenceModel สำหรับเฟส Execution และชั้น Application ที่มีส่วนอื่นๆ preprocessBitmap ซึ่งจะไม่ได้รับการพิจารณาในการติดตาม NNAPI ส่วน runInferenceModel จะเป็นส่วนหนึ่งของเหตุการณ์ systrace ที่ประมวลผลโดยตัวแยกวิเคราะห์ systrace ของ nnapi
Kotlin
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
Java
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
คุณภาพของการบริการ
ใน Android 11 ขึ้นไป NNAPI ช่วยให้คุณภาพของบริการ (QoS) ดีขึ้นโดย อนุญาตให้แอปพลิเคชันระบุลำดับความสำคัญสัมพัทธ์ของโมเดล ระยะเวลาสูงสุดที่คาดว่าจะใช้ในการเตรียมโมเดลที่กำหนด และระยะเวลาสูงสุด ที่คาดว่าจะใช้ในการคำนวณที่กำหนดให้เสร็จสมบูรณ์ Android 11 ยังมีรหัสผลลัพธ์ NNAPI เพิ่มเติม ซึ่งช่วยให้แอปพลิเคชันเข้าใจข้อผิดพลาดต่างๆ เช่น การไม่สามารถดำเนินการให้เสร็จตามกำหนดเวลาได้
กำหนดลำดับความสำคัญของเวิร์กโหลด
หากต้องการตั้งค่าลำดับความสำคัญของภาระงาน NNAPI ให้เรียกใช้
ANeuralNetworksCompilation_setPriority()
ก่อนเรียกใช้ ANeuralNetworksCompilation_finish()
กำหนดเวลา
แอปพลิเคชันสามารถกำหนดกำหนดเวลาสำหรับการคอมไพล์โมเดลและการอนุมานได้
- หากต้องการตั้งค่าการหมดเวลาในการคอมไพล์ ให้เรียกใช้
ANeuralNetworksCompilation_setTimeout()ก่อนเรียกใช้ANeuralNetworksCompilation_finish() - หากต้องการตั้งค่าการหมดเวลาอนุมาน ให้เรียกใช้
ANeuralNetworksExecution_setTimeout()ก่อนเริ่มการคอมไพล์
ข้อมูลเพิ่มเติมเกี่ยวกับตัวถูกดำเนินการ
ส่วนต่อไปนี้จะครอบคลุมหัวข้อขั้นสูงเกี่ยวกับการใช้ตัวถูกดำเนินการ
Tensor ที่ทำให้เล็กลง
Tensor ที่ผ่านการควอนไทซ์เป็นวิธีที่กะทัดรัดในการแสดงอาร์เรย์ n มิติของค่าจุดลอยตัว
NNAPI รองรับเทนเซอร์ที่ผ่านการหาปริมาณแบบอสมมาตร 8 บิต สำหรับเทนเซอร์เหล่านี้ ค่าของแต่ละเซลล์จะแสดงด้วยจำนวนเต็ม 8 บิต เทนเซอร์มีค่าสเกลและค่าจุดศูนย์ที่เชื่อมโยงกัน โดยใช้เพื่อแปลงจํานวนเต็ม 8 บิต เป็นค่าทศนิยมที่แสดง
สูตรคือ
(cellValue - zeroPoint) * scale
โดยที่ค่า zeroPoint เป็นจำนวนเต็ม 32 บิต และค่า scale เป็นค่าจำนวนจุดลอยตัว 32 บิต
เมื่อเทียบกับเทนเซอร์ที่มีค่าจุดลอยตัว 32 บิต เทนเซอร์ที่กำหนดปริมาณ 8 บิต มีข้อดี 2 ประการดังนี้
- แอปพลิเคชันของคุณจะมีขนาดเล็กลง เนื่องจากน้ำหนักที่ฝึกแล้วมีขนาดเพียง 1 ใน 4 ของขนาดเทนเซอร์ 32 บิต
- การคำนวณมักจะดำเนินการได้เร็วขึ้น เนื่องจากต้องดึงข้อมูลจากหน่วยความจำน้อยลง และประสิทธิภาพของโปรเซสเซอร์ เช่น DSP ในการคำนวณจำนวนเต็ม
แม้ว่าจะแปลงโมเดลจุดลอยตัวเป็นโมเดลที่เล็กลงได้ แต่ประสบการณ์ของเราแสดงให้เห็นว่าการฝึกโมเดลที่เล็กลงโดยตรงจะให้ผลลัพธ์ที่ดีกว่า กล่าวคือ โครงข่ายระบบประสาทเทียมจะเรียนรู้ที่จะชดเชยความละเอียดที่เพิ่มขึ้นของแต่ละค่า สำหรับเทนเซอร์ที่แปลงเป็นจำนวนเต็มแต่ละรายการ ระบบจะกำหนดค่าสเกลและ zeroPoint ในระหว่างกระบวนการฝึก
ใน NNAPI คุณจะกำหนดประเภท Tensor ที่วัดปริมาณได้โดยการตั้งค่าฟิลด์ประเภทของโครงสร้างข้อมูล
ANeuralNetworksOperandType
เป็น
ANEURALNETWORKS_TENSOR_QUANT8_ASYMM
นอกจากนี้ คุณยังระบุค่าสเกลและค่า zeroPoint ของเทนเซอร์ในโครงสร้างข้อมูลนั้นได้ด้วย
นอกจากเทนเซอร์ที่แปลงให้เล็กลงแบบอสมมาตร 8 บิตแล้ว NNAPI ยังรองรับรายการต่อไปนี้ด้วย
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNELซึ่งคุณใช้เพื่อแสดงค่าถ่วงน้ำหนักในการดำเนินการCONV/DEPTHWISE_CONV/TRANSPOSED_CONVได้ANEURALNETWORKS_TENSOR_QUANT16_ASYMMซึ่งคุณใช้สำหรับสถานะภายในของQUANTIZED_16BIT_LSTMได้ANEURALNETWORKS_TENSOR_QUANT8_SYMMซึ่งอาจเป็นอินพุตของANEURALNETWORKS_DEQUANTIZE
ตัวถูกดำเนินการที่ไม่บังคับ
การดำเนินการบางอย่าง เช่น
ANEURALNETWORKS_LSH_PROJECTION
จะใช้ตัวถูกดำเนินการที่ไม่บังคับ หากต้องการระบุในโมเดลว่ามีการละเว้นตัวถูกดำเนินการที่ไม่บังคับ ให้เรียกใช้ฟังก์ชัน
ANeuralNetworksModel_setOperandValue()
โดยส่ง NULL สำหรับบัฟเฟอร์และ 0 สำหรับความยาว
หากการตัดสินใจว่ามีตัวถูกดำเนินการหรือไม่แตกต่างกันสำหรับการดำเนินการแต่ละครั้ง
คุณจะระบุว่าละเว้นตัวถูกดำเนินการโดยใช้ฟังก์ชัน
ANeuralNetworksExecution_setInput()
หรือ
ANeuralNetworksExecution_setOutput()
โดยส่ง NULL สำหรับบัฟเฟอร์และ 0 สำหรับความยาว
เทนเซอร์ที่มีอันดับที่ไม่รู้จัก
Android 9 (ระดับ API 28) ได้เปิดตัวตัวดำเนินการโมเดลที่มีมิติข้อมูลที่ไม่รู้จัก แต่มีอันดับที่ทราบ (จำนวนมิติข้อมูล) Android 10 (API ระดับ 29) ได้เปิดตัว เทนเซอร์ที่มีอันดับที่ไม่รู้จัก ดังที่แสดงใน ANeuralNetworksOperandType
การเปรียบเทียบ NNAPI
การเปรียบเทียบ NNAPI พร้อมใช้งานใน AOSP ใน platform/test/mlts/benchmark
(แอปเปรียบเทียบ) และ platform/test/mlts/models (โมเดลและชุดข้อมูล)
การเปรียบเทียบจะประเมินเวลาในการตอบสนองและความแม่นยำ และเปรียบเทียบไดรเวอร์กับงานเดียวกันที่ทำโดยใช้ TensorFlow Lite ที่ทำงานบน CPU สำหรับโมเดลและชุดข้อมูลเดียวกัน
หากต้องการใช้การเปรียบเทียบ ให้ทำดังนี้
เชื่อมต่ออุปกรณ์ Android เป้าหมายกับคอมพิวเตอร์ เปิดหน้าต่างเทอร์มินัล และ ตรวจสอบว่าเข้าถึงอุปกรณ์ผ่าน adb ได้
หากเชื่อมต่ออุปกรณ์ Android มากกว่า 1 เครื่อง ให้ส่งออกตัวแปรสภาพแวดล้อมของอุปกรณ์เป้าหมาย
ANDROID_SERIALไปที่ไดเรกทอรีต้นทางระดับบนสุดของ Android
เรียกใช้คำสั่งต่อไปนี้
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
เมื่อการทดสอบประสิทธิภาพสิ้นสุดลง ผลลัพธ์จะแสดงเป็นหน้า HTML ที่ส่งไปยัง
xdg-open
บันทึก NNAPI
NNAPI สร้างข้อมูลการวินิจฉัยที่เป็นประโยชน์ในบันทึกของระบบ หากต้องการวิเคราะห์บันทึก ให้ใช้ยูทิลิตี logcat
เปิดใช้การบันทึก NNAPI แบบละเอียดสำหรับเฟสหรือคอมโพเนนต์ที่เฉพาะเจาะจงโดยตั้งค่าพร็อพเพอร์ตี้
debug.nn.vlog (ใช้ adb shell) เป็นรายการค่าต่อไปนี้
โดยคั่นด้วยช่องว่าง เครื่องหมายโคลอน หรือคอมมา
model: การสร้างโมเดลcompilation: การสร้างแผนการดำเนินการของโมเดลและการคอมไพล์execution: การดำเนินการโมเดลcpuexe: การดำเนินการโดยใช้การติดตั้งใช้งาน CPU ของ NNAPImanager: ข้อมูลส่วนขยาย NNAPI, อินเทอร์เฟซที่ใช้ได้ และความสามารถที่เกี่ยวข้องallหรือ1: องค์ประกอบทั้งหมดข้างต้น
เช่น หากต้องการเปิดใช้การบันทึกแบบละเอียดทั้งหมด ให้ใช้คำสั่ง
adb shell setprop debug.nn.vlog all หากต้องการปิดใช้การบันทึกแบบละเอียด ให้ใช้คำสั่ง
adb shell setprop debug.nn.vlog '""'
เมื่อเปิดใช้แล้ว การบันทึกแบบละเอียดจะสร้างรายการบันทึกที่ระดับ INFO โดยมีแท็กที่ตั้งค่าเป็นชื่อเฟสหรือคอมโพเนนต์
นอกเหนือจากdebug.nn.vlogข้อความที่ควบคุมแล้ว คอมโพเนนต์ API ของ NNAPI ยังมี
รายการบันทึกอื่นๆ ในระดับต่างๆ โดยแต่ละรายการใช้แท็กล็อกที่เฉพาะเจาะจง
หากต้องการดูรายการคอมโพเนนต์ ให้ค้นหาในโครงสร้างแหล่งที่มาโดยใช้นิพจน์ต่อไปนี้
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
ปัจจุบันนิพจน์นี้จะแสดงแท็กต่อไปนี้
- BurstBuilder
- Callback
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- ผู้จัดการ
- หน่วยความจำ
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- การดำเนินการ
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
หากต้องการควบคุมระดับของข้อความบันทึกที่แสดงโดย logcat ให้ใช้ตัวแปรสภาพแวดล้อม ANDROID_LOG_TAGS
หากต้องการแสดงชุดข้อความบันทึก NNAPI ทั้งหมดและปิดใช้ข้อความอื่นๆ ให้ตั้งค่า ANDROID_LOG_TAGS เป็น
ดังนี้
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
คุณตั้งค่า ANDROID_LOG_TAGS ได้โดยใช้คำสั่งต่อไปนี้
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
โปรดทราบว่านี่เป็นเพียงตัวกรองที่ใช้กับ logcat คุณยังคงต้อง
ตั้งค่าพร็อพเพอร์ตี้ debug.nn.vlog เป็น all เพื่อสร้างข้อมูลบันทึกแบบละเอียด