
The Android Neural Networks API (NNAPI) is an Android C API designed for running computationally intensive operations for machine learning on Android devices. NNAPI is designed to provide a base layer of functionality for higher-level machine learning frameworks, such as TensorFlow Lite and Caffe2, that build and train neural networks. The API is available on all Android devices running Android 8.1 (API level 27) or higher, but was deprecated in Android 15.
NNAPI با اعمال دادههای دستگاههای اندروید به مدلهای از پیش آموزشدیده و تعریفشده توسط توسعهدهنده، از استنتاج پشتیبانی میکند. نمونههایی از استنتاج شامل طبقهبندی تصاویر، پیشبینی رفتار کاربر و انتخاب پاسخهای مناسب برای یک عبارت جستجو میشود.
استنتاج روی دستگاه مزایای زیادی دارد:
- تأخیر : نیازی نیست درخواستی را از طریق اتصال شبکه ارسال کنید و منتظر پاسخ باشید. به عنوان مثال، این میتواند برای برنامههای ویدیویی که فریمهای متوالی دریافتی از دوربین را پردازش میکنند، بسیار مهم باشد.
- در دسترس بودن : برنامه حتی زمانی که خارج از پوشش شبکه باشد، اجرا میشود.
- سرعت : سختافزار جدیدی که مخصوص پردازش شبکه عصبی است، محاسبات بسیار سریعتری را نسبت به یک پردازنده مرکزی (CPU) عمومی به تنهایی ارائه میدهد.
- حریم خصوصی : دادهها از دستگاه اندروید خارج نمیشوند.
- هزینه : وقتی تمام محاسبات روی دستگاه اندروید انجام میشود، نیازی به مزرعه سرور نیست.
همچنین مواردی وجود دارد که یک توسعهدهنده باید در نظر داشته باشد:
- میزان مصرف سیستم : ارزیابی شبکههای عصبی شامل محاسبات زیادی است که میتواند مصرف باتری را افزایش دهد. اگر این موضوع برای برنامه شما نگرانکننده است، به خصوص برای محاسبات طولانی مدت، باید نظارت بر سلامت باتری را در نظر بگیرید.
- اندازه برنامه : به اندازه مدلهای خود توجه کنید. مدلها ممکن است چندین مگابایت فضا اشغال کنند. اگر قرار دادن مدلهای بزرگ در APK شما به طور نامناسبی بر کاربران شما تأثیر میگذارد، میتوانید دانلود مدلها را پس از نصب برنامه، استفاده از مدلهای کوچکتر یا اجرای محاسبات خود در فضای ابری در نظر بگیرید. NNAPI قابلیت اجرای مدلها در فضای ابری را ارائه نمیدهد.
برای مشاهدهی یک مثال از نحوهی استفاده از NNAPI، به نمونهی API شبکههای عصبی اندروید مراجعه کنید.
درک زمان اجرای API شبکههای عصبی
NNAPI قرار است توسط کتابخانهها، چارچوبها و ابزارهای یادگیری ماشین فراخوانی شود که به توسعهدهندگان اجازه میدهد مدلهای خود را خارج از دستگاه آموزش داده و آنها را در دستگاههای اندروید مستقر کنند. برنامهها معمولاً مستقیماً از NNAPI استفاده نمیکنند، بلکه در عوض از چارچوبهای یادگیری ماشین سطح بالاتر استفاده میکنند. این چارچوبها به نوبه خود میتوانند از NNAPI برای انجام عملیات استنتاج شتابیافته سختافزاری در دستگاههای پشتیبانیشده استفاده کنند.
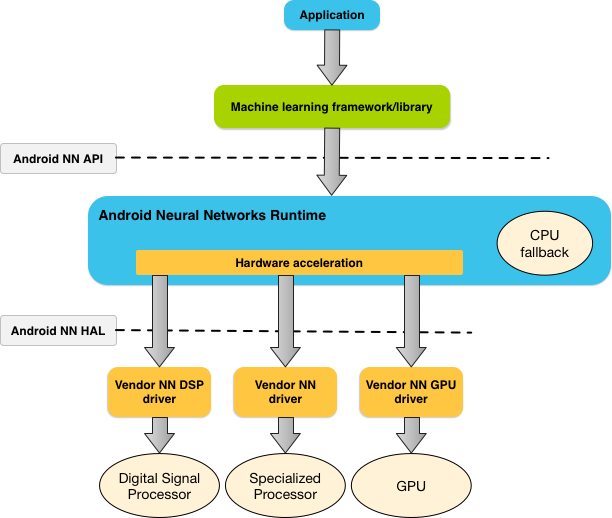
بر اساس نیازهای یک برنامه و قابلیتهای سختافزاری روی یک دستگاه اندروید، زمان اجرای شبکه عصبی اندروید میتواند به طور موثر حجم کار محاسباتی را بین پردازندههای موجود روی دستگاه، از جمله سختافزار اختصاصی شبکه عصبی، واحدهای پردازش گرافیکی (GPU) و پردازندههای سیگنال دیجیتال (DSP)، توزیع کند.
برای دستگاههای اندرویدی که فاقد درایور تخصصی فروشنده هستند، زمان اجرای NNAPI درخواستها را روی CPU اجرا میکند.
شکل ۱ معماری سیستم سطح بالای NNAPI را نشان میدهد.
مدل برنامهنویسی API شبکههای عصبی
برای انجام محاسبات با استفاده از NNAPI، ابتدا باید یک گراف جهتدار بسازید که محاسبات مورد نظر را تعریف کند. این گراف محاسباتی، همراه با دادههای ورودی شما (به عنوان مثال، وزنها و بایاسهای منتقل شده از یک چارچوب یادگیری ماشین)، مدلی را برای ارزیابی زمان اجرای NNAPI تشکیل میدهد.
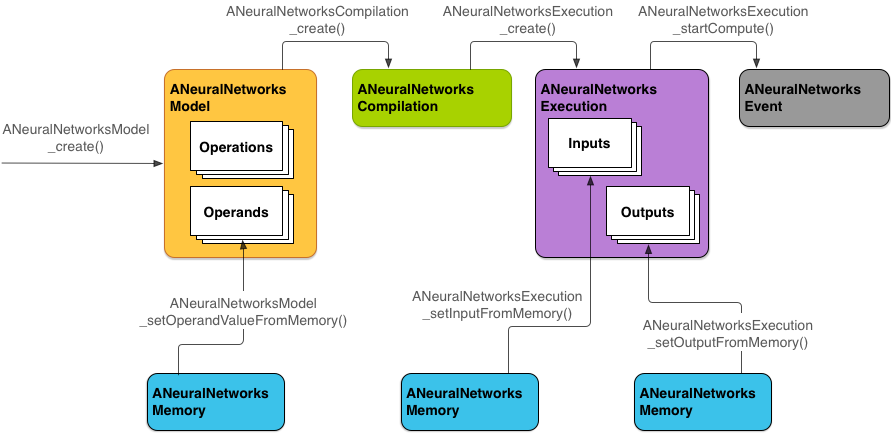
NNAPI از چهار انتزاع اصلی استفاده میکند:
- مدل : نمودار محاسباتی از عملیات ریاضی و مقادیر ثابت آموخته شده از طریق یک فرآیند آموزش. این عملیات مختص شبکههای عصبی هستند. آنها شامل کانولوشن دوبعدی (2D)، فعالسازی لجستیک ( سیگموئید )، فعالسازی خطی یکسو شده (ReLU) و موارد دیگر میشوند. ایجاد یک مدل یک عملیات همزمان است. پس از ایجاد موفقیتآمیز، میتوان آن را در نخها و کامپایلها دوباره استفاده کرد. در NNAPI، یک مدل به عنوان یک نمونه
ANeuralNetworksModelنمایش داده میشود. - کامپایل : نشاندهنده پیکربندی برای کامپایل یک مدل NNAPI به کد سطح پایینتر است. ایجاد یک کامپایل یک عملیات همزمان است. پس از ایجاد موفقیتآمیز، میتوان آن را در نخها و اجراها دوباره استفاده کرد. در NNAPI، هر کامپایل به عنوان یک نمونه
ANeuralNetworksCompilationنمایش داده میشود. - حافظه : نشاندهنده حافظه مشترک، فایلهای نگاشتشده در حافظه و بافرهای حافظه مشابه است. استفاده از بافر حافظه به NNAPI اجازه میدهد تا زمان اجرای آن، دادهها را به طور کارآمدتری به درایورها منتقل کند. یک برنامه معمولاً یک بافر حافظه مشترک ایجاد میکند که شامل هر تانسور مورد نیاز برای تعریف یک مدل است. همچنین میتوانید از بافرهای حافظه برای ذخیره ورودیها و خروجیها برای یک نمونه اجرا استفاده کنید. در NNAPI، هر بافر حافظه به عنوان یک نمونه
ANeuralNetworksMemoryنمایش داده میشود. اجرا : رابطی برای اعمال یک مدل NNAPI بر روی مجموعهای از ورودیها و جمعآوری نتایج. اجرا میتواند به صورت همزمان یا غیرهمزمان انجام شود.
برای اجرای ناهمزمان، چندین نخ میتوانند برای اجرای یکسان منتظر بمانند. وقتی این اجرا کامل شد، همه نخها آزاد میشوند.
در NNAPI، هر اجرا به عنوان یک نمونه از
ANeuralNetworksExecutionنمایش داده میشود.
شکل ۲ جریان برنامهنویسی پایه را نشان میدهد.
ادامهی این بخش، مراحل راهاندازی مدل NNAPI شما برای انجام محاسبات، کامپایل مدل و اجرای مدل کامپایلشده را شرح میدهد.
دسترسی به دادههای آموزشی را فراهم کنید
دادههای وزنها و بایاسهای آموزشدیده شما احتمالاً در یک فایل ذخیره میشوند. برای فراهم کردن دسترسی کارآمد به این دادهها برای زمان اجرای NNAPI، با فراخوانی تابع ANeuralNetworksMemory_createFromFd() و ارسال توصیفگر فایل فایل داده باز شده، یک نمونه از ANeuralNetworksMemory ایجاد کنید. همچنین میتوانید پرچمهای محافظت از حافظه و یک آفست را که ناحیه حافظه مشترک در آن شروع میشود، در فایل مشخص کنید.
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
اگرچه در این مثال ما فقط از یک نمونه ANeuralNetworksMemory برای همه وزنهای خود استفاده میکنیم، اما میتوان برای چندین فایل از بیش از یک نمونه ANeuralNetworksMemory استفاده کرد.
از بافرهای سختافزاری بومی استفاده کنید
شما میتوانید از بافرهای سختافزاری بومی برای ورودیها، خروجیها و مقادیر ثابت عملوند مدل استفاده کنید. در موارد خاص، یک شتابدهنده NNAPI میتواند بدون نیاز به کپی کردن دادهها توسط درایور، به اشیاء AHardwareBuffer دسترسی پیدا کند. AHardwareBuffer پیکربندیهای مختلفی دارد و هر شتابدهنده NNAPI ممکن است از همه این پیکربندیها پشتیبانی نکند. به دلیل این محدودیت، به محدودیتهای ذکر شده در مستندات مرجع ANeuralNetworksMemory_createFromAHardwareBuffer مراجعه کنید و قبل از اجرا، آنها را روی دستگاههای هدف آزمایش کنید تا مطمئن شوید که کامپایلها و اجراهایی که از AHardwareBuffer استفاده میکنند، مطابق انتظار رفتار میکنند و از انتساب دستگاه برای مشخص کردن شتابدهنده استفاده میکنند.
برای اینکه به NNAPI runtime اجازه دسترسی به یک شیء AHardwareBuffer را بدهید، با فراخوانی تابع ANeuralNetworksMemory_createFromAHardwareBuffer و ارسال شیء AHardwareBuffer ، همانطور که در نمونه کد زیر نشان داده شده است، یک نمونه ANeuralNetworksMemory ایجاد کنید:
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
وقتی NNAPI دیگر نیازی به دسترسی به شیء AHardwareBuffer نداشت، نمونهی ANeuralNetworksMemory مربوطه را آزاد کنید:
ANeuralNetworksMemory_free(mem2);
توجه:
- شما میتوانید از
AHardwareBufferفقط برای کل بافر استفاده کنید؛ نمیتوانید آن را با پارامترARectبه کار ببرید. - زمان اجرای NNAPI بافر را خالی نمیکند. شما باید قبل از زمانبندی اجرا، مطمئن شوید که بافرهای ورودی و خروجی در دسترس هستند.
- هیچ پشتیبانی برای توصیفگرهای فایل حصار همگامسازی وجود ندارد.
- برای یک
AHardwareBufferبا فرمتها و بیتهای استفادهی مختص فروشنده، تعیین اینکه کلاینت یا درایور مسئول پاکسازی حافظهی پنهان هستند، به پیادهسازی فروشنده بستگی دارد.
مدل
یک مدل واحد اساسی محاسبات در NNAPI است. هر مدل توسط یک یا چند عملوند و عملیات تعریف میشود.
عملوندها
عملوندها اشیاء دادهای هستند که در تعریف گراف استفاده میشوند. این اشیاء شامل ورودیها و خروجیهای مدل، گرههای میانی که شامل دادههایی هستند که از یک عملیات به عملیات دیگر جریان مییابند و ثابتهایی که به این عملیاتها منتقل میشوند، میشوند.
دو نوع عملوند وجود دارد که میتوان به مدلهای NNAPI اضافه کرد: اسکالر و تانسور .
یک اسکالر نشان دهنده یک مقدار واحد است. NNAPI از مقادیر اسکالر در قالبهای بولی، ممیز شناور ۱۶ بیتی، ممیز شناور ۳۲ بیتی، عدد صحیح ۳۲ بیتی و عدد صحیح ۳۲ بیتی بدون علامت پشتیبانی میکند.
بیشتر عملیات در NNAPI شامل تانسورها میشود. تانسورها آرایههای n بعدی هستند. NNAPI از تانسورهایی با مقادیر ممیز شناور ۱۶ بیتی، ممیز شناور ۳۲ بیتی، کوانتیزه ۸ بیتی، کوانتیزه ۱۶ بیتی، عدد صحیح ۳۲ بیتی و مقادیر بولی ۸ بیتی پشتیبانی میکند.
برای مثال، شکل ۳ مدلی با دو عملیات را نشان میدهد: یک جمع و به دنبال آن یک ضرب. این مدل یک تانسور ورودی میگیرد و یک تانسور خروجی تولید میکند.
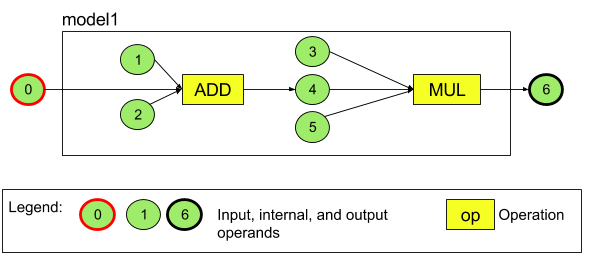
مدل بالا هفت عملوند دارد. این عملوندها به طور ضمنی توسط اندیس ترتیبی که به مدل اضافه میشوند، شناسایی میشوند. اولین عملوند اضافه شده دارای اندیس ۰، دومی دارای اندیس ۱ و به همین ترتیب است. عملوندهای ۱، ۲، ۳ و ۵ عملوندهای ثابت هستند.
ترتیب اضافه کردن عملوندها مهم نیست. برای مثال، عملوند خروجی مدل میتواند اولین عملوندی باشد که اضافه میشود. نکته مهم این است که هنگام اشاره به یک عملوند، از مقدار اندیس صحیح استفاده کنید.
عملوندها نوع دارند. این نوعها هنگام اضافه شدن به مدل مشخص میشوند.
یک عملوند نمیتواند هم به عنوان ورودی و هم به عنوان خروجی یک مدل استفاده شود.
هر عملوند باید یا ورودی مدل، یک ثابت یا عملوند خروجی دقیقاً یک عملیات باشد.
برای اطلاعات بیشتر در مورد استفاده از عملوندها، به بخش «بیشتر درباره عملوندها» مراجعه کنید.
عملیات
یک عملیات، محاسباتی را که باید انجام شوند مشخص میکند. هر عملیات از این عناصر تشکیل شده است:
- یک نوع عملیات (برای مثال، جمع، ضرب، کانولوشن)،
- فهرستی از اندیسهای عملوندهایی که عملیات برای ورودی استفاده میکند، و
- فهرستی از اندیسهای عملوندهایی که عملیات برای خروجی استفاده میکند.
ترتیب در این لیستها مهم است؛ برای ورودیها و خروجیهای مورد انتظار هر نوع عملیات ، به مرجع API مربوط به NNAPI مراجعه کنید.
قبل از اضافه کردن عملیات، باید عملوندهایی را که یک عملیات مصرف یا تولید میکند به مدل اضافه کنید.
ترتیب اضافه کردن عملیات مهم نیست. NNAPI برای تعیین ترتیب اجرای عملیاتها، به وابستگیهای ایجاد شده توسط گراف محاسباتی عملوندها و عملیاتها متکی است.
عملیاتی که NNAPI پشتیبانی میکند در جدول زیر خلاصه شده است:
مشکل شناختهشده در API سطح ۲۸: هنگام ارسال تانسورهای ANEURALNETWORKS_TENSOR_QUANT8_ASYMM به عملیات ANEURALNETWORKS_PAD ، که در اندروید ۹ (API سطح ۲۸) و بالاتر در دسترس است، خروجی NNAPI ممکن است با خروجی چارچوبهای یادگیری ماشین سطح بالاتر، مانند TensorFlow Lite، مطابقت نداشته باشد. در عوض، باید فقط ANEURALNETWORKS_TENSOR_FLOAT32 ارسال کنید. این مشکل در اندروید ۱۰ (API سطح ۲۹) و بالاتر برطرف شده است.
ساخت مدلها
در مثال زیر، مدل دو عملیاتی موجود در شکل 3 را ایجاد میکنیم.
برای ساخت مدل، مراحل زیر را دنبال کنید:
برای تعریف یک مدل خالی، تابع
ANeuralNetworksModel_create()را فراخوانی کنید.ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
با فراخوانی تابع
ANeuralNetworks_addOperand()عملوندها را به مدل خود اضافه کنید. نوع داده آنها با استفاده از ساختار دادهANeuralNetworksOperandTypeتعریف میشود.// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6برای عملوندهایی که مقادیر ثابتی دارند، مانند وزنها و بایاسهایی که برنامه شما از یک فرآیند آموزش به دست میآورد، از توابع
ANeuralNetworksModel_setOperandValue()وANeuralNetworksModel_setOperandValueFromMemory()استفاده کنید.در مثال زیر، مقادیر ثابت را از فایل دادههای آموزشی مربوط به بافر حافظهای که در بخش «ارائه دسترسی به دادههای آموزشی» ایجاد کردهایم، تنظیم میکنیم.
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));برای هر عملیاتی که در گراف جهتدار میخواهید محاسبه کنید، با فراخوانی تابع
ANeuralNetworksModel_addOperation()، آن عملیات را به مدل خود اضافه کنید.به عنوان پارامترهای این فراخوانی، برنامه شما باید موارد زیر را ارائه دهد:
- نوع عملیات
- تعداد مقادیر ورودی
- آرایهای از اندیسها برای عملوندهای ورودی
- تعداد مقادیر خروجی
- آرایهای از اندیسها برای عملوندهای خروجی
توجه داشته باشید که یک عملوند نمیتواند هم برای ورودی و هم برای خروجی یک عملیات مشابه استفاده شود.
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);با فراخوانی تابع
ANeuralNetworksModel_identifyInputsAndOutputs()، مشخص کنید که مدل باید کدام عملوندها را به عنوان ورودی و خروجی خود در نظر بگیرد.// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
به صورت اختیاری، با فراخوانی تابع
ANeuralNetworksModel_relaxComputationFloat32toFloat16()، مشخص کنید که آیاANEURALNETWORKS_TENSOR_FLOAT32مجاز است با محدوده یا دقتی به کوچکی فرمت ممیز شناور ۱۶ بیتی IEEE 754 محاسبه شود یا خیر.برای نهایی کردن تعریف مدل خود، تابع
ANeuralNetworksModel_finish()را فراخوانی کنید. اگر خطایی وجود نداشته باشد، این تابع کد نتیجهیANEURALNETWORKS_NO_ERRORرا برمیگرداند.ANeuralNetworksModel_finish(model);
زمانی که یک مدل ایجاد میکنید، میتوانید آن را به تعداد دلخواه کامپایل کنید و هر کامپایل را به تعداد دلخواه اجرا کنید.
جریان کنترل
برای گنجاندن جریان کنترل در یک مدل NNAPI، موارد زیر را انجام دهید:
زیرگرافهای اجرایی مربوطه (زیرگرافهای
thenوelseبرای دستورIF، زیرگرافهایconditionوbodyبرای حلقهWHILE) را به عنوان مدلهای مستقلANeuralNetworksModel*بسازید:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
عملوندهایی ایجاد کنید که به مدلهای درون مدل حاوی جریان کنترل ارجاع دهند:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
عملیات جریان کنترل را اضافه کنید:
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
گردآوری
مرحله کامپایل تعیین میکند که مدل شما روی کدام پردازندهها اجرا خواهد شد و از درایورهای مربوطه میخواهد که برای اجرای آن آماده شوند. این میتواند شامل تولید کد ماشین مخصوص پردازندههایی باشد که مدل شما روی آنها اجرا خواهد شد.
برای کامپایل کردن یک مدل، مراحل زیر را دنبال کنید:
برای ایجاد یک نمونه کامپایل جدید، تابع
ANeuralNetworksCompilation_create()را فراخوانی کنید.// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
به صورت اختیاری، میتوانید از انتساب دستگاه برای انتخاب صریح دستگاههایی که باید روی آنها اجرا شوند، استفاده کنید.
شما میتوانید به صورت اختیاری بر نحوهی تعامل زمان اجرا بین مصرف باتری و سرعت اجرا تأثیر بگذارید. میتوانید این کار را با فراخوانی
ANeuralNetworksCompilation_setPreference()انجام دهید.// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
تنظیماتی که میتوانید مشخص کنید شامل موارد زیر است:
-
ANEURALNETWORKS_PREFER_LOW_POWER: ترجیحاً به گونهای اجرا شود که مصرف باتری را به حداقل برساند. این مورد برای کامپایلهایی که اغلب اجرا میشوند، مطلوب است. -
ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: ترجیح میدهد در سریعترین زمان ممکن یک پاسخ واحد برگرداند، حتی اگر این باعث مصرف بیشتر برق شود. این حالت پیشفرض است. -
ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: ترجیح میدهد حداکثر توان عملیاتی فریمهای متوالی را افزایش دهد، مثلاً هنگام پردازش فریمهای متوالی دریافتی از دوربین.
-
شما میتوانید به صورت اختیاری با فراخوانی
ANeuralNetworksCompilation_setCachingذخیرهسازی تلفیقی را تنظیم کنید.// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
برای
cacheDirازgetCodeCacheDir()استفاده کنید.tokenمشخص شده باید برای هر مدل درون برنامه منحصر به فرد باشد.تعریف کامپایل را با فراخوانی تابع
ANeuralNetworksCompilation_finish()نهایی کنید. اگر خطایی وجود نداشته باشد، این تابع کد نتیجهیANEURALNETWORKS_NO_ERRORرا برمیگرداند.ANeuralNetworksCompilation_finish(compilation);
کشف و تخصیص دستگاه
در دستگاههای اندرویدی که اندروید ۱۰ (سطح API 29) و بالاتر را اجرا میکنند، NNAPI توابعی را ارائه میدهد که به کتابخانهها و برنامههای چارچوب یادگیری ماشین اجازه میدهد تا اطلاعاتی در مورد دستگاههای موجود دریافت کنند و دستگاههایی را که برای اجرا استفاده میشوند، مشخص کنند. ارائه اطلاعات در مورد دستگاههای موجود به برنامهها این امکان را میدهد که نسخه دقیق درایورهای موجود در دستگاه را دریافت کنند تا از ناسازگاریهای شناخته شده جلوگیری شود. با دادن این قابلیت به برنامهها که مشخص کنند کدام دستگاهها قرار است بخشهای مختلف یک مدل را اجرا کنند، میتوان برنامهها را برای دستگاه اندرویدی که روی آن مستقر شدهاند، بهینه کرد.
کشف دستگاه
برای دریافت تعداد دستگاههای موجود از ANeuralNetworks_getDeviceCount استفاده کنید. برای هر دستگاه، از ANeuralNetworks_getDevice برای تنظیم یک نمونه ANeuralNetworksDevice به یک ارجاع به آن دستگاه استفاده کنید.
وقتی مرجع دستگاه را داشته باشید، میتوانید با استفاده از توابع زیر اطلاعات بیشتری در مورد آن دستگاه کسب کنید:
-
ANeuralNetworksDevice_getFeatureLevel -
ANeuralNetworksDevice_getName -
ANeuralNetworksDevice_getType -
ANeuralNetworksDevice_getVersion
تخصیص دستگاه
از ANeuralNetworksModel_getSupportedOperationsForDevices برای کشف اینکه کدام عملیات یک مدل میتواند روی دستگاههای خاص اجرا شود، استفاده کنید.
برای کنترل اینکه از کدام شتابدهندهها برای اجرا استفاده شود، به جای ANeuralNetworksCompilation_create ، تابع ANeuralNetworksCompilation_createForDevices را فراخوانی کنید. از شیء ANeuralNetworksCompilation حاصل، طبق معمول استفاده کنید. اگر مدل ارائه شده شامل عملیاتی باشد که توسط دستگاههای انتخاب شده پشتیبانی نمیشوند، تابع خطا برمیگرداند.
اگر چندین دستگاه مشخص شده باشد، زمان اجرا مسئول توزیع کار بین دستگاهها است.
مشابه سایر دستگاهها، پیادهسازی CPU مربوط به NNAPI توسط یک ANeuralNetworksDevice با نام nnapi-reference و نوع ANEURALNETWORKS_DEVICE_TYPE_CPU نمایش داده میشود. هنگام فراخوانی ANeuralNetworksCompilation_createForDevices ، از پیادهسازی CPU برای مدیریت موارد خرابی در کامپایل و اجرای مدل استفاده نمیشود.
وظیفه یک برنامه این است که یک مدل را به زیرمدلهایی تقسیم کند که بتوانند روی دستگاههای مشخصشده اجرا شوند. برنامههایی که نیازی به انجام پارتیشنبندی دستی ندارند، باید همچنان به فراخوانی تابع سادهتر ANeuralNetworksCompilation_create ادامه دهند تا از تمام دستگاههای موجود (از جمله CPU) برای تسریع مدل استفاده کنند. اگر مدل نتواند بهطور کامل توسط دستگاههایی که با استفاده از ANeuralNetworksCompilation_createForDevices مشخص کردهاید پشتیبانی شود، ANEURALNETWORKS_BAD_DATA بازگردانده میشود.
پارتیشنبندی مدل
وقتی چندین دستگاه برای مدل در دسترس باشند، زمان اجرای NNAPI کار را بین دستگاهها توزیع میکند. برای مثال، اگر بیش از یک دستگاه در اختیار ANeuralNetworksCompilation_createForDevices قرار گرفته باشد، تمام دستگاههای مشخص شده هنگام تخصیص کار در نظر گرفته میشوند. توجه داشته باشید که اگر دستگاه CPU در لیست نباشد، اجرای CPU غیرفعال میشود. هنگام استفاده از ANeuralNetworksCompilation_create تمام دستگاههای موجود، از جمله CPU، در نظر گرفته میشوند.
توزیع با انتخاب از لیست دستگاههای موجود، برای هر یک از عملیات موجود در مدل، دستگاهی که از آن عملیات پشتیبانی میکند و اعلام بهترین عملکرد، یعنی سریعترین زمان اجرا یا کمترین مصرف برق، بسته به ترجیح اجرایی که توسط کلاینت مشخص شده است، انجام میشود. این الگوریتم پارتیشنبندی، ناکارآمدیهای احتمالی ناشی از IO بین پردازندههای مختلف را در نظر نمیگیرد، بنابراین، هنگام مشخص کردن چندین پردازنده (چه به طور صریح هنگام استفاده از ANeuralNetworksCompilation_createForDevices و چه به طور ضمنی با استفاده از ANeuralNetworksCompilation_create )، مهم است که برنامهی حاصل را پروفایل کنیم.
برای درک چگونگی پارتیشنبندی مدل شما توسط NNAPI، گزارشهای اندروید را برای یافتن پیامی (در سطح INFO با برچسب ExecutionPlan ) بررسی کنید:
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name نام توصیفی عملیات در نمودار است و device-index اندیس دستگاه کاندید در لیست دستگاهها است. این لیست ورودی ارائه شده به ANeuralNetworksCompilation_createForDevices است یا در صورت استفاده از ANeuralNetworksCompilation_createForDevices ، لیست دستگاههایی که هنگام تکرار روی همه دستگاهها با استفاده از ANeuralNetworks_getDeviceCount و ANeuralNetworks_getDevice برگردانده میشوند.
پیام (در سطح INFO با برچسب ExecutionPlan ):
ModelBuilder::partitionTheWork: only one best device: device-name
این پیام نشان میدهد که کل نمودار روی دستگاه device-name شتاب گرفته است.
اعدام
مرحله اجرا، مدل را روی مجموعهای از ورودیها اعمال میکند و خروجیهای محاسبات را در یک یا چند بافر کاربر یا فضای حافظهای که برنامه شما اختصاص داده است، ذخیره میکند.
برای اجرای یک مدل کامپایل شده، مراحل زیر را دنبال کنید:
برای ایجاد یک نمونه اجرایی جدید، تابع
ANeuralNetworksExecution_create()را فراخوانی کنید.// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
مشخص کنید که برنامه شما مقادیر ورودی را برای محاسبه از کجا میخواند. برنامه شما میتواند مقادیر ورودی را از بافر کاربر یا فضای حافظه اختصاص داده شده به ترتیب با فراخوانی
ANeuralNetworksExecution_setInput()یاANeuralNetworksExecution_setInputFromMemory()بخواند.// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
مشخص کنید که برنامه شما مقادیر خروجی را کجا مینویسد. برنامه شما میتواند مقادیر خروجی را یا در یک بافر کاربر یا در یک فضای حافظه اختصاص داده شده، با فراخوانی
ANeuralNetworksExecution_setOutput()یاANeuralNetworksExecution_setOutputFromMemory()بنویسد.// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
با فراخوانی تابع
ANeuralNetworksExecution_startCompute()، اجرا را برای شروع زمانبندی کنید. اگر خطایی وجود نداشته باشد، این تابع کد نتیجهیANEURALNETWORKS_NO_ERRORرا برمیگرداند.// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
تابع
ANeuralNetworksEvent_wait()را برای انتظار جهت تکمیل اجرا فراخوانی کنید. اگر اجرا موفقیتآمیز باشد، این تابع کد نتیجهیANEURALNETWORKS_NO_ERRORرا برمیگرداند. انتظار میتواند روی نخی متفاوت از نخی که اجرا را شروع کرده است، انجام شود.// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
به صورت اختیاری، میتوانید با استفاده از همان نمونه کامپایل برای ایجاد یک نمونه جدید
ANeuralNetworksExecution، مجموعه متفاوتی از ورودیها را به مدل کامپایل شده اعمال کنید.// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
اجرای همزمان
اجرای ناهمزمان برای ایجاد و همگامسازی نخها زمان صرف میکند. علاوه بر این، تأخیر میتواند بسیار متغیر باشد، به طوری که طولانیترین تأخیرها بین زمانی که یک نخ مطلع یا بیدار میشود و زمانی که در نهایت به یک هسته CPU متصل میشود، به ۵۰۰ میکروثانیه میرسد.
برای بهبود تأخیر، میتوانید به جای آن، یک برنامه را برای انجام یک فراخوانی استنتاج همزمان به زمان اجرا هدایت کنید. این فراخوانی فقط زمانی که یک استنتاج تکمیل شده باشد، برمیگردد، نه زمانی که استنتاج شروع شده باشد. به جای فراخوانی ANeuralNetworksExecution_startCompute برای یک فراخوانی استنتاج غیرهمزمان به زمان اجرا، برنامه ANeuralNetworksExecution_compute را برای انجام یک فراخوانی همزمان به زمان اجرا فراخوانی میکند. فراخوانی ANeuralNetworksExecution_compute ANeuralNetworksEvent دریافت نمیکند و با فراخوانی ANeuralNetworksEvent_wait جفت نمیشود.
اعدامهای پشت سر هم
در دستگاههای اندرویدی که اندروید ۱۰ (سطح API ۲۹) و بالاتر را اجرا میکنند، NNAPI از طریق شیء ANeuralNetworksBurst از اجرای پشت سر هم پشتیبانی میکند. اجراهای پشت سر هم، توالی اجراهای یک کامپایل هستند که به سرعت و پشت سر هم اتفاق میافتند، مانند اجراهایی که روی فریمهای ضبط دوربین یا نمونههای صوتی متوالی انجام میشوند. استفاده از اشیاء ANeuralNetworksBurst ممکن است منجر به اجرای سریعتر شود، زیرا به شتابدهندهها نشان میدهد که منابع ممکن است بین اجراها دوباره استفاده شوند و شتابدهندهها باید در مدت زمان اجرای پشت سر هم در حالت عملکرد بالا باقی بمانند.
ANeuralNetworksBurst تنها تغییر کوچکی در مسیر اجرای عادی ایجاد میکند. شما میتوانید با استفاده از ANeuralNetworksBurst_create ، همانطور که در قطعه کد زیر نشان داده شده است، یک شیء burst ایجاد کنید:
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
اجراهای پشت سر هم (burst executions) همزمان هستند. با این حال، به جای استفاده از ANeuralNetworksExecution_compute برای انجام هر استنتاج، اشیاء مختلف ANeuralNetworksExecution را با ANeuralNetworksBurst یکسان در فراخوانیهای تابع ANeuralNetworksExecution_burstCompute جفت میکنید.
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
وقتی دیگر به شیء ANeuralNetworksBurst نیازی نیست، آن را با ANeuralNetworksBurst_free آزاد کنید.
// Cleanup ANeuralNetworksBurst_free(burst);
صفهای فرمان ناهمزمان و اجرای محصور شده
In Android 11 and higher, NNAPI supports an additional way to schedule asynchronous execution through the ANeuralNetworksExecution_startComputeWithDependencies() method. When you use this method, the execution waits for all of the depending events to be signaled before starting the evaluation. Once the execution has completed and the outputs are ready to be consumed, the returned event is signaled.
بسته به اینکه کدام دستگاهها اجرا را مدیریت میکنند، این رویداد ممکن است توسط یک حصار همگامسازی پشتیبانی شود. شما باید ANeuralNetworksEvent_wait() را فراخوانی کنید تا منتظر رویداد بمانید و منابعی را که اجرا استفاده کرده است، بازیابی کنید. میتوانید حصارهای همگامسازی را با استفاده از ANeuralNetworksEvent_createFromSyncFenceFd() به یک شیء رویداد وارد کنید و میتوانید حصارهای همگامسازی را با استفاده از ANeuralNetworksEvent_getSyncFenceFd() از یک شیء رویداد صادر کنید.
خروجیهای با اندازه پویا
برای پشتیبانی از مدلهایی که اندازه خروجی به دادههای ورودی بستگی دارد - یعنی جایی که اندازه در زمان اجرای مدل قابل تعیین نیست - از ANeuralNetworksExecution_getOutputOperandRank و ANeuralNetworksExecution_getOutputOperandDimensions استفاده کنید.
نمونه کد زیر نحوه انجام این کار را نشان میدهد:
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
پاکسازی
مرحله پاکسازی، آزادسازی منابع داخلی مورد استفاده برای محاسبات شما را مدیریت میکند.
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
مدیریت خطا و پشتیبانی از CPU
اگر در هنگام پارتیشنبندی خطایی رخ دهد، اگر درایور نتواند یک (بخش از) مدل را کامپایل کند، یا اگر درایور نتواند یک (بخش از) مدل کامپایل شده را اجرا کند، NNAPI ممکن است به پیادهسازی CPU خود از یک یا چند عملیات بازگردد.
اگر کلاینت NNAPI حاوی نسخههای بهینهشدهای از عملیات باشد (مثلاً TFLite)، غیرفعال کردن پشتیبان CPU و مدیریت خطاها با پیادهسازی بهینهشدهی عملیات کلاینت میتواند مفید باشد.
در اندروید ۱۰، اگر کامپایل با استفاده از ANeuralNetworksCompilation_createForDevices انجام شود، آنگاه قابلیت پشتیبانی از CPU غیرفعال خواهد شد.
در اندروید P، در صورت عدم موفقیت در اجرا روی درایور، اجرای NNAPI به CPU برمیگردد. این موضوع در اندروید ۱۰ نیز صادق است، زمانی که به جای ANeuralNetworksCompilation_create از ANeuralNetworksCompilation_createForDevices استفاده میشود.
اولین اجرا به سراغ آن پارتیشن واحد میرود و اگر آن هم با شکست مواجه شود، کل مدل را روی CPU دوباره اجرا میکند.
اگر پارتیشنبندی یا کامپایل با شکست مواجه شود، کل مدل روی CPU امتحان خواهد شد.
مواردی وجود دارد که برخی از عملیات توسط CPU پشتیبانی نمیشوند و در چنین شرایطی، کامپایل یا اجرا به جای بازگشت به حالت اولیه، با شکست مواجه میشود.
حتی پس از غیرفعال کردن قابلیت پشتیبانگیری از CPU، ممکن است هنوز عملیاتی در مدل وجود داشته باشند که روی CPU زمانبندی شدهاند. اگر CPU در لیست پردازندههای ارائه شده به ANeuralNetworksCompilation_createForDevices باشد و یا تنها پردازندهای باشد که از آن عملیات پشتیبانی میکند یا پردازندهای باشد که بهترین عملکرد را برای آن عملیاتها ادعا میکند، به عنوان مجری اصلی (غیر پشتیبانگیری) انتخاب خواهد شد.
برای اطمینان از اینکه هیچ اجرایی توسط CPU انجام نمیشود، از ANeuralNetworksCompilation_createForDevices استفاده کنید و nnapi-reference از لیست دستگاهها حذف کنید. از اندروید P به بعد، میتوان با تنظیم ویژگی debug.nn.partition به مقدار ۲، در زمان اجرا در بیلدهای DEBUG، fallback را غیرفعال کرد.
دامنههای حافظه
در اندروید ۱۱ و بالاتر، NNAPI از دامنههای حافظهای پشتیبانی میکند که رابطهای تخصیصدهنده برای حافظههای غیرشفاف ارائه میدهند. این امر به برنامهها اجازه میدهد تا حافظههای بومی دستگاه را در طول اجراها منتقل کنند، به طوری که NNAPI هنگام انجام اجراهای متوالی روی همان درایور، دادهها را بیجهت کپی یا تبدیل نمیکند.
ویژگی دامنه حافظه برای تانسورهایی در نظر گرفته شده است که عمدتاً درون درایور قرار دارند و نیازی به دسترسی مکرر به سمت کلاینت ندارند. نمونههایی از چنین تانسورهایی شامل تانسورهای حالت در مدلهای توالی است. برای تانسورهایی که نیاز به دسترسی مکرر CPU در سمت کلاینت دارند، به جای آن از استخرهای حافظه مشترک استفاده کنید.
برای تخصیص حافظهی غیرشفاف، مراحل زیر را انجام دهید:
برای ایجاد یک توصیفگر حافظه جدید، تابع
ANeuralNetworksMemoryDesc_create()را فراخوانی کنید:// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
با فراخوانی
ANeuralNetworksMemoryDesc_addInputRole()وANeuralNetworksMemoryDesc_addOutputRole()تمام نقشهای ورودی و خروجی مورد نظر را مشخص کنید.// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
به صورت اختیاری، ابعاد حافظه را با فراخوانی تابع
ANeuralNetworksMemoryDesc_setDimensions()مشخص کنید.// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
تعریف توصیفگر را با فراخوانی تابع
ANeuralNetworksMemoryDesc_finish()نهایی کنید.ANeuralNetworksMemoryDesc_finish(desc);
با ارسال توصیفگر به
ANeuralNetworksMemory_createFromDesc()، هر تعداد حافظه که نیاز دارید اختصاص دهید.// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
وقتی دیگر به توصیفگر حافظه نیازی ندارید، آن را آزاد کنید.
ANeuralNetworksMemoryDesc_free(desc);
کلاینت فقط میتواند از شیء ANeuralNetworksMemory ایجاد شده با ANeuralNetworksExecution_setInputFromMemory() یا ANeuralNetworksExecution_setOutputFromMemory() مطابق با نقشهای مشخص شده در شیء ANeuralNetworksMemoryDesc استفاده کند. آرگومانهای offset و length باید روی 0 تنظیم شوند که نشان میدهد کل حافظه استفاده شده است. کلاینت همچنین میتواند با استفاده از ANeuralNetworksMemory_copy() به طور صریح محتوای حافظه را تنظیم یا استخراج کند.
شما میتوانید حافظههای مبهم با نقشهایی با ابعاد یا رتبه نامشخص ایجاد کنید. در این صورت، اگر درایور اصلی از آن پشتیبانی نکند، ایجاد حافظه ممکن است با وضعیت ANEURALNETWORKS_OP_FAILED با شکست مواجه شود. کلاینت تشویق میشود که با اختصاص یک بافر به اندازه کافی بزرگ که توسط Ashmem یا BLOB-mode AHardwareBuffer پشتیبانی میشود، منطق fallback را پیادهسازی کند.
وقتی NNAPI دیگر نیازی به دسترسی به شیء حافظهی مبهم نداشت، نمونهی ANeuralNetworksMemory مربوطه را آزاد کنید:
ANeuralNetworksMemory_free(opaqueMem);
اندازهگیری عملکرد
شما میتوانید عملکرد برنامه خود را با اندازهگیری زمان اجرا یا با پروفایلبندی ارزیابی کنید.
زمان اجرا
وقتی میخواهید کل زمان اجرا را در طول زمان اجرا تعیین کنید، میتوانید از API اجرای همزمان استفاده کنید و زمان صرف شده برای فراخوانی را اندازهگیری کنید. وقتی میخواهید کل زمان اجرا را در سطح پایینتری از پشته نرمافزار تعیین کنید، میتوانید از ANeuralNetworksExecution_setMeasureTiming و ANeuralNetworksExecution_getDuration برای دریافت موارد زیر استفاده کنید:
- زمان اجرا روی یک شتابدهنده (نه در درایور، که روی پردازنده میزبان اجرا میشود).
- زمان اجرا در راننده، شامل زمان روی پدال گاز.
زمان اجرا در درایور، سربارهایی مانند سربار خودِ زمان اجرا و IPC مورد نیاز برای ارتباط زمان اجرا با درایور را شامل نمیشود.
این APIها مدت زمان بین کار ارسالی و رویدادهای تکمیلشدهی کار را اندازهگیری میکنند، نه زمانی که یک درایور یا شتابدهنده به انجام استنتاج اختصاص میدهد، که احتمالاً با تغییر زمینه قطع میشود.
برای مثال، اگر استنتاج ۱ شروع شود، سپس درایور کار را برای انجام استنتاج ۲ متوقف کند، سپس دوباره شروع به کار کند و استنتاج ۱ را تکمیل کند، زمان اجرای استنتاج ۱ شامل زمانی خواهد بود که کار برای انجام استنتاج ۲ متوقف شده بود.
این اطلاعات زمانبندی ممکن است برای استقرار در محیط عملیاتی یک برنامه جهت جمعآوری دادههای تلهمتری برای استفاده آفلاین مفید باشد. میتوانید از دادههای زمانبندی برای تغییر برنامه جهت عملکرد بالاتر استفاده کنید.
هنگام استفاده از این قابلیت، موارد زیر را در نظر داشته باشید:
- جمعآوری اطلاعات زمانبندی ممکن است هزینه عملکردی داشته باشد.
- فقط یک درایور قادر به محاسبه زمان صرف شده در خودش یا روی شتابدهنده است، به استثنای زمان صرف شده در زمان اجرای NNAPI و در IPC.
- شما میتوانید از این APIها فقط با
ANeuralNetworksExecutionکه باANeuralNetworksCompilation_createForDevicesباnumDevices = 1ایجاد شده است، استفاده کنید. - No driver is required to be able to report timing information.
Profile your application with Android Systrace
Starting with Android 10, NNAPI automatically generates systrace events that you can use to profile your application.
The NNAPI Source comes with a parse_systrace utility to process the systrace events generated by your application and generate a table view showing the time spent in the different phases of the model lifecycle (Instantiation, Preparation, Compilation Execution and Termination) and different layers of the applications. The layers in which your application is split are:
-
Application: the main application code -
Runtime: NNAPI Runtime -
IPC: The inter process communication between NNAPI Runtime and the Driver code -
Driver: the accelerator driver process.
Generate the profiling analysys data
Assuming you checked out the AOSP source tree at $ANDROID_BUILD_TOP, and using the TFLite image classification example as target application, you can generate the NNAPI profiling data with the following steps:
- Start the Android systrace with the following command:
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
The -o trace.html parameter indicates that the traces will be written in the trace.html . When profiling own application you will need to replace org.tensorflow.lite.examples.classification with the process name specified in your app manifest.
This will keep one of your shell console busy, don't run the command in background since it is interactively waiting for an enter to terminate.
- After the systrace collector is started, start your app and run your benchmark test.
In our case you can start the Image Classification app from Android Studio or directly from your test phone UI if the app has already been installed. To generate some NNAPI data you need to configure the app to use NNAPI by selecting NNAPI as target device in the app configuration dialog.
When the test completes, terminate the systrace by pressing
enteron the console terminal active since step 1.Run the
systrace_parserutility generate cumulative statistics:
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
The parser accepts the following parameters: - --total-times : shows the total time spent in a layer including the time spent waiting for execution on a call to an underlying layer - --print-detail : prints all the events that have been collected from systrace - --per-execution : prints only the execution and its subphases (as per-execution times) instead of stats for all phases - --json : produces the output in JSON format
An example of the output is shown below:
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
The parser might fail if the collected events do not represent a complete application trace. In particular it might fail if systrace events generated to mark the end of a section are present in the trace without an associated section start event. This usually happens if some events from a previous profiling session are being generated when you start the systrace collector. In this case you would have to run your profiling again.
Add statistics for your application code to systrace_parser output
The parse_systrace application is based on the built-in Android systrace functionality. You can add traces for specific operations in your app using the systrace API ( for Java , for native applications ) with custom event names.
To associate your custom events with phases of the Application lifecycle, prepend your event name with one of the following strings:
-
[NN_LA_PI]: Application level event for Initialization -
[NN_LA_PP]: Application level event for Preparation -
[NN_LA_PC]: Application level event for Compilation -
[NN_LA_PE]: Application level event for Execution
Here is an example of how you can alter the TFLite image classification example code by adding a runInferenceModel section for the Execution phase and the Application layer containing another other sections preprocessBitmap that won't be considered in NNAPI traces. The runInferenceModel section will be part of the systrace events processed by the nnapi systrace parser:
کاتلین
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
جاوا
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
کیفیت خدمات
In Android 11 and higher, NNAPI enables better quality of service (QoS) by allowing an application to indicate the relative priorities of its models, the maximum amount of time expected to prepare a given model, and the maximum amount of time expected to complete a given computation. Android 11 also introduces additional NNAPI result codes that enable applications to understand failures such as missed execution deadlines.
Set the priority of a workload
To set the priority of an NNAPI workload, call ANeuralNetworksCompilation_setPriority() prior to calling ANeuralNetworksCompilation_finish() .
Set deadlines
Applications can set deadlines for both model compilation and inference.
- To set the compilation timeout, call
ANeuralNetworksCompilation_setTimeout()prior to callingANeuralNetworksCompilation_finish(). - To set the inference timeout, call
ANeuralNetworksExecution_setTimeout()prior to starting the compilation .
More about operands
The following section covers advanced topics about using operands.
Quantized tensors
A quantized tensor is a compact way to represent an n-dimensional array of floating point values.
NNAPI supports 8-bit asymmetric quantized tensors. For these tensors, the value of each cell is represented by an 8-bit integer. Associated with the tensor is a scale and a zero point value. These are used to convert the 8-bit integers into the floating point values that are being represented.
فرمول این است:
(cellValue - zeroPoint) * scale
where the zeroPoint value is a 32-bit integer and the scale a 32-bit floating point value.
Compared to tensors of 32-bit floating point values, 8-bit quantized tensors have two advantages:
- Your application is smaller, as the trained weights take a quarter of the size of 32-bit tensors.
- Computations can often be executed faster. This is due to the smaller amount of data that needs to be fetched from memory and the efficiency of processors such as DSPs in doing integer math.
While it is possible to convert a floating point model to a quantized one, our experience has shown that better results are achieved by training a quantized model directly. In effect, the neural network learns to compensate for the increased granularity of each value. For each quantized tensor, the scale and zeroPoint values are determined during the training process.
In NNAPI, you define quantized tensor types by setting the type field of the ANeuralNetworksOperandType data structure to ANEURALNETWORKS_TENSOR_QUANT8_ASYMM . You also specify the scale and zeroPoint value of the tensor in that data structure.
In addition to 8-bit asymmetric quantized tensors, NNAPI supports the following:
-
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNELwhich you can use for representing weights toCONV/DEPTHWISE_CONV/TRANSPOSED_CONVoperations. -
ANEURALNETWORKS_TENSOR_QUANT16_ASYMMwhich you can use for the internal state ofQUANTIZED_16BIT_LSTM. -
ANEURALNETWORKS_TENSOR_QUANT8_SYMMwhich can be an input toANEURALNETWORKS_DEQUANTIZE.
Optional operands
A few operations, like ANEURALNETWORKS_LSH_PROJECTION , take optional operands. To indicate in the model that the optional operand is omitted, call the ANeuralNetworksModel_setOperandValue() function, passing NULL for the buffer and 0 for the length.
If the decision on whether the operand is present or not varies for each execution, you indicate that the operand is omitted by using the ANeuralNetworksExecution_setInput() or ANeuralNetworksExecution_setOutput() functions, passing NULL for the buffer and 0 for the length.
Tensors of unknown rank
Android 9 (API level 28) introduced model operands of unknown dimensions but known rank (the number of dimensions). Android 10 (API level 29) introduced tensors of unknown rank, as shown in ANeuralNetworksOperandType .
NNAPI benchmark
The NNAPI benchmark is available on AOSP in platform/test/mlts/benchmark (benchmark app) and platform/test/mlts/models (models and datasets).
The benchmark evaluates latency and accuracy and compares drivers to the same work done using Tensorflow Lite running on the CPU, for the same models and datasets.
To use the benchmark, do the following:
Connect a target Android device to your computer, open a terminal window, and make sure the device is reachable through adb.
If more than one Android device is connected, export the target device
ANDROID_SERIALenvironment variable.Navigate to the Android top-level source directory.
Run the following commands:
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
At the end of a benchmark run, its results will be presented as an HTML page passed to
xdg-open.
NNAPI logs
NNAPI generates useful diagnostic information in the system logs. To analyze the logs, use the logcat utility.
Enable verbose NNAPI logging for specific phases or components by setting the property debug.nn.vlog (using adb shell ) to the following list of values, separated by space, colon, or comma:
-
model: Model building -
compilation: Generation of the model execution plan and compilation -
execution: Model execution -
cpuexe: Execution of operations using the NNAPI CPU implementation -
manager: NNAPI extensions, available interfaces and capabilities related info -
allor1: All the elements above
For example, to enable full verbose logging use the command adb shell setprop debug.nn.vlog all . To disable verbose logging, use the command adb shell setprop debug.nn.vlog '""' .
Once enabled, verbose logging generates log entries at INFO level with a tag set to the phase or component name.
Beside the debug.nn.vlog controlled messages, NNAPI API components provide other log entries at various levels, each one using a specific log tag.
To get a list of components, search the source tree using the following expression:
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
This expression currently returns the following tags:
- BurstBuilder
- تماسهای برگشتی
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- مدیر
- حافظه
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- عملیات
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- یوتیلز
- ValidateHal
- VersionedInterfaces
To control the level of log messages shown by logcat , use the environment variable ANDROID_LOG_TAGS .
To show the full set of NNAPI log messages and disable any others, set ANDROID_LOG_TAGS to the following:
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
You can set ANDROID_LOG_TAGS using the following command:
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
Note that this is just a filter that applies to logcat . You still need to set the property debug.nn.vlog to all to generate verbose log info.