
Android Neural Networks API (NNAPI) هي واجهة برمجة تطبيقات C لنظام التشغيل Android مصمَّمة لتنفيذ عمليات تتطلّب قدرًا كبيرًا من الحسابات لتعلُّم الآلة على أجهزة Android. تم تصميم NNAPI لتوفير طبقة أساسية من الوظائف لأُطر عمل تعلُّم الآلة ذات المستوى الأعلى، مثل TensorFlow Lite وCaffe2، التي تنشئ الشبكات العصبية وتدرّبها. تتوفّر واجهة برمجة التطبيقات على جميع أجهزة Android التي تعمل بالإصدار 8.1 من نظام التشغيل Android (المستوى 27 من واجهة برمجة التطبيقات) أو الإصدارات الأحدث، ولكن تم إيقافها نهائيًا في Android 15.
تتيح واجهة برمجة التطبيقات NNAPI الاستدلال من خلال تطبيق البيانات من أجهزة Android على النماذج التي تم تدريبها مسبقًا والتي يحددها المطوّرون. تشمل أمثلة الاستدلال تصنيف الصور وتوقُّع سلوك المستخدم واختيار الردود المناسبة لطلب بحث.
تقدّم الاستدلال على الجهاز مزايا عديدة، منها:
- وقت الاستجابة: لا تحتاج إلى إرسال طلب عبر اتصال شبكة والانتظار للحصول على رد. على سبيل المثال، يمكن أن يكون ذلك مهمًا للتطبيقات التي تعالج مقاطع فيديو متتالية من كاميرا.
- التوفّر: يعمل التطبيق حتى عندما يكون خارج نطاق تغطية الشبكة.
- السرعة: توفّر الأجهزة الجديدة المخصّصة لمعالجة الشبكات العصبية عمليات حسابية أسرع بكثير من وحدة المعالجة المركزية العامة وحدها.
- الخصوصية: لا تتم مغادرة البيانات لجهاز Android.
- التكلفة: لا حاجة إلى مزارع الخوادم عندما تتم جميع العمليات الحسابية على جهاز Android.
هناك أيضًا بعض المفاضلات التي يجب أن يضعها المطوّر في اعتباره:
- استخدام النظام: يتطلّب تقييم الشبكات العصبية إجراء الكثير من العمليات الحسابية، ما قد يؤدي إلى زيادة استهلاك طاقة البطارية. عليك مراقبة صحة البطارية إذا كان ذلك يهم تطبيقك، خاصةً بالنسبة إلى العمليات الحسابية الطويلة الأمد.
- حجم التطبيق: انتبه إلى حجم نماذجك. قد تشغل النماذج مساحة تصل إلى عدة ميغابايت. إذا كان تجميع النماذج الكبيرة في حِزمة APK سيؤثر بشكل غير مبرّر في المستخدمين، يمكنك تنزيل النماذج بعد تثبيت التطبيق أو استخدام نماذج أصغر أو تنفيذ العمليات الحسابية في السحابة الإلكترونية. لا توفّر واجهة برمجة التطبيقات NNAPI وظائف لتشغيل النماذج على السحابة الإلكترونية.
اطّلِع على نموذج واجهة برمجة التطبيقات Android Neural Networks API للاطّلاع على مثال حول كيفية استخدام NNAPI.
فهم وقت تشغيل Neural Networks API
من المفترض أن يتم استدعاء NNAPI من خلال مكتبات وأُطر وأدوات تعلُّم الآلة التي تتيح للمطوّرين تدريب نماذجهم خارج الجهاز ونشرها على أجهزة Android. لا تستخدم التطبيقات عادةً واجهة برمجة التطبيقات NNAPI مباشرةً، بل تستخدم بدلاً من ذلك أُطر تعلُّم آلي ذات مستوى أعلى. ويمكن أن تستخدم هذه الأُطر بدورها واجهة برمجة التطبيقات NNAPI لتنفيذ عمليات الاستدلال التي يتم تسريعها بواسطة الأجهزة على الأجهزة المتوافقة.
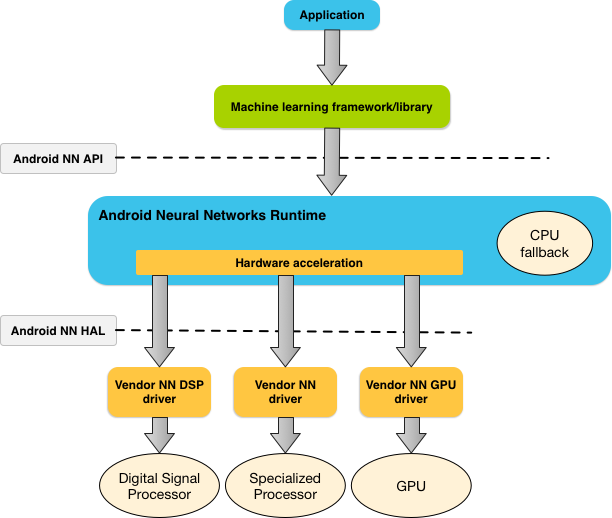
استنادًا إلى متطلبات التطبيق وإمكانات الأجهزة على جهاز Android، يمكن لوقت تشغيل الشبكة العصبية في Android توزيع عبء العمل الحسابي بكفاءة على المعالِجات المتاحة على الجهاز، بما في ذلك أجهزة الشبكة العصبية المخصّصة ووحدات معالجة الرسومات (GPU) ومعالِجات الإشارات الرقمية (DSP).
بالنسبة إلى أجهزة Android التي لا تتضمّن برنامج تشغيل مخصّصًا من المورّد، ينفّذ وقت تشغيل NNAPI الطلبات على وحدة المعالجة المركزية.
يوضّح الشكل 1 بنية النظام العالية المستوى لواجهة برمجة التطبيقات NNAPI.
نموذج برمجة Neural Networks API
لإجراء عمليات حسابية باستخدام NNAPI، عليك أولاً إنشاء رسم بياني موجّه يحدّد العمليات الحسابية التي سيتم إجراؤها. يؤدي دمج الرسم البياني للحساب هذا مع بيانات الإدخال (مثل الأوزان والانحيازات التي يتم تمريرها من إطار عمل تعلُّم آلي) إلى إنشاء نموذج لتقييم وقت التشغيل في NNAPI.
تستخدم واجهة برمجة التطبيقات NNAPI أربع تجريدات رئيسية:
- النموذج: رسم بياني للحسابات يتضمّن العمليات الرياضية والقيم الثابتة التي يتم تعلّمها من خلال عملية التدريب هذه العمليات خاصة بالشبكات العصبية. وتشمل هذه العمليات الالتفاف الثنائي الأبعاد (2D) وعملية التنشيط اللوجستية (الدالة السينية) وعملية التنشيط الخطية المعدَّلة (ReLU) وغير ذلك. إنشاء نموذج هو عملية متزامنة.
بعد إنشائه بنجاح، يمكن إعادة استخدامه في سلاسل محادثات ومجموعات متعددة.
في NNAPI، يتم تمثيل النموذج على أنّه
ANeuralNetworksModel. - التجميع: يمثّل إعدادًا لتجميع نموذج NNAPI في رمز منخفض المستوى. إنشاء تجميع هو عملية متزامنة. بعد إنشائه بنجاح، يمكن إعادة استخدامه في سلاسل التنفيذ وعمليات التنفيذ. في NNAPI، يتم تمثيل كل عملية تجميع على أنّها مثيل
ANeuralNetworksCompilation. - الذاكرة: تمثّل الذاكرة المشتركة والملفات التي تم ربطها بالذاكرة ومخازن الذاكرة المشابهة. يتيح استخدام مخزن مؤقت للذاكرة لوقت تشغيل NNAPI نقل البيانات إلى برامج التشغيل
بشكل أكثر كفاءة. ينشئ التطبيق عادةً مخزنًا مؤقتًا واحدًا للذاكرة المشتركة يحتوي على كل موتر مطلوب لتحديد نموذج. يمكنك أيضًا استخدام مخازن مؤقتة للذاكرة لتخزين المدخلات والمخرجات الخاصة بمثيل التنفيذ. في NNAPI، يتم تمثيل كل مخزن مؤقت للذاكرة كعنصر
ANeuralNetworksMemory. التنفيذ: واجهة لتطبيق نموذج NNAPI على مجموعة من المدخلات وجمع النتائج يمكن تنفيذ الإجراء بشكل متزامن أو غير متزامن.
بالنسبة إلى التنفيذ غير المتزامن، يمكن أن تنتظر سلاسل متعددة عملية التنفيذ نفسها. عند اكتمال هذا التنفيذ، يتم تحرير جميع سلاسل التعليمات.
في NNAPI، يتم تمثيل كل عملية تنفيذ كـ
ANeuralNetworksExecution.
يوضّح الشكل 2 مسار البرمجة الأساسي.
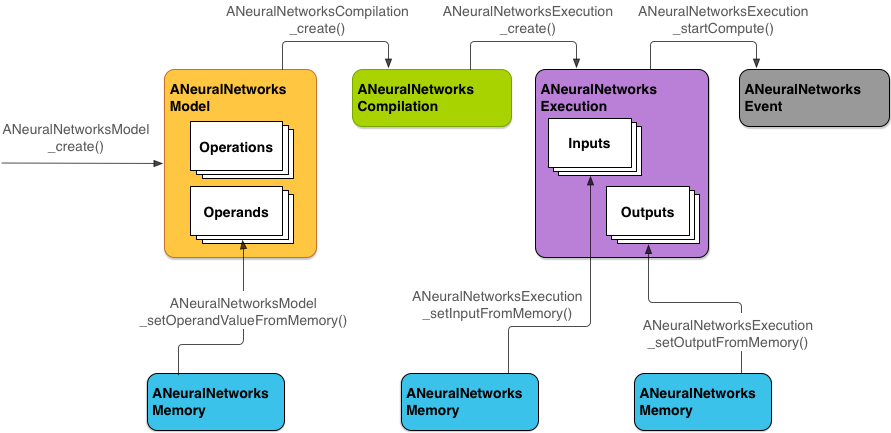
يصف الجزء المتبقي من هذا القسم خطوات إعداد نموذج NNAPI لتنفيذ العمليات الحسابية وتجميع النموذج وتنفيذ النموذج المجمَّع.
توفير إمكانية الوصول إلى بيانات التدريب
من المحتمل أن يتم تخزين بيانات الأوزان والانحيازات المدرَّبة في ملف. لتوفير وصول فعّال إلى بيانات وقت التشغيل في NNAPI، أنشئ مثيلاً من ANeuralNetworksMemory من خلال استدعاء الدالة ANeuralNetworksMemory_createFromFd() وتمرير واصف الملف لملف البيانات المفتوح. يمكنك أيضًا تحديد علامات حماية الذاكرة وإزاحة حيث يبدأ جزء الذاكرة المشتركة في الملف.
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
على الرغم من أنّنا نستخدم في هذا المثال مثيلاً واحدًا
ANeuralNetworksMemory
لجميع الأوزان، يمكن استخدام أكثر من مثيل واحد
ANeuralNetworksMemory لملفات متعددة.
استخدام مخازن مؤقتة للأجهزة الأصلية
يمكنك استخدام مخازن مؤقتة للأجهزة الأصلية
لإدخالات النماذج ومخرجاتها وقيم المعامِلات الثابتة. في حالات معيّنة، يمكن لمسرّع NNAPI الوصول إلى عناصر AHardwareBuffer بدون أن يحتاج برنامج التشغيل إلى نسخ البيانات. يتضمّن AHardwareBuffer العديد من الإعدادات المختلفة، وقد لا يتيح كل مسرّع NNAPI استخدام جميع هذه الإعدادات. وبسبب هذا القيد، يُرجى الرجوع إلى القيود الواردة في مستندات ANeuralNetworksMemory_createFromAHardwareBuffer المرجعية وإجراء اختبار مسبق على الأجهزة المستهدَفة لضمان عمل عمليات التجميع والتنفيذ التي تستخدم AHardwareBuffer على النحو المتوقّع، وذلك باستخدام تعيين الجهاز لتحديد أداة التسريع.
للسماح لوقت تشغيل NNAPI بالوصول إلى عنصر AHardwareBuffer، أنشئ مثيلاً من ANeuralNetworksMemory من خلال استدعاء الدالة ANeuralNetworksMemory_createFromAHardwareBuffer وتمرير عنصر AHardwareBuffer، كما هو موضّح في نموذج الرمز البرمجي التالي:
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
عندما لا يحتاج NNAPI إلى الوصول إلى الكائن AHardwareBuffer، يجب تحرير مثيل ANeuralNetworksMemory المقابل:
ANeuralNetworksMemory_free(mem2);
ملاحظة:
- يمكنك استخدام
AHardwareBufferمع المخزن المؤقت بأكمله فقط، ولا يمكنك استخدامه مع المَعلمةARect. - لن يمحو وقت تشغيل NNAPI المخزن المؤقت. يجب التأكّد من إمكانية الوصول إلى مخازن الإدخال والإخراج المؤقتة قبل جدولة التنفيذ.
- لا تتوفّر إمكانية استخدام واصفات ملفات سياج المزامنة.
- بالنسبة إلى
AHardwareBufferالذي يتضمّن تنسيقات واستخدامات خاصة بالمورّد، يعود إلى عملية التنفيذ التي يجريها المورّد تحديد ما إذا كان العميل أو برنامج التشغيل مسؤولاً عن إفراغ ذاكرة التخزين المؤقت.
الطراز
النموذج هو وحدة الحوسبة الأساسية في NNAPI. يتم تحديد كل نموذج من خلال معامل واحد أو أكثر وعمليات.
المعاملات
المعاملات هي عناصر بيانات تُستخدم في تحديد الرسم البياني. وتشمل هذه العناصر مدخلات النموذج ومخرجاته، والعُقد الوسيطة التي تحتوي على البيانات التي تنتقل من عملية إلى أخرى، والثوابت التي يتم تمريرها إلى هذه العمليات.
هناك نوعان من المعامِلات التي يمكن إضافتها إلى نماذج NNAPI: القيم العددية والموترات.
يمثّل النوع العددي قيمة واحدة. تتيح واجهة برمجة التطبيقات NNAPI استخدام قيم عددية بتنسيقات منطقية، ونقطة عائمة 16 بت، ونقطة عائمة 32 بت، وعدد صحيح 32 بت، وعدد صحيح غير موقّع 32 بت.
تتضمّن معظم العمليات في NNAPI موترات. الموتّرات هي صفائف متعددة الأبعاد. تتيح واجهة برمجة التطبيقات NNAPI موترات ذات قيم نقطة عائمة 16 بت ونقطة عائمة 32 بت وكمية 8 بت وكمية 16 بت وعدد صحيح 32 بت وقيم منطقية 8 بت.
على سبيل المثال، يمثّل الشكل 3 نموذجًا يتضمّن عمليتَين: عملية جمع تليها عملية ضرب. يتلقّى النموذج موتر إدخال وينتج موتر إخراج.
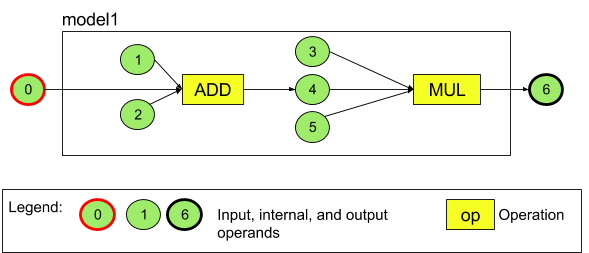
يحتوي النموذج أعلاه على سبعة معاملات. يتم تحديد معاملات التشغيل هذه ضمنيًا من خلال فهرس الترتيب الذي تمت إضافتها به إلى النموذج. يحمل المعامل الأول المضاف الفهرس 0، ويحمل المعامل الثاني الفهرس 1، وهكذا. المعاملات 1 و2 و3 و5 هي معاملات ثابتة.
لا يهم ترتيب إضافة المعامِلات. على سبيل المثال، يمكن أن يكون عامل تشغيل إخراج النموذج هو أول عامل يتم إضافته. والجزء المهم هو استخدام قيمة الفهرس الصحيحة عند الإشارة إلى عامل.
للمُعاملات أنواع. يتم تحديد هذه القيم عند إضافتها إلى النموذج.
لا يمكن استخدام عامل التشغيل كمدخل ومخرج لنموذج في الوقت نفسه.
يجب أن يكون كل عامل إدخال إما إدخال نموذج أو ثابتًا أو عامل إخراج عملية واحدة فقط.
لمزيد من المعلومات حول استخدام المعامِلات، يُرجى الاطّلاع على مزيد من المعلومات حول المعامِلات.
العمليات
تحدّد العملية الحسابات المطلوب إجراؤها. تتألف كل عملية مما يلي:
- نوع العملية (مثل الجمع أو الضرب أو الالتفاف)
- قائمة بفهارس المعامِلات التي تستخدمها العملية كمدخلات
- قائمة بفهارس المعامِلات التي تستخدمها العملية في الإخراج
ويُعد الترتيب في هذه القوائم مهمًا، لذا راجِع مرجع واجهة برمجة التطبيقات NNAPI لمعرفة المدخلات والمخرجات المتوقّعة لكل نوع من العمليات.
يجب إضافة المعامِلات التي تستهلكها عملية أو تنتجها إلى النموذج قبل إضافة العملية.
لا يهم ترتيب العمليات التي تضيفها. تعتمد NNAPI على التبعيات التي تم إنشاؤها بواسطة الرسم البياني للحساب الخاص بالمعامِلات والعمليات لتحديد ترتيب تنفيذ العمليات.
يرد في الجدول أدناه ملخّص للعمليات التي تتوافق مع NNAPI:
مشكلة معروفة في المستوى 28 من واجهة برمجة التطبيقات: عند تمرير موترات
ANEURALNETWORKS_TENSOR_QUANT8_ASYMM
إلى عملية
ANEURALNETWORKS_PAD
المتاحة على الإصدار 9 من نظام التشغيل Android (المستوى 28 من واجهة برمجة التطبيقات) والإصدارات الأحدث، قد لا يتطابق الناتج من NNAPI مع الناتج من أُطر تعلُّم الآلة ذات المستوى الأعلى، مثل
TensorFlow Lite. بدلاً من ذلك، يجب تمرير ANEURALNETWORKS_TENSOR_FLOAT32 فقط.
تم حلّ المشكلة في الإصدار 10 من نظام التشغيل Android (المستوى 29 لواجهة برمجة التطبيقات) والإصدارات الأحدث.
إنشاء نماذج
في المثال التالي، ننشئ نموذج العمليتَين الموضّح في الشكل 3.
لإنشاء النموذج، اتّبِع الخطوات التالية:
استدعِ الدالة
ANeuralNetworksModel_create()لتحديد نموذج فارغ.ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
أضِف المعامِلات إلى النموذج عن طريق استدعاء
ANeuralNetworks_addOperand(). يتم تحديد أنواع البيانات باستخدام بنية البياناتANeuralNetworksOperandType.// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6بالنسبة إلى المعامِلات التي تتضمّن قيمًا ثابتة، مثل الأوزان والانحيازات التي يحصل عليها تطبيقك من عملية تدريب، استخدِم الدالتَين
ANeuralNetworksModel_setOperandValue()وANeuralNetworksModel_setOperandValueFromMemory().في المثال التالي، نضبط القيم الثابتة من ملف بيانات التدريب بما يتوافق مع مخزن الذاكرة المؤقتة الذي أنشأناه في توفير إذن الوصول إلى بيانات التدريب.
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));لكل عملية في الرسم البياني الموجّه الذي تريد حسابه، أضِف العملية إلى النموذج من خلال استدعاء الدالة
ANeuralNetworksModel_addOperation().يجب أن يوفّر تطبيقك ما يلي كمَعلمات لهذا الطلب:
- نوع العملية
- عدد القيم المُدخَلة
- مصفوفة الفهارس الخاصة بعوامل الإدخال
- عدد القيم الناتجة
- مصفوفة فهارس معاملات الإخراج
يُرجى العِلم أنّه لا يمكن استخدام عامل في كلّ من الإدخال والإخراج للعملية نفسها.
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);تحديد المعامِلات التي يجب أن يتعامل معها النموذج كمدخلات ومخرجات من خلال استدعاء الدالة
ANeuralNetworksModel_identifyInputsAndOutputs()// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
يمكنك اختياريًا تحديد ما إذا كان مسموحًا بحساب
ANEURALNETWORKS_TENSOR_FLOAT32باستخدام نطاق أو دقة منخفضة مثل تلك الخاصة بتنسيق IEEE 754 16-bit floating-point من خلال استدعاءANeuralNetworksModel_relaxComputationFloat32toFloat16().اتّصِل بالرقم
ANeuralNetworksModel_finish()لإنهاء تعريف النموذج. إذا لم تكن هناك أخطاء، ستعرض هذه الدالة رمز النتيجةANEURALNETWORKS_NO_ERROR.ANeuralNetworksModel_finish(model);
بعد إنشاء نموذج، يمكنك تجميعه أي عدد من المرات وتنفيذ كل عملية تجميع أي عدد من المرات.
التحكّم في التدفق
لدمج عملية التحكّم في التدفق في نموذج NNAPI، اتّبِع الخطوات التالية:
إنشاء الرسومات البيانية الفرعية المقابلة للتنفيذ (الرسومات البيانية الفرعية
thenوelseلعبارةIF، والرسومات البيانية الفرعيةconditionوbodyلحلقةWHILE) كنماذجANeuralNetworksModel*مستقلة:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
أنشئ معاملات تشير إلى هذه النماذج ضمن النموذج الذي يحتوي على تدفق التحكّم:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
أضِف عملية تدفّق التحكّم:
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
موسيقى مجمّعة
تحدّد خطوة التجميع المعالِجات التي سيتم تنفيذ النموذج عليها، وتطلب من برامج التشغيل ذات الصلة الاستعداد لتنفيذه. وقد يشمل ذلك إنشاء رمز آلة مخصّص للمعالِجات التي سيتم تشغيل النموذج عليها.
لتجميع نموذج، اتّبِع الخطوات التالية:
استدعِ الدالة
ANeuralNetworksCompilation_create()لإنشاء مثيل تجميع جديد.// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
يمكنك اختياريًا استخدام تعيين الأجهزة لاختيار الأجهزة التي سيتم تنفيذ الاختبار عليها بشكل صريح.
يمكنك اختياريًا التأثير في كيفية الموازنة بين استهلاك طاقة البطارية وسرعة التنفيذ في وقت التشغيل. يمكنك إجراء ذلك من خلال الاتصال بالرقم
ANeuralNetworksCompilation_setPreference().// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
تشمل الإعدادات المفضّلة التي يمكنك تحديدها ما يلي:
ANEURALNETWORKS_PREFER_LOW_POWER: يجب تنفيذ العملية بطريقة تقلّل من استنزاف البطارية. وهذا أمر مرغوب فيه بالنسبة إلى عمليات التجميع التي يتم تنفيذها بشكل متكرر.ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: يُفضّل عرض إجابة واحدة بأسرع ما يمكن، حتى إذا كان ذلك يؤدي إلى استهلاك المزيد من الطاقة. هذا هو الخيار التلقائي.ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: يُفضّل زيادة سرعة نقل اللقطات المتتالية إلى أقصى حد، مثلاً عند معالجة اللقطات المتتالية الواردة من الكاميرا.
يمكنك اختياريًا إعداد التخزين المؤقت للتجميع عن طريق استدعاء
ANeuralNetworksCompilation_setCaching.// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
استخدِم
getCodeCacheDir()للحصول علىcacheDir. يجب أن يكونtokenالمحدّد فريدًا لكل نموذج ضمن التطبيق.أكمِل تعريف التجميع من خلال استدعاء
ANeuralNetworksCompilation_finish(). إذا لم تكن هناك أخطاء، ستعرض هذه الدالة رمز نتيجةANEURALNETWORKS_NO_ERROR.ANeuralNetworksCompilation_finish(compilation);
رصد الأجهزة وتحديدها
على أجهزة Android التي تعمل بالإصدار 10 (المستوى 29 لواجهة برمجة التطبيقات) والإصدارات الأحدث، توفّر واجهة برمجة التطبيقات NNAPI وظائف تتيح لمكتبات وأطر عمل تعلُّم الآلة الحصول على معلومات حول الأجهزة المتاحة وتحديد الأجهزة التي سيتم استخدامها للتنفيذ. يسمح توفير معلومات عن الأجهزة المتاحة للتطبيقات بالحصول على الإصدار الدقيق من برامج التشغيل المتوفّرة على الجهاز لتجنُّب حالات عدم التوافق المعروفة. من خلال منح التطبيقات القدرة على تحديد الأجهزة التي سيتم عليها تنفيذ أقسام مختلفة من أحد النماذج، يمكن تحسين التطبيقات لتتوافق مع جهاز Android الذي يتم نشرها عليه.
رصد الأجهزة
استخدِم
ANeuralNetworks_getDeviceCount
للحصول على عدد الأجهزة المتاحة. بالنسبة إلى كل جهاز، استخدِم
ANeuralNetworks_getDevice
لضبط مثيل ANeuralNetworksDevice على مرجع لهذا الجهاز.
بعد الحصول على مرجع جهاز، يمكنك الاطّلاع على معلومات إضافية عن هذا الجهاز باستخدام الدوال التالية:
ANeuralNetworksDevice_getFeatureLevelANeuralNetworksDevice_getNameANeuralNetworksDevice_getTypeANeuralNetworksDevice_getVersion
تعيين الجهاز
استخدِم
ANeuralNetworksModel_getSupportedOperationsForDevices
للاطّلاع على العمليات التي يمكن تنفيذها على طُرز أجهزة معيّنة.
للتحكّم في مسرّعات التنفيذ التي سيتم استخدامها، استخدِم
ANeuralNetworksCompilation_createForDevices
بدلاً من ANeuralNetworksCompilation_create.
استخدِم عنصر ANeuralNetworksCompilation الناتج كالمعتاد.
تعرض الدالة خطأ إذا كان النموذج المقدَّم يحتوي على عمليات غير متوافقة مع الأجهزة المحدّدة.
في حال تحديد أجهزة متعددة، يكون وقت التشغيل مسؤولاً عن توزيع العمل على الأجهزة.
على غرار الأجهزة الأخرى، يتم تمثيل تنفيذ وحدة المعالجة المركزية NNAPI بواسطة ANeuralNetworksDevice بالاسم nnapi-reference والنوع ANEURALNETWORKS_DEVICE_TYPE_CPU. عند استدعاء
ANeuralNetworksCompilation_createForDevices، لا يتم استخدام تنفيذ وحدة المعالجة المركزية (CPU) للتعامل مع حالات تعذُّر تجميع النموذج وتنفيذه.
ويقع على عاتق التطبيق مسؤولية تقسيم النموذج إلى نماذج فرعية يمكن تشغيلها على الأجهزة المحدّدة. يجب أن تستمر التطبيقات التي لا تحتاج إلى تقسيم يدوي في استدعاء الدالة ANeuralNetworksCompilation_create الأبسط
لاستخدام جميع الأجهزة المتاحة (بما في ذلك وحدة المعالجة المركزية) لتسريع
النموذج. إذا تعذّر توفير الدعم الكامل للنموذج على الأجهزة التي حدّدتها باستخدام ANeuralNetworksCompilation_createForDevices، سيتم عرض ANEURALNETWORKS_BAD_DATA.
تقسيم النموذج
عندما تتوفّر أجهزة متعددة للنموذج، يوزّع وقت تشغيل NNAPI العمل على الأجهزة. على سبيل المثال، إذا تم توفير أكثر من جهاز واحد إلى ANeuralNetworksCompilation_createForDevices، سيتم أخذ جميع الأجهزة المحدّدة في الاعتبار عند تخصيص العمل. يُرجى العِلم أنّه في حال عدم إدراج جهاز وحدة المعالجة المركزية في القائمة، سيتم إيقاف تنفيذ وحدة المعالجة المركزية. عند استخدام ANeuralNetworksCompilation_create،
سيتم أخذ جميع الأجهزة المتاحة في الاعتبار، بما في ذلك وحدة المعالجة المركزية.
يتم التوزيع عن طريق الاختيار من قائمة الأجهزة المتاحة، ولكل عملية في النموذج، يتم اختيار الجهاز الذي يتيح تنفيذ العملية ويحقق أفضل أداء، أي أسرع وقت تنفيذ أو أقل استهلاك للطاقة، وذلك حسب خيار التنفيذ الذي يحدده العميل. لا يأخذ خوارزمية التقسيم هذه في الاعتبار أوجه القصور المحتملة الناتجة عن عمليات الإدخال والإخراج بين المعالِجات المختلفة، لذا عند تحديد معالِجات متعددة (إما بشكل صريح عند استخدام ANeuralNetworksCompilation_createForDevices أو بشكل ضِمني عند استخدام ANeuralNetworksCompilation_create)، من المهم تحديد خصائص التطبيق الناتج.
لمعرفة كيفية تقسيم نموذجك بواسطة NNAPI، راجِع سجلّات Android بحثًا عن رسالة (على مستوى INFO مع العلامة ExecutionPlan):
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name هو الاسم الوصفي للعملية في الرسم البياني، وdevice-index هو فهرس الجهاز المرشّح في قائمة الأجهزة.
هذه القائمة هي الإدخال المقدَّم إلى ANeuralNetworksCompilation_createForDevices، أو إذا كنت تستخدم ANeuralNetworksCompilation_createForDevices، تكون القائمة هي قائمة الأجهزة التي يتم عرضها عند تكرار جميع الأجهزة باستخدام ANeuralNetworks_getDeviceCount وANeuralNetworks_getDevice.
الرسالة (على مستوى INFO مع العلامة ExecutionPlan):
ModelBuilder::partitionTheWork: only one best device: device-name
تشير هذه الرسالة إلى أنّه تم تسريع الرسم البياني بأكمله على الجهاز device-name.
التنفيذ
تطبِّق خطوة التنفيذ النموذج على مجموعة من المدخلات وتخزِّن نواتج العمليات الحسابية في مخزن مؤقت واحد أو أكثر أو مساحات ذاكرة خصّصها تطبيقك.
لتنفيذ نموذج تم تجميعه، اتّبِع الخطوات التالية:
استدعِ الدالة
ANeuralNetworksExecution_create()لإنشاء مثيل تنفيذ جديد.// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
حدِّد المكان الذي يقرأ فيه تطبيقك قيم الإدخال لإجراء العمليات الحسابية. يمكن لتطبيقك قراءة قيم الإدخال من مخزن مؤقت للمستخدم أو مساحة ذاكرة مخصّصة من خلال استدعاء
ANeuralNetworksExecution_setInput()أوANeuralNetworksExecution_setInputFromMemory()على التوالي.// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
حدِّد المكان الذي يكتب فيه تطبيقك قيم الإخراج. يمكن لتطبيقك كتابة قيم الإخراج إما في مخزن مؤقت للمستخدم أو مساحة ذاكرة مخصّصة، وذلك من خلال استدعاء
ANeuralNetworksExecution_setOutput()أوANeuralNetworksExecution_setOutputFromMemory()على التوالي.// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
جدوِل عملية التنفيذ لبدءها من خلال استدعاء الدالة
ANeuralNetworksExecution_startCompute(). إذا لم تكن هناك أخطاء، ستعرض هذه الدالة رمز نتيجةANEURALNETWORKS_NO_ERROR.// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
استدعِ الدالة
ANeuralNetworksEvent_wait()للانتظار إلى حين اكتمال عملية التنفيذ. في حال نجاح التنفيذ، تعرض هذه الدالة رمز النتيجةANEURALNETWORKS_NO_ERROR. يمكن إجراء عملية الانتظار على سلسلة تعليمات مختلفة عن تلك التي تبدأ التنفيذ.// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
يمكنك اختياريًا تطبيق مجموعة مختلفة من المدخلات على النموذج المجمَّع باستخدام مثيل التجميع نفسه لإنشاء مثيل
ANeuralNetworksExecutionجديد.// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
التنفيذ المتزامن
يستغرق التنفيذ غير المتزامن وقتًا لإنشاء سلاسل المحادثات ومزامنتها. علاوةً على ذلك، يمكن أن يختلف وقت الاستجابة بشكل كبير، حيث تصل أطول حالات التأخير إلى 500 ميكروثانية بين وقت تلقّي سلسلة التعليمات إشعارًا أو تنبيهًا ووقت ربطها في النهاية بنواة وحدة المعالجة المركزية.
لتحسين وقت الاستجابة، يمكنك بدلاً من ذلك توجيه تطبيق لإجراء طلب استنتاج متزامن إلى وقت التشغيل. ولن يتم عرض نتيجة هذه المكالمة إلا بعد اكتمال الاستنتاج، وليس بعد بدئه. بدلاً من الاتصال بـ
ANeuralNetworksExecution_startCompute
لإجراء استنتاج غير متزامن في وقت التشغيل، يتصل التطبيق بـ
ANeuralNetworksExecution_compute
لإجراء استنتاج متزامن في وقت التشغيل. لا تتضمّن المكالمة إلى ANeuralNetworksExecution_compute رقم ANeuralNetworksEvent، ولا يتم إقرانها بمكالمة إلى ANeuralNetworksEvent_wait.
عمليات التنفيذ المتسلسلة
على أجهزة Android التي تعمل بالإصدار 10 (المستوى 29 من واجهة برمجة التطبيقات) والإصدارات الأحدث، تتيح واجهة برمجة التطبيقات NNAPI عمليات التنفيذ السريع من خلال الكائن
ANeuralNetworksBurst. عمليات التنفيذ المتسلسلة هي سلسلة من عمليات تنفيذ التجميع نفسه
التي تحدث بالتتابع السريع، مثل تلك التي تعمل على لقطات من
عملية التقاط الكاميرا أو عيّنات الصوت المتتالية. قد يؤدي استخدام عناصر ANeuralNetworksBurst إلى عمليات تنفيذ أسرع، لأنّها تشير إلى أدوات التسريع بأنّه يمكن إعادة استخدام الموارد بين عمليات التنفيذ، وأنّه يجب أن تظل أدوات التسريع في حالة عالية الأداء طوال مدة التشغيل السريع.
لا يؤدي ANeuralNetworksBurst إلا إلى تغيير بسيط في مسار التنفيذ العادي. يمكنك إنشاء عنصر burst باستخدام
ANeuralNetworksBurst_create،
كما هو موضّح في مقتطف الرمز التالي:
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
عمليات التنفيذ المتسلسلة متزامنة. ومع ذلك، بدلاً من استخدام
ANeuralNetworksExecution_compute
لتنفيذ كل استنتاج، يمكنك ربط عناصر
ANeuralNetworksExecution
المختلفة بالعنصر ANeuralNetworksBurst نفسه في طلبات الدالة
ANeuralNetworksExecution_burstCompute.
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
حرِّر العنصر ANeuralNetworksBurst باستخدام
ANeuralNetworksBurst_free
عندما لا يعود هناك حاجة إليه.
// Cleanup ANeuralNetworksBurst_free(burst);
قوائم انتظار الأوامر غير المتزامنة والتنفيذ المحصور
في Android 11 والإصدارات الأحدث، تتيح NNAPI طريقة إضافية لجدولة التنفيذ غير المتزامن من خلال الطريقة ANeuralNetworksExecution_startComputeWithDependencies(). عند استخدام هذه الطريقة، ينتظر التنفيذ إلى أن يتم الإشارة إلى جميع الأحداث التابعة قبل بدء التقييم. بعد اكتمال التنفيذ
وتوفّر النواتج للاستخدام، يتم الإشارة إلى الحدث الذي تم عرضه.
استنادًا إلى الأجهزة التي تتولّى التنفيذ، قد يكون الحدث مدعومًا بإشارة مزامنة. يجب استدعاء
ANeuralNetworksEvent_wait()
لانتظار الحدث واسترداد الموارد التي استخدمها التنفيذ. يمكنك استيراد حواجز المزامنة إلى عنصر حدث باستخدام ANeuralNetworksEvent_createFromSyncFenceFd()، ويمكنك تصدير حواجز المزامنة من عنصر حدث باستخدام ANeuralNetworksEvent_getSyncFenceFd().
مخرجات ذات حجم ديناميكي
لاستخدام نماذج يعتمد حجم الناتج فيها على بيانات الإدخال، أي النماذج التي لا يمكن تحديد حجمها في وقت تنفيذ النموذج، استخدِم ANeuralNetworksExecution_getOutputOperandRank وANeuralNetworksExecution_getOutputOperandDimensions.
يوضّح نموذج الرمز البرمجي التالي كيفية إجراء ذلك:
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
تنظيف
تتولّى خطوة التنظيف إتاحة الموارد الداخلية المستخدَمة في عملية الحساب.
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
إدارة الأخطاء والرجوع إلى وحدة المعالجة المركزية
في حال حدوث خطأ أثناء التقسيم، أو تعذُّر تجميع برنامج تشغيل (جزء من) نموذج، أو تعذُّر تنفيذ برنامج تشغيل (جزء من) نموذج مجمّع، قد يعود NNAPI إلى تنفيذ عملية واحدة أو أكثر على وحدة المعالجة المركزية.
إذا كان برنامج NNAPI يتضمّن إصدارات محسَّنة من العملية (مثل TFLite)، قد يكون من المفيد إيقاف خيار الرجوع إلى وحدة المعالجة المركزية والتعامل مع حالات الأعطال باستخدام عملية التنفيذ المحسَّنة في البرنامج.
في نظام التشغيل Android 10، إذا تم إجراء عملية التجميع باستخدام
ANeuralNetworksCompilation_createForDevices، سيتم إيقاف التوافق مع وحدة المعالجة المركزية.
في نظام التشغيل Android P، يتم الرجوع إلى وحدة المعالجة المركزية (CPU) في حال تعذُّر التنفيذ على برنامج التشغيل.
وينطبق ذلك أيضًا على الإصدار 10 من نظام التشغيل Android عند استخدام ANeuralNetworksCompilation_create بدلاً من ANeuralNetworksCompilation_createForDevices.
يتم الرجوع إلى التنفيذ الأول لهذا القسم الفردي، وإذا استمر تعذُّر التنفيذ، تتم إعادة محاولة تنفيذ النموذج بأكمله على وحدة المعالجة المركزية.
في حال تعذُّر التقسيم أو التجميع، سيتم تجربة النموذج بأكمله على وحدة المعالجة المركزية.
في بعض الحالات، لا تتوافق بعض العمليات مع وحدة المعالجة المركزية، وفي مثل هذه الحالات، سيفشل التجميع أو التنفيذ بدلاً من الرجوع إلى الإصدار السابق.
حتى بعد إيقاف خيار استخدام وحدة المعالجة المركزية كخيار احتياطي، قد تظل هناك عمليات في النموذج تتم جدولتها على وحدة المعالجة المركزية. إذا كان وحدة المعالجة المركزية (CPU) مدرَجة في قائمة المعالِجات المتوافقة مع ANeuralNetworksCompilation_createForDevices، وكانت إما المعالج الوحيد الذي يتيح هذه العمليات أو المعالج الذي يقدّم أفضل أداء لهذه العمليات، سيتم اختيارها كمنفّذ أساسي (غير احتياطي).
لضمان عدم تنفيذ وحدة المعالجة المركزية، استخدِم ANeuralNetworksCompilation_createForDevices مع استبعاد nnapi-reference من قائمة الأجهزة.
بدءًا من Android P، يمكن إيقاف عملية الرجوع إلى الإصدار السابق في وقت التنفيذ على إصدارات DEBUG من خلال ضبط السمة debug.nn.partition على 2.
نطاقات الذاكرة
في نظام التشغيل Android 11 والإصدارات الأحدث، تتيح واجهة برمجة التطبيقات NNAPI نطاقات الذاكرة التي توفّر واجهات أدوات التخصيص للذاكرات غير الشفافة. ويتيح ذلك للتطبيقات تمرير الذاكرات الأصلية للجهاز بين عمليات التنفيذ، وبالتالي لا تنسخ واجهة برمجة التطبيقات NNAPI البيانات أو تحوّلها بدون داعٍ عند تنفيذ عمليات متتالية على برنامج التشغيل نفسه.
تم تصميم ميزة نطاق الذاكرة للموترات التي تكون داخلية في معظمها بالنسبة إلى برنامج التشغيل ولا تحتاج إلى الوصول بشكل متكرر إلى جهة العميل. وتشمل أمثلة هذه الموترات متوترات الحالة في نماذج التسلسل. بالنسبة إلى الموترات التي تحتاج إلى الوصول إلى وحدة المعالجة المركزية بشكل متكرر من جهة العميل، استخدِم مجموعات الذاكرة المشتركة بدلاً من ذلك.
لتخصيص ذاكرة مبهمة، اتّبِع الخطوات التالية:
استدعِ الدالة
ANeuralNetworksMemoryDesc_create()لإنشاء واصف ذاكرة جديد:// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
حدِّد جميع أدوار الإدخال والإخراج المقصودة من خلال استدعاء
ANeuralNetworksMemoryDesc_addInputRole()وANeuralNetworksMemoryDesc_addOutputRole().// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
يمكنك اختياريًا تحديد سمات الذاكرة من خلال استدعاء
ANeuralNetworksMemoryDesc_setDimensions().// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
أكمِل تعريف الواصف من خلال استدعاء
ANeuralNetworksMemoryDesc_finish().ANeuralNetworksMemoryDesc_finish(desc);
يمكنك تخصيص أي عدد تريده من الذاكرات عن طريق تمرير الواصف إلى
ANeuralNetworksMemory_createFromDesc().// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
حرِّر واصف الذاكرة عندما لا تعود بحاجة إليه.
ANeuralNetworksMemoryDesc_free(desc);
لا يجوز للعميل استخدام الكائن ANeuralNetworksMemory الذي تم إنشاؤه إلا مع ANeuralNetworksExecution_setInputFromMemory() أو ANeuralNetworksExecution_setOutputFromMemory() وفقًا للأدوار المحدّدة في الكائن ANeuralNetworksMemoryDesc. يجب ضبط وسيطتَي الإزاحة والطول على 0، ما يشير إلى أنّه يتم استخدام الذاكرة بأكملها. يمكن للعميل أيضًا ضبط محتوى الذاكرة أو استخراجه بشكل صريح باستخدام ANeuralNetworksMemory_copy().
يمكنك إنشاء ذكريات مبهمة بأدوار ذات سمات أو ترتيب غير محدّد.
في هذه الحالة، قد يتعذّر إنشاء الذاكرة مع ظهور الحالة ANEURALNETWORKS_OP_FAILED إذا كان برنامج التشغيل الأساسي لا يتيح ذلك. ننصح العميل بتنفيذ منطق احتياطي من خلال تخصيص مخزن مؤقت كبير بما يكفي ومزوّد بنظام Ashmem أو وضع BLOB AHardwareBuffer.
عندما لا يعود NNAPI بحاجة إلى الوصول إلى عنصر الذاكرة غير الشفاف، حرِّر مثيل ANeuralNetworksMemory المقابل:
ANeuralNetworksMemory_free(opaqueMem);
قياس الأداء
يمكنك تقييم أداء تطبيقك من خلال قياس وقت التنفيذ أو إنشاء ملف تعريف.
وقت التنفيذ
عندما تريد تحديد إجمالي وقت التنفيذ من خلال وقت التشغيل، يمكنك استخدام واجهة برمجة التطبيقات للتنفيذ المتزامن وقياس الوقت الذي استغرقه الطلب. عندما تريد تحديد إجمالي وقت التنفيذ من خلال مستوى أدنى من حزمة البرامج، يمكنك استخدام ANeuralNetworksExecution_setMeasureTiming وANeuralNetworksExecution_getDuration للحصول على ما يلي:
- وقت التنفيذ على أداة تسريع (وليس في برنامج التشغيل الذي يعمل على المعالج المضيف).
- وقت التنفيذ في برنامج التشغيل، بما في ذلك الوقت المستغرق في أداة التسريع
لا يشمل وقت التنفيذ في برنامج التشغيل النفقات العامة، مثل نفقات وقت التشغيل نفسه وعملية الاتصال بين العمليات (IPC) اللازمة لوقت التشغيل للتواصل مع برنامج التشغيل.
تقيس واجهات برمجة التطبيقات هذه المدة بين حدثَي إرسال العمل وإكماله، بدلاً من الوقت الذي يخصّصه برنامج التشغيل أو أداة التسريع لتنفيذ الاستنتاج، والذي قد يتوقّف بسبب تبديل السياق.
على سبيل المثال، إذا بدأ الاستنتاج 1، ثم توقّف برنامج التشغيل عن العمل لتنفيذ الاستنتاج 2، ثم استأنف الاستنتاج 1 وأكمله، سيشمل وقت التنفيذ للاستنتاج 1 الوقت الذي توقّف فيه العمل لتنفيذ الاستنتاج 2.
قد تكون معلومات التوقيت هذه مفيدة عند نشر تطبيق في مرحلة الإنتاج لجمع بيانات القياس عن بُعد لاستخدامها بلا إنترنت. يمكنك استخدام بيانات التوقيت لتعديل التطبيق وتحسين أدائه.
عند استخدام هذه الوظيفة، يُرجى مراعاة ما يلي:
- قد يؤدي جمع معلومات التوقيت إلى تكلفة أداء.
- يمكن للسائق فقط احتساب الوقت المستغرَق في حد ذاته أو في المسرّع، باستثناء الوقت المستغرَق في وقت تشغيل NNAPI وفي IPC.
- لا يمكنك استخدام واجهات برمجة التطبيقات هذه إلا مع
ANeuralNetworksExecutionتم إنشاؤه باستخدامANeuralNetworksCompilation_createForDevicesمعnumDevices = 1. - لا يُشترط أن يكون لديك رخصة قيادة لتتمكّن من الإبلاغ عن معلومات التوقيت.
إنشاء ملف تعريف لتطبيقك باستخدام أداة Android Systrace
بدءًا من Android 10، تنشئ NNAPI تلقائيًا أحداث systrace التي يمكنك استخدامها لإنشاء ملف تعريف لتطبيقك.
تتضمّن أداة NNAPI Source أداة مساعدة parse_systrace لمعالجة أحداث systrace التي تم إنشاؤها بواسطة تطبيقك وإنشاء عرض جدولي يعرض الوقت المستغرَق في المراحل المختلفة لدورة حياة النموذج (الإنشاء والإعداد والتنفيذ والإنهاء) والطبقات المختلفة للتطبيقات. الطبقات التي يتم تقسيم تطبيقك إليها هي:
-
Application: الرمز البرمجي الرئيسي للتطبيق -
Runtime: وقت تشغيل NNAPI IPC: الاتصال بين العمليات في وقت تشغيل NNAPI وبرنامج التشغيلDriver: عملية برنامج Accelerator
إنشاء بيانات تحليل التوصيف
بافتراض أنّك اطّلعت على شجرة المصدر لنظام التشغيل Android في $ANDROID_BUILD_TOP، واستخدمت مثال تصنيف الصور في TFLite كتطبيق مستهدف، يمكنك إنشاء بيانات قياس أداء NNAPI باتّباع الخطوات التالية:
- ابدأ Android systrace باستخدام الأمر التالي:
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
تشير المَعلمة -o trace.html إلى أنّه سيتم تسجيل عمليات التتبُّع في trace.html. عند إنشاء ملف تعريف لتطبيقك، عليك استبدال org.tensorflow.lite.examples.classification باسم العملية المحدّد في بيان التطبيق.
سيؤدي ذلك إلى إبقاء إحدى وحدات تحكّم shell مشغولة، لذا لا تنفِّذ الأمر في الخلفية لأنّه ينتظر بشكل تفاعلي إدخال enter لإنهاء العملية.
- بعد بدء أداة جمع بيانات systrace، شغِّل تطبيقك ونفِّذ اختبار الأداء.
في حالتنا، يمكنك بدء تطبيق تصنيف الصور من Android Studio أو مباشرةً من واجهة مستخدم الهاتف التجريبي إذا كان التطبيق مثبّتًا عليه. لإنشاء بعض بيانات NNAPI، عليك ضبط التطبيق لاستخدام NNAPI من خلال اختيار NNAPI كجهاز مستهدف في مربّع حوار إعدادات التطبيق.
عند اكتمال الاختبار، أوقِف عملية systrace بالضغط على
enterفي نافذة وحدة التحكّم النشطة منذ الخطوة 1.شغِّل الأداة المساعدة
systrace_parserلإنشاء إحصاءات تراكمية:
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
يقبل المحلّل المَعلمات التالية:
- --total-times: يعرض إجمالي الوقت المستغرَق في إحدى الطبقات، بما في ذلك الوقت
المستغرَق في انتظار التنفيذ عند استدعاء إحدى الطبقات الأساسية
- --print-detail: يطبع جميع الأحداث التي تم جمعها من systrace
- --per-execution: يطبع التنفيذ فقط والمراحل الفرعية الخاصة به
(حسب أوقات التنفيذ) بدلاً من الإحصاءات الخاصة بجميع المراحل
- --json: ينتج الإخراج بتنسيق JSON
في ما يلي مثال على الناتج:
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
قد يتعذّر على المحلّل اللغوي العمل إذا كانت الأحداث التي تم جمعها لا تمثّل تتبُّعًا كاملاً للتطبيق. على وجه الخصوص، قد يحدث ذلك إذا كانت أحداث systrace التي تم إنشاؤها لتحديد نهاية قسم معيّن متوفّرة في التتبُّع بدون حدث بدء قسم مرتبط. يحدث ذلك عادةً إذا تم إنشاء بعض الأحداث من جلسة تسجيل سابقة عند بدء أداة تجميع systrace. في هذه الحالة، عليك إعادة إجراء عملية إنشاء الملف الشخصي.
إضافة إحصاءات لرمز تطبيقك إلى ناتج systrace_parser
يعتمد تطبيق parse_systrace على وظيفة Android systrace المضمّنة. يمكنك إضافة عمليات تتبُّع لعمليات معيّنة في تطبيقك باستخدام واجهة برمجة التطبيقات systrace (للغة Java ، للتطبيقات الأصلية ) مع أسماء أحداث مخصّصة.
لربط أحداثك المخصّصة بمراحل من دورة حياة التطبيق، أضِف إحدى السلاسل التالية إلى بداية اسم الحدث:
-
[NN_LA_PI]: حدث على مستوى التطبيق لعملية الإعداد [NN_LA_PP]: حدث على مستوى التطبيق للإعداد-
[NN_LA_PC]: حدث على مستوى التطبيق خاص بالتجميع -
[NN_LA_PE]: حدث على مستوى التطبيق للتنفيذ
في ما يلي مثال على كيفية تعديل مثال رمز تصنيف الصور في TFLite من خلال إضافة قسم runInferenceModel للمرحلة Execution وطبقة Application التي تحتوي على أقسام أخرى preprocessBitmap لن يتم أخذها في الاعتبار في عمليات تتبُّع NNAPI. سيكون القسم runInferenceModel جزءًا من أحداث systrace التي يعالجها محلّل nnapi systrace:
Kotlin
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
Java
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
جودة الخدمة
في نظام التشغيل Android 11 والإصدارات الأحدث، تتيح واجهة برمجة التطبيقات NNAPI تحسين جودة الخدمة (QoS) من خلال السماح لأحد التطبيقات بتحديد الأولويات النسبية لنماذجه، والحد الأقصى للوقت المتوقّع لإعداد نموذج معيّن، والحد الأقصى للوقت المتوقّع لإكمال عملية حسابية معيّنة. يوفّر نظام التشغيل Android 11 أيضًا رموز نتائج إضافية في NNAPI تتيح للتطبيقات فهم أسباب تعذُّر تنفيذ العمليات، مثل عدم الالتزام بالمواعيد النهائية.
تحديد أولوية حمل العمل
لضبط أولوية عبء عمل NNAPI، استدعِ الدالة
ANeuralNetworksCompilation_setPriority()
قبل استدعاء الدالة ANeuralNetworksCompilation_finish().
تحديد المواعيد النهائية
يمكن للتطبيقات ضبط المواعيد النهائية لكلّ من تجميع النماذج والاستدلال.
- لضبط مهلة التجميع، استدعِ الدالة
ANeuralNetworksCompilation_setTimeout()قبل استدعاء الدالةANeuralNetworksCompilation_finish(). - لضبط مهلة الاستنتاج، استدعِ الدالة
ANeuralNetworksExecution_setTimeout()قبل بدء عملية التجميع.
مزيد من المعلومات حول المعامِلات
يتناول القسم التالي مواضيع متقدّمة حول استخدام المعامِلات.
المتّجهات الكمّية
الموتّر الكمّي هو طريقة مضغوطة لتمثيل مصفوفة n-بعدية من قيم النقطة العائمة.
تتيح واجهة برمجة التطبيقات NNAPI استخدام موترات كمّية غير متماثلة ذات 8 بت. بالنسبة إلى هذه الموترات، يتم تمثيل قيمة كل خلية بعدد صحيح مكوّن من 8 بتات. يرتبط الموتر بمقياس وقيمة نقطة صفر. ويتم استخدامها لتحويل الأعداد الصحيحة ذات 8 بت إلى قيم النقطة العائمة التي يتم تمثيلها.
الصيغة هي:
(cellValue - zeroPoint) * scale
حيث تكون قيمة zeroPoint عددًا صحيحًا من 32 بت، ويكون المقياس قيمة نقطة عائمة من 32 بت.
مقارنةً بموترات قيم النقطة العائمة ذات 32 بت، تتميّز موترات التكميم ذات 8 بت بميزتَين:
- يصبح حجم تطبيقك أصغر، لأنّ الأوزان المدرَّبة تشغل ربع حجم الموترات ذات 32 بت.
- يمكن غالبًا تنفيذ العمليات الحسابية بشكل أسرع. ويرجع ذلك إلى كمية البيانات الأصغر التي يجب استرجاعها من الذاكرة وكفاءة المعالِجات، مثل معالِجات الإشارات الرقمية (DSP)، في إجراء العمليات الحسابية للأعداد الصحيحة.
مع أنّه من الممكن تحويل نموذج ذي فاصلة عائمة إلى نموذج كمّي، أظهرت تجربتنا أنّ التدريب المباشر لنموذج كمّي يحقّق نتائج أفضل. في الواقع، يتعلّم الشبكة العصبية كيفية تعويض الدقة المتزايدة لكل قيمة. بالنسبة إلى كل موتر كمّي، يتم تحديد قيمتَي المقياس وzeroPoint أثناء عملية التدريب.
في NNAPI، يمكنك تحديد أنواع الموتر الكمي من خلال ضبط حقل النوع في بنية البيانات
ANeuralNetworksOperandType
على
ANEURALNETWORKS_TENSOR_QUANT8_ASYMM.
يمكنك أيضًا تحديد قيمة المقياس وzeroPoint للموتر في بنية البيانات هذه.
بالإضافة إلى موترات الكمّ غير المتماثلة ذات 8 بت، تتيح واجهة برمجة التطبيقات NNAPI ما يلي:
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNELالتي يمكنك استخدامها لتمثيل الأوزان في عملياتCONV/DEPTHWISE_CONV/TRANSPOSED_CONV.ANEURALNETWORKS_TENSOR_QUANT16_ASYMMالتي يمكنك استخدامها للحالة الداخليةQUANTIZED_16BIT_LSTM.ANEURALNETWORKS_TENSOR_QUANT8_SYMMالتي يمكن أن تكون إدخالاً إلىANEURALNETWORKS_DEQUANTIZE
المعاملات الاختيارية
تتضمّن بعض العمليات، مثل
ANEURALNETWORKS_LSH_PROJECTION،
معاملات اختيارية. للإشارة في النموذج إلى أنّه تم حذف المعامِل الاختياري، استدعِ الدالة ANeuralNetworksModel_setOperandValue()، مع تمرير NULL إلى المخزن المؤقت و0 إلى الطول.
إذا كان قرار ما إذا كان المعامل متوفّرًا أو لا يختلف لكل عملية تنفيذ، يمكنك الإشارة إلى أنّه تم حذف المعامل باستخدام الدالتَين ANeuralNetworksExecution_setInput() أو ANeuralNetworksExecution_setOutput()، مع تمرير NULL إلى المخزن المؤقت و0 إلى الطول.
متّجهات ذات ترتيب غير معروف
قدّم نظام التشغيل Android 9 (المستوى 28 من واجهة برمجة التطبيقات) معاملات نماذج ذات أبعاد غير معروفة ولكن بترتيب معروف (عدد الأبعاد). قدّم إصدار Android 10 (المستوى 29 من واجهة برمجة التطبيقات) موترات ذات ترتيب غير معروف، كما هو موضّح في ANeuralNetworksOperandType.
NNAPI benchmark
يتوفّر معيار NNAPI على AOSP في platform/test/mlts/benchmark
(تطبيق قياس الأداء) وplatform/test/mlts/models (النماذج ومجموعات البيانات).
يقيس معيار الأداء وقت الاستجابة والدقة، ويقارن بين برامج التشغيل من حيث الأداء نفسه الذي تم تحقيقه باستخدام TensorFlow Lite الذي يعمل على وحدة المعالجة المركزية، وذلك بالنسبة إلى النماذج ومجموعات البيانات نفسها.
لاستخدام مقياس الأداء، اتّبِع الخطوات التالية:
وصِّل جهاز Android مستهدفًا بالكمبيوتر، وافتح نافذة طرفية، وتأكَّد من إمكانية الوصول إلى الجهاز من خلال adb.
في حال ربط أكثر من جهاز Android واحد، عليك تصدير متغير بيئة
ANDROID_SERIALالجهاز المستهدف.انتقِل إلى دليل المصدر ذي المستوى الأعلى في Android.
نفِّذ الأوامر التالية:
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
في نهاية عملية قياس الأداء، سيتم عرض النتائج كصفحة HTML يتم تمريرها إلى
xdg-open.
سجلّات NNAPI
تُنشئ واجهة برمجة التطبيقات NNAPI معلومات تشخيصية مفيدة في سجلات النظام. لتحليل السجلات، استخدِم أداة logcat.
يمكنك تفعيل تسجيل الدخول المفصّل إلى NNAPI لمراحل أو مكوّنات معيّنة من خلال ضبط السمة debug.nn.vlog (باستخدام adb shell) على قائمة القيم التالية، مفصولة بمسافة أو نقطتين أو فاصلة:
model: إنشاء النماذج-
compilation: إنشاء خطة تنفيذ النموذج وتجميعه execution: تنفيذ النموذج-
cpuexe: تنفيذ العمليات باستخدام تنفيذ NNAPI لوحدة المعالجة المركزية -
manager: معلومات حول إضافات NNAPI والواجهات والإمكانات المتاحة -
allأو1: جميع العناصر أعلاه
على سبيل المثال، لتفعيل أسلوب التسجيل المطوَّل الكامل، استخدِم الأمر
adb shell setprop debug.nn.vlog all. لإيقاف التسجيل المطوَّل، استخدِم الأمر
adb shell setprop debug.nn.vlog '""'.
بعد تفعيل التسجيل المفصّل، يتم إنشاء إدخالات السجلّ بمستوى INFO مع ضبط العلامة على اسم المرحلة أو المكوّن.
بالإضافة إلى الرسائل التي يتم التحكّم فيها debug.nn.vlog، توفّر مكوّنات واجهة برمجة التطبيقات NNAPI إدخالات سجلّ أخرى على مستويات مختلفة، ويستخدم كل منها علامة سجلّ معيّنة.
للحصول على قائمة بالمكوّنات، ابحث في شجرة المصدر باستخدام التعبير التالي:
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
تعرض هذه العبارة حاليًا العلامات التالية:
- BurstBuilder
- عمليات إعادة الاستدعاء
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- مدير
- الذاكرة
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- العمليات
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
للتحكّم في مستوى رسائل السجلّ التي يعرضها logcat، استخدِم متغيّر البيئة ANDROID_LOG_TAGS.
لعرض المجموعة الكاملة من رسائل سجلّ NNAPI وإيقاف أي رسائل أخرى، اضبط ANDROID_LOG_TAGS على ما يلي:
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
يمكنك ضبط ANDROID_LOG_TAGS باستخدام الأمر التالي:
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
يُرجى العِلم أنّ هذا مجرّد فلتر ينطبق على logcat. سيظل عليك ضبط السمة debug.nn.vlog على all لإنشاء معلومات سجلّ مفصّلة.