
L'API Android Neural Networks (NNAPI) est conçue pour exécuter des opérations nécessitant beaucoup de ressources de calcul pour le machine learning sur les appareils Android. Le réseau NNAPI est conçu pour fournir une couche de fonctionnalité de base pour les frameworks de machine learning de niveau supérieur, tels que TensorFlow Lite et Caffe2, qui créent et entraînent des réseaux de neurones. L'API est disponible sur tous les appareils Android équipés d'Android 8.1 (niveau d'API 27) ou version ultérieure, mais elle a été abandonnée dans Android 15.
NNAPI permet l'inférence en appliquant des données à partir d'appareils Android à des modèles précédemment définis par les développeurs et entraînés. Parmi les inférences possibles, citons la classification d'images, la prédiction du comportement des utilisateurs et la sélection des réponses appropriées à une requête de recherche.
L'inférence sur un appareil présente de nombreux avantages :
- Latence : vous n'avez pas besoin d'envoyer une requête via une connexion réseau et d'attendre une réponse. Cet aspect peut être essentiel pour les applications vidéo, par exemple, qui traitent les trames successives provenant d'une caméra.
- Disponibilité : l'application s'exécute même sans couverture réseau.
- Rapidité : les nouveaux équipements spécifiques au traitement d'un réseau de neurones permettent un calcul beaucoup plus rapide qu'un processeur à usage général seul.
- Confidentialité : les données ne quittent pas l'appareil Android.
- Coût : aucune batterie de serveurs n'est nécessaire lorsque tous les calculs sont effectués sur l'appareil Android.
Toutefois, il est important de garder à l'esprit les inconvénients potentiels suivants :
- Utilisation du système : l'évaluation des réseaux de neurones implique de nombreux calculs, ce qui peut accroître l'utilisation de la batterie. Pensez à surveiller l'état de la batterie si votre application peut en pâtir, en particulier pour les calculs de longue durée.
- Taille de l'application : prêtez attention à la taille des modèles. Ils peuvent occuper plusieurs mégaoctets d'espace. Si le regroupement de modèles volumineux dans votre fichier APK a un impact excessif sur les utilisateurs, vous pouvez envisager de les télécharger après l'installation de l'application, d'utiliser des modèles plus petits ou d'exécuter les calculs dans le cloud. NNAPI ne fournit pas de fonctionnalité permettant d'exécuter des modèles dans le cloud.
Consultez l'exemple d'API Android Neural Networks pour découvrir un exemple d'utilisation de NNAPI.
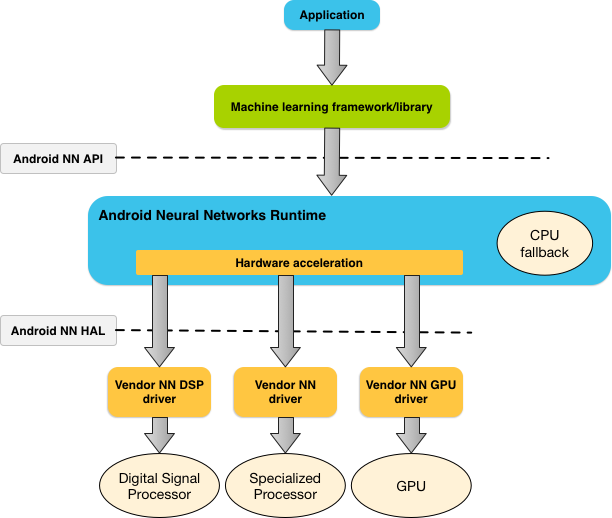
Comprendre l'environnement d'exécution de l'API Neural Networks
NNAPI doit être appelé par les bibliothèques, frameworks et outils de machine learning qui permettent aux développeurs d'entraîner leurs modèles hors de l'appareil et de les déployer sur des appareils Android. Les applications n'utilisent généralement pas directement NNAPI, mais plutôt des frameworks de machine learning de niveau supérieur. Ces frameworks peuvent à leur tour utiliser NNAPI pour effectuer des opérations d'inférence avec accélération matérielle sur les appareils compatibles.
En fonction des exigences de l'application et des capacités matérielles d'un appareil Android, l'environnement d'exécution du réseau de neurones Android peut répartir efficacement la charge de travail de calcul entre les processeurs disponibles sur l'appareil, y compris les équipements de réseau de neurones dédiés, les unités de traitement graphique (GPU) et les digital signal processors (DSP).
Pour les appareils Android dépourvus de pilote fournisseur spécialisé, l'environnement d'exécution NNAPI exécute les requêtes sur le processeur.
La figure 1 présente l'architecture système globale de NNAPI.
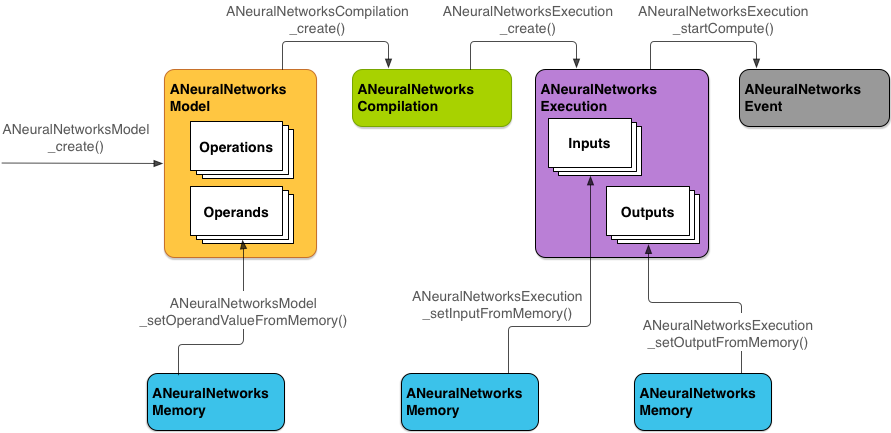
Modèle de programmation de l'API Neural Networks
Pour effectuer des calculs à l'aide du système NNAPI, vous devez d'abord élaborer un graphe orienté qui définit les calculs à effectuer. Ce graphe de calcul, combiné à vos données d'entrée (par exemple, les pondérations et les biais transmis à partir d'un framework de machine learning), constitue le modèle d'évaluation de l'environnement d'exécution de l'API NNAPI.
NNAPI utilise quatre abstractions principales :
- Modèle : graphe de calcul des opérations mathématiques et valeurs constantes apprises au cours d'un processus d'entraînement. Ces opérations sont spécifiques aux réseaux de neurones. Elles incluent une convolution bidimensionnelle (2D), une activation logistique (sigmoïde), un linéaire rectifié (ReLU) et plus encore. La création d'un modèle est une opération synchrone.
Une fois créé, il peut être réutilisé dans les threads et les compilations.
Dans NNAPI, un modèle est représenté sous la forme d'une instance
ANeuralNetworksModel. - Compilation : représente une configuration permettant de compiler un modèle NNAPI dans un code de niveau inférieur. La création d'une compilation est une opération synchrone. Une fois créée, elle peut être réutilisée dans les threads et les exécutions. Dans NNAPI, chaque compilation est représentée par une instance
ANeuralNetworksCompilation. - Mémoire : représente la mémoire partagée, les fichiers mappés en mémoire et les tampons de mémoire similaires. Avec un tampon de mémoire, l'environnement d'exécution NNAPI transfère les données aux pilotes plus efficacement. Une application crée généralement un tampon de mémoire partagée contenant tous les tenseurs nécessaires pour définir un modèle. Vous pouvez également utiliser des tampons de mémoire pour stocker les entrées et les sorties d'une instance d'exécution. Dans NNAPI, chaque tampon de mémoire est représenté sous la forme d'une instance
ANeuralNetworksMemory. Exécution : interface permettant d'appliquer un modèle NNAPI à un ensemble d'entrées et de collecter les résultats. L'exécution peut être effectuée de manière synchrone ou asynchrone.
Avec une exécution asynchrone, plusieurs threads peuvent attendre la même exécution. Une fois l'exécution terminée, tous les threads sont libérés.
Dans NNAPI, chaque exécution est représentée par une instance
ANeuralNetworksExecution.
La figure 2 illustre le flux de programmation de base.
Le reste de cette section décrit les étapes de configuration du modèle NNAPI pour effectuer des calculs, compiler le modèle et exécuter le modèle compilé.
Fournir l'accès aux données d'entraînement
Vos données d'entraînement et de pondération sont probablement stockées dans un fichier. Pour fournir à l'environnement d'exécution NNAPI un accès efficace à ces données, créez une instance ANeuralNetworksMemory. Pour ce faire, appelez la fonction ANeuralNetworksMemory_createFromFd() et transmettez le descripteur du fichier de données ouvert. Vous devez également spécifier des indicateurs de protection de la mémoire et définir un décalage là où la région de la mémoire partagée commence dans le fichier.
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
Bien que dans cet exemple, nous n'utilisions qu'une seule instance ANeuralNetworksMemory pour toutes nos pondérations, il est possible d'utiliser plusieurs instances ANeuralNetworksMemory pour plusieurs fichiers.
Utiliser des tampons matériels natifs
Vous pouvez utiliser des tampons matériels natifs pour les valeurs d'opérande des entrées, des sorties et des constantes du modèle. Dans certains cas, un accélérateur NNAPI peut accéder aux objets AHardwareBuffer sans que le pilote ait besoin de copier les données. AHardwareBuffer comporte de nombreuses configurations différentes, et tous les accélérateurs NNAPI ne sont pas forcément compatibles avec toutes ces configurations. En raison de cette limitation, reportez-vous aux contraintes indiquées dans la documentation de référence d'ANeuralNetworksMemory_createFromAHardwareBuffer. Effectuez également des tests anticipés sur les appareils cibles pour vous assurer que les compilations et les exécutions qui utilisent AHardwareBuffer fonctionnent comme prévu, en utilisant l'attribution d'appareil pour spécifier l'accélérateur.
Pour autoriser l'environnement d'exécution NNAPI à accéder à un objet AHardwareBuffer, créez une instance ANeuralNetworksMemory. Pour ce faire, appelez la fonction ANeuralNetworksMemory_createFromAHardwareBuffer et transmettez l'objet AHardwareBuffer comme illustré dans l'exemple de code suivant :
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
Lorsque NNAPI n'a plus besoin d'accéder à l'objet AHardwareBuffer, libérez l'instance ANeuralNetworksMemory correspondante :
ANeuralNetworksMemory_free(mem2);
Remarque :
- Vous ne pouvez utiliser
AHardwareBufferque pour la totalité de la mémoire tampon. Vous ne pouvez pas l'utiliser avec un paramètreARect. - L'environnement d'exécution NNAPI ne vide pas le tampon. Vous devez vous assurer que les tampons d'entrée et de sortie sont accessibles avant de planifier l'exécution.
- Il n'est pas possible de synchroniser des descripteurs de fichiers de clôture.
- Pour un objet
AHardwareBufferavec des formats et des bits d'utilisation spécifiques au fournisseur, c'est l'implémentation du fournisseur qui doit déterminer si le client ou le pilote est chargé de vider le cache.
Modèle
Un modèle est l'unité fondamentale de calcul dans NNAPI. Chaque modèle est défini par un ou plusieurs opérandes et opérations.
Opérandes
Les opérandes sont des objets de données utilisés pour définir le graphe. Ils incluent les entrées et les sorties du modèle, les nœuds intermédiaires qui contiennent les données qui circulent d'une opération à une autre et les constantes transmises à ces opérations.
Deux types d'opérandes peuvent être ajoutés aux modèles NNAPI : les scalaires et les tenseurs.
Un scalaire représente une valeur unique. NNAPI accepte les valeurs scalaires dans les formats booléens, à virgule flottante 16 bits, à virgule flottante 32 bits, ainsi que dans les formats entiers 32 bits et non entiers 32 bits non signés.
La plupart des opérations dans NNAPI impliquent des tenseurs. Les tenseurs sont des tableaux à N dimensions. NNAPI accepte les tenseurs à virgule flottante 16 bits, à virgule flottante 32 bits, à quantification 8 bits, à quantification 16 bits, ainsi que les formats entiers 32 bits et les valeurs booléennes 8 bits.
Par exemple, la figure 3 représente un modèle comportant deux opérations : une addition suivie d'une multiplication. Le modèle utilise un tenseur d'entrée et génère un tenseur de sortie.
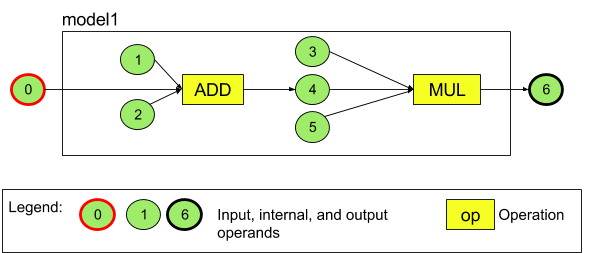
Le modèle ci-dessus comporte sept opérandes. Ces opérandes sont identifiés implicitement par l'indice correspondant à l'ordre dans lequel ils sont ajoutés au modèle. Le premier opérande ajouté présente l'indice 0, le deuxième l'indice 1, etc. Les opérandes 1, 2, 3 et 5 sont des opérandes constants.
L'ordre dans lequel vous ajoutez les opérandes n'a pas d'importance. Par exemple, l'opérande de sortie du modèle peut être le premier ajouté. L'important est d'utiliser la bonne valeur d'indice lorsque vous faites référence à un opérande.
Il existe différents types d'opérandes. Ils sont spécifiés lorsqu'ils sont ajoutés au modèle.
Un opérande ne peut pas être utilisé à la fois en entrée et en sortie d'un modèle.
Chaque opérande doit être une entrée de modèle, une constante ou l'opérande de sortie d'une seule opération.
Pour en savoir plus sur l'utilisation des opérandes, consultez la section En savoir plus sur les opérandes.
Opérations
Une opération spécifie les calculs à effectuer. Chaque opération comprend les éléments suivants :
- Un type d'opération (par exemple, addition, multiplication, convolution)
- Une liste d'indices des opérandes que l'opération utilise pour l'entrée
- Une liste des indices des opérandes que l'opération utilise pour la sortie
L'ordre dans ces listes est important. Consultez la documentation de référence de l'API NNAPI pour découvrir les entrées et sorties attendues de chaque type d'opération.
Vous devez ajouter au modèle les opérandes qu'une opération consomme ou génère avant d'ajouter l'opération.
L'ordre dans lequel vous ajoutez les opérations n'a pas d'importance. NNAPI s'appuie sur les dépendances établies par le graphe de calcul des opérandes et des opérations pour déterminer l'ordre d'exécution des opérations.
Le tableau ci-dessous récapitule les opérations acceptées par NNAPI :
Problème connu au niveau d'API 28 : lors de la transmission de tenseurs ANEURALNETWORKS_TENSOR_QUANT8_ASYMM à l'opération ANEURALNETWORKS_PAD, ce qui est possible sur Android 9 (niveau d'API 28) et les versions ultérieures, la sortie de NNAPI peut ne pas correspondre à celle des frameworks de machine learning de niveau supérieur, tels que TensorFlow Lite. À la place, vous devez transmettre ANEURALNETWORKS_TENSOR_FLOAT32.
Le problème est résolu sous Android 10 (niveau d'API 29) et les versions ultérieures.
Créer les modèles
Dans l'exemple suivant, nous créerons le modèle à deux opérations, présenté à la figure 3.
Pour ce faire, procédez comme suit :
Appelez la fonction
ANeuralNetworksModel_create()pour définir un modèle vide.ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
Ajoutez les opérandes au modèle en appelant
ANeuralNetworks_addOperand(). Leurs types de données sont définis à l'aide de la structure de donnéesANeuralNetworksOperandType.// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6Pour les opérandes qui ont des valeurs constantes, telles que les pondérations et les biais obtenus par votre application à partir d'un processus d'entraînement, utilisez
ANeuralNetworksModel_setOperandValue()etANeuralNetworksModel_setOperandValueFromMemory().Dans l'exemple suivant, nous définirons des valeurs constantes à partir du fichier de données d'entraînement correspondant au tampon de mémoire que nous avons créé dans la section Fournir l'accès aux données d'entraînement.
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));Pour chaque opération du graphe orienté que vous souhaitez calculer, ajoutez l'opération au modèle en appelant la fonction
ANeuralNetworksModel_addOperation().Votre application doit fournir les éléments suivants en tant que paramètres de cet appel :
- Type d'opération
- Nombre de valeurs d'entrée
- Tableau des indices des opérandes d'entrée
- Nombre de valeurs de sortie
- Tableau des indices des opérandes de sortie
Notez qu'un opérande ne peut pas être utilisé à la fois pour l'entrée et la sortie de la même opération.
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);Pour identifier les opérandes que le modèle doit traiter comme ses entrées et ses sorties, appelez la fonction
ANeuralNetworksModel_identifyInputsAndOutputs().// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
Vous pouvez également indiquer si
ANEURALNETWORKS_TENSOR_FLOAT32peut être calculé avec une plage ou une précision aussi faible que celle du format à virgule flottante 16 bits IEEE 754 en appelantANeuralNetworksModel_relaxComputationFloat32toFloat16().Appelez
ANeuralNetworksModel_finish()pour finaliser la définition du modèle. En l'absence d'erreurs, cette fonction renvoie un code de résultatANEURALNETWORKS_NO_ERROR.ANeuralNetworksModel_finish(model);
Une fois que vous avez créé un modèle, vous pouvez le compiler autant de fois que vous le souhaitez et exécuter chaque compilation autant de fois que vous le souhaitez.
Flux de contrôle
Pour intégrer un flux de contrôle dans un modèle NNAPI, procédez comme suit :
Créez les sous-graphes d'exécution correspondants (sous-graphes
thenetelsepour une instructionIF, sous-graphesconditionetbodypour une boucleWHILE) en tant que modèles indépendantsANeuralNetworksModel*:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
Créez des opérandes qui référencent ces modèles dans le modèle contenant le flux de contrôle :
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
Ajoutez l'opération de flux de contrôle :
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
Compilation
L'étape de compilation détermine sur quels processeurs votre modèle sera exécuté et demande aux pilotes correspondants de se préparer à son exécution. Cela peut inclure la génération du code machine propre aux processeurs sur lesquels votre modèle s'exécutera.
Pour compiler un modèle, procédez comme suit :
Appelez la fonction
ANeuralNetworksCompilation_create()afin de créer une instance de compilation.// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
Vous pouvez éventuellement utiliser l'attribution d'appareils pour choisir explicitement les appareils sur lesquels exécuter l'opération.
Vous avez la possibilité d'ajuster la façon dont l'exécution gère l'utilisation de la batterie et la vitesse d'exécution. Pour ce faire, appelez
ANeuralNetworksCompilation_setPreference().// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
Vous pouvez définir les préférences suivantes :
ANEURALNETWORKS_PREFER_LOW_POWER: permet de privilégier une exécution qui minimise la décharge de la batterie. Cette option est souhaitable pour les compilations qui sont souvent exécutées.ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: permet de privilégier une réponse unique le plus rapidement possible, même si cela augmente la consommation d'énergie. Il s'agit de l'option par défaut.ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: privilégie l'optimisation du débit des trames successives, par exemple lors du traitement des trames successives provenant de la caméra.
Vous avez la possibilité d'appeler
ANeuralNetworksCompilation_setCachingpour configurer la mise en cache de la compilation.// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
Utilisez
getCodeCacheDir()pourcacheDir. Le jeton (token) spécifié doit être spécifique à chaque modèle dans l'application.Finalisez la définition de la compilation en appelant
ANeuralNetworksCompilation_finish(). En l'absence d'erreurs, cette fonction renvoie un code de résultatANEURALNETWORKS_NO_ERROR.ANeuralNetworksCompilation_finish(compilation);
Détection et attribution d'appareils
Sur les appareils Android exécutant Android 10 (niveau d'API 29) ou version ultérieure, NNAPI propose des fonctions permettant aux applications et aux bibliothèques de framework de machine learning d'obtenir des informations sur les appareils disponibles et de spécifier les appareils à utiliser pour l'exécution. Fournir des informations sur les appareils disponibles permet aux applications de récupérer la version exacte des pilotes qui se trouvent sur un appareil afin d'éviter les incompatibilités connues. En donnant aux applications la possibilité de spécifier les appareils devant exécuter différentes sections d'un modèle, elles peuvent être optimisées pour l'appareil Android sur lequel elles sont déployées.
Détection d'appareils
Utilisez ANeuralNetworks_getDeviceCount pour déterminer le nombre d'appareils disponibles. Pour chaque appareil, utilisez ANeuralNetworks_getDevice afin de définir une instance ANeuralNetworksDevice pour faire référence à cet appareil.
Une fois que vous disposez d'une référence d'appareil, vous pouvez obtenir des informations supplémentaires à propos de cet appareil à l'aide des fonctions suivantes :
ANeuralNetworksDevice_getFeatureLevelANeuralNetworksDevice_getNameANeuralNetworksDevice_getTypeANeuralNetworksDevice_getVersion
Attribution des appareils
Utilisez ANeuralNetworksModel_getSupportedOperationsForDevices pour identifier quelles opérations d'un modèle peuvent être exécutées sur des appareils spécifiques.
Pour contrôler les accélérateurs à utiliser pour l'exécution, appelez ANeuralNetworksCompilation_createForDevices à la place de ANeuralNetworksCompilation_create.
Utilisez l'objet ANeuralNetworksCompilation obtenu, comme prévu.
La fonction renvoie une erreur si le modèle fourni contient des opérations non compatibles avec les appareils sélectionnés.
Si plusieurs appareils sont spécifiés, l'environnement d'exécution est responsable de la répartition des tâches entre les appareils.
Comme pour d'autres appareils, l'implémentation du processeur NNAPI est représentée par un objet ANeuralNetworksDevice nommé nnapi-reference et de type ANEURALNETWORKS_DEVICE_TYPE_CPU. Lors de l'appel d'ANeuralNetworksCompilation_createForDevices, l'implémentation du processeur n'est pas utilisée pour gérer les cas d'échec de la compilation et de l'exécution du modèle.
Il appartient à l'application de partitionner un modèle en sous-modèles pouvant être exécutés sur les appareils spécifiés. Les applications qui n'ont pas besoin de procéder au partitionnement manuel doivent continuer à appeler l'élément ANeuralNetworksCompilation_create plus simple pour utiliser tous les appareils disponibles (y compris le processeur) afin d'accélérer le modèle. Si le modèle n'est pas entièrement compatible avec les appareils que vous avez spécifiés avec ANeuralNetworksCompilation_createForDevices, ANEURALNETWORKS_BAD_DATA est renvoyé.
Partitionnement des modèles
Lorsque plusieurs appareils sont disponibles pour le modèle, l'environnement d'exécution NNAPI répartit les tâches entre eux. Par exemple, si plusieurs appareils ont été fournis à ANeuralNetworksCompilation_createForDevices, tous les appareils spécifiés sont pris en compte lors de l'allocation des tâches. Notez que si l'appareil CPU ne figure pas dans la liste, l'exécution du processeur est désactivée. Lorsque vous utilisez ANeuralNetworksCompilation_create, tous les appareils disponibles sont pris en compte, y compris le processeur.
Pour effectuer la distribution, sélectionnez dans la liste des appareils disponibles l'appareil prenant en charge l'opération pour chacune des opérations du modèle, et déclarez les performances optimales (à savoir, la durée d'exécution la plus rapide ou la consommation d'énergie la plus faible) en fonction des préférences d'exécution spécifiées par le client. Cet algorithme de partitionnement ne tient pas compte des inefficacités possibles causées par l'E/S entre les différents processeurs. Par conséquent, lorsque vous spécifiez plusieurs processeurs (soit explicitement lors de l'utilisation d'ANeuralNetworksCompilation_createForDevices, soit implicitement avec ANeuralNetworksCompilation_create), il est important de profiler l'application obtenue.
Pour savoir comment votre modèle a été partitionné par NNAPI, recherchez la présence d'un message dans les journaux Android (au niveau INFO avec la balise ExecutionPlan) :
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name est le nom descriptif de l'opération dans le graphe, et device-index est l'indice de l'appareil candidat dans la liste.
Cette liste correspond à l'entrée fournie à ANeuralNetworksCompilation_createForDevices ou, si vous utilisez ANeuralNetworksCompilation_createForDevices, à la liste des appareils renvoyés lors de l'itération sur tous les appareils utilisant ANeuralNetworks_getDeviceCount et ANeuralNetworks_getDevice.
Voici le message qui apparaît (au niveau INFO avec la balise ExecutionPlan) :
ModelBuilder::partitionTheWork: only one best device: device-name
Ce message indique que l'intégralité du graphe a été accéléré sur l'appareil device-name.
Exécution
L'étape d'exécution applique le modèle à un ensemble d'entrées et stocke les sorties de calculs dans un ou plusieurs tampons utilisateur ou espaces mémoire alloués par votre application.
Pour exécuter un modèle compilé, procédez comme suit :
Appelez la fonction
ANeuralNetworksExecution_create()pour créer une instance d'exécution.// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
Spécifiez l'emplacement où votre application lira les valeurs d'entrée pour le calcul. Votre application peut lire les valeurs d'entrée à partir d'un tampon utilisateur ou d'un espace mémoire alloué en appelant
ANeuralNetworksExecution_setInput()ouANeuralNetworksExecution_setInputFromMemory(), respectivement.// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
Spécifiez l'emplacement où votre application écrira les valeurs de sortie. Votre application peut écrire des valeurs de sortie dans un tampon utilisateur ou dans un espace mémoire alloué, en appelant
ANeuralNetworksExecution_setOutput()ouANeuralNetworksExecution_setOutputFromMemory(), respectivement.// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
Planifiez le démarrage de l'exécution en appelant la fonction
ANeuralNetworksExecution_startCompute(). En l'absence d'erreurs, cette fonction renvoie un code de résultatANEURALNETWORKS_NO_ERROR.// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
Appelez la fonction
ANeuralNetworksEvent_wait()pour attendre la fin de l'exécution. Si l'exécution a réussi, cette fonction renvoie un code de résultatANEURALNETWORKS_NO_ERROR. L'attente peut avoir lieu sur un thread différent de celui qui démarre l'exécution.// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
Vous pouvez éventuellement appliquer un autre ensemble d'entrées au modèle compilé en utilisant la même instance de compilation pour créer une instance
ANeuralNetworksExecution.// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
Exécution synchrone
L'exécution de tâches asynchrones nécessite un certain temps pour générer et synchroniser les threads. De plus, la latence peut être extrêmement variable. Les retards les plus longs atteignent jusqu'à 500 microsecondes entre le moment où un thread est notifié ou activé, et le moment où il est finalement lié à un cœur de processeur.
Pour améliorer la latence, vous pouvez également demander à une application d'effectuer un appel d'inférence synchrone vers l'environnement d'exécution. Cet appel ne sera renvoyé qu'une fois l'inférence terminée plutôt que lorsqu'une inférence aura commencé. Au lieu d'appeler ANeuralNetworksExecution_startCompute pour un appel d'inférence asynchrone vers l'environnement d'exécution, l'application appelleANeuralNetworksExecution_compute afin d'effectuer un appel synchrone à l'environnement d'exécution. Un appel à ANeuralNetworksExecution_compute ne nécessite pas d'événement ANeuralNetworksEvent et n'est pas associé à un appel à ANeuralNetworksEvent_wait.
Exécutions intensives
Sur les appareils Android exécutant Android 10 (niveau d'API 29) ou version ultérieure, NNAPI accepte les exécutions intensives via l'objet ANeuralNetworksBurst. Les exécutions intensives sont une séquence d'exécutions de la même compilation qui se succèdent rapidement, telles que celles exécutées au niveau des trames d'une capture d'échantillons audio successifs tirés d'une caméra. L'utilisation d'objets ANeuralNetworksBurst peut accélérer les exécutions, car ils indiquent aux accélérateurs que les ressources peuvent être réutilisées entre les exécutions et que les accélérateurs doivent rester performants pendant toute la durée de l'utilisation intensive.
ANeuralNetworksBurst n'ajoute qu'une légère modification dans le chemin d'exécution normal. Vous pouvez créer un objet "burst" avec ANeuralNetworksBurst_create, comme indiqué dans l'extrait de code suivant :
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
Les exécutions intensives sont synchrones. Cependant, au lieu d'utiliser ANeuralNetworksExecution_compute pour effectuer chaque inférence, vous associez les différents objets ANeuralNetworksExecution avec le même élément ANeuralNetworksBurst dans les appels de la fonction ANeuralNetworksExecution_burstCompute.
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
Libérez l'objet ANeuralNetworksBurst avec ANeuralNetworksBurst_free lorsqu'il n'est plus nécessaire.
// Cleanup ANeuralNetworksBurst_free(burst);
Files d'attente de commandes asynchrones et exécution clôturée
Dans Android 11 et les versions ultérieures, NNAPI offre un moyen supplémentaire de planifier l'exécution de tâches asynchrones via la méthode ANeuralNetworksExecution_startComputeWithDependencies(). Lorsque vous utilisez cette méthode, l'exécution attend que tous les événements dépendants soient signalés avant de lancer l'évaluation. Une fois l'exécution terminée et les résultats prêts à être utilisés, l'événement renvoyé est signalé.
En fonction des appareils qui gèrent l'exécution, l'événement peut être protégé par une barrière de synchronisation. Vous devez appeler ANeuralNetworksEvent_wait() pour attendre l'événement et récupérer les ressources utilisées par l'exécution. Vous pouvez importer des barrières de synchronisation vers un objet d'événement avec ANeuralNetworksEvent_createFromSyncFenceFd() et les exporter à partir d'un objet d'événement avec ANeuralNetworksEvent_getSyncFenceFd()
Sorties de taille dynamique
Pour utiliser des modèles dont la taille de la sortie dépend des données d'entrée (lorsque la taille ne peut pas être déterminée au moment de l'exécution du modèle), utilisez ANeuralNetworksExecution_getOutputOperandRank et ANeuralNetworksExecution_getOutputOperandDimensions.
L'exemple de code suivant montre comment procéder :
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
Effectuer un nettoyage
L'étape de nettoyage gère la libération des ressources internes utilisées pour votre calcul.
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
Gestion des erreurs et retour au processeur
En cas d'erreur lors du partitionnement, si un pilote ne parvient pas à compiler une partie ou la totalité d'un modèle, ou si un pilote ne parvient pas à exécuter une partie ou la totalité d'un modèle compilé, NNAPI peut revenir à sa propre implémentation de processeur pour une ou plusieurs opérations.
Si le client NNAPI contient des versions optimisées de l'opération (par exemple, TFLite), il peut être avantageux de désactiver le retour au processeur et de gérer les défaillances lors de l'implémentation de l'opération optimisée du client.
Dans Android 10, si la compilation est effectuée avec ANeuralNetworksCompilation_createForDevices, le retour au processeur est désactivé.
Dans Android P, l'exécution de NNAPI revient au processeur en cas d'échec de l'exécution sur le pilote.
C'est également le cas sur Android 10 lorsque vous utilisez ANeuralNetworksCompilation_create au lieu d'ANeuralNetworksCompilation_createForDevices.
La première exécution revient au processeur pour cette partition unique et, si l'opération échoue toujours, l'ensemble du modèle est relancé sur le processeur.
Si le partitionnement ou la compilation échoue, l'intégralité du modèle est testée sur le processeur.
Dans certains cas, certaines opérations ne sont pas compatibles avec le processeur, et la compilation ou l'exécution échoue au lieu de revenir au processeur.
Même après avoir désactivé la fonctionnalité de retour au processeur, des opérations dans le modèle peuvent être planifiées sur le processeur. Si ce dernier figure dans la liste des processeurs fournis à ANeuralNetworksCompilation_createForDevices et qu'il est le seul à prendre en charge ces opérations ou qu'il revendique des performances optimales pour ces opérations, il sera choisi comme exécuteur principal (et non comme processeur de secours).
Pour éviter toute exécution du processeur, utilisez ANeuralNetworksCompilation_createForDevices tout en excluant nnapi-reference de la liste des appareils.
À partir d'Android P, il est possible de désactiver le retour au processeur au moment de l'exécution sur les compilations DEBUG. Pour ce faire, définissez la propriété debug.nn.partition sur 2.
Domaines de mémoire
Dans Android 11 et les versions ultérieures, NNAPI est compatible avec les domaines de mémoire qui fournissent des interfaces d'allocation pour les mémoires opaques. Cela permet aux applications de transmettre les mémoires natives d'appareils lors des exécutions. Dès lors, NNAPI ne copie et ne transforme pas les données inutilement lors d'exécutions consécutives sur le même pilote.
La fonctionnalité de domaine de mémoire est destinée aux tenseurs principalement internes pour le pilote et qui n'ont pas besoin d'un accès fréquent côté client. Parmi ces tenseurs, citons les tenseurs d'état dans les modèles de séquence. Pour les tenseurs qui nécessitent un accès fréquent au processeur côté client, utilisez plutôt des pools de mémoire partagés.
Pour allouer une mémoire opaque, procédez comme suit :
Appelez la fonction
ANeuralNetworksMemoryDesc_create()pour créer un descripteur de mémoire :// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
Appelez
ANeuralNetworksMemoryDesc_addInputRole()etANeuralNetworksMemoryDesc_addOutputRole()pour spécifier tous les rôles d'entrée et de sortie souhaités.// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
Vous pouvez également définir les dimensions de la mémoire en appelant
ANeuralNetworksMemoryDesc_setDimensions().// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
Finalisez la définition du descripteur en appelant
ANeuralNetworksMemoryDesc_finish().ANeuralNetworksMemoryDesc_finish(desc);
Attribuez autant de mémoires que nécessaire en transmettant le descripteur à
ANeuralNetworksMemory_createFromDesc().// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
Libérez le descripteur de mémoire lorsque vous n'en avez plus besoin.
ANeuralNetworksMemoryDesc_free(desc);
Le client ne peut utiliser l'objet ANeuralNetworksMemory créé avec ANeuralNetworksExecution_setInputFromMemory() ou ANeuralNetworksExecution_setOutputFromMemory() qu'avec les rôles spécifiés dans l'objet ANeuralNetworksMemoryDesc. Les arguments de décalage et de longueur doivent être définis sur 0, ce qui indique que l'intégralité de la mémoire est utilisée. Le client peut également définir ou extraire explicitement le contenu de la mémoire avec ANeuralNetworksMemory_copy().
Vous pouvez créer des mémoires opaques avec des rôles dont le rang ou la dimension ne sont pas spécifiés.
Dans ce cas, la création de la mémoire peut échouer avec l'état ANEURALNETWORKS_OP_FAILED si elle n'est pas compatible avec le pilote sous-jacent. Le client est invité à mettre en œuvre une logique de secours en allouant un tampon suffisamment volumineux reposant sur Ashmem ou un élément AHardwareBuffer en mode BLOB.
Lorsque NNAPI n'a plus besoin d'accéder à l'objet mémoire opaque, libérez l'instance ANeuralNetworksMemory correspondante :
ANeuralNetworksMemory_free(opaqueMem);
Évaluer les performances
Pour évaluer les performances de votre application, mesurez le temps d'exécution ou créez un profil.
Temps d'exécution
Lorsque vous souhaitez déterminer le temps total d'exécution via l'environnement d'exécution, vous pouvez utiliser l'API d'exécution synchrone et mesurer le temps passé par l'appel. Lorsque vous souhaitez déterminer le temps total d'exécution via un niveau inférieur de la pile logicielle, vous pouvez utiliser ANeuralNetworksExecution_setMeasureTiming et ANeuralNetworksExecution_getDuration pour obtenir :
- le temps d'exécution sur un accélérateur (pas dans le pilote, qui s'exécute sur le processeur hôte) ;
- le temps d'exécution dans le pilote, y compris le temps passé sur l'accélérateur.
Le temps d'exécution dans le pilote exclut les surcharges potentielles, tels que celle de l'environnement d'exécution lui-même et l'IPC nécessaire pour que l'environnement d'exécution communique avec le pilote.
Ces API mesurent la durée entre les événements de début et de fin de la tâche, plutôt que le temps consacré par un pilote ou un accélérateur pour réaliser l'inférence, qui peut être interrompue par un changement de contexte.
Par exemple, si l'inférence 1 commence, que le pilote arrête la tâche pour réaliser l'inférence 2, puis reprend et termine l'inférence 1, le temps d'exécution de l'inférence 1 inclut le temps pendant lequel la tâche a été arrêtée pour effectuer l'inférence 2.
Ces informations temporelles peuvent s'avérer utiles pour le déploiement en production d'une application afin de collecter la télémétrie pour une utilisation hors connexion. Vous pouvez utiliser ces données temporelles pour modifier l'application et en améliorer les performances.
Lorsque vous utilisez cette fonctionnalité, tenez compte des points suivants :
- La collecte d'informations temporelles peut avoir un coût en termes de performances.
- Seul un pilote est capable de calculer le temps passé par lui-même ou sur l'accélérateur, à l'exclusion du temps passé dans l'environnement d'exécution NNAPI et dans IPC.
- Vous ne pouvez utiliser ces API qu'avec un élément
ANeuralNetworksExecutionqui a été créé avecANeuralNetworksCompilation_createForDevicesetnumDevices = 1. - Vous n'avez pas besoin de pilote pour pouvoir fournir des informations temporelles.
Profiler votre application avec Android Systrace
À partir d'Android 10, NNAPI génère automatiquement des événements systrace que vous pouvez utiliser pour profiler votre application.
La source NNAPI est fournie avec un utilitaire parse_systrace permettant de traiter les événements systrace générés par votre application et de générer une vue Tableau indiquant le temps passé dans les différentes phases du cycle de vie du modèle (instanciation, préparation, compilation, exécution et finalisation) et dans les différentes couches des applications. Les couches dans lesquelles votre application est divisée sont les suivantes :
Application: code principal de l'applicationRuntime: environnement d'exécution NNAPIIPC: communication interprocessus entre l'environnement d'exécution NNAPI et le code du piloteDriver: processus du pilote de l'accélérateur
Générer les données d'analyse de profilage
En supposant que vous avez consulté l'arborescence source d'AOSP sous $ANDROID_BUILD_TOP et en utilisant l'exemple de classification d'images TFLite comme application cible, vous pouvez générer les données de profilage NNAPI comme suit :
- Lancez Android Systrace via la commande suivante :
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
Le paramètre -o trace.html indique que les traces seront écrites dans trace.html. Lorsque vous profilez votre propre application, vous devez remplacer org.tensorflow.lite.examples.classification par le nom de processus spécifié dans le fichier manifeste de votre application.
Cela occupe l'une des consoles de votre interface système. N'exécutez pas la commande en arrière-plan, car elle attend de manière interactive un élément enter pour s'arrêter.
- Une fois le collecteur systrace démarré, lancez votre application et exécutez votre test d'analyse comparative.
Dans notre cas, vous pouvez démarrer l'application Image Classification (Classification d'images) à partir d'Android Studio ou directement depuis l'interface utilisateur du téléphone de test si l'application est déjà installée. Pour générer des données NNAPI, vous devez configurer l'application de sorte qu'elle utilise NNAPI. Pour ce faire, sélectionnez NNAPI comme appareil cible dans la boîte de dialogue de configuration de l'application.
Une fois le test terminé, arrêtez systrace en appuyant sur
entersur le terminal de la console qui est actif depuis l'étape 1.Exécutez l'utilitaire
systrace_parserpour générer des statistiques cumulées :
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
L'analyseur accepte les paramètres suivants :
- --total-times : affiche le temps total passé dans une couche, y compris le temps passé à exécuter l'appel d'une couche sous-jacente.
- --print-detail : imprime tous les événements collectés à partir de systrace.
--per-execution : imprime uniquement l'exécution et ses sous-phases (en fonction du temps d'exécution) au lieu des statistiques pour toutes les phases.
- --json : génère la sortie au format JSON.
Voici un exemple de sortie :
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
L'analyseur peut échouer si les événements collectés ne représentent pas une trace d'application complète. Il peut notamment échouer si les événements systrace générés pour marquer la fin d'une section sont présents dans la trace sans événement de début de section associé. Cela se produit généralement si certains événements d'une session de profilage précédente sont générés lorsque vous démarrez le collecteur systrace. Dans ce cas, vous devrez réexécuter le profilage.
Ajouter des statistiques à la sortie systrace_parser pour le code d'application
L'application parse_systrace repose sur la fonctionnalité systrace Android intégrée. Vous pouvez ajouter des traces pour des opérations spécifiques dans votre application à l'aide de l'API systrace (pour Java, pour les applications natives) avec des noms d'événements personnalisés.
Pour associer vos événements personnalisés aux phases du cycle de vie de l'application, ajoutez le nom de l'événement à l'une des chaînes suivantes :
[NN_LA_PI]: événement au niveau de l'application pour l'initialisation[NN_LA_PP]: événement au niveau de l'application pour la préparation[NN_LA_PC]: événement au niveau de l'application pour la compilation[NN_LA_PE]: événement au niveau de l'application pour l'exécution
Voici un exemple montrant comment modifier l'exemple de code de classification d'images TFLite en ajoutant une section runInferenceModel pour la phase Execution et la couche Application contenant une autre section preprocessBitmap qui ne sera pas prise en compte dans les traces NNAPI. La section runInferenceModel fera partie des événements systrace traités par l'analyseur systrace nnapi :
Kotlin
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
Java
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
Qualité de service
Dans Android 11 et les versions ultérieures, NNAPI implique une meilleure qualité de service (QoS) en permettant à une application d'indiquer les priorités relatives de ses modèles, le temps maximal attendu pour préparer un modèle donné et la durée maximale de temps attendu pour effectuer un calcul donné. Android 11 comprend également des codes de résultats NNAPI supplémentaires qui permettent aux applications de comprendre les échecs tels que les délais d'exécution manqués.
Définir la priorité d'une charge de travail
Pour définir la priorité d'une charge de travail NNAPI, appelez ANeuralNetworksCompilation_setPriority() avant ANeuralNetworksCompilation_finish().
Définir des délais
Les applications peuvent définir des délais pour la compilation et l'inférence des modèles.
- Pour définir le délai avant expiration de la compilation, appelez
ANeuralNetworksCompilation_setTimeout()avantANeuralNetworksCompilation_finish(). - Pour définir le délai avant expiration de l'inférence, appelez
ANeuralNetworksExecution_setTimeout()avant de lancer la compilation.
En savoir plus sur les opérandes
La section suivante aborde des sujets avancés concernant l'utilisation des opérandes.
Tenseurs quantifiés
Un tenseur quantifié est un moyen compact de représenter un tableau de valeurs à virgule flottante à n dimensions.
NNAPI est compatible avec les tenseurs quantifiés asymétriques 8 bits. Pour ces tenseurs, la valeur de chaque cellule est représentée par un entier de 8 bits. Une échelle et une valeur zeroPoint sont associés au tenseur. Elles permettent de convertir les entiers 8 bits dans les valeurs à virgule flottante qui sont représentées.
La formule est la suivante :
(cellValue - zeroPoint) * scale
où la valeur zeroPoint est un entier 32 bits et l'échelle une valeur à virgule flottante 32 bits.
Par rapport aux tenseurs de valeurs à virgule flottante 32 bits, les tenseurs quantifiés 8 bits présentent deux avantages :
- Votre application est plus petite, car les pondérations entraînées prennent un quart de la taille des tenseurs 32 bits.
- Les calculs peuvent souvent être exécutés plus rapidement. Cela est dû à la plus petite quantité de données devant être récupérées depuis la mémoire et à l'efficacité des processeurs tels que les DSP pour les calculs à base d'entiers.
Bien qu'il soit possible de convertir un modèle à virgule flottante en un modèle quantifié, d'après notre expérience, de meilleurs résultats sont obtenus en entraînant directement un modèle quantifié. En effet, le réseau de neurones apprend à compenser la précision accrue de chaque valeur. Pour chaque tenseur quantifié, les valeurs d'échelle et les valeurs zeroPoint sont déterminées pendant le processus d'entraînement.
Dans NNAPI, vous définissez le champ de type de la structure de données ANeuralNetworksOperandType sur ANEURALNETWORKS_TENSOR_QUANT8_ASYMM pour spécifier des types de tenseurs quantifiés.
Vous spécifiez également l'échelle et la valeur zeroPoint du tenseur dans cette structure de données.
En plus des tenseurs quantifiés asymétriques 8 bits, NNAPI accepte les éléments suivants :
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNELque vous pouvez utiliser pour représenter les pondérations dans les opérationsCONV/DEPTHWISE_CONV/TRANSPOSED_CONVANEURALNETWORKS_TENSOR_QUANT16_ASYMMque vous pouvez utiliser pour l'état interne deQUANTIZED_16BIT_LSTMANEURALNETWORKS_TENSOR_QUANT8_SYMM, qui peut être une entrée pourANEURALNETWORKS_DEQUANTIZE
Opérandes facultatifs
Certaines opérations, comme ANEURALNETWORKS_LSH_PROJECTION, acceptent des opérandes facultatifs. Pour indiquer dans le modèle que l'opérande facultatif est omis, appelez la fonction ANeuralNetworksModel_setOperandValue(), en transmettant NULL pour la mémoire tampon et 0 pour la longueur.
Le choix d'utiliser l'opérande ou non varie en fonction de chaque exécution. Vous pouvez indiquer que l'opérande est omis à l'aide des fonctions ANeuralNetworksExecution_setInput() ou ANeuralNetworksExecution_setOutput(), en transmettant NULL pour la mémoire tampon et 0 pour la longueur.
Tenseurs de rang inconnu
Android 9 (niveau d'API 28) comprend des opérandes de modèle avec des dimensions inconnues, mais un rang connu (le nombre de dimensions). Android 10 (niveau d'API 29) inclut des tenseurs de rang inconnu, comme indiqué dans ANeuralNetworksOperandType.
Analyse comparative de NNAPI
L'analyse comparative de NNAPI est disponible sur AOSP dans platform/test/mlts/benchmark (application d'analyse comparative) et platform/test/mlts/models (modèles et ensembles de données).
Elle évalue la latence et la justesse, et compare les pilotes au même travail effectué avec TensorFlow Lite exécuté sur le processeur, pour les mêmes modèles et ensembles de données.
Pour exploiter l'analyse comparative, procédez comme suit :
Connectez un appareil Android cible à votre ordinateur, ouvrez une fenêtre de terminal et assurez-vous que l'appareil est accessible via adb.
Si plusieurs appareils Android sont connectés, exportez la variable d'environnement
ANDROID_SERIALde l'appareil cible.Accédez au répertoire source Android de premier niveau.
Exécutez les commandes suivantes :
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
À la fin d'une analyse comparative, ses résultats sont présentés sous la forme d'une page HTML transmise à
xdg-open.
Journaux NNAPI
NNAPI génère des informations de diagnostic utiles dans les journaux système. Pour analyser les journaux, exécutez l'utilitaire logcat.
Activez la journalisation détaillée de NNAPI pour des phases ou des composants spécifiques en définissant la propriété debug.nn.vlog (avec adb shell) sur la liste de valeurs suivantes, séparées par un espace, un signe deux-points ou une virgule :
model: création du modèlecompilation: génération du plan d'exécution et de la compilation du modèleexecution: exécution du modèlecpuexe: exécution des opérations à l'aide de l'implémentation du processeur NNAPImanager: extensions NNAPI, interfaces disponibles et informations relatives aux fonctionnalitésallou1: tous les éléments ci-dessus
Par exemple, pour activer la journalisation détaillée, exécutez la commande adb shell setprop debug.nn.vlog all. Pour désactiver la journalisation détaillée, utilisez la commande adb shell setprop debug.nn.vlog '""'.
Une fois activée, la journalisation détaillée génère des entrées de journal au niveau INFO avec une balise définie sur le nom de la phase ou du composant.
En plus des messages contrôlés debug.nn.vlog, les composants de l'API NNAPI fournissent d'autres entrées de journal à différents niveaux, chacune utilisant une balise de journal spécifique.
Pour obtenir la liste des composants, effectuez une recherche dans l'arborescence source à l'aide de l'expression suivante :
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
Cette expression renvoie actuellement les balises suivantes :
- BurstBuilder
- Callbacks
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- Manager
- Memory
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- Operations
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
Pour contrôler le niveau des messages de journal affiché par logcat, utilisez la variable d'environnement ANDROID_LOG_TAGS.
Pour afficher l'ensemble complet des messages de journal NNAPI et désactiver les autres, définissez ANDROID_LOG_TAGS comme suit :
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
Vous pouvez définir ANDROID_LOG_TAGS à l'aide de la commande suivante :
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
Notez qu'il s'agit d'un filtre qui s'applique à logcat. Vous devez toujours définir la propriété debug.nn.vlog sur all pour générer des informations de journal détaillées.