
Способ тестирования модулей или модулей, взаимодействующих с потоком, зависит от того, использует ли тестируемый объект поток в качестве входных данных или выходных данных.
- Если тестируемый субъект наблюдает поток, вы можете генерировать потоки внутри фиктивных зависимостей, которыми можно управлять с помощью тестов.
- Если модуль или модуль предоставляет поток, вы можете прочитать и проверить один или несколько элементов, созданных потоком в тесте.
Создание фейкового продюсера
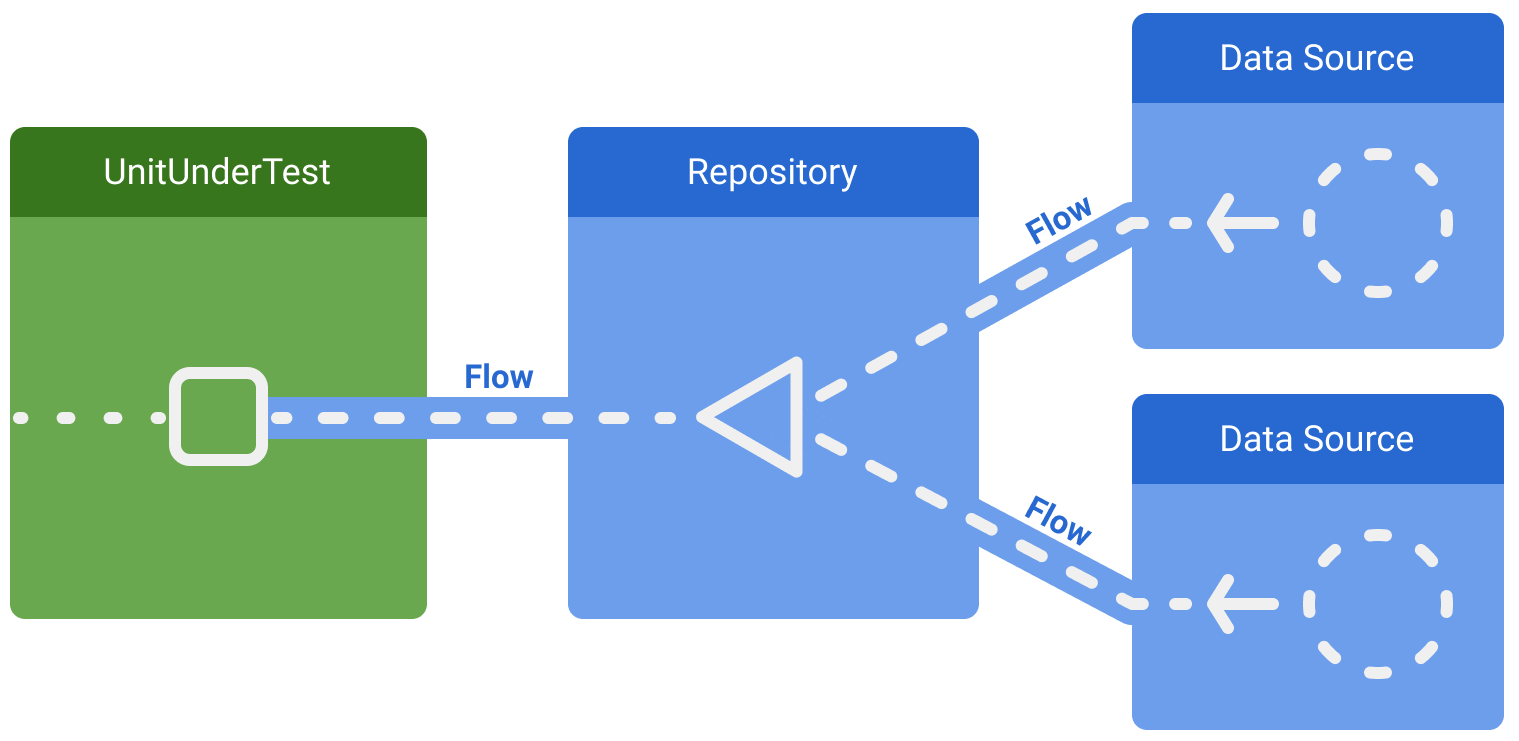
Когда тестируемый объект является потребителем потока, одним из распространенных способов его тестирования является замена производителя поддельной реализацией. Например, дан класс, который наблюдает за репозиторием, который принимает данные из двух источников данных в рабочей среде:
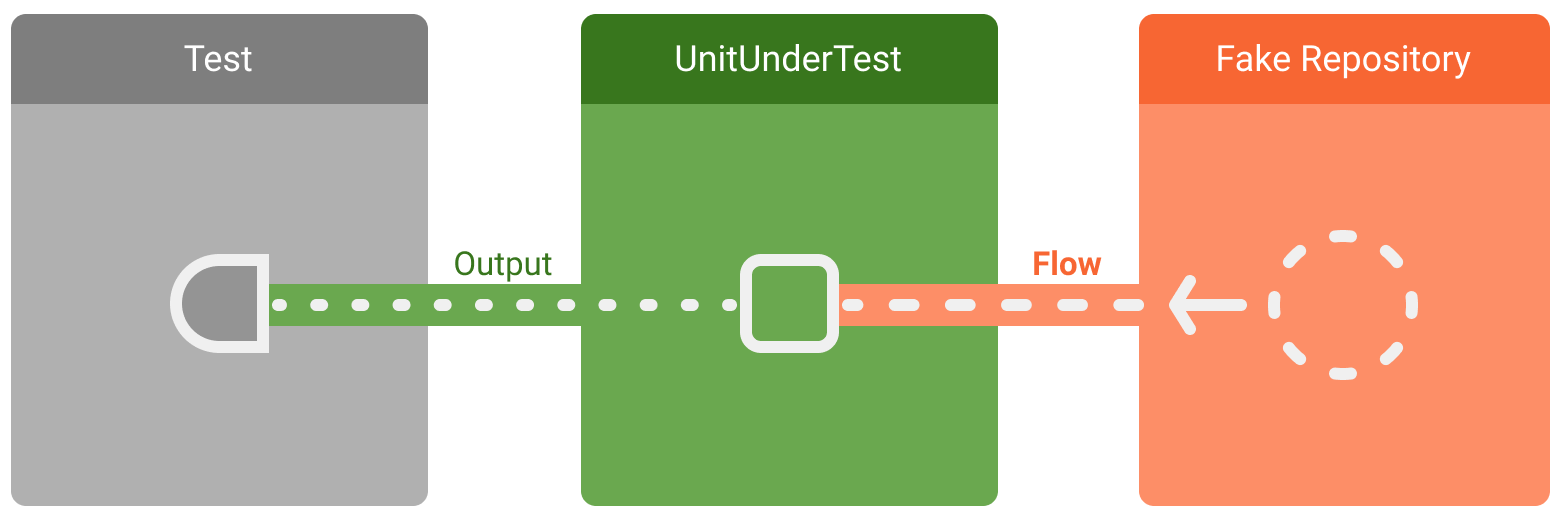
Чтобы сделать тест детерминированным, вы можете заменить репозиторий и его зависимости поддельным репозиторием, который всегда выдает одни и те же поддельные данные:
Чтобы создать предопределенную серию значений в потоке, используйте построитель flow :
class MyFakeRepository : MyRepository {
fun observeCount() = flow {
emit(ITEM_1)
}
}
В тесте внедряется этот фейковый репозиторий, заменяющий реальную реализацию:
@Test
fun myTest() {
// Given a class with fake dependencies:
val sut = MyUnitUnderTest(MyFakeRepository())
// Trigger and verify
...
}
Теперь, когда у вас есть контроль над выходными данными тестируемого объекта, вы можете убедиться, что он работает правильно, проверив его выходные данные.
Подтверждение выбросов потока в тесте
Если тестируемый объект раскрывает поток, тесту необходимо сделать утверждения об элементах потока данных.
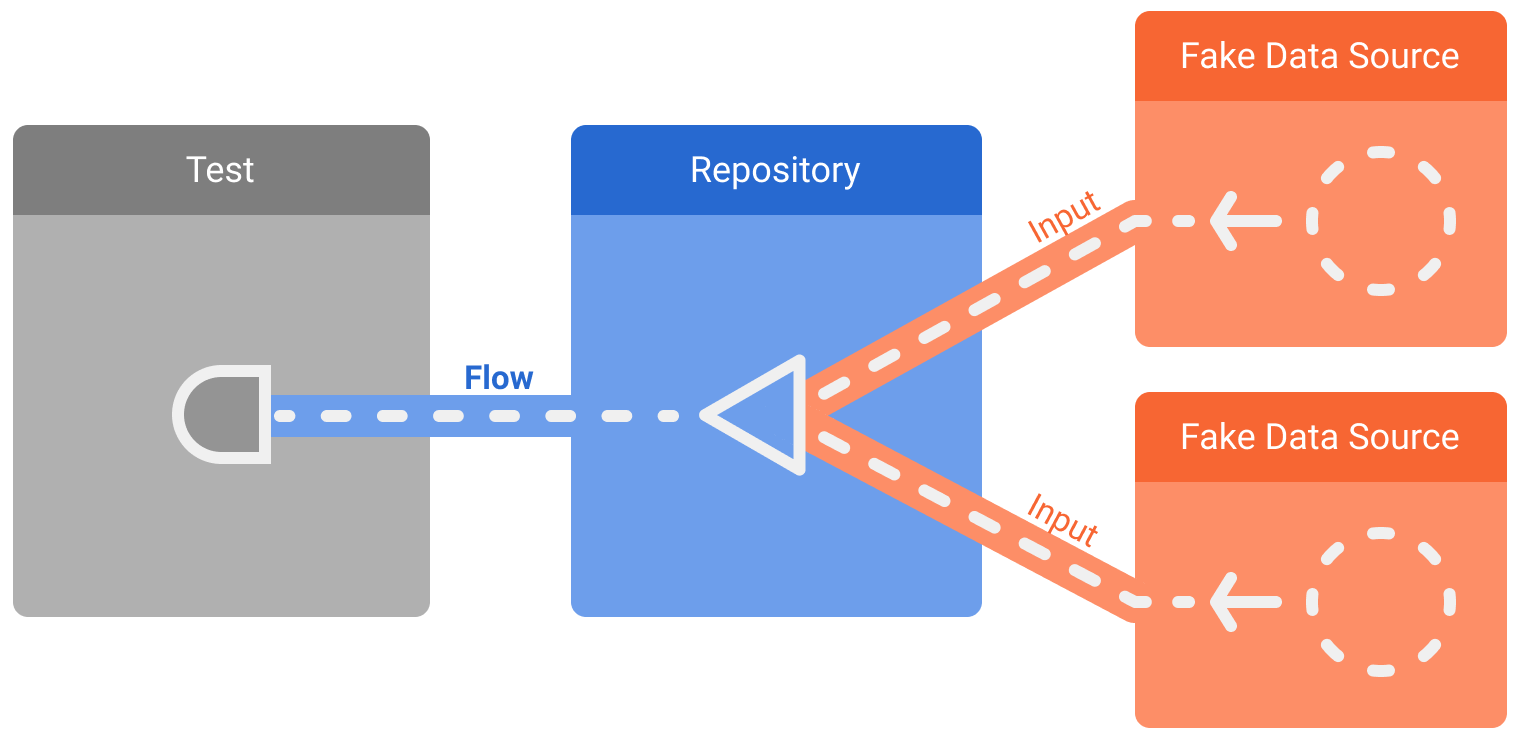
Предположим, что репозиторий предыдущего примера предоставляет поток:
В некоторых тестах вам нужно будет проверить только первую эмиссию или конечное число элементов, поступающих из потока.
Вы можете использовать первую эмиссию в поток, вызвав first() . Эта функция ожидает получения первого элемента, а затем отправляет сигнал отмены производителю.
@Test
fun myRepositoryTest() = runTest {
// Given a repository that combines values from two data sources:
val repository = MyRepository(fakeSource1, fakeSource2)
// When the repository emits a value
val firstItem = repository.counter.first() // Returns the first item in the flow
// Then check it's the expected item
assertEquals(ITEM_1, firstItem)
}
Если тесту необходимо проверить несколько значений, вызов toList() заставляет поток ждать, пока источник выдаст все свои значения, а затем возвращает эти значения в виде списка. Это работает только для конечных потоков данных.
@Test
fun myRepositoryTest() = runTest {
// Given a repository with a fake data source that emits ALL_MESSAGES
val messages = repository.observeChatMessages().toList()
// When all messages are emitted then they should be ALL_MESSAGES
assertEquals(ALL_MESSAGES, messages)
}
Для потоков данных, которые требуют более сложной коллекции элементов или не возвращают конечное число элементов, вы можете использовать Flow API для выбора и преобразования элементов. Вот несколько примеров:
// Take the second item
outputFlow.drop(1).first()
// Take the first 5 items
outputFlow.take(5).toList()
// Takes the first item verifying that the flow is closed after that
outputFlow.single()
// Finite data streams
// Verify that the flow emits exactly N elements (optional predicate)
outputFlow.count()
outputFlow.count(predicate)
Непрерывный сбор во время теста
Сбор потока с помощью toList() как показано в предыдущем примере, использует collect() внутри себя и приостанавливается до тех пор, пока весь список результатов не будет готов к возврату.
Чтобы чередовать действия, которые заставляют поток выдавать значения, и утверждения относительно выданных значений, вы можете непрерывно собирать значения из потока во время теста.
Например, возьмем следующий класс Repository для тестирования и сопровождающую его реализацию поддельного источника данных, которая имеет метод emit для динамического создания значений во время теста:
class Repository(private val dataSource: DataSource) {
fun scores(): Flow<Int> {
return dataSource.counts().map { it * 10 }
}
}
class FakeDataSource : DataSource {
private val flow = MutableSharedFlow<Int>()
suspend fun emit(value: Int) = flow.emit(value)
override fun counts(): Flow<Int> = flow
}
При использовании этого фейка в тесте можно создать собирающую сопрограмму, которая будет непрерывно получать значения из Repository . В этом примере мы собираем их в список, а затем выполняем утверждения по его содержимому:
@Test
fun continuouslyCollect() = runTest {
val dataSource = FakeDataSource()
val repository = Repository(dataSource)
val values = mutableListOf<Int>()
backgroundScope.launch(UnconfinedTestDispatcher(testScheduler)) {
repository.scores().toList(values)
}
dataSource.emit(1)
assertEquals(10, values[0]) // Assert on the list contents
dataSource.emit(2)
dataSource.emit(3)
assertEquals(30, values[2])
assertEquals(3, values.size) // Assert the number of items collected
}
Поскольку поток, представленный здесь Repository никогда не завершается, вызов toList который его собирает, никогда не возвращается. Запуск сопрограммы сбора данных в TestScope.backgroundScope гарантирует, что сопрограмма будет отменена до окончания теста. В противном случае runTest будет продолжать ждать завершения, в результате чего тест перестанет отвечать на запросы и в конечном итоге завершится неудачно.
Обратите внимание, как здесь используется UnconfinedTestDispatcher для сбора сопрограммы. Это гарантирует, что сопрограмма сбора данных запускается без промедления и готова получать значения после возврата launch .
Использование турбины
Сторонняя библиотека Turbine предлагает удобный API для создания сопрограммы-сборщика, а также другие удобные функции для тестирования Flows:
@Test
fun usingTurbine() = runTest {
val dataSource = FakeDataSource()
val repository = Repository(dataSource)
repository.scores().test {
// Make calls that will trigger value changes only within test{}
dataSource.emit(1)
assertEquals(10, awaitItem())
dataSource.emit(2)
awaitItem() // Ignore items if needed, can also use skip(n)
dataSource.emit(3)
assertEquals(30, awaitItem())
}
}
Дополнительную информацию смотрите в документации библиотеки .
Тестирование StateFlows
StateFlow — это наблюдаемый держатель данных, который можно собирать для наблюдения за значениями, которые он хранит, с течением времени в виде потока. Обратите внимание, что этот поток значений объединен, а это означает, что если значения быстро устанавливаются в StateFlow , сборщики этого StateFlow не гарантированно получат все промежуточные значения, а только самое последнее.
В тестах, если вы помните о слиянии, вы можете собирать значения StateFlow так же, как вы можете собирать любой другой поток, в том числе с помощью Turbine. В некоторых сценариях тестирования может оказаться желательной попытка собрать и утвердить все промежуточные значения.
Однако мы обычно рекомендуем рассматривать StateFlow как держатель данных и вместо этого утверждать его свойство value . Таким образом, тесты проверяют текущее состояние объекта в данный момент времени и не зависят от того, произойдет объединение или нет.
Например, возьмем эту ViewModel , которая собирает значения из Repository и предоставляет их пользовательскому интерфейсу в StateFlow :
class MyViewModel(private val myRepository: MyRepository) : ViewModel() {
private val _score = MutableStateFlow(0)
val score: StateFlow<Int> = _score.asStateFlow()
fun initialize() {
viewModelScope.launch {
myRepository.scores().collect { score ->
_score.value = score
}
}
}
}
Поддельная реализация этого Repository может выглядеть так:
class FakeRepository : MyRepository {
private val flow = MutableSharedFlow<Int>()
suspend fun emit(value: Int) = flow.emit(value)
override fun scores(): Flow<Int> = flow
}
При тестировании ViewModel с помощью этой подделки вы можете генерировать значения из подделки, чтобы инициировать обновления в StateFlow ViewModel , а затем утверждать обновленное value :
@Test
fun testHotFakeRepository() = runTest {
val fakeRepository = FakeRepository()
val viewModel = MyViewModel(fakeRepository)
assertEquals(0, viewModel.score.value) // Assert on the initial value
// Start collecting values from the Repository
viewModel.initialize()
// Then we can send in values one by one, which the ViewModel will collect
fakeRepository.emit(1)
assertEquals(1, viewModel.score.value)
fakeRepository.emit(2)
fakeRepository.emit(3)
assertEquals(3, viewModel.score.value) // Assert on the latest value
}
Работа с StateFlow, созданными StateIn
В предыдущем разделе ViewModel использует MutableStateFlow для хранения последнего значения, отправленного потоком из Repository . Это распространенный шаблон, обычно реализуемый более простым способом с помощью оператора stateIn , который преобразует холодный поток в горячий StateFlow :
class MyViewModelWithStateIn(myRepository: MyRepository) : ViewModel() {
val score: StateFlow<Int> = myRepository.scores()
.stateIn(viewModelScope, SharingStarted.WhileSubscribed(5000L), 0)
}
Оператор stateIn имеет параметр SharingStarted , который определяет, когда он становится активным и начинает использовать базовый поток. Такие параметры, как SharingStarted.Lazily и SharingStarted.WhileSubscribed , часто используются в моделях представлений.
Даже если вы утверждаете value StateFlow в своем тесте, вам необходимо создать сборщик. Это может быть пустой коллектор:
@Test
fun testLazilySharingViewModel() = runTest {
val fakeRepository = HotFakeRepository()
val viewModel = MyViewModelWithStateIn(fakeRepository)
// Create an empty collector for the StateFlow
backgroundScope.launch(UnconfinedTestDispatcher(testScheduler)) {
viewModel.score.collect {}
}
assertEquals(0, viewModel.score.value) // Can assert initial value
// Trigger-assert like before
fakeRepository.emit(1)
assertEquals(1, viewModel.score.value)
fakeRepository.emit(2)
fakeRepository.emit(3)
assertEquals(3, viewModel.score.value)
}
Дополнительные ресурсы
- Тестирование сопрограмм Kotlin на Android
- Kotlin работает на Android
-
StateFlowиSharedFlow - Дополнительные ресурсы для сопрограмм и потоков Kotlin
Способ тестирования модулей или модулей, взаимодействующих с потоком, зависит от того, использует ли тестируемый объект поток в качестве входных данных или выходных данных.
- Если тестируемый субъект наблюдает поток, вы можете генерировать потоки внутри фиктивных зависимостей, которыми можно управлять с помощью тестов.
- Если модуль или модуль предоставляет поток, вы можете прочитать и проверить один или несколько элементов, созданных потоком, в тесте.
Создание фейкового продюсера
Когда тестируемый объект является потребителем потока, одним из распространенных способов его тестирования является замена производителя поддельной реализацией. Например, дан класс, который наблюдает за репозиторием, который принимает данные из двух источников данных в рабочей среде:
Чтобы сделать тест детерминированным, вы можете заменить репозиторий и его зависимости поддельным репозиторием, который всегда выдает одни и те же поддельные данные:
Чтобы создать предопределенную серию значений в потоке, используйте построитель flow :
class MyFakeRepository : MyRepository {
fun observeCount() = flow {
emit(ITEM_1)
}
}
В тесте внедряется этот фейковый репозиторий, заменяющий реальную реализацию:
@Test
fun myTest() {
// Given a class with fake dependencies:
val sut = MyUnitUnderTest(MyFakeRepository())
// Trigger and verify
...
}
Теперь, когда у вас есть контроль над выходными данными тестируемого объекта, вы можете убедиться, что он работает правильно, проверив его выходные данные.
Подтверждение выбросов потока в тесте
Если тестируемый объект раскрывает поток, тесту необходимо сделать утверждения об элементах потока данных.
Предположим, что репозиторий предыдущего примера предоставляет поток:
В некоторых тестах вам нужно будет проверить только первую эмиссию или конечное число элементов, поступающих из потока.
Вы можете использовать первую эмиссию в поток, вызвав first() . Эта функция ожидает получения первого элемента, а затем отправляет сигнал отмены производителю.
@Test
fun myRepositoryTest() = runTest {
// Given a repository that combines values from two data sources:
val repository = MyRepository(fakeSource1, fakeSource2)
// When the repository emits a value
val firstItem = repository.counter.first() // Returns the first item in the flow
// Then check it's the expected item
assertEquals(ITEM_1, firstItem)
}
Если тесту необходимо проверить несколько значений, вызов toList() заставляет поток ждать, пока источник выдаст все свои значения, а затем возвращает эти значения в виде списка. Это работает только для конечных потоков данных.
@Test
fun myRepositoryTest() = runTest {
// Given a repository with a fake data source that emits ALL_MESSAGES
val messages = repository.observeChatMessages().toList()
// When all messages are emitted then they should be ALL_MESSAGES
assertEquals(ALL_MESSAGES, messages)
}
Для потоков данных, которые требуют более сложной коллекции элементов или не возвращают конечное число элементов, вы можете использовать Flow API для выбора и преобразования элементов. Вот несколько примеров:
// Take the second item
outputFlow.drop(1).first()
// Take the first 5 items
outputFlow.take(5).toList()
// Takes the first item verifying that the flow is closed after that
outputFlow.single()
// Finite data streams
// Verify that the flow emits exactly N elements (optional predicate)
outputFlow.count()
outputFlow.count(predicate)
Непрерывный сбор во время теста
Сбор потока с помощью toList() как показано в предыдущем примере, использует collect() внутри себя и приостанавливается до тех пор, пока весь список результатов не будет готов к возврату.
Чтобы чередовать действия, которые заставляют поток выдавать значения, и утверждения относительно выданных значений, вы можете непрерывно собирать значения из потока во время теста.
Например, возьмем следующий класс Repository для тестирования и сопровождающую его реализацию поддельного источника данных, которая имеет метод emit для динамического создания значений во время теста:
class Repository(private val dataSource: DataSource) {
fun scores(): Flow<Int> {
return dataSource.counts().map { it * 10 }
}
}
class FakeDataSource : DataSource {
private val flow = MutableSharedFlow<Int>()
suspend fun emit(value: Int) = flow.emit(value)
override fun counts(): Flow<Int> = flow
}
При использовании этого фейка в тесте можно создать собирающую сопрограмму, которая будет непрерывно получать значения из Repository . В этом примере мы собираем их в список, а затем выполняем утверждения по его содержимому:
@Test
fun continuouslyCollect() = runTest {
val dataSource = FakeDataSource()
val repository = Repository(dataSource)
val values = mutableListOf<Int>()
backgroundScope.launch(UnconfinedTestDispatcher(testScheduler)) {
repository.scores().toList(values)
}
dataSource.emit(1)
assertEquals(10, values[0]) // Assert on the list contents
dataSource.emit(2)
dataSource.emit(3)
assertEquals(30, values[2])
assertEquals(3, values.size) // Assert the number of items collected
}
Поскольку поток, представленный здесь Repository никогда не завершается, вызов toList который его собирает, никогда не возвращается. Запуск сопрограммы сбора данных в TestScope.backgroundScope гарантирует, что сопрограмма будет отменена до окончания теста. В противном случае runTest будет продолжать ждать завершения, в результате чего тест перестанет отвечать на запросы и в конечном итоге завершится неудачно.
Обратите внимание, как здесь используется UnconfinedTestDispatcher для сбора сопрограммы. Это гарантирует, что сопрограмма сбора данных запускается без промедления и готова получать значения после возврата launch .
Использование турбины
Сторонняя библиотека Turbine предлагает удобный API для создания сопрограммы-сборщика, а также другие удобные функции для тестирования Flows:
@Test
fun usingTurbine() = runTest {
val dataSource = FakeDataSource()
val repository = Repository(dataSource)
repository.scores().test {
// Make calls that will trigger value changes only within test{}
dataSource.emit(1)
assertEquals(10, awaitItem())
dataSource.emit(2)
awaitItem() // Ignore items if needed, can also use skip(n)
dataSource.emit(3)
assertEquals(30, awaitItem())
}
}
Дополнительную информацию смотрите в документации библиотеки .
Тестирование StateFlows
StateFlow — это наблюдаемый держатель данных, который можно собирать для наблюдения за значениями, которые он хранит, с течением времени в виде потока. Обратите внимание, что этот поток значений объединен, а это означает, что если значения быстро устанавливаются в StateFlow , сборщики этого StateFlow не гарантированно получат все промежуточные значения, а только самое последнее.
В тестах, если вы помните о слиянии, вы можете собирать значения StateFlow так же, как вы можете собирать любой другой поток, в том числе с помощью Turbine. В некоторых сценариях тестирования может оказаться желательной попытка собрать и утвердить все промежуточные значения.
Однако мы обычно рекомендуем рассматривать StateFlow как держатель данных и вместо этого утверждать его свойство value . Таким образом, тесты проверяют текущее состояние объекта в данный момент времени и не зависят от того, произойдет объединение или нет.
Например, возьмем эту ViewModel , которая собирает значения из Repository и предоставляет их пользовательскому интерфейсу в StateFlow :
class MyViewModel(private val myRepository: MyRepository) : ViewModel() {
private val _score = MutableStateFlow(0)
val score: StateFlow<Int> = _score.asStateFlow()
fun initialize() {
viewModelScope.launch {
myRepository.scores().collect { score ->
_score.value = score
}
}
}
}
Поддельная реализация этого Repository может выглядеть так:
class FakeRepository : MyRepository {
private val flow = MutableSharedFlow<Int>()
suspend fun emit(value: Int) = flow.emit(value)
override fun scores(): Flow<Int> = flow
}
При тестировании ViewModel с помощью этой подделки вы можете генерировать значения из подделки, чтобы инициировать обновления в StateFlow ViewModel , а затем утверждать обновленное value :
@Test
fun testHotFakeRepository() = runTest {
val fakeRepository = FakeRepository()
val viewModel = MyViewModel(fakeRepository)
assertEquals(0, viewModel.score.value) // Assert on the initial value
// Start collecting values from the Repository
viewModel.initialize()
// Then we can send in values one by one, which the ViewModel will collect
fakeRepository.emit(1)
assertEquals(1, viewModel.score.value)
fakeRepository.emit(2)
fakeRepository.emit(3)
assertEquals(3, viewModel.score.value) // Assert on the latest value
}
Работа с StateFlow, созданными StateIn
В предыдущем разделе ViewModel использует MutableStateFlow для хранения последнего значения, отправленного потоком из Repository . Это распространенный шаблон, обычно реализуемый более простым способом с помощью оператора stateIn , который преобразует холодный поток в горячий StateFlow :
class MyViewModelWithStateIn(myRepository: MyRepository) : ViewModel() {
val score: StateFlow<Int> = myRepository.scores()
.stateIn(viewModelScope, SharingStarted.WhileSubscribed(5000L), 0)
}
Оператор stateIn имеет параметр SharingStarted , который определяет, когда он становится активным и начинает использовать базовый поток. Такие параметры, как SharingStarted.Lazily и SharingStarted.WhileSubscribed , часто используются в моделях представлений.
Даже если вы утверждаете value StateFlow в своем тесте, вам необходимо создать сборщик. Это может быть пустой коллектор:
@Test
fun testLazilySharingViewModel() = runTest {
val fakeRepository = HotFakeRepository()
val viewModel = MyViewModelWithStateIn(fakeRepository)
// Create an empty collector for the StateFlow
backgroundScope.launch(UnconfinedTestDispatcher(testScheduler)) {
viewModel.score.collect {}
}
assertEquals(0, viewModel.score.value) // Can assert initial value
// Trigger-assert like before
fakeRepository.emit(1)
assertEquals(1, viewModel.score.value)
fakeRepository.emit(2)
fakeRepository.emit(3)
assertEquals(3, viewModel.score.value)
}
Дополнительные ресурсы
- Тестирование сопрограмм Kotlin на Android
- Kotlin работает на Android
-
StateFlowиSharedFlow - Дополнительные ресурсы для сопрограмм и потоков Kotlin