


Команда Android Runtime (ART) сократила время компиляции на 18% без ущерба для качества скомпилированного кода и снижения пиковых нагрузок на память. Это улучшение стало частью нашей инициативы 2025 года по улучшению времени компиляции без ущерба для использования памяти или качества скомпилированного кода.
Оптимизация скорости компиляции имеет решающее значение для ART. Например, при компиляции «на лету» (JIT) это напрямую влияет на эффективность приложений и общую производительность устройства. Более быстрая компиляция сокращает время до начала оптимизации, что приводит к более плавной и отзывчивой работе пользователя. Кроме того, как для JIT, так и для компиляции «на лету» (AOT), улучшение скорости компиляции приводит к снижению потребления ресурсов в процессе компиляции, что положительно сказывается на времени автономной работы и теплоотводе устройства, особенно на устройствах низкого ценового сегмента.
Часть этих улучшений скорости компиляции была внедрена в июньском релизе Android 2025 года, а остальные будут доступны в релизе Android в конце года. Кроме того, все пользователи Android версий 12 и выше имеют право получить эти улучшения через основные обновления .
Оптимизация оптимизирующего компилятора
Оптимизация компилятора — это всегда игра на компромиссы. Нельзя просто получить скорость бесплатно; приходится чем-то жертвовать. Мы поставили перед собой очень четкую и сложную цель: сделать компилятор быстрее, но сделать это без регрессии в использовании памяти и, что особенно важно, без ухудшения качества создаваемого им кода. Если компилятор быстрее, но приложения работают медленнее, значит, мы потерпели неудачу.
Единственный ресурс, который мы были готовы потратить, — это наше собственное время на разработку, чтобы глубоко изучить проблему, провести исследование и найти оригинальные решения, отвечающие этим строгим критериям. Давайте подробнее рассмотрим, как мы работаем над выявлением областей для улучшения, а также над поиском правильных решений различных проблем.
Поиск перспективных вариантов оптимизации
Прежде чем приступить к оптимизации метрики, необходимо её измерить. В противном случае вы никогда не сможете быть уверены, улучшили вы её или нет. К счастью, скорость компиляции достаточно стабильна, если принять некоторые меры предосторожности, например, использовать одно и то же устройство для измерения до и после изменения, а также убедиться, что устройство не перегревается. Кроме того, у нас есть детерминированные измерения, такие как статистика компилятора, которые помогают нам понять, что происходит «под капотом».
Поскольку ресурсом, которым мы жертвовали ради этих улучшений, было наше время на разработку, мы хотели как можно быстрее вносить изменения. Это означало, что мы взяли несколько репрезентативных приложений (смесь собственных приложений, сторонних приложений и самой операционной системы Android) для создания прототипов. Позже мы убедились, что финальная реализация того стоит, проведя широкомасштабное тестирование как вручную, так и с помощью автоматизированных тестов.
С помощью этого набора тщательно отобранных APK-файлов мы запустим локальную компиляцию вручную, получим профиль компиляции и используем pprof для визуализации того, на что мы тратим время.
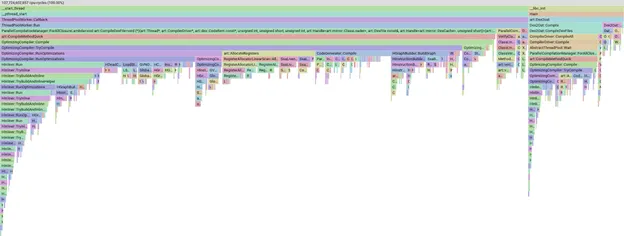
Пример графика пламени профиля в pprof
Инструмент pprof очень мощный и позволяет нам анализировать, фильтровать и сортировать данные, чтобы, например, определить, какие этапы или методы компиляции занимают больше всего времени. Мы не будем подробно рассказывать о самом pprof; просто знайте, что если полоска больше, это означает, что компиляция заняла больше времени.
Один из таких способов представления данных — «снизу вверх», позволяющий увидеть, какие методы занимают больше всего времени. На изображении ниже мы видим метод Kill, на долю которого приходится более 1% времени компиляции. Некоторые другие наиболее часто используемые методы будут рассмотрены позже в этой статье.
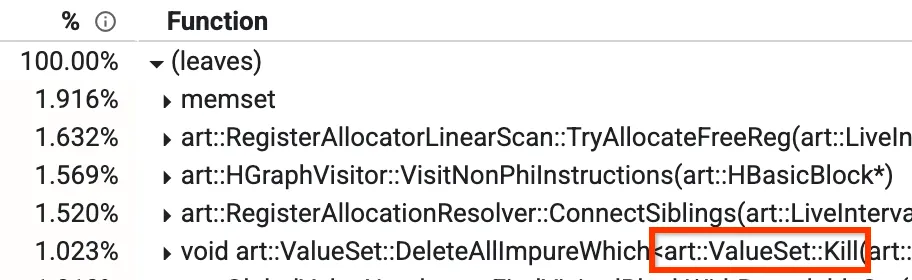
Вид профиля снизу вверх
В нашем оптимизирующем компиляторе есть этап, называемый глобальной нумерацией значений (GVN). Вам не нужно беспокоиться о том, что он делает в целом, но важно знать, что у него есть метод `Kill`, который удаляет некоторые узлы в соответствии с фильтром. Это занимает много времени, поскольку приходится перебирать все узлы и проверять каждый по отдельности. Мы заметили, что в некоторых случаях мы заранее знаем, что проверка будет ложной, независимо от того, какие узлы у нас есть в данный момент. В таких случаях мы можем вообще пропустить итерацию , снизив ее с 1,023% до ~0,3% и улучшив время выполнения GVN примерно на 15%.
Внедрение эффективных оптимизаций
Мы рассмотрели, как измерять и определять, на что тратится время, но это только начало. Следующий шаг — оптимизация времени, затрачиваемого на компиляцию.
Обычно в таких случаях, как описанный выше случай с «уничтожением», мы бы рассмотрели, как ускорить итерацию по узлам, например, за счет параллельного выполнения операций или улучшения самого алгоритма. На самом деле, именно это мы и попробовали сначала, и только когда не нашли ничего подходящего, нас осенило: «Подождите-ка…», и мы поняли, что решение (в некоторых случаях) заключается в том, чтобы вообще не выполнять итерации! При проведении подобных оптимизаций легко упустить из виду главное.
В других случаях мы использовали несколько различных методов, в том числе:
- Использование эвристических методов для определения того, не даст ли оптимизация значимых результатов и, следовательно, может ли она быть пропущена.
- использование дополнительных структур данных для кэширования вычисленных данных
- изменение существующих структур данных для повышения скорости.
- в некоторых случаях используется ленивое вычисление результатов для избежания циклов.
- Используйте правильную абстракцию — ненужные функции могут замедлить работу кода.
- Избегайте постоянного отслеживания часто используемого указателя при многократных загрузках.
Как понять, стоит ли проводить оптимизацию?
Самое интересное, что вы этого не делаете. После обнаружения области, потребляющей много времени компиляции, и после того, как вы потратили время на разработку, пытаясь её улучшить, иногда просто не удаётся найти решение. Возможно, ничего нельзя сделать, реализация займёт слишком много времени, это значительно ухудшит другой показатель, увеличит сложность кодовой базы и т. д. На каждую успешную оптимизацию, о которой вы можете прочитать в этом посте, приходится бесчисленное множество других, которые просто не были реализованы.
Если вы оказались в подобной ситуации, попробуйте оценить, насколько вы сможете улучшить показатель, прилагая как можно меньше усилий. Это означает, в следующем порядке:
- Оценка на основе уже собранных показателей или просто интуиции.
- Оценка стоимости с помощью быстрого и не совсем идеального прототипа.
- Реализуйте решение.
Не забудьте оценить недостатки вашего решения. Например, если вы собираетесь использовать дополнительные структуры данных, сколько памяти вы готовы использовать?
Погружение глубже
Итак, без лишних слов, давайте рассмотрим некоторые из изменений, которые мы внедрили.
Мы внесли изменения для оптимизации метода FindReferenceInfoOf. Этот метод выполнял линейный поиск элемента в векторе. Мы обновили структуру данных, добавив индексацию по идентификатору инструкции, чтобы FindReferenceInfoOf стал O(1) вместо O(n). Кроме того, мы предварительно выделили память для вектора, чтобы избежать его изменения размера. Мы немного увеличили объем памяти, так как нам пришлось добавить дополнительное поле, которое подсчитывало количество вставленных элементов в вектор, но это была небольшая жертва, поскольку пиковый объем памяти не увеличился. Это ускорило фазу LoadStoreAnalysis на 34-66%, что, в свою очередь, дает улучшение времени компиляции примерно на 0,5-1,8%.
У нас есть собственная реализация HashSet, которую мы используем в нескольких местах. Создание этой структуры данных занимало значительное количество времени, и мы выяснили причину. Много лет назад эта структура данных использовалась лишь в немногих местах, где применялись очень большие HashSet, и она была оптимизирована для таких условий. Однако сейчас она используется в обратном направлении, с небольшим количеством записей и коротким сроком жизни. Это означало, что мы тратили циклы впустую, создавая этот огромный HashSet, но использовали его лишь для нескольких записей, прежде чем отбросить. Благодаря этому изменению мы улучшили время компиляции примерно на 1,3-2%. В качестве дополнительного бонуса, использование памяти уменьшилось примерно на 0,5-1%, поскольку мы больше не использовали такие большие структуры данных, как раньше.
Мы улучшили время компиляции примерно на 0,5-1%, передавая структуры данных по ссылке в лямбда-функцию, чтобы избежать их копирования. Это упустили при первоначальном анализе, и этот момент годами оставался в нашем коде. Благодаря изучению профилирования в pprof мы заметили, что эти методы создают и уничтожают множество структур данных, что побудило нас исследовать и оптимизировать их.
Мы ускорили этап записи скомпилированного результата за счет кэширования вычисленных значений , что привело к улучшению общего времени компиляции примерно на 1,3-2,8%. К сожалению, дополнительная обработка данных оказалась слишком трудоемкой, и автоматизированное тестирование выявило регрессию в использовании памяти. Позже мы пересмотрели тот же код и реализовали новую версию , которая не только устранила регрессию в использовании памяти, но и улучшила время компиляции еще на ~0,5-1,8%! Во втором изменении нам пришлось переработать и переосмыслить работу этого этапа, чтобы избавиться от одной из двух структур данных.
В нашем оптимизирующем компиляторе есть этап, на котором встраиваются вызовы функций для повышения производительности. Для выбора методов для встраивания мы используем как эвристические методы до начала вычислений, так и окончательные проверки после выполнения работы, но непосредственно перед завершением встраивания. Если какой-либо из этих методов обнаруживает, что встраивание нецелесообразно (например, будет добавлено слишком много новых инструкций), то мы не встраиваем вызов метода.
Мы перенесли две проверки из категории «окончательные проверки» в категорию «эвристика», чтобы оценить, будет ли встраивание кода успешным или нет, прежде чем выполнять какие-либо ресурсоемкие вычисления. Поскольку это оценка, она не идеальна, но мы убедились, что наши новые эвристики охватывают 99,9% того, что встраивалось ранее, без влияния на производительность. Одна из этих новых эвристик касалась необходимого количества регистров DEX (улучшение примерно на 0,2-1,3%), а другая — количества инструкций (улучшение примерно на 2%).
У нас есть собственная реализация BitVector, которую мы используем в нескольких местах. Мы заменили класс BitVector с изменяемым размером на более простой класс BitVectorView для некоторых битовых векторов фиксированного размера. Это исключает некоторые косвенные обращения и проверки диапазона во время выполнения, а также ускоряет создание объектов битовых векторов.
Кроме того, класс BitVectorView был шаблонизирован на основе базового типа хранения (вместо того, чтобы всегда использовать uint32_t, как старый BitVector). Это позволяет некоторым операциям, например Union(), обрабатывать вдвое больше битов одновременно на 64-битных платформах. Количество примеров затронутых функций было уменьшено более чем на 1% в общей сложности при компиляции ОС Android. Это было сделано в рамках нескольких изменений [ 1 , 2 , 3 , 4 , 5 , 6 ].
Если бы мы подробно рассказывали обо всех оптимизациях, мы бы провели здесь весь день! Если вас интересуют другие оптимизации, взгляните на некоторые другие изменения, которые мы внедрили:
- Добавление учета позволит сократить время компиляции примерно на 0,6-1,6%.
- По возможности , выполняйте вычисления с отложенным выполнением , чтобы избежать циклов.
- Переработайте наш код таким образом, чтобы он пропускал предварительные вычисления, когда они не будут использоваться.
- Избегайте использования зависимых цепочек поставок, если распределитель нагрузки может быть легко получен из других источников.
- Ещё один пример добавления проверки для избежания ненужной работы .
- Избегайте частого ветвления по типу регистра (ядро/FP) в распределителе регистров.
- Убедитесь, что некоторые массивы инициализируются во время компиляции. Не полагайтесь на clang в этом вопросе.
- Уберите лишние циклы . Используйте циклы с диапазонами, которые clang может оптимизировать лучше, поскольку ему не нужно перезагружать внутренние указатели контейнера из-за побочных эффектов циклов. Избегайте вызова виртуальной функции `HInstruction::GetInputRecords()` в цикле через встроенный `InputAt(.)` для каждого ввода.
- Избегайте использования функций Accept() в шаблоне проектирования «посетитель», воспользовавшись оптимизацией компилятора.
Заключение
Наша работа над повышением скорости компиляции ART принесла значительные результаты, сделав Android более плавным и эффективным, а также улучшив время автономной работы и теплоотвод устройства. Тщательно выявляя и внедряя оптимизации, мы продемонстрировали, что существенное повышение скорости компиляции возможно без ущерба для использования памяти или качества кода.
Наш путь включал в себя профилирование с помощью таких инструментов, как pprof, готовность к итеративным разработкам и, порой, отказ от менее перспективных направлений. Совместные усилия команды ART не только значительно сократили время компиляции, но и заложили основу для будущих усовершенствований.
Все эти улучшения будут доступны в итоговом обновлении Android 2025 года, а для Android 12 и выше — через основные обновления. Мы надеемся, что этот подробный анализ нашего процесса оптимизации даст ценное представление о сложностях и преимуществах разработки компиляторов!
Автор:
Продолжить чтение


Новости о продуктах
Мы рады сообщить, что в Android XR появилась официальная поддержка Unreal Engine и Godot. Также мы запускаем новые инструменты, призванные повысить вашу производительность и расширить возможности XR: Android XR Engine Hub и Android XR Interaction Framework.
Luke Hopkins • 4 мин чтения


Новости о продуктах
С выходом Android 17 мы переходим к адаптивному стандарту разработки. Ваши пользователи больше не зависят от одного форм-фактора; они переключаются между телефонами, складными устройствами, планшетами, ноутбуками, автомобильными дисплеями и иммерсивными средами XR в течение всего дня.
Fahd Imtiaz • 4 мин чтения


Новости о продуктах
Мы рады представить вам функции Google TV и инструменты для разработчиков, призванные повысить доступность вашего контента и подготовить ваше приложение к будущим телевизионным приложениям.
Paul Lammertsma • 4 мин чтения
Будьте в курсе событий
Получайте еженедельно самые свежие новости о разработке Android прямо на свою электронную почту.
