
Инструмент Profile GPU Rendering указывает относительное время, которое требуется каждому этапу конвейера рендеринга для рендеринга предыдущего кадра. Эти знания могут помочь вам выявить узкие места в конвейере, чтобы вы знали, что оптимизировать, чтобы улучшить производительность рендеринга вашего приложения.
На этой странице кратко объясняется, что происходит на каждом этапе конвейера, и обсуждаются проблемы, которые могут вызвать узкие места на этом этапе. Прежде чем читать эту страницу, вы должны ознакомиться с информацией, представленной в разделе «Профиль рендеринга с помощью графического процессора» . Кроме того, чтобы понять, как все этапы сочетаются друг с другом, может оказаться полезным рассмотреть , как работает конвейер рендеринга.
Визуальное представление
Инструмент Profile GPU Rendering отображает этапы и их относительное время в виде графика: гистограммы с цветовой кодировкой. На рис. 1 показан пример такого дисплея.
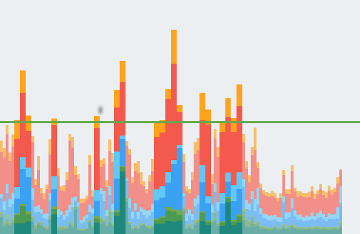
Рис. 1. График рендеринга профиля на графическом процессоре
Каждый сегмент каждой вертикальной полосы, отображаемой на графике рендеринга профиля с использованием графического процессора, представляет этап конвейера и выделяется на гистограмме определенным цветом. На рис. 2 показан ключ к значению каждого отображаемого цвета.

Рис. 2. Легенда графика рендеринга профиля с помощью графического процессора
Как только вы поймете, что означает каждый цвет, вы сможете нацелиться на определенные аспекты вашего приложения, чтобы попытаться оптимизировать производительность его рендеринга.
Этапы и их значения
В этом разделе объясняется, что происходит на каждом этапе, соответствующем цвету на рисунке 2, а также причины узких мест, на которые следует обратить внимание.
Обработка ввода
Этап обработки ввода в конвейере измеряет, сколько времени приложение потратило на обработку входных событий. Эта метрика показывает, сколько времени приложение потратило на выполнение кода, вызванного в результате обратных вызовов событий ввода.
Когда этот сегмент большой
Высокие значения в этой области обычно являются результатом слишком большого объема или слишком сложной работы, выполняемой внутри обратных вызовов событий обработчика ввода. Поскольку эти обратные вызовы всегда происходят в основном потоке, решения этой проблемы сосредоточены на непосредственной оптимизации работы или перегрузке ее в другой поток.
Также стоит отметить, что на этом этапе может появиться прокрутка RecyclerView . RecyclerView прокручивает немедленно, когда обрабатывает событие касания. В результате он может увеличивать или заполнять новые представления элементов. По этой причине важно выполнить эту операцию как можно быстрее. Инструменты профилирования, такие как Traceview или Systrace, могут помочь вам в дальнейшем расследовании.
Анимация
Фаза анимации показывает, сколько времени потребовалось для оценки всех аниматоров, работавших в этом кадре. Наиболее распространенными аниматорами являются ObjectAnimator , ViewPropertyAnimator и Transitions .
Когда этот сегмент большой
Высокие значения в этой области обычно являются результатом работы, выполняемой из-за некоторого изменения свойств анимации. Например, анимация перемещения, которая прокручивает ваш ListView или RecyclerView , вызывает большое увеличение количества представлений и численности населения.
Измерение/расположение
Чтобы Android мог отображать элементы вашего представления на экране, он выполняет две конкретные операции над макетами и представлениями в вашей иерархии представлений.
Сначала система измеряет элементы просмотра. Каждое представление и макет имеют определенные данные, описывающие размер объекта на экране. Некоторые представления могут иметь определенный размер; другие имеют размер, который адаптируется к размеру родительского контейнера макета.
Во-вторых, система размещает элементы просмотра. После того как система рассчитает размеры дочерних представлений, она может приступить к компоновке, изменению размера и расположению представлений на экране.
Система выполняет измерение и компоновку не только для рисуемых видов, но и для родительских иерархий этих видов, вплоть до корневого вида.
Когда этот сегмент большой
Если ваше приложение тратит много времени на каждый кадр в этой области, это обычно происходит либо из-за огромного количества просмотров, которые необходимо разместить, либо из-за таких проблем, как двойное налогообложение в неправильном месте в вашей иерархии. В любом из этих случаев решение проблемы производительности предполагает улучшение производительности иерархий представлений .
Код, добавленный вами в onLayout(boolean, int, int, int, int) или onMeasure(int, int) также может вызывать проблемы с производительностью. Traceview и Systrace помогут вам изучить стеки вызовов и выявить проблемы, которые могут возникнуть в вашем коде.
Рисовать
На этапе рисования операции рендеринга представления, такие как рисование фона или рисование текста, преобразуются в последовательность собственных команд рисования. Система записывает эти команды в список отображения.
Полоса рисования записывает, сколько времени требуется для завершения ввода команд в список отображения для всех представлений, которые необходимо обновить на экране в этом кадре. Измеренное время применяется к любому коду, который вы добавили к объектам пользовательского интерфейса в своем приложении. Примерами такого кода могут быть onDraw() , dispatchDraw() и различные draw ()methods принадлежащие подклассам класса Drawable .
Когда этот сегмент большой
Проще говоря, вы можете понимать эту метрику как показывающую, сколько времени потребовалось для выполнения всех вызовов onDraw() для каждого недействительного представления. Это измерение включает в себя любое время, потраченное на отправку команд отрисовки дочерним элементам и объектам рисования, которые могут присутствовать. По этой причине, когда вы видите этот всплеск шкалы, причиной может быть то, что несколько просмотров внезапно стали недействительными. Инвалидация приводит к необходимости повторного создания списков отображения представлений. Альтернативно, длительное время может быть результатом нескольких пользовательских представлений, которые имеют чрезвычайно сложную логику в методах onDraw() .
Синхронизировать/загрузить
Метрика синхронизации и загрузки представляет собой время, необходимое для передачи растровых объектов из памяти ЦП в память графического процессора в течение текущего кадра.
Поскольку процессоры разные, ЦП и ГП имеют разные области оперативной памяти, предназначенные для обработки. Когда вы рисуете растровое изображение на Android, система передает его в память графического процессора, прежде чем графический процессор сможет отобразить его на экране. Затем графический процессор кэширует растровое изображение, поэтому системе не нужно повторно передавать данные, если только текстура не будет удалена из кэша текстур графического процессора.
Примечание. На устройствах Lollipop этот этап отображается фиолетовым цветом.
Когда этот сегмент большой
Все ресурсы кадра должны находиться в памяти графического процессора, прежде чем их можно будет использовать для рисования кадра. Это означает, что высокое значение этого показателя может означать либо большое количество загрузок небольших ресурсов, либо небольшое количество очень больших ресурсов. Распространенным случаем является ситуация, когда приложение отображает одно растровое изображение, размер которого близок к размеру экрана. Другой случай — когда приложение отображает большое количество миниатюр.
Чтобы уменьшить эту полосу, вы можете использовать такие методы, как:
- Убедитесь, что разрешение растровых изображений не намного превышает размер, в котором они будут отображаться. Например, вашему приложению следует избегать отображения изображения 1024x1024 как изображения 48x48.
- Воспользовавшись преимуществом
prepareToDraw()для асинхронной предварительной загрузки растрового изображения перед следующей фазой синхронизации.
Выдавать команды
Сегмент «Выпуск команд» представляет время, необходимое для выдачи всех команд, необходимых для вывода списков отображения на экран.
Чтобы система могла отображать списки отображения на экране, она отправляет необходимые команды на графический процессор. Обычно это действие выполняется через API OpenGL ES .
Этот процесс занимает некоторое время, поскольку система выполняет окончательное преобразование и обрезку для каждой команды перед отправкой команды в графический процессор. Дополнительные издержки возникают на стороне графического процессора, который вычисляет окончательные команды. Эти команды включают окончательные преобразования и дополнительную обрезку.
Когда этот сегмент большой
Время, затраченное на этом этапе, является прямым показателем сложности и количества списков отображения, которые система отображает в данном кадре. Например, наличие большого количества операций рисования, особенно в тех случаях, когда каждый примитив рисования имеет небольшую стоимость, может привести к увеличению этого времени. Например:
Котлин
for (i in 0 until 1000) { canvas.drawPoint() }
Ява
for (int i = 0; i < 1000; i++) { canvas.drawPoint() }
выпуск намного дороже, чем:
Котлин
canvas.drawPoints(thousandPointArray)
Ява
canvas.drawPoints(thousandPointArray);
Между выдачей команд и фактическим составлением списков отображения не всегда существует корреляция 1:1. В отличие от Issue Commands , который фиксирует время, необходимое для отправки команд рисования на графический процессор, метрика Draw представляет время, необходимое для фиксации выданных команд в списке отображения.
Эта разница возникает потому, что списки отображения кэшируются системой везде, где это возможно. В результате возникают ситуации, когда прокрутка, преобразование или анимация требуют от системы повторной отправки списка отображения, но не фактического его перестроения (повторного захвата команд рисования) с нуля. В результате вы можете видеть высокую панель «Выдать команды», не видя высокой панели команд рисования .
Буферы обработки/замены
Как только Android завершает отправку всего своего списка отображения в графический процессор, система выдает последнюю команду, чтобы сообщить графическому драйверу, что с текущим кадром все готово. На этом этапе драйвер наконец может представить обновленное изображение на экране.
Когда этот сегмент большой
Важно понимать, что графический процессор выполняет работу параллельно с центральным процессором. Система Android выдает команды рисования графическому процессору, а затем переходит к следующей задаче. Графический процессор считывает эти команды рисования из очереди и обрабатывает их.
В ситуациях, когда ЦП выдает команды быстрее, чем графический процессор их обрабатывает, очередь связи между процессорами может переполниться. Когда это происходит, ЦП блокируется и ждет, пока в очереди не появится место для размещения следующей команды. Состояние полной очереди часто возникает на этапе замены буферов , поскольку на этом этапе было отправлено количество команд на целый кадр.
Ключом к смягчению этой проблемы является снижение сложности работы, выполняемой на графическом процессоре, аналогично тому, что вы делали бы на этапе «Выдача команд».
Разнообразный
Помимо времени, которое требуется системе рендеринга на выполнение своей работы, существует дополнительный набор работ, который происходит в основном потоке и не имеет ничего общего с рендерингом. Время, затраченное на эту работу, указывается как «разное время» . Разное время обычно представляет собой работу, которая может происходить в потоке пользовательского интерфейса между двумя последовательными кадрами рендеринга.
Когда этот сегмент большой
Если это значение велико, вполне вероятно, что в вашем приложении есть обратные вызовы, намерения или другая работа, которая должна выполняться в другом потоке. Такие инструменты, как трассировка методов или Systrace, могут обеспечить видимость задач, выполняющихся в основном потоке. Эта информация может помочь вам улучшить производительность.