
Questo documento ti aiuta a identificare e risolvere i principali problemi di prestazioni della tua app.
Principali problemi di prestazioni
Esistono molti problemi che possono contribuire a prestazioni scadenti in un'app, ma di seguito sono riportati alcuni problemi comuni da cercare:
- Latenza di avvio
La latenza di avvio è il tempo che intercorre tra il tocco dell'icona dell'app, della notifica o di un altro punto di accesso e la visualizzazione dei dati dell'utente sullo schermo.
Punta ai seguenti obiettivi di avvio nelle tue app:
- Avvio a freddo in meno di 500 ms. Un avvio a freddo si verifica quando l'app in fase di avvio non è presente nella memoria del sistema. Ciò si verifica quando l'app viene avviata per la prima volta dopo il riavvio o dopo che il processo dell'app è stato interrotto dall'utente o dal sistema. Un avvio a freddo richiede il massimo impegno da parte del sistema, in quanto deve caricare tutto dallo spazio di archiviazione e inizializzare l'app. Cerca di fare in modo che gli avvii a freddo richiedano 500 ms o meno.
- Avvio tiepido in meno di 200 ms e avvio a caldo in meno di 150 ms. Un avvio a caldo si verifica quando il processo dell'applicazione è già in esecuzione in background, ma il sistema deve reinizializzare la UI o riportare l'attività in primo piano, ad esempio quando un utente esce dall'app e la riapre poco dopo. Un avvio a caldo è ancora più veloce perché l'attività dell'app è già memorizzata nella cache e deve solo essere portata in primo piano, senza la necessità di ricreare la gerarchia di oggetti View. Cerca di mantenere gli avvii a caldo sotto i 200 ms e gli avvii a freddo sotto i 150 ms.
- Latenze P95 e P99 molto vicine alla latenza mediana. P95 e P99 rappresentano il 95° e il 99° percentile dei tempi di avvio, mentre la mediana è il 50° percentile. Quando l'app impiega molto tempo ad avviarsi, l'esperienza utente è scadente. Le comunicazioni interprocesso (IPC) e I/O non necessari durante il percorso critico di avvio dell'app possono causare contese di blocco e introdurre incoerenze.
- Scorrimento a scatti
Jank è il termine che descrive il problema visivo che si verifica quando il sistema non è in grado di creare e fornire i frame in tempo per disegnarli sullo schermo alla cadenza richiesta di 60 Hz o superiore. Il jank è più evidente durante lo scorrimento, quando invece di un flusso animato fluido, si verificano dei problemi. Il jank si verifica quando il movimento si interrompe lungo il percorso per uno o più frame, poiché l'app impiega più tempo a eseguire il rendering dei contenuti rispetto alla durata di un frame sul sistema.
Imposta come target frequenze di aggiornamento a 90 Hz nelle tue app. Le frequenze di rendering convenzionali sono 60 Hz, ma molti dispositivi più recenti funzionano in modalità 90 Hz durante le interazioni dell'utente, come lo scorrimento. Alcuni dispositivi supportano frequenze ancora più elevate, fino a 120 Hz.
Per vedere la frequenza di aggiornamento utilizzata da un dispositivo in un determinato momento, attiva una sovrapposizione utilizzando Opzioni sviluppatore > Mostra frequenza di aggiornamento nella sezione Debug.
- Transizioni non fluide
Ciò è evidente durante le interazioni come il passaggio da una scheda all'altra o il caricamento di una nuova attività. Questi tipi di transizioni devono essere animazioni fluide e non includere ritardi o sfarfallii visivi.
- Inefficienze energetiche
L'esecuzione di attività riduce la carica della batteria e, in definitiva, la durata della batteria.
Le allocazioni di memoria, che derivano dalla creazione di nuovi oggetti nel codice, causano lavoro nel sistema. Non solo le allocazioni stesse richiedono uno sforzo da parte di Android Runtime (ART), ma anche la liberazione successiva di questi oggetti (garbage collection) richiede tempo e impegno.
Sia l'allocazione della memoria che la garbage collection sono diventate molto più veloci ed efficienti, soprattutto per gli oggetti temporanei. Sebbene in passato fosse una best practice evitare di allocare oggetti ogni volta che era possibile, ti consigliamo di fare ciò che è più sensato per la tua app e la tua architettura. Risparmiare sulle allocazioni a rischio di codice non gestibile non è la best practice, considerando le funzionalità di ART.
Tuttavia, le allocazioni richiedono impegno, quindi tieni presente che possono contribuire a problemi di prestazioni se allochi molti oggetti nel ciclo interno.
Identificare i problemi
Per risolvere i problemi di prestazioni, identifica e ispeziona i seguenti percorsi utente critici:
- Flussi di avvio comuni, inclusi quelli da avvio app e notifica.
- Schermate in cui l'utente scorre i dati.
- Transizioni tra le schermate.
- Flussi di lunga durata, come la navigazione o la riproduzione di musica.
Per ciascuno di questi flussi, esamina cosa sta succedendo utilizzando i seguenti strumenti di debug:
- Perfetto: ti consente di vedere cosa sta succedendo sull'intero dispositivo con dati di temporizzazione precisi.
- Profiler di memoria: ti consente di vedere quali allocazioni di memoria vengono eseguite nell'heap.
- Simpleperf: mostra un grafico a fiamme delle chiamate di funzione che utilizzano la maggior parte della CPU durante un determinato periodo di tempo. Quando identifichi qualcosa che richiede molto tempo in Systrace, ma non sai perché, Simpleperf può fornire informazioni aggiuntive.
Per comprendere ed eseguire il debug di questi problemi di prestazioni, è fondamentale eseguire manualmente il debug delle singole esecuzioni di test. Non puoi sostituire i passaggi precedenti analizzando i dati aggregati. Tuttavia, per capire cosa vedono effettivamente gli utenti e identificare quando potrebbero verificarsi regressioni, è importante configurare la raccolta delle metriche nei test automatizzati e sul campo:
- Flussi di avvio
- Metriche di campo: tempo di avvio di Play Console
- Test di laboratorio: test di avvio con Macrobenchmark
- Jank
- Metriche sul campo
- Android vitals in Play Console: in Play Console non puoi restringere le metriche a un percorso utente specifico. Riporta solo il jank complessivo nell'app.
- Misurazione personalizzata con
FrameMetricsAggregator: puoi utilizzareFrameMetricsAggregatorper registrare le metriche di jank durante un particolare flusso di lavoro.
- Test di laboratorio
- Scorrimento con Macrobenchmark.
- Macrobenchmark raccoglie i tempi dei frame utilizzando i comandi
dumpsys gfxinfoche racchiudono un singolo percorso utente. Questo è un modo per comprendere la variazione di jank in un percorso utente specifico. Le metricheRenderTime, che evidenziano il tempo necessario per disegnare i frame, sono più importanti del conteggio dei frame con problemi per identificare regressioni o miglioramenti.
- Metriche sul campo
Problemi di verifica dei link dell'app
I link alle app sono link diretti basati sull'URL del tuo sito web di cui è stata verificata la proprietà. Le verifiche degli app link possono non riuscire per i seguenti motivi:
- Ambiti dei filtri per intent errati:aggiungi
autoVerifyai filtri per intent solo per gli URL a cui la tua app può rispondere. - Passaggi di protocollo non verificati:i reindirizzamenti lato server e dei sottodomini non verificati sono considerati rischi per la sicurezza e non superano la verifica. Causano
l'errore di tutti i link
autoVerify. Ad esempio, il reindirizzamento dei link da HTTP a HTTPS, come da example.com a www.example.com, senza verificare i link HTTPS può causare un errore di verifica. Assicurati di verificare i link per app aggiungendo filtri per intent. - Link non verificabili:l'aggiunta di link non verificabili a scopo di test può impedire al sistema di verificare gli app link per la tua app.
- Server inaffidabili:assicurati che i server possano connettersi alle app client.
Configurare l'app per l'analisi del rendimento
È essenziale configurare correttamente i test per ottenere benchmark accurati, ripetibili e utilizzabili da un'app. Esegui i test su un sistema il più vicino possibile alla produzione, eliminando le fonti di rumore. Le sezioni seguenti mostrano una serie di passaggi specifici per APK e sistema che puoi eseguire per preparare una configurazione di test, alcuni dei quali sono specifici per il caso d'uso.
Tracepoint
Le app possono instrumentare il proprio codice con eventi di traccia personalizzati.
Durante l'acquisizione delle tracce, la tracciatura comporta un piccolo sovraccarico di circa 5 μs per sezione, quindi non inserirla in ogni metodo. La traccia di blocchi di lavoro più grandi, >0,1 ms, può fornire informazioni significative sui colli di bottiglia.
Considerazioni relative all'APK
Le varianti di debug possono essere utili per la risoluzione dei problemi e la simbolizzazione degli esempi di stack, ma hanno un impatto significativo sulle prestazioni. I dispositivi con Android 10 (livello API 29) e versioni successive possono utilizzare profileable android:shell="true" nel manifest per attivare la profilazione nelle build di rilascio.
Utilizza la configurazione di riduzione del codice di livello di produzione. A seconda delle risorse utilizzate dall'app, questo può avere un impatto significativo sulle prestazioni. Alcune configurazioni ProGuard rimuovono i punti di traccia, quindi valuta la possibilità di rimuovere queste regole per la configurazione su cui esegui i test.
Compilation
Compila la tua app sul dispositivo in uno stato noto, in genere speed per
semplicità o speed-profile per corrispondere più da vicino alle prestazioni di produzione
(anche se ciò richiede il riscaldamento dell'applicazione e lo scarico dei profili o
la compilazione dei profili di base dell'app).
Sia speed che speed-profile riducono la quantità di codice eseguito interpretato
da dex e, di conseguenza, la quantità di compilazione just-in-time (JIT)
in background, che può causare interferenze significative. Solo speed-profile
riduce l'impatto del caricamento delle classi di runtime da dex.
Il seguente comando compila l'applicazione utilizzando la modalità speed:
adb shell cmd package compile -m speed -f com.example.packagename
La modalità di compilazione speed compila completamente i metodi dell'app. La modalità
speed-profile compila i metodi e le classi dell'app in base a un
profilo dei percorsi di codice utilizzati, raccolto durante l'utilizzo dell'app. Può essere
difficile raccogliere i profili in modo coerente e corretto, quindi se decidi di
utilizzarli, verifica che raccolgano ciò che ti aspetti. I profili si trovano
nel seguente percorso:
/data/misc/profiles/ref/[package-name]/primary.prof
Considerazioni sul sistema
Per misurazioni di basso livello e ad alta fedeltà, calibra i tuoi dispositivi. Esegui confronti A/B sullo stesso dispositivo e sulla stessa versione del sistema operativo. Possono verificarsi variazioni significative nel rendimento, anche per lo stesso tipo di dispositivo.
Sui dispositivi con accesso root, valuta la possibilità di utilizzare uno script lockClocks per
Microbenchmark. Tra le altre cose, questi script eseguono le seguenti operazioni:
- Posiziona le CPU a una frequenza fissa.
- Disattiva i core piccoli e configura la GPU.
- Disattiva la limitazione termica.
Non è consigliabile utilizzare uno script lockClocks per i test incentrati sull'esperienza utente, come l'avvio dell'app, il test DoU e il test di jank, ma può essere essenziale per ridurre il rumore nei test Microbenchmark.
Se possibile, valuta l'utilizzo di un framework di test come Macrobenchmark, che può ridurre il rumore nelle misurazioni e prevenire l'imprecisione della misurazione.
Avvio dell'app lento: attività trampoline non necessaria
Un'attività di trampolino può estendere inutilmente il tempo di avvio dell'app ed è
importante esserne consapevoli se la tua app lo fa. Come mostrato nella seguente traccia di esempio, un activityStart è immediatamente seguito da un altro activityStart senza che vengano disegnati frame dalla prima attività.
 Figura 1. Una traccia che mostra l'attività sul tappeto elastico.
Figura 1. Una traccia che mostra l'attività sul tappeto elastico.
Questo può accadere sia in un punto di ingresso delle notifiche sia in un punto di ingresso di avvio regolare dell'app e spesso puoi risolvere il problema eseguendo il refactoring. Ad esempio, se utilizzi questa attività per eseguire la configurazione prima dell'esecuzione di un'altra attività, estrai questo codice in un componente o una libreria riutilizzabile.
Allocazioni non necessarie che attivano frequenti GC
Potresti notare che le garbage collection (GC) si verificano più frequentemente del previsto in una traccia Systrace.
Nell'esempio seguente, la garbage collection ogni 10 secondi durante un'operazione a lunga esecuzione indica che l'app potrebbe allocare memoria in modo non necessario ma costante nel tempo:
 Figura 2. Una traccia che mostra lo spazio tra gli eventi di Google Cloud.
Figura 2. Una traccia che mostra lo spazio tra gli eventi di Google Cloud.
Potresti anche notare in Memory Profiler che uno stack di chiamate specifico esegue la maggior parte delle allocazioni. Non è necessario eliminare tutte le allocazioni in modo aggressivo, in quanto ciò può rendere più difficile la manutenzione del codice. Inizia invece a lavorare sui punti critici delle allocazioni.
Frame scattosi
La pipeline grafica è relativamente complicata e può esserci qualche sfumatura nel determinare se un utente potrebbe alla fine vedere un frame eliminato. In alcuni casi, la piattaforma può "recuperare" un frame utilizzando il buffering. Tuttavia, puoi ignorare la maggior parte di queste sfumature per identificare i frame problematici dal punto di vista della tua app.
Quando i frame vengono disegnati con poco lavoro richiesto dall'app, i
Choreographer.doFrame() punti di traccia si verificano con una cadenza di 16,7 ms su un dispositivo
a 60 FPS:
 Figura 3. Una traccia che mostra i frame veloci frequenti.
Figura 3. Una traccia che mostra i frame veloci frequenti.
Se riduci lo zoom e navighi nella traccia, a volte vedi che i frame impiegano un po' più di tempo per essere completati, ma non più del tempo assegnato di 16,7 ms. Questi fotogrammi sono OK:
 Figura 4. Una traccia che mostra frame veloci frequenti con burst periodici di
lavoro.
Figura 4. Una traccia che mostra frame veloci frequenti con burst periodici di
lavoro.
Quando si verifica un'interruzione di questa cadenza regolare, si tratta di un frame instabile, come mostrato nelle figure 5 e 6:
 Figura 5. Una traccia che mostra un frame instabile.
Figura 5. Una traccia che mostra un frame instabile.
 Figura 6. Una traccia che mostra più frame con problemi.
Figura 6. Una traccia che mostra più frame con problemi.
In alcuni casi, devi ingrandire un punto di traccia per saperne di più su quali componenti dell'interfaccia utente vengono aggiornati da Compose o, come nella Figura 6, su cosa sta facendo un LazyColumn. Quando diagnostichi questi colli di bottiglia dell'interfaccia utente, la traccia standard del sistema potrebbe non mostrare quali composable sono la causa principale. In questi casi, utilizza la traccia della composizione di Jetpack Compose, che mostra le funzioni componibili esatte direttamente all'interno della traccia, semplificando l'individuazione di ricomposizioni impreviste. Le figure 5 e 6 mostrano i risultati della traccia della composizione.
Per ulteriori informazioni sull'ottimizzazione delle prestazioni di Compose, consulta Prestazioni di Jetpack Compose. Per ulteriori informazioni sull'identificazione dei frame scattosi e sul debug delle relative cause, consulta Rendering lento.
Errori comuni di layout pigro
L'invalidazione dell'intero stato di backing di un layout pigro senza necessità può comportare ricomposizioni eccessive, tempi di rendering dei frame lunghi e jank. Per ridurre al minimo il numero di elementi dell'elenco che devono essere aggiornati, utilizza le chiavi degli elementi per gli elementi e modifica solo gli elementi di stato specifici che cambiano.
Consulta la sezione Utilizzare le chiavi di layout pigro per scoprire come evitare costose riallocazioni dell'elenco completo, che causano l'aggiornamento dei contenuti anziché la loro sostituzione completa.
L'implementazione errata di elenchi a scorrimento nidificati può causare cali di rendimento. Evita di nidificare un layout pigro scorrevole all'interno di un altro container scorrevole senza vincoli espliciti. Per saperne di più, consulta la sezione Evitare di nidificare componenti scorrevoli nella stessa direzione.
Il precaricamento di dati insufficienti o non tempestivo può rendere difficile raggiungere la fine di un elenco scorrevole quando un utente deve attendere altri dati dal server. Anche se tecnicamente non si tratta di jank, in quanto non vengono mancati i termini per i frame, puoi migliorare significativamente l'esperienza utente modificando i tempi e la quantità di precaricamento in modo che l'utente non debba attendere i dati.
Debug dell'app
Di seguito sono riportati alcuni metodi per eseguire il debug del rendimento dell'app.
Eseguire il debug dell'avvio dell'app con Systrace
Per una panoramica della procedura di avvio dell'app, consulta Tempo di avvio dell'app. Per una panoramica della tracciatura del sistema e dell'utilizzo del profiler di Android Studio, guarda il seguente video.
Puoi disambiguare i tipi di startup nelle seguenti fasi:
- Avvio a freddo: inizia creando un nuovo processo senza stato salvato.
- Avvio tiepido: ricrea l'Activity riutilizzando il processo o ricrea il processo con lo stato salvato.
- Avvio a caldo: riavvia l'attività e inizia dall'inflazione.
Ti consigliamo di acquisire Systrace con l'app System Tracing sul dispositivo. Per Android 10 e versioni successive, utilizza Perfetto. Per Android 9 e versioni precedenti, utilizza Systrace. Ti consigliamo inoltre di visualizzare i file di traccia con il visualizzatore di tracce Perfetto basato sul web. Per saperne di più, consulta la panoramica della tracciatura del sistema.
Ecco alcuni aspetti da controllare:
- Monitor contention: la competizione per le risorse protette dal monitor può introdurre un ritardo significativo nell'avvio dell'app.
Transazioni del raccoglitore sincrone: cerca transazioni non necessarie nel percorso critico della tua app. Se una transazione necessaria è costosa, valuta la possibilità di collaborare con il team della piattaforma associato per apportare miglioramenti.
GC simultaneo: è comune e ha un impatto relativamente basso, ma se lo riscontri spesso, valuta di esaminarlo con il Profiler di memoria di Android Studio.
I/O: controlla l'I/O eseguito durante l'avvio e cerca eventuali blocchi prolungati.
Attività significativa su altri thread: questi possono interferire con il thread dell'interfaccia utente, quindi fai attenzione al lavoro in background durante l'avvio.
Ti consigliamo di chiamare reportFullyDrawn al termine dell'avvio dal punto di vista dell'app per migliorare i report sulle metriche di avvio dell'app. Per saperne di più sull'utilizzo di reportFullyDrawn, consulta la sezione Tempo
per la visualizzazione completa.
Puoi estrarre gli orari di inizio definiti da RFD tramite Perfetto Trace Processor
e viene generato un evento di traccia visibile all'utente.
Utilizzare System Tracing sul dispositivo
Puoi utilizzare l'app a livello di sistema chiamata System Tracing per acquisire una traccia di sistema su un dispositivo. Questa app ti consente di registrare le tracce dal dispositivo senza
doverlo collegare o connetterlo a adb.
Utilizzare Memory Profiler di Android Studio
Puoi utilizzare Android Studio Memory Profiler per esaminare la pressione della memoria che potrebbe essere causata da perdite di memoria o da pattern di utilizzo errati. Fornisce una visualizzazione in tempo reale delle allocazioni degli oggetti.
Puoi risolvere i problemi di memoria nella tua app utilizzando Memory Profiler per monitorare perché e con quale frequenza si verificano le operazioni di Garbage Collection.
Per profilare la memoria dell'app:
Rilevare problemi di memoria.
Registra una sessione di profilazione della memoria del percorso dell'utente su cui vuoi concentrarti. Cerca un conteggio degli oggetti in aumento, come mostrato nella Figura 7, che alla fine porta a GC, come mostrato nella Figura 8.
 Figura 7. Aumento del conteggio degli oggetti.
Figura 7. Aumento del conteggio degli oggetti. Figura 8. Raccolte di rifiuti.
Figura 8. Raccolte di rifiuti.Dopo aver identificato il percorso dell'utente che aggiunge pressione sulla memoria, analizza le cause principali della pressione sulla memoria.
Diagnosticare i punti critici della pressione della memoria.
Seleziona un intervallo nella sequenza temporale per visualizzare sia le Allocazioni sia le Dimensioni superficiali, come mostrato nella figura 9.
 Figura 9. Valori per Allocations e Shallow
Size.
Figura 9. Valori per Allocations e Shallow
Size.Esistono diversi modi per ordinare questi dati. Di seguito sono riportati alcuni esempi di come ogni visualizzazione può aiutarti ad analizzare i problemi.
Disponi per classe: utile quando vuoi trovare classi che generano oggetti che altrimenti vengono memorizzati nella cache o riutilizzati da un pool di memoria.
Ad esempio, se un'app crea 2000 oggetti di una determinata classe ogni secondo, aumenta il conteggio delle Allocazioni di 2000 ogni secondo e lo vedi quando ordini per classe. Se vuoi riutilizzare questi oggetti per evitare di generare spazzatura, implementa un pool di memoria.
Disponi per callstack: utile quando vuoi trovare un percorso critico in cui viene allocata la memoria, ad esempio all'interno di un ciclo o di una funzione specifica che esegue molte operazioni di allocazione.
Dimensioni superficiali: tiene traccia solo della memoria dell'oggetto stesso. È utile per monitorare classi semplici composte principalmente da valori primitivi.
Dimensioni mantenute: mostra la memoria totale dovuta all'oggetto stesso più eventuali riferimenti a cui fa riferimento solo l'oggetto. È utile per monitorare la pressione della memoria dovuta a oggetti complessi. Per ottenere questo valore, esegui un dump completo della memoria, come mostrato nella Figura 10. Dimensioni mantenute viene aggiunta come colonna, come mostrato nella Figura 11.
 Figura 10. Dump completo della memoria.
Figura 10. Dump completo della memoria.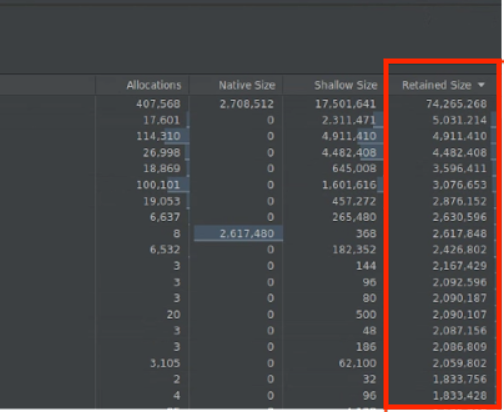
Figura 11. Colonna Dimensioni trattenute.
Misura l'impatto di un'ottimizzazione.
Le GC sono più evidenti ed è più facile misurare l'impatto delle ottimizzazioni in memoria. Quando un'ottimizzazione riduce la pressione della memoria, vedrai meno GC.
Per misurare l'impatto dell'ottimizzazione, nella sequenza temporale del profiler, misura il tempo tra le operazioni di Garbage Collection. Un impatto positivo si traduce in un intervallo di tempo più lungo tra le GC.
Gli impatti finali dei miglioramenti della memoria sono i seguenti:
- I riavvii per esaurimento della memoria sono probabilmente ridotti se l'app non subisce costantemente una saturazione della memoria.
- Un numero inferiore di GC migliora le metriche di jank, in particolare nel P99. Questo perché le GC causano contesa della CPU, il che può comportare il rinvio delle attività di rendering durante l'esecuzione della GC.
Consigliati per te
- Nota: il testo del link viene visualizzato quando JavaScript è disattivato
- Analisi e ottimizzazione dell'avvio dell'app {:#app-startup-analysis-optimization}
- Frame bloccati
- Scrivere un Macrobenchmark