
WorkManager allows you to create and enqueue a chain of work that specifies multiple dependent tasks and defines what order they should run in. This functionality is particularly useful when you need to run several tasks in a particular order.
To create a chain of work, you can use
WorkManager.beginWith(OneTimeWorkRequest)
or
WorkManager.beginWith(List<OneTimeWorkRequest>)
, which each return an instance of
WorkContinuation.
A WorkContinuation can then be used to add dependent OneTimeWorkRequest
instances using
then(OneTimeWorkRequest)
or
then(List<OneTimeWorkRequest>)
.
Every invocation of the WorkContinuation.then(...) returns a new instance of WorkContinuation. If you add a List of OneTimeWorkRequest instances, these requests can potentially run in parallel.
Finally, you can use the
WorkContinuation.enqueue()
method to enqueue() your chain of WorkContinuations.
Let's look at an example. In this example, 3 different Worker jobs are configured to run (potentially in parallel). The results of these Workers are then joined and passed on to a caching Worker job. Finally, the output of that job is passed into an upload Worker, which uploads the results to a remote server.
Kotlin
WorkManager.getInstance(myContext) // Candidates to run in parallel .beginWith(listOf(plantName1, plantName2, plantName3)) // Dependent work (only runs after all previous work in chain) .then(cache) .then(upload) // Call enqueue to kick things off .enqueue()
Java
WorkManager.getInstance(myContext) // Candidates to run in parallel .beginWith(Arrays.asList(plantName1, plantName2, plantName3)) // Dependent work (only runs after all previous work in chain) .then(cache) .then(upload) // Call enqueue to kick things off .enqueue();
Input Mergers
When you chain OneTimeWorkRequest instances, the output of parent work
requests is passed in as input to the children. So in the above example, the
outputs of plantName1, plantName2, and plantName3 would be passed in as
inputs to the cache request.
In order to manage inputs from multiple parent work requests, WorkManager uses
InputMerger.
There are two different types of InputMerger provided by WorkManager:
OverwritingInputMergerattempts to add all keys from all inputs to the output. In case of conflicts, it overwrites the previously-set keys.ArrayCreatingInputMergerattempts to merge the inputs, creating arrays when necessary.
If you have a more specific use case, then you can write your own by subclassing
InputMerger.
OverwritingInputMerger
OverwritingInputMerger is the default merger method. If there are key
conflicts in the merger, then the latest value for a key will overwrite any
previous versions in the resulting output data.
For example, if the plant inputs each have a key matching their respective
variable names ("plantName1", "plantName2", and "plantName3"), then the
data passed to the cache worker will have three key-value pairs.
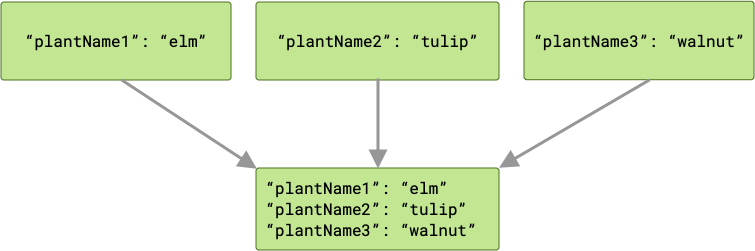
If there is a conflict, then the last worker to complete “wins”, and its value
is passed to cache.
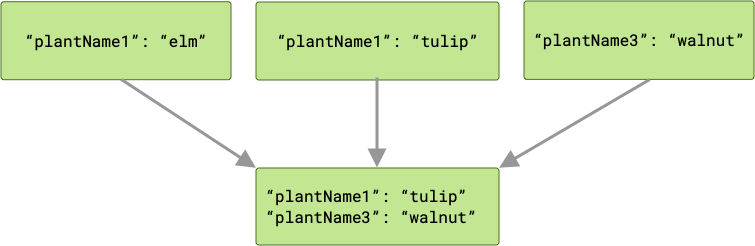
Because your work requests are run in parallel, you do not have guarantees for
the order in which it runs. In the example above, plantName1 could hold a
value of either "tulip" or "elm", depending on which value is written
last. If you have a chance of a key conflict and you need to preserve all output
data in a merger, then ArrayCreatingInputMerger may be a better option.
ArrayCreatingInputMerger
For the above example, given that we want to preserve the outputs from all plant
name Workers, we should use an ArrayCreatingInputMerger.
Kotlin
val cache: OneTimeWorkRequest = OneTimeWorkRequestBuilder<PlantWorker>() .setInputMerger(ArrayCreatingInputMerger::class) .setConstraints(constraints) .build()
Java
OneTimeWorkRequest cache = new OneTimeWorkRequest.Builder(PlantWorker.class) .setInputMerger(ArrayCreatingInputMerger.class) .setConstraints(constraints) .build();
ArrayCreatingInputMerger pairs each key with an array. If each of the keys
is unique, then your result is a series of one-element arrays.
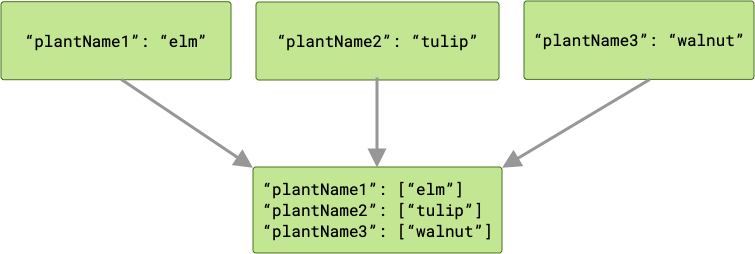
If there are any key collisions, then any corresponding values are grouped together in an array.
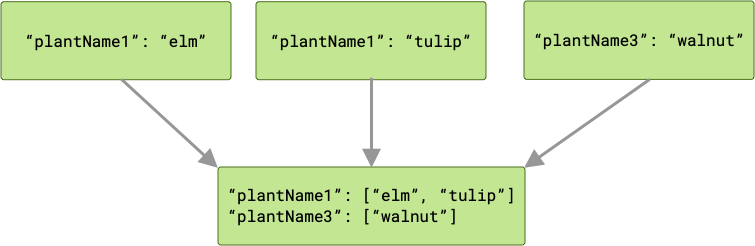
Chaining and Work Statuses
Chains of OneTimeWorkRequest execute sequentially as long as their work
completes successfully (that is, they return a Result.success()). Work
requests may fail or be cancelled while running, which has downstream effects on
dependent work requests.
When the first OneTimeWorkRequest is enqueued in a chain of work requests,
all subsequent work requests are blocked until the work of that first work
request is completed.
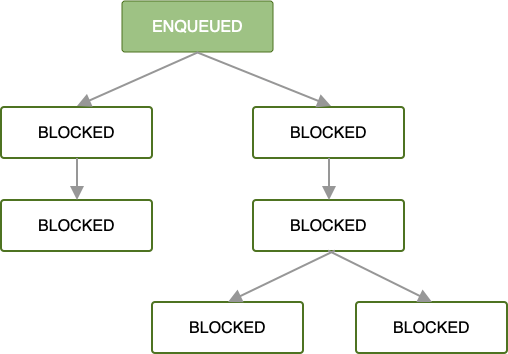
Once enqueued and all work constraints are satisfied, the first work request
begins running. If work is successfully completed in the root
OneTimeWorkRequest or List<OneTimeWorkRequest> (that is, it returns a
Result.success()), then the next set of dependent work requests will be
enqueued.
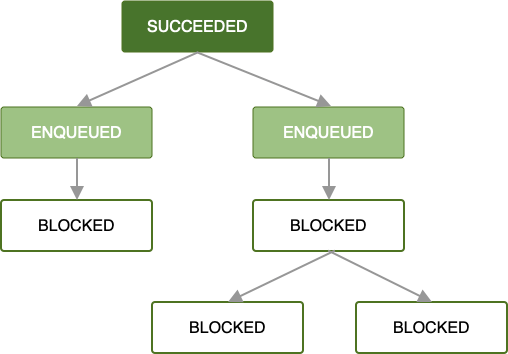
As long as each work request completes successfully, this same pattern propagates through the rest of your chain of work requests until all work in the chain is completed. While that is the simplest and often preferred case, error states are just as important to handle.
When an error occurs while a worker is processing your work request then you can retry that request according to a backoff policy you define. Retrying a request that is a part of a chain means that just that request will be retried with the input data provided to it. Any work running in parallel will be unaffected.
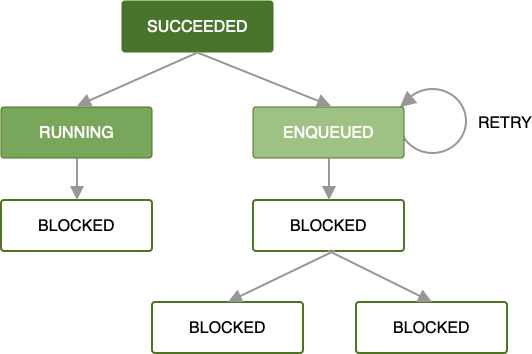
For more information on defining custom retry strategies, see Retry and Backoff Policy.
If that retry policy is undefined or exhausted, or you otherwise reach some
state in which a OneTimeWorkRequest returns Result.failure(), then that
work request and all dependent work requests are marked as FAILED.
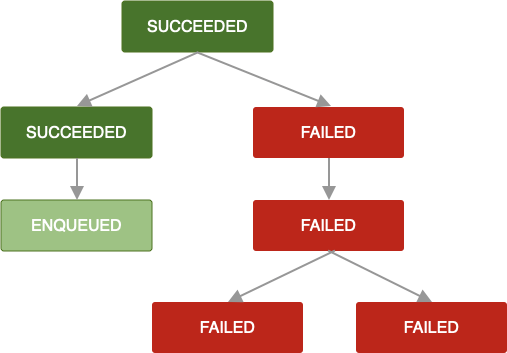
The same logic applies when a OneTimeWorkRequest is cancelled. Any dependent
work requests are also marked CANCELLED and their work will not be executed.
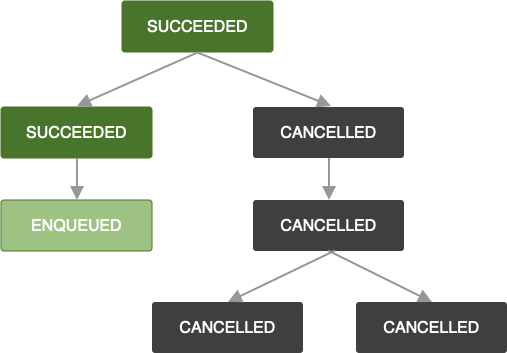
Note that if you were to append more work requests to a chain that has failed or
has cancelled work requests, then your newly appended work request will also be
marked FAILED or CANCELLED, respectively. If you want to extend the work
of an existing chain, see APPEND_OR_REPLACE in
ExistingWorkPolicy.
When creating chains of work requests, dependent work requests should define retry policies to ensure that work is always completed in a timely manner. Failed work requests could result in incomplete chains and/or unexpected state.
For more information, see Cancelling and Stopping Work.