
Automated testing helps you improve app quality in multiple ways. For example, it helps you perform validation, catching regressions, and verifying compatibility. A good testing strategy lets you take advantage of automated testing to focus on an important benefit: developer productivity.
Teams achieve higher levels of productivity when they use a systematic approach to testing paired with infrastructure enhancements. Doing so provides timely feedback on how the code behaves. A good testing strategy does the following:
- Catches issues as early as possible.
- Executes quickly.
- Provides clear indications when something needs to be fixed.
This page will help you decide what types of tests to implement, where to run them and how often.
The testing pyramid
You can categorize tests in modern applications by size. Small tests focus only on a small portion of code, making them fast and reliable. Big tests have a broad scope and require more complex setups that are difficult to maintain. However, big tests have more fidelity*, and they can discover a lot more issues in one go.
*Fidelity refers to the similarity of the test runtime environment to the production environment.
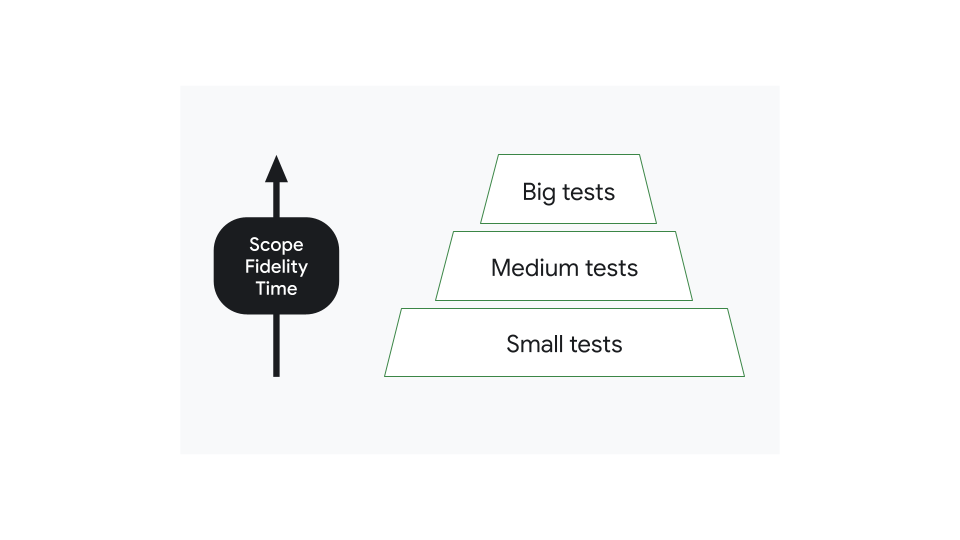
Most apps should have many small tests and relatively few big tests. The distribution of tests in each category should form a pyramid, with the more numerous small tests forming the base and the less numerous big tests forming the tip.
Minimize the cost of a bug
A good testing strategy maximizes developer productivity while minimizing the cost of finding bugs.
Consider an example of a possibly inefficient strategy. Here, the number of tests by size don't organize into a pyramid. There are too many big end-to-end tests and too few component UI tests:
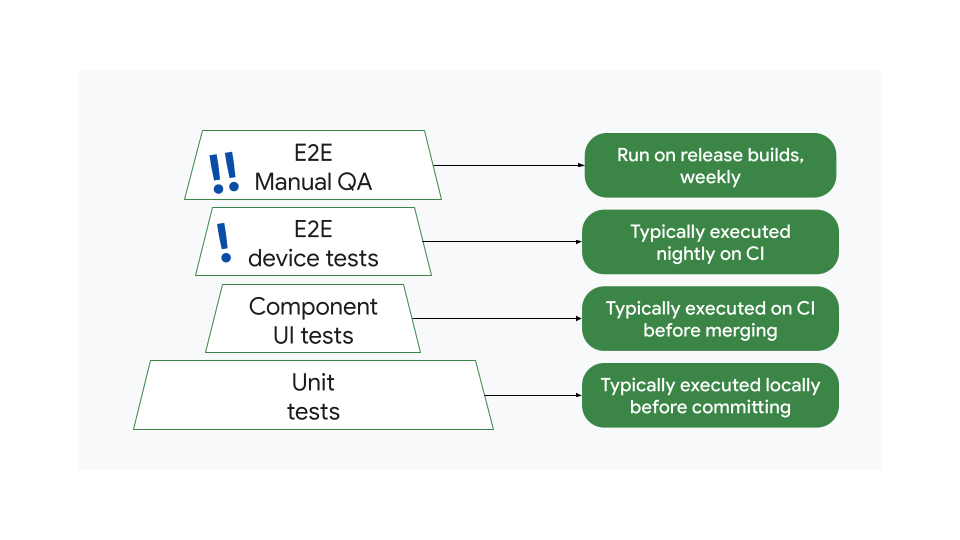
This means that too few tests are run before merging. If there is a bug, the tests might not catch it until the nightly or weekly end-to-end tests run.
It's important to consider the implications this has for the cost of identifying and fixing bugs and why it is important to bias your testing efforts towards smaller and more frequent tests:
- When the bug is caught by a unit test, it's typically fixed in minutes, so the cost is low.
- An end-to-end test could take days to discover the same bug. This could draw in multiple team members, reducing the overall productivity and potentially delaying a release. The cost of this bug is higher.
That said, an inefficient testing strategy is better than no strategy at all. When a bug makes it to production, the fix takes a long time to land in the user's devices, sometimes weeks, so the feedback loop is the longest and most expensive.
A scalable testing strategy
The testing pyramid has been traditionally split into 3 categories:
- Unit tests
- Integration tests
- End-to-end tests.
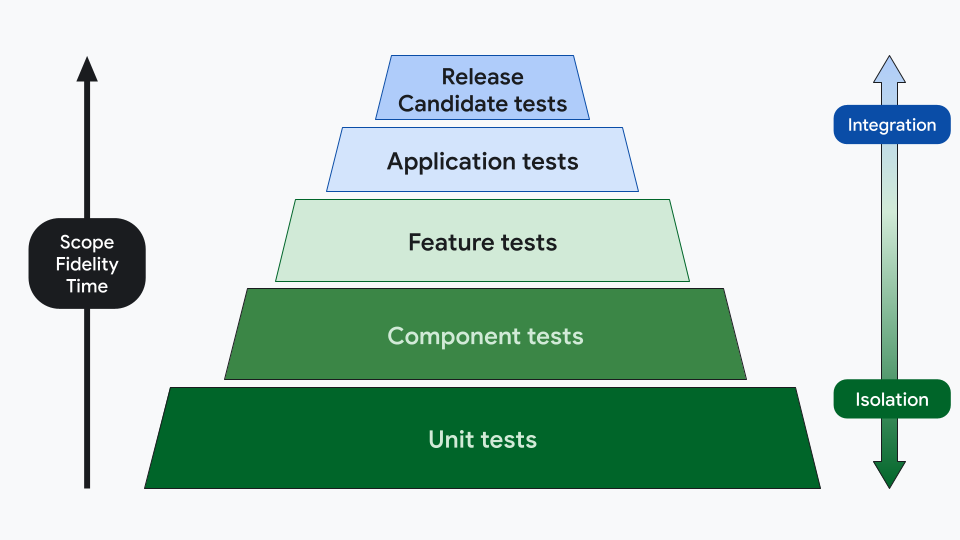
However, these concepts don't have precise definitions, so teams might want to define their categories differently, for example using 5 layers:
- A unit test is run on the host machine and verifies a single functional
unit of logic with no dependencies on the Android framework.
- Example: verifying off-by-one errors in a mathematical function.
- A component test verifies the functionality or appearance of a module or
component independently from other components in the system. Unlike unit
tests, the surface area of a component test extends to higher abstractions
above individual methods and classes.
- Example: Screenshot test for a custom button
- A feature test verifies the interaction of two or more independent
components or modules. Feature tests are larger and more complex, and
usually operate at the feature level.
- Example: UI behavior tests that verifies the state management in a screen
- An application test verifies the functionality of the entire application
in the form of a deployable binary. They are large integration tests that
use a debuggable binary, such as a dev build that can contain testing hooks,
as the system under test.
- Example: UI behavior test to verify configuration changes in a foldable, localization and accessibility tests
- A release candidate test verifies the functionality of a release build.
They are similar to application tests, except that the application binary is
minified and optimized. These are large end-to-end integration tests
that run in an environment as close to production as possible without
exposing the app to public user accounts or public backends.
- Example: Critical user journeys, performance testing
This categorization takes into account fidelity, time, scope and level of isolation. You can have different types of tests across multiple layers. For example, the Application test layer can contain behavior, screenshot and performance tests.
Scope |
Network access |
Execution |
Build type |
Lifecycle |
|
|---|---|---|---|---|---|
Unit |
Single method or class with minimal dependencies. |
No |
Local |
Debuggable |
Pre-merge |
Component |
Module or component level Multiple classes together |
No |
Local |
Debuggable |
Pre-merge |
Feature |
Feature level Integration with components owned by other teams |
Mocked |
Local |
Debuggable |
Pre-merge |
Application |
Application level Integration with features and/or services owned by other teams |
Mocked |
Emulator |
Debuggable |
Pre-merge |
Release Candidate |
Application level Integration with features and/or services owned by other teams |
Prod server |
Emulator |
Minified release build |
Post-merge |
Decide the test category
As a rule of thumb, you should consider the lowest layer of the pyramid that can give the team the right level of feedback.
For example, consider how to test the implementation of this feature: the UI of a sign-in flow. Depending on what you need to test you'll choose different categories:
Subject under test |
Description of what is being testing |
Test category |
Example type of test |
|---|---|---|---|
Form validator logic |
A class that validates the email address against a regular expression and checks that the password field was entered. It has no dependencies. |
Unit tests |
|
Sign-in form UI behavior |
A form with a button that is only enabled when the form has been validated |
Component tests |
UI behavior test running on Robolectric |
Sign-in form UI appearance |
A form following a UX specification |
Component tests |
|
Integration with the auth manager |
The UI that sends credentials to an auth manager and receives responses that can contain different errors. |
Feature tests |
|
Sign-in dialog |
A screen showing the sign-in form when the login button is pressed. |
Application tests |
UI behavior test running on Robolectric |
Critical user journey: Signing in |
A complete sign-in flow using a test account against a staging server |
Release Candidate |
End-to-end Compose UI behavior test running on device |
In some cases, whether something belongs to one category or another can be subjective. There can be additional reasons why a test is moved up or down, such as infrastructure cost, flakiness, and long test times.
Note that the test category doesn't dictate the type of test and not all features have to be tested in every category.
Manual testing can also be part of your test strategy. Typically, QA teams perform Release Candidate tests but they can also be involved in other stages. For example, exploratory testing for bugs in a feature without a script.
Test infrastructure
A testing strategy must be supported by infrastructure and tools to help developers continually run their tests and enforce rules that guarantee that all tests pass.
You can categorize tests by scope to define when and where to run which tests. For example, following the 5-layer model:
Category |
Environment (where) |
Trigger (when) |
|---|---|---|
Unit |
[Local][4] |
Every commit |
Component |
Local |
Every commit |
Feature |
Local and emulators |
Pre-merge, before merging or submitting a change |
Application |
Local, emulators, 1 phone, 1 foldable |
Post-merge, after merging or submitting a change |
Release Candidate |
8 different phones, 1 foldable, 1 tablet |
Pre-release |
- Unit and Component tests run on the Continuous Integration system for every new commit, but only for the affected modules.
- All Unit, Component and Feature tests run before merging or submitting a change.
- Application tests run post-merge.
- Release Candidate tests run nightly on a phone, foldable and tablet.
- Before a release, Release Candidate tests run on a large number of devices.
These rules can change over time when the number of tests affects productivity. For example, if you move tests to a nightly cadence, you might decrease CI build and test times, but you could also prolong the feedback loop.