


تیم Android Runtime (ART) زمان کامپایل را بدون به خطر انداختن کد کامپایل شده یا هرگونه پسرفت در حافظه اوج، 18٪ کاهش داده است. این بهبود بخشی از ابتکار عمل 2025 ما برای بهبود زمان کامپایل بدون قربانی کردن استفاده از حافظه یا کیفیت کد کامپایل شده بود.
بهینهسازی سرعت زمان کامپایل برای ART بسیار مهم است. به عنوان مثال، کامپایل کردن آن به صورت Just-in-time (JIT) مستقیماً بر کارایی برنامهها و عملکرد کلی دستگاه تأثیر میگذارد. کامپایلهای سریعتر، زمان قبل از شروع بهینهسازیها را کاهش میدهند و منجر به یک تجربه کاربری روانتر و پاسخگوتر میشوند. علاوه بر این، برای هر دو JIT و ahead-of-time (AOT)، بهبود در سرعت زمان کامپایل به کاهش مصرف منابع در طول فرآیند کامپایل منجر میشود و به نفع عمر باتری و کاهش دمای دستگاه، به ویژه در دستگاههای رده پایین، خواهد بود.
برخی از این بهبودهای سرعت زمان کامپایل در نسخه اندروید ژوئن ۲۰۲۵ راهاندازی شدند و بقیه در نسخه پایان سال اندروید در دسترس خواهند بود. علاوه بر این، همه کاربران اندروید در نسخههای ۱۲ و بالاتر واجد شرایط دریافت این بهبودها از طریق بهروزرسانیهای اصلی هستند.
بهینهسازی کامپایلر بهینهساز
بهینهسازی یک کامپایلر همیشه یک بازی بدهبستان است. شما نمیتوانید سرعت را رایگان به دست آورید؛ باید از چیزی صرف نظر کنید. ما یک هدف بسیار واضح و چالشبرانگیز برای خودمان تعیین کردهایم: کامپایلر را سریعتر کنیم، اما این کار را بدون ایجاد رگرسیون حافظه و از همه مهمتر، بدون کاهش کیفیت کدی که تولید میکند، انجام دهیم. اگر کامپایلر سریعتر باشد اما برنامهها کندتر اجرا شوند، ما شکست خوردهایم.
تنها منبعی که حاضر بودیم صرف کنیم، زمان توسعه خودمان برای کاوش عمیق، تحقیق و یافتن راهحلهای هوشمندانهای بود که با این معیارهای سختگیرانه مطابقت داشته باشند. بیایید نگاهی دقیقتر به نحوهی کارمان برای یافتن حوزههای قابل بهبود و همچنین یافتن راهحلهای مناسب برای مشکلات مختلف بیندازیم.
یافتن بهینهسازیهای ارزشمند و ممکن
قبل از اینکه بتوانید بهینهسازی یک معیار را شروع کنید، باید بتوانید آن را اندازهگیری کنید. در غیر این صورت، هرگز نمیتوانید مطمئن باشید که آن را بهبود بخشیدهاید یا خیر. خوشبختانه برای ما، سرعت زمان کامپایل نسبتاً ثابت است، تا زمانی که برخی اقدامات احتیاطی مانند استفاده از همان دستگاهی که برای اندازهگیری قبل و بعد از تغییر استفاده میکنید و مطمئن شوید که دستگاه خود را با فشار حرارتی تنظیم نمیکنید، را انجام دهید. علاوه بر این، ما همچنین اندازهگیریهای قطعی مانند آمار کامپایلر داریم که به ما کمک میکند بفهمیم در پشت صحنه چه میگذرد.
از آنجایی که منبعی که برای این پیشرفتها فدا میکردیم، زمان توسعه ما بود، میخواستیم بتوانیم هر چه سریعتر این کار را تکرار کنیم. این به این معنی بود که ما تعداد انگشتشماری از برنامههای نمونه (ترکیبی از برنامههای شخص ثالث، برنامههای شخص ثالث و خود سیستم عامل اندروید) را برای نمونهسازی راهحلها انتخاب کردیم. بعداً، با آزمایش دستی و خودکار به صورت گسترده، تأیید کردیم که پیادهسازی نهایی ارزشش را دارد.
با آن مجموعه از apk های دستچین شده، ما یک کامپایل دستی را به صورت محلی آغاز میکنیم، نمایهای از کامپایل را دریافت میکنیم و از pprof برای تجسم اینکه زمان خود را کجا صرف میکنیم، استفاده میکنیم.
نمونهای از نمودار شعلهای یک پروفایل در pprof
ابزار pprof بسیار قدرتمند است و به ما امکان میدهد دادهها را برش، فیلتر و مرتب کنیم تا ببینیم، برای مثال، کدام مراحل یا متدهای کامپایلر بیشترین زمان را صرف میکنند. ما وارد جزئیات خود pprof نمیشویم؛ فقط بدانید که اگر نوار بزرگتر باشد، به این معنی است که زمان کامپایل بیشتری صرف شده است.
یکی از این دیدگاهها، دیدگاه «پایین به بالا» است که در آن میتوانید ببینید کدام متدها بیشترین زمان را صرف میکنند. در تصویر زیر میتوانیم روشی به نام Kill را ببینیم که بیش از ۱٪ از زمان کامپایل را به خود اختصاص میدهد. برخی از روشهای برتر دیگر نیز بعداً در پست وبلاگ مورد بحث قرار خواهند گرفت.
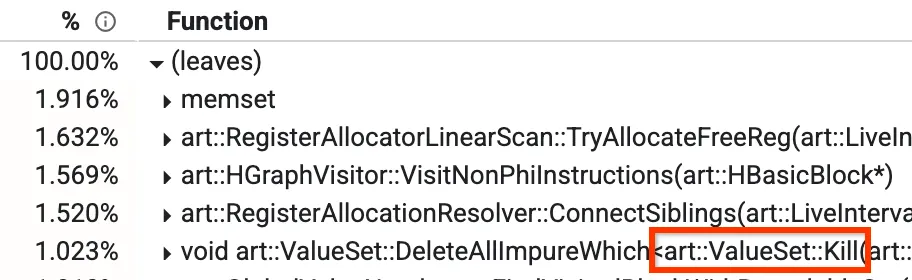
نمای پایین به بالای یک پروفایل
در کامپایلر بهینهسازی ما، مرحلهای به نام شمارهگذاری مقادیر سراسری (GVN) وجود دارد. لازم نیست نگران عملکرد کلی آن باشید، اما بخش مربوط به آن این است که بدانید متدی به نام `Kill` دارد که برخی از گرهها را طبق یک فیلتر حذف میکند. این کار زمانبر است زیرا باید روی تمام گرهها تکرار شود و یکی یکی بررسی شود. متوجه شدیم که مواردی وجود دارد که از قبل میدانیم بررسی نادرست خواهد بود، صرف نظر از گرههایی که در آن نقطه فعال هستند. در این موارد، میتوانیم کلاً از تکرار صرف نظر کنیم و آن را از ۱.۰۲۳٪ به حدود ۰.۳٪ کاهش دهیم و زمان اجرای GVN را حدود ۱۵٪ بهبود بخشیم.
پیادهسازی بهینهسازیهای ارزشمند
ما نحوه اندازهگیری و تشخیص محل صرف زمان را بررسی کردیم، اما این تنها آغاز کار است. مرحله بعدی نحوه بهینهسازی زمان صرف شده برای کامپایل است.
معمولاً در موردی مانند مورد «کشتن» که در بالا ذکر شد، به نحوه تکرار گرهها نگاهی میاندازیم و مثلاً با انجام کارها به صورت موازی یا بهبود خود الگوریتم، آن را سریعتر انجام میدهیم. در واقع، این کاری بود که در ابتدا امتحان کردیم و تنها زمانی که نتوانستیم کاری برای انجام دادن پیدا کنیم، لحظهای «یک دقیقه صبر کن...» داشتیم و دیدیم که راه حل این است که (در برخی موارد) اصلاً تکرار نکنیم! هنگام انجام این نوع بهینهسازیها، به راحتی میتوان جنگل را به خاطر درختان از دست داد.
در موارد دیگر، ما از تکنیکهای مختلفی استفاده کردیم، از جمله:
- استفاده از روشهای اکتشافی برای تصمیمگیری در مورد اینکه آیا یک بهینهسازی نتایج ارزشمندی تولید نمیکند و بنابراین میتوان از آن صرفنظر کرد یا خیر
- استفاده از ساختارهای داده اضافی برای ذخیره دادههای محاسبهشده
- تغییر ساختارهای داده فعلی برای افزایش سرعت
- محاسبهی نتایج با تنبلی برای جلوگیری از چرخهها در برخی موارد
- از انتزاع مناسب استفاده کنید - ویژگیهای غیرضروری میتوانند سرعت کد را کاهش دهند
- از دنبال کردن یک اشارهگر که اغلب استفاده میشود در بارهای زیاد خودداری کنید
از کجا بفهمیم که آیا بهینهسازیها ارزش دنبال کردن را دارند یا خیر؟
بخش جالب ماجرا همین است، شما این کار را نمیکنید. بعد از اینکه تشخیص دادید یک بخش زمان کامپایل زیادی را صرف میکند و بعد از اختصاص زمان توسعه برای بهبود آن، گاهی اوقات نمیتوانید راهحلی پیدا کنید. شاید کاری برای انجام دادن وجود نداشته باشد، پیادهسازی آن خیلی طول بکشد، یک معیار دیگر را به طور قابل توجهی کاهش دهد، پیچیدگی پایه کد را افزایش دهد و غیره. برای هر بهینهسازی موفقی که میتوانید در این پست وبلاگ ببینید، بدانید که تعداد بیشماری بهینهسازی دیگر وجود دارد که به نتیجه نرسیدهاند.
اگر شما هم در شرایط مشابهی هستید، سعی کنید تخمین بزنید که با انجام کمترین کار ممکن، چقدر میتوانید این معیار را بهبود ببخشید. این یعنی به ترتیب:
- تخمین با معیارهایی که قبلاً جمعآوری کردهاید، یا فقط یک حس درونی
- تخمین با یک نمونه اولیه سریع و ناقص
- یک راه حل را اجرا کنید.
فراموش نکنید که معایب راهحل خود را نیز تخمین بزنید. برای مثال، اگر قرار است به ساختارهای داده اضافی تکیه کنید، حاضرید از چه میزان حافظه استفاده کنید؟
غواصی عمیقتر
بدون مقدمه چینی بیشتر، بیایید نگاهی به برخی از تغییراتی که اعمال کردهایم بیندازیم.
ما تغییری را برای بهینهسازی روشی به نام FindReferenceInfoOf پیادهسازی کردیم. این روش جستجوی خطی یک بردار را برای یافتن یک ورودی انجام میداد. ما آن ساختار داده را بهروزرسانی کردیم تا توسط شناسه دستورالعمل فهرستبندی شود، به طوری که FindReferenceInfoOf به جای O(n) برابر با O(1) باشد. همچنین، ما بردار را از قبل تخصیص دادیم تا از تغییر اندازه جلوگیری شود. ما کمی حافظه را افزایش دادیم زیرا مجبور شدیم یک فیلد اضافی اضافه کنیم که تعداد ورودیهای وارد شده در بردار را بشمارد، اما این یک فداکاری کوچک بود زیرا حداکثر حافظه افزایش نیافت. این امر فاز LoadStoreAnalysis ما را 34 تا 66 درصد سرعت بخشید که به نوبه خود باعث بهبود زمان کامپایل حدود 0.5 تا 1.8 درصد میشود.
ما یک پیادهسازی سفارشی از HashSet داریم که در چندین جا از آن استفاده میکنیم. ایجاد این ساختار داده زمان قابل توجهی میبرد و ما دلیل آن را فهمیدیم. سالها پیش، این ساختار داده فقط در چند جایی که از HashSetهای بسیار بزرگ استفاده میکردند، استفاده میشد و برای بهینهسازی آن، تغییراتی اعمال شد. با این حال، امروزه در جهت مخالف با تنها چند ورودی و با طول عمر کوتاه استفاده میشود. این بدان معناست که ما با ایجاد این HashSet عظیم، چرخهها را هدر میدادیم، اما قبل از کنار گذاشتن آن، فقط برای چند ورودی از آن استفاده کردیم. با این تغییر ، حدود ۱.۳ تا ۲ درصد از زمان کامپایل را بهبود بخشیدیم. به عنوان یک مزیت اضافه، استفاده از حافظه حدود ۰.۵ تا ۱ درصد کاهش یافت، زیرا ما مانند قبل از ساختارهای داده بزرگی استفاده نمیکردیم.
ما با ارسال ساختارهای داده با ارجاع به لامبدا برای جلوگیری از کپی کردن آنها، حدود ۰.۵ تا ۱ درصد از زمان کامپایل را بهبود بخشیدیم. این چیزی بود که در بررسی اولیه از قلم افتاده بود و سالها در کدبیس ما باقی مانده بود. به لطف نگاهی به پروفایلها در pprof بود که متوجه شدیم این روشها ساختارهای داده زیادی را ایجاد و از بین میبرند، که ما را به بررسی و بهینهسازی آنها سوق داد.
ما با ذخیره مقادیر محاسبهشده در حافظه پنهان (cache) سرعت مرحلهای که خروجی کامپایل شده را مینویسد، افزایش دادیم که معادل حدود ۱.۳ تا ۲.۸ درصد بهبود در کل زمان کامپایل بود. متأسفانه، حسابداری اضافی بیش از حد بود و تست خودکار ما، ما را از رگرسیون حافظه مطلع کرد. بعداً، نگاهی دوباره به همان کد انداختیم و نسخه جدیدی را پیادهسازی کردیم که نه تنها رگرسیون حافظه را برطرف میکرد، بلکه زمان کامپایل را نیز حدود ۰.۵ تا ۱.۸ درصد بهبود بخشید! در این تغییر دوم، مجبور شدیم نحوه عملکرد این مرحله را مجدداً بازسازی و تصور کنیم تا از شر یکی از دو ساختار داده خلاص شویم.
ما در کامپایلر بهینهسازی خود مرحلهای داریم که فراخوانیهای تابع را برای دستیابی به عملکرد بهتر، درونخطی میکند. برای انتخاب اینکه کدام متدها را درونخطی کنیم، قبل از انجام هرگونه محاسبه، از روشهای اکتشافی و درست قبل از نهایی کردن درونخطی کردن، از بررسیهای نهایی پس از انجام کار استفاده میکنیم. اگر هر یک از این روشها تشخیص دهند که درونخطی کردن ارزشش را ندارد (برای مثال، دستورالعملهای جدید زیادی اضافه میشود)، فراخوانی متد را درونخطی نمیکنیم.
ما دو بررسی را از دسته «بررسیهای نهایی» به دسته «اکتشافی» منتقل کردیم تا قبل از انجام هرگونه محاسبه زمانبر، تخمین بزنیم که آیا یک inline کردن موفق خواهد شد یا خیر. از آنجایی که این یک تخمین است، کامل نیست، اما تأیید کردیم که اکتشافات جدید ما ۹۹.۹٪ از آنچه قبلاً inline شده بود را بدون تأثیر بر عملکرد پوشش میدهد. یکی از این اکتشافات جدید در مورد رجیسترهای DEX مورد نیاز (بهبود حدود ۰.۲ تا ۱.۳٪) و دیگری در مورد تعداد دستورالعملها (بهبود حدود ۲٪) بود.
ما یک پیادهسازی سفارشی از BitVector داریم که در چندین جا از آن استفاده میکنیم. ما کلاس BitVector با قابلیت تغییر اندازه را با یک BitVectorView سادهتر برای بردارهای بیتی با اندازه ثابت خاص جایگزین کردیم. این کار برخی از مسیرهای غیرمستقیم و بررسیهای محدوده زمان اجرا را حذف میکند و ساخت اشیاء بردار بیتی را سرعت میبخشد.
علاوه بر این، کلاس BitVectorView بر اساس نوع ذخیرهسازی زیرین الگوسازی شد (به جای اینکه همیشه از uint32_t مانند BitVector قدیمی استفاده کند). این امر به برخی از عملیات، به عنوان مثال Union()، اجازه میدهد تا دو برابر بیتهای بیشتری را در پلتفرمهای ۶۴ بیتی با هم پردازش کنند. نمونههای توابع آسیبدیده هنگام کامپایل سیستم عامل اندروید در مجموع بیش از ۱٪ کاهش یافتند. این کار با چندین تغییر انجام شد [ ۱ ، ۲ ، ۳ ، ۴ ، ۵ ، ۶ ]
اگر بخواهیم با جزئیات در مورد تمام بهینهسازیها صحبت کنیم، تمام روز اینجا خواهیم بود! اگر به بهینهسازیهای بیشتری علاقهمند هستید، به برخی تغییرات دیگری که اعمال کردهایم نگاهی بیندازید:
- حسابداری را اضافه کنید تا زمان کامپایل حدود ۰.۶ تا ۱.۶ درصد بهبود یابد.
- در صورت امکان، دادهها را با تنبلی محاسبه کنید تا از چرخهها جلوگیری شود.
- کد خود را طوری اصلاح کنیم که از کارهای پیشمحاسباتی در مواقعی که استفاده نمیشود، صرفنظر کنیم.
- وقتی میتوان تخصیصدهنده را به راحتی از جاهای دیگر تهیه کرد ، از برخی زنجیرههای بار وابسته اجتناب کنید .
- مورد دیگری از اضافه کردن چک برای جلوگیری از کار غیرضروری .
- از شاخهبندی مکرر روی نوع ثبات (هسته/FP) در تخصیصدهنده ثبات خودداری کنید .
- مطمئن شوید که برخی از آرایهها در زمان کامپایل مقداردهی اولیه شدهاند . برای انجام این کار به clang تکیه نکنید.
- برخی از حلقهها را پاکسازی کنید . از حلقههای محدودهای استفاده کنید که clang میتواند آنها را بهتر بهینهسازی کند زیرا نیازی به بارگذاری مجدد اشارهگرهای داخلی کانتینر به دلیل عوارض جانبی حلقه ندارد. از فراخوانی تابع مجازی `HInstruction::GetInputRecords()` در حلقه از طریق `InputAt(.)` درونخطی برای هر ورودی خودداری کنید.
- با سوءاستفاده از بهینهسازی کامپایلر، از توابع Accept() برای الگوی بازدیدکننده اجتناب کنید .
نتیجهگیری
تعهد ما به بهبود سرعت زمان کامپایل ART، پیشرفتهای قابل توجهی را به همراه داشته است، که باعث روانتر و کارآمدتر شدن اندروید شده و در عین حال به بهبود عمر باتری و کاهش دمای دستگاه نیز کمک میکند. با شناسایی و پیادهسازی دقیق بهینهسازیها، نشان دادهایم که افزایش قابل توجه زمان کامپایل بدون به خطر انداختن استفاده از حافظه یا کیفیت کد امکانپذیر است.
سفر ما شامل پروفایلسازی با ابزارهایی مانند pprof، تمایل به تکرار و گاهی حتی رها کردن مسیرهای کمثمرتر بود. تلاشهای جمعی تیم ART نه تنها زمان کامپایل را تا درصد قابل توجهی کاهش داده، بلکه زمینه را برای پیشرفتهای آینده نیز فراهم کرده است.
همه این پیشرفتها در بهروزرسانی اندروید پایان سال ۲۰۲۵ و برای اندروید ۱۲ و بالاتر از طریق بهروزرسانیهای اصلی در دسترس هستند. امیدواریم این بررسی عمیق در فرآیند بهینهسازی ما، بینشهای ارزشمندی در مورد پیچیدگیها و مزایای مهندسی کامپایلر ارائه دهد!
نوشته شده توسط:
ادامه مطلب


اخبار محصول
ما مفتخریم اعلام کنیم که پشتیبانی رسمی از موتور Unreal و Godot برای اندروید XR آغاز شده است. ما همچنین ابزارهای جدیدی را برای افزایش بهرهوری شما و فعال کردن قابلیتهای جدید XR راهاندازی میکنیم: مرکز موتور Android XR و چارچوب تعامل Android XR.
Luke Hopkins • ۴ دقیقه مطالعه


اخبار محصول
با انتشار اندروید ۱۷، ما در حال گذار به یک استاندارد توسعه تطبیقی اولیه هستیم. کاربران شما دیگر به یک فرم فاکتور واحد متکی نیستند؛ آنها در طول روز بین تلفنها، دستگاههای تاشو، تبلتها، لپتاپها، نمایشگرهای خودرو و محیطهای فراگیر واقعیت افزوده (XR) جابجا میشوند.
Fahd Imtiaz • ۴ دقیقه مطالعه


اخبار محصول
ما مفتخریم که ویژگیهای گوگل تیوی و ابزارهای توسعهدهندگانی را که برای افزایش قابلیت کشف محتوای شما و آمادهسازی برنامهتان برای تجربیات تلویزیونی آینده طراحی شدهاند، به اشتراک بگذاریم.
Paul Lammertsma • ۴ دقیقه مطالعه
در جریان باشید
جدیدترین بینشهای توسعه اندروید را به صورت هفتگی در صندوق ورودی خود دریافت کنید.
