
Dans les coroutines, un flux est un type qui peut émettre plusieurs valeurs de manière séquentielle, par opposition aux fonctions de suspension qui ne renvoient qu'une seule valeur. Par exemple, vous pouvez utiliser un flux pour recevoir les mises à jour en direct d'une base de données.
Les flux sont basés sur des coroutines et peuvent fournir plusieurs valeurs.
Un flux est conceptuellement un flux de données qui peut être calculé de manière asynchrone. Les valeurs émises doivent être du même type. Par exemple, Flow<Int> est un flux qui émet des valeurs entières.
Un flux est très semblable à un Iterator qui produit une séquence de valeurs, mais qui utilise des fonctions de suspension pour produire et consommer des valeurs de manière asynchrone. Cela signifie, par exemple, que le flux peut effectuer de façon sécurisée une requête réseau pour produire la valeur suivante sans bloquer le thread principal.
Trois entités sont impliquées dans les flux de données :
- Un producteur produit des données qui sont ajoutées au flux. Grâce aux coroutines, les flux peuvent également produire des données de manière asynchrone.
- Les intermédiaires facultatifs peuvent modifier chaque valeur émise dans le flux ou le flux lui-même.
- Un consommateur utilise les valeurs du flux.
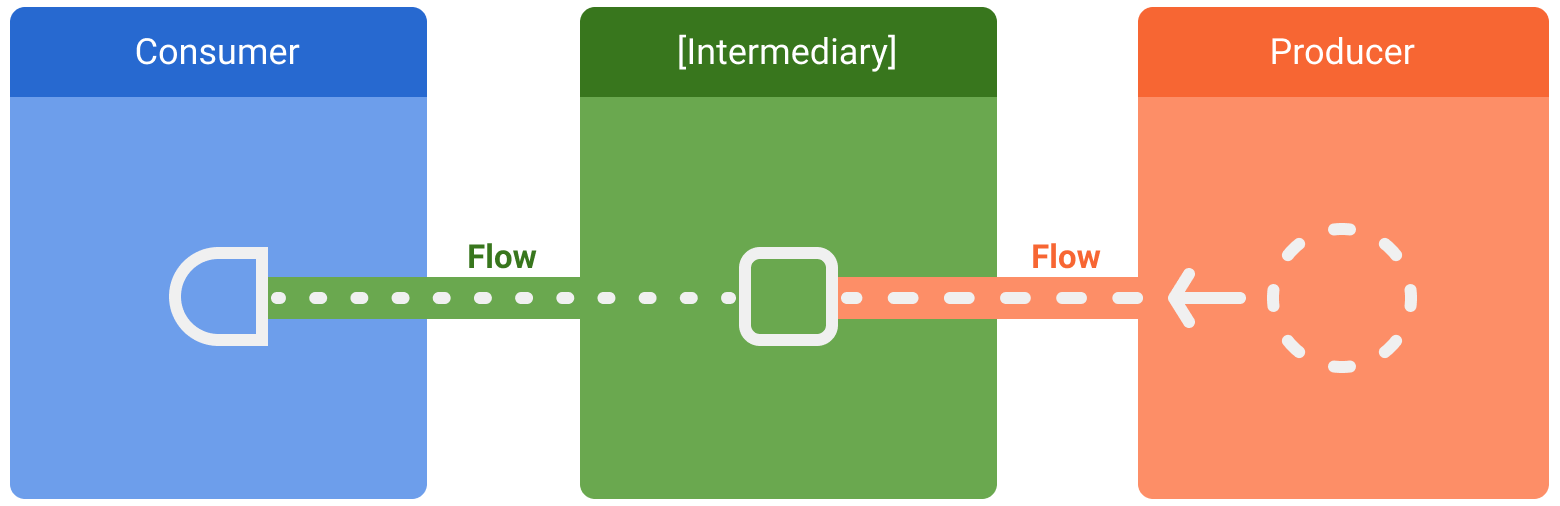
Dans Android, un dépôt est généralement un producteur de données d'interface utilisateur dont l'interface utilisateur (UI) correspond au consommateur qui affiche les données. Il arrive aussi que la couche d'interface utilisateur soit un producteur d'événements d'entrée utilisateur et que d'autres couches de la hiérarchie les consomment. Les couches entre le producteur et le consommateur agissent généralement comme des intermédiaires qui modifient le flux de données pour l'adapter aux exigences de la couche suivante.
Créer un flux
Pour créer des flux, utilisez les API de compilation Flow. La fonction de compilateur flow crée un nouveau flux dans lequel vous pouvez émettre manuellement de nouvelles valeurs dans le flux de données à l'aide de la fonction emit.
Dans l'exemple suivant, une source de données récupère automatiquement les dernières actualités à intervalles fixes. Étant donné qu'une fonction de suspension ne peut pas renvoyer plusieurs valeurs consécutives, la source de données crée et renvoie un flux pour répondre à cette exigence. Dans ce cas, la source de données fait office de producteur.
class NewsRemoteDataSource( private val newsApi: NewsApi, private val refreshIntervalMs: Long = 5000 ) { val latestNews: Flow<List<ArticleHeadline>> = flow { while (true) { val latestNews = newsApi.fetchLatestNews() emit(latestNews) // Emits the result of the request to the flow delay(refreshIntervalMs) // Suspends the coroutine for some time } } } // Interface that provides a way to make network requests with suspend functions interface NewsApi { suspend fun fetchLatestNews(): List<ArticleHeadline> }
Le constructeur flow est exécuté dans une coroutine. Il bénéficie donc des mêmes API asynchrones, mais certaines restrictions s'appliquent :
- Les flux sont séquentiels. Comme le producteur se trouve dans une coroutine, lorsqu'il appelle une fonction de suspension, il suspend son activité jusqu'à ce qu'elle renvoie un résultat. Dans l'exemple ci-dessus, le producteur suspend son activité jusqu'à ce que la requête réseau
fetchLatestNewssoit terminée. Ce n'est qu'alors que le résultat est émis dans le flux. - Avec le constructeur
flow, le producteur ne peut pas utiliser les valeursemitd'un autreCoroutineContext. Par conséquent, n'appelez pasemitdans un autreCoroutineContexten créant de nouvelles coroutines ou en utilisant des blocs de codewithContext. Dans ces cas, vous pouvez utiliser d'autres compilateurs Flow tels quecallbackFlow.
Modifier le flux
Les intermédiaires peuvent utiliser des opérateurs intermédiaires pour modifier le flux de données sans consommer les valeurs. Ces opérateurs sont des fonctions qui, lorsqu'elles sont appliquées à un flux de données, configurent une chaîne d'opérations qui ne sont exécutées que lorsque les valeurs sont consommées à l'avenir. Pour en savoir plus sur les opérateurs intermédiaires, consultez la documentation de référence sur Flow.
Dans l'exemple ci-dessous, la couche du dépôt utilise l'opérateur intermédiaire map pour transformer les données à afficher sur View :
class NewsRepository( private val newsRemoteDataSource: NewsRemoteDataSource, private val userData: UserData ) { /** * Returns the favorite latest news applying transformations on the flow. * These operations are lazy and don't trigger the flow. They just transform * the current value emitted by the flow at that point in time. */ val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews // Intermediate operation to filter the list of favorite topics .map { news -> news.filter { userData.isFavoriteTopic(it) } } // Intermediate operation to save the latest news in the cache .onEach { news -> saveInCache(news) } }
Les opérateurs intermédiaires peuvent être appliqués l'un après l'autre, formant une chaîne d'opérations qui sont exécutées en différé lorsqu'un élément est émis dans le flux. Notez que l'application d'un opérateur intermédiaire à un flux de données ne lance pas la collecte à partir du flux.
Collecter à partir d'un flux
Utilisez un opérateur terminal pour déclencher le flux et commencer à écouter les valeurs. Pour obtenir toutes les valeurs du flux à mesure qu'elles sont émises, utilisez collect.
Pour en savoir plus sur les opérateurs terminaux, consultez la documentation officielle sur Flow.
Comme collect est une fonction de suspension, il doit être exécuté dans une coroutine. Il accepte un lambda comme paramètre appelé à chaque nouvelle valeur. Comme il s'agit d'une fonction de suspension, la coroutine qui appelle collect peut être suspendue jusqu'à ce que le flux soit fermé.
Pour reprendre l'exemple précédent, voici une implémentation simple d'un ViewModel consommant les données de la couche de dépôt :
class LatestNewsViewModel( private val newsRepository: NewsRepository ) : ViewModel() { init { viewModelScope.launch { // Trigger the flow and consume its elements using collect newsRepository.favoriteLatestNews.collect { favoriteNews -> // Update UI with the latest favorite news } } } }
La collecte du flux déclenche le producteur qui actualise les dernières actualités et émet le résultat de la requête réseau à intervalles fixes. Comme le producteur reste toujours actif avec la boucle while(true), le flux de données sera fermé une fois le ViewModel effacé et le viewModelScope annulé.
La collecte du flux peut s'arrêter pour les raisons suivantes :
- La coroutine qui collecte est annulée, comme illustré dans l'exemple précédent. Cela interrompt également le producteur sous-jacent.
- Le producteur finit d'émettre des éléments. Dans ce cas, le flux de données est fermé et la coroutine qui a appelé
collectreprend l'exécution.
Les flux sont froids et différés, sauf indication contraire avec d'autres opérateurs intermédiaires. Cela signifie que le code du producteur est exécuté à chaque fois qu'un opérateur terminal est appelé sur le flux. Dans l'exemple précédent, le fait d'avoir plusieurs collecteurs de flux force la source de données à récupérer les dernières actualités plusieurs fois à différents intervalles fixes. Pour optimiser et partager un flux lorsque plusieurs consommateurs collectent en même temps, utilisez l'opérateur shareIn.
Intercepter les exceptions inattendues
L'implémentation du producteur peut provenir d'une bibliothèque tierce.
Des exceptions inattendues peuvent donc être générées. Pour gérer ces exceptions, utilisez l'opérateur intermédiaire catch.
class LatestNewsViewModel( private val newsRepository: NewsRepository ) : ViewModel() { init { viewModelScope.launch { newsRepository.favoriteLatestNews // Intermediate catch operator. If an exception is thrown, // catch and update the UI .catch { exception -> notifyError(exception) } .collect { favoriteNews -> // Update UI with the latest favorite news } } } }
Dans l'exemple précédent, lorsqu'une exception se produit, la commande collect lambda n'est pas appelée, car un nouvel élément n'a pas été reçu.
catch peut également lancer la commande emit pour les éléments dans le flux. Au lieu de cela, la couche de dépôt de l'exemple peut emit les valeurs mises en cache :
class NewsRepository( // ... ) { val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews .map { news -> news.filter { userData.isFavoriteTopic(it) } } .onEach { news -> saveInCache(news) } // If an error happens, emit the last cached values .catch { exception -> emit(lastCachedNews()) } }
Dans cet exemple, lorsqu'une exception se produit, le lambda collect est appelé car un nouvel élément a été émis dans le flux à cause de l'exception.
Exécuter dans un autre CoroutineContext
Par défaut, le producteur d'un constructeur flow s'exécute dans le CoroutineContext de la coroutine qui le collecte et, comme mentionné précédemment, ne peut pas emit de valeurs à partir d'un CoroutineContext différent. Ce comportement est parfois indésirable.
Par exemple, dans les exemples présentés dans cette rubrique, la couche de dépôt ne doit pas effectuer d'opérations sur Dispatchers.Main, qui est utilisé par viewModelScope.
Pour modifier le CoroutineContext d'un flux, utilisez l'opérateur intermédiaire flowOn.
flowOn modifie le CoroutineContext du flux en amont, c'est-à-dire le producteur et tout opérateur intermédiaire appliqué avant (ou au-dessus) de flowOn. Le flux en aval (les opérateurs intermédiaires après flowOn ainsi que le consommateur) n'est pas affecté et s'exécute sur le CoroutineContext utilisé pour la collect du flux. S'il existe plusieurs opérateurs flowOn, chacun modifie le flux en amont de son emplacement actuel.
class NewsRepository( private val newsRemoteDataSource: NewsRemoteDataSource, private val userData: UserData, private val defaultDispatcher: CoroutineDispatcher ) { val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews .map { news -> // Executes on the default dispatcher news.filter { userData.isFavoriteTopic(it) } } .onEach { news -> // Executes on the default dispatcher saveInCache(news) } // flowOn affects the upstream flow ↑ .flowOn(defaultDispatcher) // the downstream flow ↓ is not affected .catch { exception -> // Executes in the consumer's context emit(lastCachedNews()) } }
Avec ce code, les opérateurs onEach et map utilisent le defaultDispatcher, tandis que l'opérateur catch et le consommateur sont exécutés sur le Dispatchers.Main utilisé par viewModelScope.
Comme la couche source de données effectue des opérations d'E/S, vous devez utiliser un coordinateur optimisé pour les opérations d'E/S :
class NewsRemoteDataSource( // ... private val ioDispatcher: CoroutineDispatcher ) { val latestNews: Flow<List<ArticleHeadline>> = flow { // Executes on the IO dispatcher // ... } .flowOn(ioDispatcher) }
Flow dans les bibliothèques Jetpack
Flow est intégré dans de nombreuses bibliothèques Jetpack et est populaire parmi les bibliothèques Android tierces. Flow convient parfaitement aux mises à jour de données en direct et aux flux de données sans fin.
Vous pouvez utiliser Flow avec Room pour être averti des modifications dans une base de données. Lorsque vous utilisez des objets d'accès aux données (DAO), renvoyez un type de Flow pour obtenir des mises à jour en direct.
@Dao abstract class ExampleDao { @Query("SELECT * FROM Example") abstract fun getExamples(): Flow<List<Example>> }
Chaque fois que le tableau Example est modifié, une nouvelle liste est émise avec les nouveaux éléments de la base de données.
Convertir des API basées sur le rappel en flux
callbackFlow est un compilateur Flow qui vous permet de convertir les API basées sur le rappel en flux.
Par exemple, les API Android Firebase Firestore utilisent des rappels.
Pour convertir ces API en flux et écouter les mises à jour de la base de données Firestore, vous pouvez utiliser le code suivant :
class FirestoreUserEventsDataSource(
private val firestore: FirebaseFirestore
) {
// Method to get user events from the Firestore database
fun getUserEvents(): Flow<UserEvents> = callbackFlow {
// Reference to use in Firestore
var eventsCollection: CollectionReference? = null
try {
eventsCollection = FirebaseFirestore.getInstance()
.collection("collection")
.document("app")
} catch (e: Throwable) {
// If Firebase cannot be initialized, close the stream of data
// flow consumers will stop collecting and the coroutine will resume
close(e)
}
// Registers callback to firestore, which will be called on new events
val subscription = eventsCollection?.addSnapshotListener { snapshot, _ ->
if (snapshot == null) { return@addSnapshotListener }
// Sends events to the flow! Consumers will get the new events
try {
trySend(snapshot.getEvents())
} catch (e: Throwable) {
// Event couldn't be sent to the flow
}
}
// The callback inside awaitClose will be executed when the flow is
// either closed or cancelled.
// In this case, remove the callback from Firestore
awaitClose { subscription?.remove() }
}
}
Contrairement au compilateur de flow, callbackFlow permet d'émettre des valeurs à partir d'un CoroutineContext différent avec la fonction send ou en dehors d'une coroutine avec la fonction trySend.
En interne, callbackFlow utilise un canal qui est conceptuellement très semblable à une file d'attente de blocage.
Un canal est configuré avec une capacité, c'est-à-dire le nombre maximal d'éléments pouvant être mis en mémoire tampon. Par défaut, la capacité du canal créé dans callbackFlow est de 64 éléments. Lorsque vous essayez d'ajouter un nouvel élément à un canal plein, send suspend le producteur jusqu'à ce qu'il y ait de la place pour le nouvel élément, alors que trySend n'ajoute pas l'élément au canal et renvoie immédiatement la valeur false.
trySend ajoute immédiatement l'élément spécifié au canal, uniquement si cela ne viole pas ses restrictions de capacité, puis renvoie le résultat réussi.
Ressources supplémentaires sur les flux
- Tester des flux Kotlin sur Android
StateFlowetSharedFlow- Ressources supplémentaires sur les coroutines Kotlin et Flow