
W przypadku korutyn przepływ to typ, który może emitować wiele wartości sekwencyjnie, w przeciwieństwie do funkcji zawieszających , które zwracają tylko jedną wartość. Możesz na przykład użyć przepływu, aby otrzymywać aktualizacje na żywo z bazy danych.
Przepływy są oparte na korutynach i mogą dostarczać wiele wartości.
Przepływ jest koncepcyjnie strumieniem danych , który można obliczać asynchronicznie. Emitowane wartości muszą być tego samego typu. Na
przykład, Flow<Int> to przepływ, który emituje wartości całkowite.
Przepływ jest bardzo podobny do Iterator, który generuje sekwencję wartości, ale używa funkcji zawieszających do asynchronicznego generowania i wykorzystywania wartości. Oznacza to na przykład, że przepływ może bezpiecznie wysłać żądanie sieciowe, aby wygenerować następną wartość, bez blokowania wątku głównego.
W strumieniach danych występują 3 encje:
- Producent generuje dane, które są dodawane do strumienia. Dzięki korutynom przepływy mogą też generować dane asynchronicznie.
- (Opcjonalnie) Pośrednicy mogą modyfikować każdą wartość emitowaną do strumienia lub sam strumień.
- Konsument wykorzystuje wartości ze strumienia.
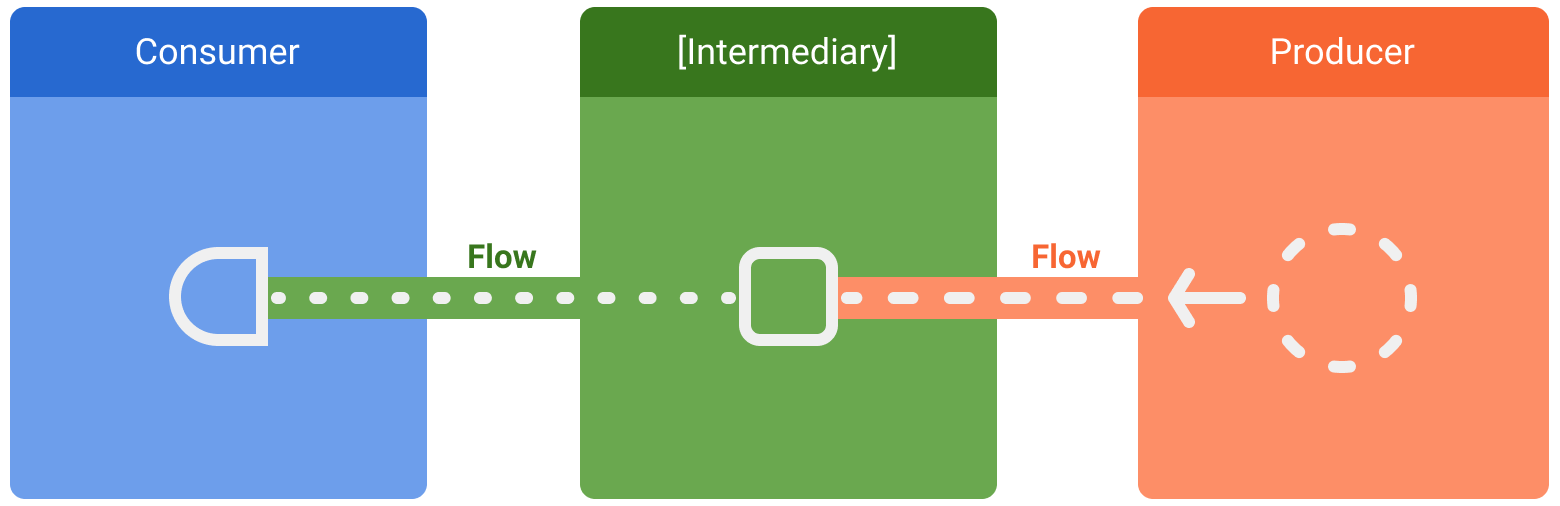
W Androidzie repozytorium jest zwykle producentem danych interfejsu, a interfejs użytkownika jest konsumentem który ostatecznie wyświetla dane. Czasami warstwa interfejsu jest producentem zdarzeń wprowadzania danych przez użytkownika, a inne warstwy hierarchii je wykorzystują. Warstwy między producentem a konsumentem zwykle pełnią rolę pośredników, którzy modyfikują strumień danych, aby dostosować go do wymagań następnej warstwy.
Tworzenie przepływu
Do tworzenia przepływów używaj interfejsów API narzędzia do tworzenia przepływów. Funkcja narzędzia do tworzenia przepływów flow tworzy nowy przepływ, w którym możesz ręcznie
emitować nowe wartości do strumienia danych za pomocą
emit
funkcji.
W przykładzie poniżej źródło danych automatycznie pobiera najnowsze wiadomości w stałych odstępach czasu. Ponieważ funkcja zawieszająca nie może zwracać wielu kolejnych wartości, źródło danych tworzy i zwraca przepływ, aby spełnić to wymaganie. W tym przypadku źródło danych pełni rolę producenta.
class NewsRemoteDataSource( private val newsApi: NewsApi, private val refreshIntervalMs: Long = 5000 ) { val latestNews: Flow<List<ArticleHeadline>> = flow { while (true) { val latestNews = newsApi.fetchLatestNews() emit(latestNews) // Emits the result of the request to the flow delay(refreshIntervalMs) // Suspends the coroutine for some time } } } // Interface that provides a way to make network requests with suspend functions interface NewsApi { suspend fun fetchLatestNews(): List<ArticleHeadline> }
Narzędzie do tworzenia przepływów flow jest wykonywane w korutynie. Dzięki temu korzysta z tych samych asynchronicznych interfejsów API, ale obowiązują pewne ograniczenia:
- Przepływy są sekwencyjne. Ponieważ producent znajduje się w korutynie, podczas wywoływania funkcji zawieszającej producent zawiesza się do momentu, aż funkcja zawieszająca zwróci wartość. W tym przykładzie producent zawiesza się do momentu zakończenia żądania sieciowego
fetchLatestNews. Dopiero wtedy wynik jest emitowany do strumienia. - W przypadku narzędzia do tworzenia przepływów
flowproducent nie możeemitwartości z innegoCoroutineContext. Dlatego nie wywołujemitw innymCoroutineContext, tworząc nowe korutyny lub używając bloków koduwithContext. W takich przypadkach możesz użyć innych narzędzi do tworzenia przepływów, takich jakcallbackFlow.
Modyfikowanie strumienia
Pośrednicy mogą używać operatorów pośrednich do modyfikowania strumienia danych bez wykorzystywania wartości. Te operatory to funkcje, które po zastosowaniu do strumienia danych konfigurują łańcuch operacji, które nie są wykonywane, dopóki wartości nie zostaną wykorzystane w przyszłości. Więcej informacji o operatorach pośrednich znajdziesz w dokumentacji referencyjnej przepływu.
W przykładzie poniżej warstwa repozytorium używa operatora pośredniego
map
aby przekształcić dane, które mają być wyświetlane w View:
class NewsRepository( private val newsRemoteDataSource: NewsRemoteDataSource, private val userData: UserData ) { /** * Returns the favorite latest news applying transformations on the flow. * These operations are lazy and don't trigger the flow. They just transform * the current value emitted by the flow at that point in time. */ val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews // Intermediate operation to filter the list of favorite topics .map { news -> news.filter { userData.isFavoriteTopic(it) } } // Intermediate operation to save the latest news in the cache .onEach { news -> saveInCache(news) } }
Operatory pośrednie można stosować jeden po drugim, tworząc łańcuch operacji, które są wykonywane leniwie, gdy element jest emitowany do przepływu. Pamiętaj, że samo zastosowanie operatora pośredniego do strumienia nie powoduje rozpoczęcia zbierania przepływu.
Zbieranie z przepływu
Aby uruchomić przepływ i rozpocząć nasłuchiwanie wartości, użyj operatora końcowego. Aby uzyskać wszystkie wartości w strumieniu w miarę ich emitowania, użyj
collect.
Więcej informacji o operatorach końcowych znajdziesz w
oficjalnej dokumentacji przepływu.
Ponieważ collect jest funkcją zawieszającą, musi być wykonywana w korutynie. Jako parametr przyjmuje lambdę, która jest wywoływana dla każdej nowej wartości. Ponieważ jest to funkcja zawieszająca, korutyna, która wywołuje collect, może zostać zawieszona do momentu zamknięcia przepływu.
Kontynuując poprzedni przykład, oto prosta implementacja ViewModel, która wykorzystuje dane z warstwy repozytorium:
class LatestNewsViewModel( private val newsRepository: NewsRepository ) : ViewModel() { init { viewModelScope.launch { // Trigger the flow and consume its elements using collect newsRepository.favoriteLatestNews.collect { favoriteNews -> // Update UI with the latest favorite news } } } }
Zbieranie przepływu uruchamia producenta, który odświeża najnowsze wiadomości i emituje wynik żądania sieciowego w stałych odstępach czasu. Ponieważ producent pozostaje zawsze aktywny dzięki pętli while(true), strumień danych zostanie zamknięty, gdy ViewModel zostanie wyczyszczony, a viewModelScope zostanie anulowany.
Zbieranie przepływu może się zatrzymać z tych powodów:
- Korutyna, która zbiera dane, zostanie anulowana, jak pokazano w poprzednim przykładzie. Spowoduje to też zatrzymanie producenta.
- Producent przestanie emitować elementy. W takim przypadku strumień danych zostanie zamknięty, a korutyna, która wywołała
collect, wznowi wykonywanie.
Przepływy są zimne i leniwe , chyba że określono je za pomocą innych operatorów pośrednich. Oznacza to, że kod producenta jest wykonywany za każdym razem, gdy operator końcowy jest wywoływany w przepływie. W poprzednim przykładzie posiadanie wielu kolektorów przepływu powoduje, że źródło danych pobiera najnowsze wiadomości wiele razy w różnych stałych odstępach czasu. Aby zoptymalizować i
udostępnić przepływ, gdy wielu konsumentów zbiera dane w tym samym czasie, użyj operatora
shareIn.
Obsługa nieoczekiwanych wyjątków
Implementacja producenta może pochodzić z biblioteki innej firmy.
Oznacza to, że może ona zgłaszać nieoczekiwane wyjątki. Aby obsługiwać te
wyjątki, użyj
catch
operatora pośredniego.
class LatestNewsViewModel( private val newsRepository: NewsRepository ) : ViewModel() { init { viewModelScope.launch { newsRepository.favoriteLatestNews // Intermediate catch operator. If an exception is thrown, // catch and update the UI .catch { exception -> notifyError(exception) } .collect { favoriteNews -> // Update UI with the latest favorite news } } } }
W poprzednim przykładzie, gdy wystąpi wyjątek, lambda collect nie jest wywoływana, ponieważ nie otrzymano nowego elementu.
catch może też emit elementy do przepływu. Przykładowa warstwa repozytorium może zamiast tego emit wartości z pamięci podręcznej:
class NewsRepository( // ... ) { val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews .map { news -> news.filter { userData.isFavoriteTopic(it) } } .onEach { news -> saveInCache(news) } // If an error happens, emit the last cached values .catch { exception -> emit(lastCachedNews()) } }
W tym przykładzie, gdy wystąpi wyjątek, lambda collect jest wywoływana, ponieważ do strumienia został wyemitowany nowy element z powodu wyjątku.
Wykonywanie w innym CoroutineContext
Domyślnie producent narzędzia do tworzenia przepływów flow jest wykonywany w CoroutineContext korutyny, która zbiera dane, i jak wspomnieliśmy wcześniej, nie może emit wartości z innego CoroutineContext. W niektórych przypadkach takie zachowanie może być niepożądane.
Na przykład w przykładach używanych w tym temacie warstwa repozytorium nie powinna wykonywać operacji na Dispatchers.Main, który jest używany przez viewModelScope.
Aby zmienić CoroutineContext przepływu, użyj operatora pośredniego
flowOn.
flowOn zmienia CoroutineContext przepływu nadrzędnego, co oznacza
producenta i wszystkich operatorów pośrednich zastosowanych przed (lub powyżej)
flowOn. Przepływ podrzędny (operatory pośrednie po flowOn wraz z konsumentem) nie jest modyfikowany i jest wykonywany w CoroutineContext używanym do collect z przepływu. Jeśli jest wiele operatorów flowOn, każdy z nich zmienia przepływ nadrzędny z bieżącej lokalizacji.
class NewsRepository( private val newsRemoteDataSource: NewsRemoteDataSource, private val userData: UserData, private val defaultDispatcher: CoroutineDispatcher ) { val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews .map { news -> // Executes on the default dispatcher news.filter { userData.isFavoriteTopic(it) } } .onEach { news -> // Executes on the default dispatcher saveInCache(news) } // flowOn affects the upstream flow ↑ .flowOn(defaultDispatcher) // the downstream flow ↓ is not affected .catch { exception -> // Executes in the consumer's context emit(lastCachedNews()) } }
W tym kodzie operatory onEach i map używają defaultDispatcher, a operator catch i konsument są wykonywane w Dispatchers.Main używanym przez viewModelScope.
Ponieważ warstwa źródła danych wykonuje operacje wejścia/wyjścia, należy użyć dyspozytora zoptymalizowanego pod kątem tych operacji:
class NewsRemoteDataSource( // ... private val ioDispatcher: CoroutineDispatcher ) { val latestNews: Flow<List<ArticleHeadline>> = flow { // Executes on the IO dispatcher // ... } .flowOn(ioDispatcher) }
Przepływy w bibliotekach Jetpack
Przepływ jest zintegrowany z wieloma bibliotekami Jetpack i jest popularny wśród bibliotek Androida innych firm. Przepływ doskonale nadaje się do aktualizacji danych na żywo i niekończących się strumieni danych.
Możesz używać
przepływu z Room
aby otrzymywać powiadomienia o zmianach w bazie danych. Gdy używasz
obiektów umożliwiających dostęp do danych (DAO),
zwróć typ Flow, aby otrzymywać aktualizacje na żywo.
@Dao abstract class ExampleDao { @Query("SELECT * FROM Example") abstract fun getExamples(): Flow<List<Example>> }
Za każdym razem, gdy w tabeli Example nastąpi zmiana, emitowana jest nowa lista z nowymi elementami w bazie danych.
Konwertowanie interfejsów API opartych na wywołaniach zwrotnych na przepływy
callbackFlow
to narzędzie do tworzenia przepływów, które umożliwia konwertowanie interfejsów API opartych na wywołaniach zwrotnych na przepływy.
Na przykład interfejsy API Firebase Firestore
na Androida używają wywołań zwrotnych.
Aby przekonwertować te interfejsy API na przepływy i nasłuchiwać aktualizacji bazy danych Firestore, możesz użyć tego kodu:
class FirestoreUserEventsDataSource(
private val firestore: FirebaseFirestore
) {
// Method to get user events from the Firestore database
fun getUserEvents(): Flow<UserEvents> = callbackFlow {
// Reference to use in Firestore
var eventsCollection: CollectionReference? = null
try {
eventsCollection = FirebaseFirestore.getInstance()
.collection("collection")
.document("app")
} catch (e: Throwable) {
// If Firebase cannot be initialized, close the stream of data
// flow consumers will stop collecting and the coroutine will resume
close(e)
}
// Registers callback to firestore, which will be called on new events
val subscription = eventsCollection?.addSnapshotListener { snapshot, _ ->
if (snapshot == null) { return@addSnapshotListener }
// Sends events to the flow! Consumers will get the new events
try {
trySend(snapshot.getEvents())
} catch (e: Throwable) {
// Event couldn't be sent to the flow
}
}
// The callback inside awaitClose will be executed when the flow is
// either closed or cancelled.
// In this case, remove the callback from Firestore
awaitClose { subscription?.remove() }
}
}
W przeciwieństwie do narzędzia do tworzenia przepływów flow, callbackFlow
umożliwia emitowanie wartości z innego CoroutineContext za pomocą
send
funkcji lub poza korutyną za pomocą
trySend
funkcji.
Wewnętrznie callbackFlow używa
kanału,
który jest koncepcyjnie bardzo podobny do kolejki blokującej
kolejki.
Kanał jest skonfigurowany z pojemnością, czyli maksymalną liczbą elementów
, które można buforować. Kanał utworzony w callbackFlow ma domyślną pojemność 64 elementów. Gdy próbujesz dodać nowy element do pełnego kanału, send zawiesza producenta do momentu, aż pojawi się miejsce na nowy element, natomiast trySend nie dodaje elementu do kanału i natychmiast zwraca wartość false.
trySend natychmiast dodaje określony element do kanału, tylko jeśli nie narusza to ograniczeń pojemności, a następnie zwraca wynik.
Dodatkowe materiały dotyczące przepływu
- Testowanie przepływów Kotlin na Androidzie
StateFlowiSharedFlow- Dodatkowe materiały dotyczące korutyn i przepływu Kotlin