
En materia de corrutinas, un flujo es un tipo que puede emitir varios valores de manera secuencial, en lugar de suspender funciones que muestran solo un valor único. Un flujo se puede usar, por ejemplo, para recibir actualizaciones en vivo de una base de datos.
Los flujos se compilan sobre las corrutinas y pueden proporcionar varios valores.
Un flujo es conceptualmente una transmisión de datos que se puede computar de forma asíncrona. Los valores emitidos deben ser del mismo tipo. Por ejemplo, un Flow<Int> es un flujo que emite valores enteros.
Un flujo es muy similar a un Iterator que produce una secuencia de valores, pero usa funciones de suspensión para producir y consumir valores de forma asíncrona. Esto significa que, por ejemplo, el flujo puede enviar de forma segura una solicitud de red para producir el siguiente valor sin bloquear el subproceso principal.
Hay tres entidades involucradas en transmisiones de datos:
- Un productor produce datos que se agregan al flujo. Gracias a las corrutinas, los flujos también pueden producir datos de forma asíncrona.
- Los intermediarios (opcional) pueden modificar cada valor emitido en el flujo, o bien el flujo mismo.
- Un consumidor consume los valores del flujo.
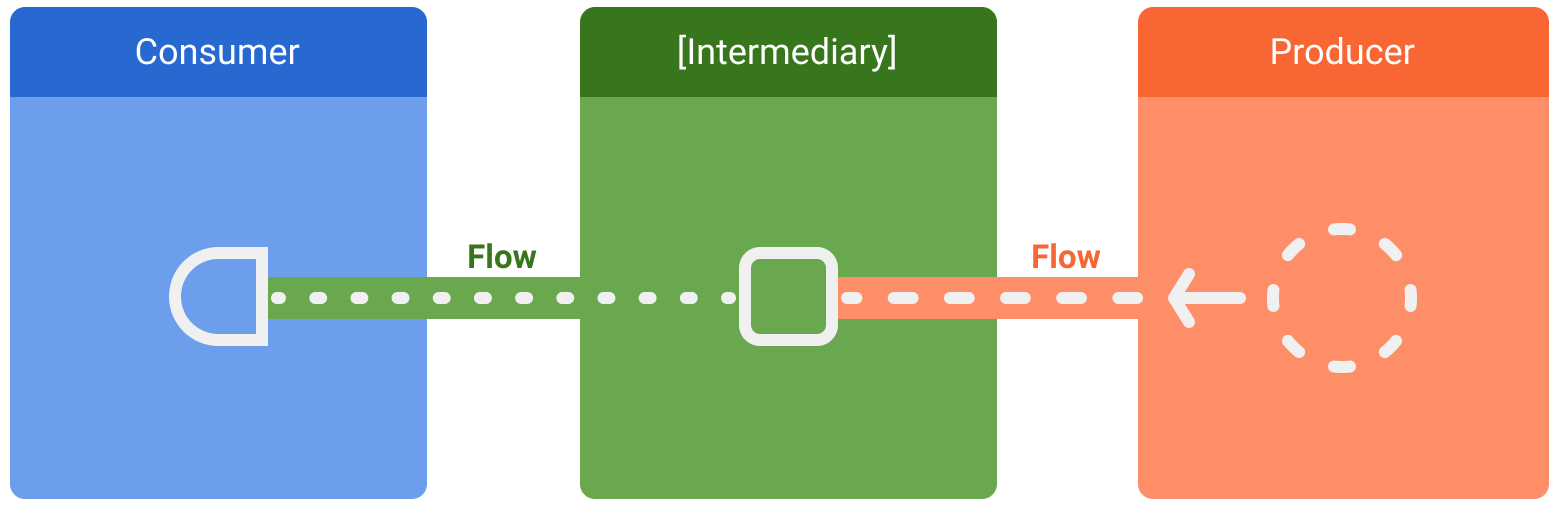
En Android, un repositorio es, generalmente, un productor de datos de IU que tiene la interfaz de usuario (IU) como consumidor que, en última instancia, muestra los datos. En otras ocasiones, la capa de IU es un productor de eventos de entrada del usuario para consumo de otras capas de la jerarquía. Las capas que se encuentran entre el productor y el consumidor suelen actuar como intermediarios que modifican el flujo de datos para ajustarlo a los requisitos de la siguiente capa.
Cómo crear un flujo
Para crear flujos, usa las APIs de compilador de flujo. La función del compilador de flow crea un flujo nuevo en el que puedes emitir de forma manual valores nuevos en el flujo de datos con la función emit.
En el siguiente ejemplo, una fuente de datos recupera las últimas noticias automáticamente a un intervalo fijo. Como una función de suspensión no puede mostrar varios valores consecutivos, la fuente de datos crea y muestra un flujo para cumplir con este requisito. En este caso, la fuente de datos actúa como productor.
class NewsRemoteDataSource(
private val newsApi: NewsApi,
private val refreshIntervalMs: Long = 5000
) {
val latestNews: Flow<List<ArticleHeadline>> = flow {
while(true) {
val latestNews = newsApi.fetchLatestNews()
emit(latestNews) // Emits the result of the request to the flow
delay(refreshIntervalMs) // Suspends the coroutine for some time
}
}
}
// Interface that provides a way to make network requests with suspend functions
interface NewsApi {
suspend fun fetchLatestNews(): List<ArticleHeadline>
}
El compilador flow se ejecuta dentro de una corrutina, por lo que se beneficia de las mismas API asíncronas. Sin embargo, se aplican algunas restricciones:
- Los flujos son secuenciales. Como el productor está en una corrutina, cuando se llama a una función de suspensión, este se suspende hasta que se muestre la función de suspensión. En el ejemplo, el productor se suspende hasta que se complete la solicitud de red de
fetchLatestNews. Solo entonces se emite el resultado en el flujo. - Con el compilador de
flow, el productor no puede cambiar los valoresemitde unCoroutineContextdiferente. Por lo tanto, no llames aemiten unCoroutineContextdiferente creando corrutinas nuevas ni usando bloques de códigowithContext. En esos casos, puedes usar otros compiladores de flujo, comocallbackFlow.
Cómo modificar un flujo
Los intermediarios pueden usar operadores intermedios para modificar el flujo de datos sin consumir los valores. Estos operadores son funciones que, cuando se aplican a un flujo de datos, establecen una cadena de operaciones que no se ejecutan hasta que los valores se consumen en el futuro. Obtén más información sobre los operadores intermedios en la documentación de referencia sobre flujos.
En el siguiente ejemplo, la capa del repositorio usa el operador intermedio map para transformar los datos que se mostrarán en View:
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val userData: UserData
) {
/**
* Returns the favorite latest news applying transformations on the flow.
* These operations are lazy and don't trigger the flow. They just transform
* the current value emitted by the flow at that point in time.
*/
val favoriteLatestNews: Flow<List<ArticleHeadline>> =
newsRemoteDataSource.latestNews
// Intermediate operation to filter the list of favorite topics
.map { news -> news.filter { userData.isFavoriteTopic(it) } }
// Intermediate operation to save the latest news in the cache
.onEach { news -> saveInCache(news) }
}
Los operadores intermedios se pueden aplicar uno después de otro para una cadena de operaciones que se ejecutan de forma diferida cuando se emite un elemento en el flujo. Ten en cuenta que aplicar un operador intermedio en un flujo no inicia la recopilación de flujo.
Cómo recopilar datos de un flujo
Usa un operador de terminal para activar el flujo y comenzar a detectar valores. Para obtener todos los valores del flujo a medida que se emiten, usa collect.
Puedes obtener más información sobre los operadores de terminal en la documentación oficial sobre flujos.
Como collect es una función de suspensión, debe ejecutarse dentro de una corrutina. Toma un valor lambda como parámetro que se llame en cada valor nuevo. Además, como se trata de una función de suspensión, la corrutina que llama a collect puede suspenderse hasta que se cierre el flujo.
Para continuar con el ejemplo anterior, aquí hay una implementación simple de un ViewModel que consume los datos de la capa del repositorio:
class LatestNewsViewModel(
private val newsRepository: NewsRepository
) : ViewModel() {
init {
viewModelScope.launch {
// Trigger the flow and consume its elements using collect
newsRepository.favoriteLatestNews.collect { favoriteNews ->
// Update View with the latest favorite news
}
}
}
}
La recopilación del flujo activa el productor que actualiza las últimas noticias y emite el resultado de la solicitud de red en un intervalo fijo. Como el productor permanece activo con el bucle while(true), el flujo de datos se cerrará cuando se borre el ViewModel y se cancele viewModelScope.
La recopilación de flujos puede detenerse por los siguientes motivos:
- Se cancela la corrutina que recopila, como se muestra en el ejemplo anterior. Esta acción también detiene al productor subyacente.
- El productor termina de emitir los elementos. En ese caso, se cierra el flujo de datos, y la corrutina que llamó a
collectreanuda la ejecución.
Los flujos son fríos y diferidos, a menos que se especifiquen otros operadores intermedios. Esto significa que el código del productor se ejecuta cada vez que se llama a un operador de terminal en el flujo. En el ejemplo anterior, tener varios recopiladores de flujo provoca que la fuente de datos recupere las últimas noticias varias veces en diferentes intervalos fijos. Para optimizar y compartir un flujo cuando varios consumidores recopilan información al mismo tiempo, usa el operador shareIn.
Cómo detectar excepciones inesperadas
La implementación del productor puede provenir de una biblioteca de terceros.
Esto significa que puede generar excepciones inesperadas. Para manejar estas excepciones, usa el operador intermedio catch.
class LatestNewsViewModel(
private val newsRepository: NewsRepository
) : ViewModel() {
init {
viewModelScope.launch {
newsRepository.favoriteLatestNews
// Intermediate catch operator. If an exception is thrown,
// catch and update the UI
.catch { exception -> notifyError(exception) }
.collect { favoriteNews ->
// Update View with the latest favorite news
}
}
}
}
En el ejemplo anterior, cuando se produce una excepción, no se llama al valor lambda collect, puesto que no se recibió un elemento nuevo.
catch también puede emit elementos en el flujo. En el caso de la capa del repositorio de ejemplo, se podrían emit los valores almacenados en caché:
class NewsRepository(...) {
val favoriteLatestNews: Flow<List<ArticleHeadline>> =
newsRemoteDataSource.latestNews
.map { news -> news.filter { userData.isFavoriteTopic(it) } }
.onEach { news -> saveInCache(news) }
// If an error happens, emit the last cached values
.catch { exception -> emit(lastCachedNews()) }
}
En este ejemplo, cuando se produce una excepción, se llama al valor lambda collect, puesto que se emitió un nuevo elemento a la transmisión debido a la excepción.
Cómo ejecutar la app en un CoroutineContext diferente
De forma predeterminada, el productor de un compiladorflow se ejecuta en el elemento CoroutineContext de la corrutina que se recopila de ella y, como ya se mencionó, no puede emit valores de un CoroutineContext diferente. Este comportamiento podría ser no deseado en algunos casos.
Por ejemplo, en los ejemplos que se usan en este tema, la capa del repositorio no debe realizar operaciones en el Dispatchers.Main que usa viewModelScope.
Para cambiar el CoroutineContext de un flujo, usa el operador intermedio flowOn.
flowOn cambia el CoroutineContext del flujo ascendente, lo que significa que el productor y los operadores intermedios se aplican antes (o más arriba)que
flowOn. El flujo descendente (los operadores intermedios que van después de flowOn y el consumidor) no se ve afectado y se ejecuta en el CoroutineContext que se usa para collect del flujo. Si hay varios operadores flowOn, cada uno cambia el ascendente desde su ubicación de ese momento.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val userData: UserData,
private val defaultDispatcher: CoroutineDispatcher
) {
val favoriteLatestNews: Flow<List<ArticleHeadline>> =
newsRemoteDataSource.latestNews
.map { news -> // Executes on the default dispatcher
news.filter { userData.isFavoriteTopic(it) }
}
.onEach { news -> // Executes on the default dispatcher
saveInCache(news)
}
// flowOn affects the upstream flow ↑
.flowOn(defaultDispatcher)
// the downstream flow ↓ is not affected
.catch { exception -> // Executes in the consumer's context
emit(lastCachedNews())
}
}
Con este código, los operadores onEach y map usan defaultDispatcher, mientras que el operador catch y el consumidor se ejecutan en el Dispatchers.Main que usa viewModelScope.
Como la capa de la fuente de datos realiza el trabajo de E/S, debes usar un despachador optimizado para operaciones de E/S:
class NewsRemoteDataSource(
...,
private val ioDispatcher: CoroutineDispatcher
) {
val latestNews: Flow<List<ArticleHeadline>> = flow {
// Executes on the IO dispatcher
...
}
.flowOn(ioDispatcher)
}
Flujos en bibliotecas Jetpack
El flujo está integrado en varias bibliotecas de Jetpack y es popular entre las bibliotecas de terceros de Android. El flujo es una gran opción para las actualizaciones de datos en tiempo real y los flujos de datos infinitos.
Puedes usar Flow with Room para recibir notificaciones sobre los cambios en una base de datos. Cuando uses objetos de acceso a datos (DAO), muestra un tipo Flow para obtener actualizaciones en tiempo real.
@Dao
abstract class ExampleDao {
@Query("SELECT * FROM Example")
abstract fun getExamples(): Flow<List<Example>>
}
Cada vez que haya un cambio en la tabla de Example, se emitirá una lista nueva con los elementos nuevos en la base de datos.
Cómo convertir APIs basadas en devolución de llamada en flujos
callbackFlow es un compilador de flujo que te permite convertir APIs basadas en devolución de llamada en flujos.
A modo de ejemplo, las APIs de Android de Firebase Firestore usan devoluciones de llamada.
Para convertir esas APIs en flujos y detectar actualizaciones de la base de datos de Firestore, puedes usar el siguiente código:
class FirestoreUserEventsDataSource(
private val firestore: FirebaseFirestore
) {
// Method to get user events from the Firestore database
fun getUserEvents(): Flow<UserEvents> = callbackFlow {
// Reference to use in Firestore
var eventsCollection: CollectionReference? = null
try {
eventsCollection = FirebaseFirestore.getInstance()
.collection("collection")
.document("app")
} catch (e: Throwable) {
// If Firebase cannot be initialized, close the stream of data
// flow consumers will stop collecting and the coroutine will resume
close(e)
}
// Registers callback to firestore, which will be called on new events
val subscription = eventsCollection?.addSnapshotListener { snapshot, _ ->
if (snapshot == null) { return@addSnapshotListener }
// Sends events to the flow! Consumers will get the new events
try {
trySend(snapshot.getEvents())
} catch (e: Throwable) {
// Event couldn't be sent to the flow
}
}
// The callback inside awaitClose will be executed when the flow is
// either closed or cancelled.
// In this case, remove the callback from Firestore
awaitClose { subscription?.remove() }
}
}
A diferencia del compilador flow, callbackFlow permite que los valores se emitan desde un CoroutineContext diferente con la función send, o bien fuera de una corrutina con la función trySend.
A nivel interno, callbackFlow usa un canal, que es conceptualmente muy similar a una cola de bloqueo.
Un canal se configura con una capacidad, es decir, una cantidad máxima de elementos que se pueden almacenar en búfer. El canal creado en callbackFlow tiene una capacidad predeterminada de 64 elementos. Cuando agregas un nuevo elemento a un canal completo, send suspende al productor hasta que haya espacio para el nuevo elemento, mientras que trySend no agrega el elemento al canal y muestra false inmediatamente.
trySend agrega inmediatamente el elemento especificado al canal.
solo si no infringe sus restricciones de capacidad y, luego, devuelve
resultado exitoso.
Recursos adicionales de flujo
- Cómo probar los flujos de Kotlin en Android
StateFlowySharedFlow- Recursos adicionales para las corrutinas y el flujo de Kotlin