


A equipe do Android Runtime (ART) reduziu o tempo de compilação em 18% sem comprometer o código compilado ou qualquer regressão de memória de pico. Essa melhoria fez parte da nossa iniciativa de 2025 para melhorar o tempo de compilação sem sacrificar o uso de memória ou a qualidade do código compilado.
Otimizar a velocidade do tempo de compilação é fundamental para o ART. Por exemplo, ao compilar just-in-time (JIT), isso afeta diretamente a eficiência dos aplicativos e a performance geral do dispositivo. Compilações mais rápidas reduzem o tempo antes que as otimizações entrem em vigor, levando a uma experiência do usuário mais suave e responsiva. Além disso, para JIT e ahead-of-time (AOT), as melhorias na velocidade do tempo de compilação se traduzem em consumo reduzido de recursos durante o processo de compilação, beneficiando a duração da bateria e a temperatura do dispositivo, especialmente em dispositivos de baixa qualidade.
Algumas dessas melhorias de velocidade de tempo de compilação foram lançadas na versão do Android de junho de 2025, e o restante estará disponível na versão de fim de ano do Android. Além disso, todos os usuários do Android nas versões 12 e mais recentes podem receber essas melhorias por meio de atualizações principais.
Otimização do compilador de otimização
A otimização de um compilador é sempre um jogo de concessões. Não é possível ter velocidade sem custo financeiro. É preciso abrir mão de algo. Definimos uma meta muito clara e desafiadora para nós mesmos: tornar o compilador mais rápido, mas sem introduzir regressões de memória e, principalmente, sem degradar a qualidade do código produzido. Se o compilador for mais rápido, mas os apps forem executados mais lentamente, falhamos.
O único recurso que estávamos dispostos a gastar era nosso próprio tempo de desenvolvimento para investigar e encontrar soluções inteligentes que atendessem a esses critérios rigorosos. Vamos analisar mais de perto como trabalhamos para encontrar áreas a serem melhoradas, além de encontrar as soluções certas para os vários problemas.
Encontrar possíveis otimizações que valham a pena
Antes de começar a otimizar uma métrica, é preciso medi-la. Caso contrário, você nunca poderá ter certeza se a melhorou ou não. Felizmente para nós, a velocidade do tempo de compilação é bastante consistente, desde que você tome algumas precauções, como usar o mesmo dispositivo que você usa para medir antes e depois de uma mudança, e garantir que você não faça o throttling térmico do dispositivo. Além disso, também temos medições determinísticas, como estatísticas do compilador, que nos ajudam a entender o que está acontecendo.
Como o recurso que estávamos sacrificando para essas melhorias era nosso tempo de desenvolvimento, queríamos poder iterar o mais rápido possível. Isso significava que pegamos alguns apps representativos (uma mistura de apps próprios, apps de terceiros e o próprio sistema operacional Android) para criar protótipos de soluções. Mais tarde, verificamos se a implementação final valeu a pena com testes manuais e automatizados de maneira generalizada.
Com esse conjunto de APKs escolhidos a dedo, acionamos uma compilação manual localmente, recebemos um perfil da compilação e usamos o pprof para visualizar onde estamos gastando nosso tempo.
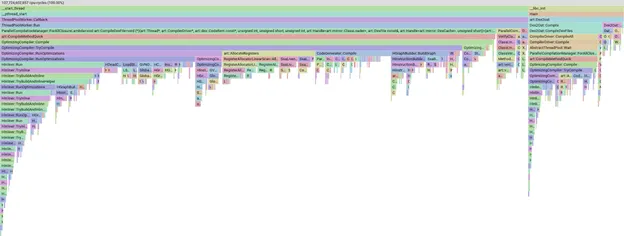
Exemplo de gráfico de chama de um perfil no pprof
A ferramenta pprof é muito poderosa e nos permite dividir, filtrar e classificar os dados para ver, por exemplo, quais fases ou métodos do compilador estão levando mais tempo. Não vamos entrar em detalhes sobre o pprof em si. Basta saber que, se a barra for maior, significa que levou mais tempo da compilação.
Uma dessas visualizações é a "de baixo para cima", em que é possível ver quais métodos estão levando mais tempo. Na imagem abaixo, podemos ver um método chamado Kill, que representa mais de 1% do tempo de compilação. Alguns dos outros métodos principais também serão discutidos mais adiante no post do blog.
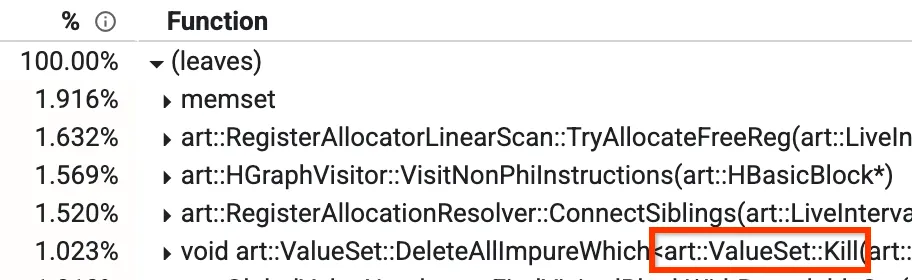
Visualização de baixo para cima de um perfil
No nosso compilador de otimização, há uma fase chamada Global Value Numbering (GVN). Não é preciso se preocupar com o que ele faz como um todo, mas a parte relevante é saber que ele tem um método chamado `Kill` que exclui alguns nós de acordo com um filtro. Isso consome muito tempo, já que precisa iterar por todos os nós e verificar um por um. Percebemos que há alguns casos em que sabemos com antecedência que a verificação será falsa, não importa os nós que temos ativos nesse momento. Nesses casos, podemos pular a iteração completamente, reduzindo de 1,023% para ~0,3% e melhorando o tempo de execução do GVN em ~15%.
Implementação de otimizações que valem a pena
Abordamos como medir e detectar onde o tempo está sendo gasto, mas isso é apenas o começo. A próxima etapa é otimizar o tempo gasto na compilação.
Normalmente, em um caso como o `Kill` acima, analisamos como iteramos pelos nós e fazemos isso mais rápido, por exemplo, fazendo coisas em paralelo ou melhorando o algoritmo em si. Na verdade, foi isso que tentamos no início e, somente quando não encontramos nada para fazer, tivemos um momento de "Espere um minuto…" e percebemos que a solução era (em alguns casos) não iterar! Ao fazer esses tipos de otimizações, é fácil perder a floresta pelas árvores.
Em outros casos, usamos algumas técnicas diferentes, incluindo:
- usar heurísticas para decidir se uma otimização não vai produzir resultados que valham a pena e, portanto, pode ser ignorada
- usar estruturas de dados extras para armazenar em cache os dados computados
- mudar as estruturas de dados atuais para aumentar a velocidade
- computar resultados lentamente para evitar ciclos em alguns casos
- usar a abstração certa: recursos desnecessários podem deixar o código mais lento
- evitar buscar um ponteiro usado com frequência em muitos carregamentos
Como sabemos se as otimizações valem a pena?
Essa é a parte interessante: você não sabe. Depois de detectar que uma área está consumindo muito tempo de compilação e depois de dedicar tempo de desenvolvimento para tentar melhorá-la, às vezes não é possível encontrar uma solução. Talvez não haja nada a fazer, vai levar muito tempo para implementar, vai regredir outra métrica significativamente, aumentar a complexidade da base de código etc. Para cada otimização bem-sucedida que você pode ver neste post do blog, saiba que há inúmeras outras que simplesmente não se concretizaram.
Se você estiver em uma situação semelhante, tente estimar o quanto vai melhorar a métrica fazendo o mínimo de trabalho possível. Isso significa, em ordem:
- Estimativa com uma métrica que você já coletou ou apenas um palpite
- Estimativa com um protótipo rápido e sujo
- Implementar uma solução.
Não se esqueça de estimar as desvantagens da sua solução. Por exemplo, se você vai usar estruturas de dados extras, quanta memória está disposto a usar?
Análise detalhada
Sem mais delongas, vamos conferir algumas das mudanças que implementamos.
Implementamos uma mudança para otimizar um método chamado FindReferenceInfoOf. Esse método estava fazendo uma pesquisa linear de um vetor para encontrar uma entrada. Atualizamos essa estrutura de dados para ser indexada pelo ID da instrução, de modo que FindReferenceInfoOf seria O(1) em vez de O(n). Além disso, pré-alocamos o vetor para evitar o redimensionamento. Aumentamos ligeiramente a memória, já que tivemos que adicionar um campo extra que contava quantas entradas inserimos no vetor, mas foi um pequeno sacrifício, já que a memória de pico não aumentou. Isso acelerou nossa fase LoadStoreAnalysis em 34 a 66%, o que, por sua vez, oferece uma melhoria de tempo de compilação de ~0,5 a 1,8%.
Temos uma implementação personalizada do HashSet que usamos em vários lugares. A criação dessa estrutura de dados estava levando um tempo considerável, e descobrimos o motivo. Há muitos anos, essa estrutura de dados era usada apenas em alguns lugares que usavam HashSets muito grandes e foi ajustada para ser otimizada para isso. No entanto, hoje em dia, ela era usada na direção oposta, com apenas algumas entradas e com uma vida útil curta. Isso significava que estávamos desperdiçando ciclos ao criar esse HashSet enorme, mas só o usamos para algumas entradas antes de descartá-lo. Com essa mudança, melhoramos ~1,3 a 2% do tempo de compilação. Como um bônus adicional, o uso de memória diminuiu em ~0,5 a 1%, já que não estávamos usando estruturas de dados tão grandes quanto antes.
Melhoramos ~0,5 a 1% do tempo de compilação ao transmitir estruturas de dados por referência para a lambda para evitar copiá-las. Isso foi algo que foi perdido na revisão original e ficou na nossa base de código por anos. Foi graças a uma análise dos perfis no pprof que percebemos que esses métodos estavam criando e destruindo muitas estruturas de dados, o que nos levou a investigar e otimizá-los.
Aceleramos a fase que grava a saída compilada armazenando em cache os valores computados, o que se traduziu em ~1,3 a 2,8% de melhoria total do tempo de compilação. Infelizmente, a contabilidade extra era muito grande, e nossos testes automatizados nos alertaram sobre a regressão de memória. Mais tarde, analisamos o mesmo código e implementamos uma nova versão que não apenas cuidou da regressão de memória, mas também melhorou o tempo de compilação em mais ~0,5 a 1,8%. Nessa segunda mudança, tivemos que refatorar e reimaginar como essa fase deveria funcionar para nos livrarmos de uma das duas estruturas de dados.
Temos uma fase no nosso compilador de otimização que incorpora chamadas de função para melhorar a performance. Para escolher quais métodos incorporar, usamos heurísticas antes de fazer qualquer computação e verificações finais depois de trabalhar, mas antes de finalizar a incorporação. Se algum deles detectar que a incorporação não vale a pena (por exemplo, muitas novas instruções seriam adicionadas), não incorporamos a chamada de método.
Movemos duas verificações da categoria "verificações finais" para a categoria "heurística" para estimar se uma incorporação será bem-sucedida ou não antes de fazermos qualquer computação demorada. Como essa é uma estimativa, ela não é perfeita, mas verificamos que nossas novas heurísticas cobrem 99,9% do que foi incorporado antes sem afetar a performance. Uma dessas novas heurísticas era sobre os registros DEX necessários (melhoria de ~0,2 a 1,3%), e a outra sobre o número de instruções (melhoria de ~2%).
Temos uma implementação personalizada de um BitVector que usamos em vários lugares. Substituímos a classe BitVector redimensionável por um BitVectorView mais simples para determinados vetores de bits de tamanho fixo. Isso elimina algumas indireções e verificações de intervalo de tempo de execução e acelera a construção dos objetos de vetor de bits.
Além disso, a classe BitVectorView foi modelada no tipo de armazenamento subjacente (em vez de sempre usar uint32_t como o BitVector antigo). Isso permite que algumas operações, por exemplo, Union(), processem o dobro de bits juntos em plataformas de 64 bits. As amostras das funções afetadas foram reduzidas em mais de 1% no total ao compilar o SO Android. Isso foi feito em várias mudanças [1, 2, 3, 4, 5, 6]
Se falássemos em detalhes sobre todas as otimizações, ficaríamos aqui o dia todo. Se você estiver interessado em mais otimizações, confira algumas outras mudanças que implementamos:
- Adicionar contabilidade para melhorar os tempos de compilação em ~0,6 a 1,6%.
- Computar dados lentamente para evitar ciclos, se possível.
- Refatorar nosso código para pular o trabalho de pré-computação quando ele não for usado.
- Evitar algumas cadeias de carregamento dependentes quando o alocador puder ser facilmente obtido de outros lugares.
- Outro caso de adição de uma verificação para evitar trabalhos desnecessários.
- Evitar ramificações frequentes no tipo de registro (núcleo/FP) no alocador de registro.
- Verificar se algumas matrizes são inicializadas no tempo de compilação. Não confie no clang para fazer isso.
- Limpar alguns loops. Usar loops de intervalo que o clang pode otimizar melhor porque não precisa recarregar os ponteiros internos do contêiner devido a efeitos colaterais do loop. Evitar chamar a função virtual `HInstruction::GetInputRecords()` no loop usando o `InputAt(.)` incorporado para cada entrada.
- Evitar funções Accept() para o padrão de visitante, aproveitando uma otimização do compilador.
Conclusão
Nossa dedicação a melhorar a velocidade do tempo de compilação do ART gerou melhorias significativas, tornando o Android mais fluido e eficiente, além de contribuir para uma melhor duração da bateria e temperatura do dispositivo. Ao identificar e implementar otimizações com diligência, demonstramos que é possível obter ganhos substanciais no tempo de compilação sem comprometer o uso de memória ou a qualidade do código.
Nossa jornada envolveu a criação de perfis com ferramentas como o pprof, a disposição para iterar e, às vezes, até mesmo abandonar caminhos menos frutíferos. Os esforços coletivos da equipe do ART não apenas reduziram o tempo de compilação em uma porcentagem notável, mas também estabeleceram as bases para avanços futuros.
Todas essas melhorias estão disponíveis na atualização de fim de ano do Android de 2025 e para o Android 12 e versões mais recentes por meio de atualizações principais. Esperamos que essa análise detalhada do nosso processo de otimização ofereça insights valiosos sobre as complexidades e recompensas da engenharia de compiladores.
-

 Novidades sobre produtos
Novidades sobre produtosEm março, apresentamos o Android Bench, nosso ranking de LLMs para tarefas de desenvolvimento do Android no mundo real. Desde então, aprimoramos o benchmark com base no seu feedback, incluindo a avaliação de modelos de peso aberto e a adição de dimensões de custo e eficiência ao ranking.
Zoe Lopez-Latorre • Leitura de 3 minutos -

 Novidades sobre produtos
Novidades sobre produtosNo Google Play, temos o compromisso de oferecer a melhor experiência possível aos usuários, além de garantir que os desenvolvedores tenham as ferramentas e a adaptabilidade necessárias para conquistar o sucesso.
Paul Feng • Leitura de 3 minutos -

 Novidades sobre produtos
Novidades sobre produtosNo ano passado, apresentamos a verificação de desenvolvedor Android para fortalecer a segurança do ecossistema e impedir que usuários maliciosos se escondam no anonimato para lançar apps prejudiciais.
Matthew Forsythe • Leitura de 2 minutos
Receba os insights mais recentes sobre o desenvolvimento do Android na sua caixa de entrada semanalmente.
