


Il team di Android Runtime (ART) ha ridotto il tempo di compilazione del 18% senza compromettere il codice compilato o eventuali regressioni della memoria di picco. Questo miglioramento fa parte della nostra iniziativa del 2025 per migliorare il tempo di compilazione senza sacrificare la memoria utilizzata o la qualità del codice compilato.
L'ottimizzazione della velocità di compilazione è fondamentale per ART. Ad esempio, quando si esegue la compilazione just-in-time (JIT), influisce direttamente sull'efficienza delle applicazioni e sul rendimento complessivo del dispositivo. Le compilazioni più rapide riducono il tempo prima che le ottimizzazioni entrino in vigore, offrendo un'esperienza utente più fluida e reattiva. Inoltre, sia per JIT che per ahead-of-time (AOT), i miglioramenti della velocità di compilazione si traducono in un consumo di risorse ridotto durante il processo di compilazione, a vantaggio della durata della batteria e della temperatura del dispositivo, soprattutto sui dispositivi di fascia bassa.
Alcuni di questi miglioramenti della velocità di compilazione sono stati lanciati nella release di Android di giugno 2025, mentre gli altri saranno disponibili nella release di fine anno di Android. Inoltre, tutti gli utenti Android con versioni 12 e successive sono idonei a ricevere questi miglioramenti tramite gli aggiornamenti mainline.
Ottimizzazione del compilatore di ottimizzazione
L'ottimizzazione di un compilatore è sempre un gioco di compromessi. Non puoi semplicemente ottenere velocità senza costi, devi rinunciare a qualcosa. Ci siamo posti un obiettivo molto chiaro e impegnativo: rendere il compilatore più veloce, ma senza introdurre regressioni della memoria e, soprattutto, senza compromettere la qualità del codice che produce. Se il compilatore è più veloce, ma le app vengono eseguite più lentamente, abbiamo fallito.
L'unica risorsa che eravamo disposti a spendere era il nostro tempo di sviluppo per approfondire, indagare e trovare soluzioni intelligenti che soddisfacessero questi criteri rigorosi. Diamo un'occhiata più da vicino a come lavoriamo per trovare le aree di miglioramento e le soluzioni giuste ai vari problemi.
Trovare possibili ottimizzazioni utili
Prima di poter iniziare a ottimizzare una metrica, devi essere in grado di misurarla. In caso contrario, non potrai mai essere certo di averla migliorata o meno. Fortunatamente per noi, la velocità di compilazione è abbastanza coerente, a condizione che tu prenda alcune precauzioni, ad esempio utilizzare lo stesso dispositivo che utilizzi per la misurazione prima e dopo una modifica e assicurarti di non limitare la temperatura del dispositivo. Inoltre, disponiamo anche di misurazioni deterministiche, come le statistiche del compilatore, che ci aiutano a capire cosa succede sotto il cofano.
Poiché la risorsa che stavamo sacrificando per questi miglioramenti era il nostro tempo di sviluppo, volevamo essere in grado di eseguire l'iterazione il più rapidamente possibile. Ciò significava che abbiamo preso una manciata di app rappresentative (un mix di app proprietarie, app di terze parti e lo stesso sistema operativo Android) per creare prototipi di soluzioni. In seguito, abbiamo verificato che l'implementazione finale valesse la pena con test manuali e automatici su larga scala.
Con questo set di APK selezionati manualmente, abbiamo attivato una compilazione manuale in locale, abbiamo ottenuto un profilo della compilazione e abbiamo utilizzato pprof per visualizzare dove stavamo spendendo il nostro tempo.
Esempio di grafico a fiamme di un profilo in pprof
Lo strumento pprof è molto potente e ci consente di suddividere, filtrare e ordinare i dati per vedere, ad esempio, quali fasi o metodi del compilatore richiedono la maggior parte del tempo. Non entreremo nei dettagli di pprof, ma sappi che se la barra è più grande significa che la compilazione ha richiesto più tempo.
Una di queste visualizzazioni è quella "dal basso verso l'alto", in cui puoi vedere quali metodi richiedono la maggior parte del tempo. Nell'immagine riportata di seguito è possibile vedere un metodo denominato Kill, che rappresenta oltre l'1% del tempo di compilazione. Alcuni degli altri metodi principali verranno trattati più avanti nel post del blog.
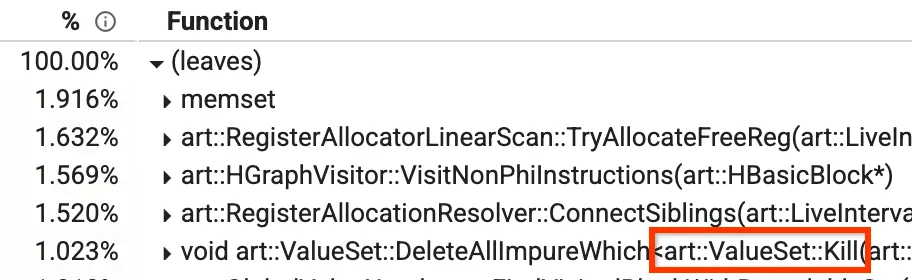
Visualizzazione dal basso verso l'alto di un profilo
Nel nostro compilatore di ottimizzazione, esiste una fase denominata Global Value Numbering (GVN). Non devi preoccuparti di cosa fa nel complesso, ma la parte pertinente è sapere che ha un metodo chiamato `Kill` che elimina alcuni nodi in base a un filtro. Questa operazione richiede tempo perché deve eseguire l'iterazione di tutti i nodi e controllarli uno per uno. Abbiamo notato che in alcuni casi sappiamo in anticipo che il controllo sarà falso, indipendentemente dai nodi attivi a quel punto. In questi casi, possiamo saltare completamente l'iterazione, portandola dall'1,023% a circa lo 0,3% e migliorando il runtime di GVN di circa il 15%.
Implementazione di ottimizzazioni utili
Abbiamo visto come misurare e rilevare dove viene speso il tempo, ma questo è solo l'inizio. Il passaggio successivo consiste nell'ottimizzare il tempo impiegato per la compilazione.
In genere, in un caso come quello di `Kill` sopra, esaminiamo il modo in cui eseguiamo l'iterazione dei nodi e lo facciamo più velocemente, ad esempio eseguendo le operazioni in parallelo o migliorando l'algoritmo stesso. In realtà, è quello che abbiamo provato all'inizio e solo quando non siamo riusciti a trovare nulla da fare abbiamo avuto un momento di "Aspetta un attimo…" e abbiamo capito che la soluzione era (in alcuni casi) non eseguire l'iterazione affatto. Quando si eseguono questo tipo di ottimizzazioni, è facile non vedere la foresta per gli alberi.
In altri casi, abbiamo utilizzato una serie di tecniche diverse, tra cui:
- Utilizzo di euristiche per decidere se un'ottimizzazione non produrrà risultati utili e quindi può essere saltata
- Utilizzo di strutture di dati aggiuntive per memorizzare nella cache i dati calcolati
- Modifica delle strutture di dati attuali per ottenere un aumento della velocità
- Calcolo pigro dei risultati per evitare cicli in alcuni casi
- Utilizzo dell'astrazione corretta: le funzionalità non necessarie possono rallentare il codice
- Evitare di seguire un puntatore utilizzato di frequente tramite molti caricamenti
Come facciamo a sapere se le ottimizzazioni meritano di essere perseguite?
La parte interessante è che non lo fai. Dopo aver rilevato che un'area consuma molto tempo di compilazione e dopo aver dedicato tempo di sviluppo per cercare di migliorarla, a volte non è possibile trovare una soluzione. Forse non c'è nulla da fare, l'implementazione richiederà troppo tempo, un'altra metrica regredirà in modo significativo, la complessità della base di codice aumenterà e così via. Per ogni ottimizzazione riuscita che puoi vedere in questo post del blog, sappi che ce ne sono innumerevoli altre che non sono andate a buon fine.
Se ti trovi in una situazione simile, prova a stimare quanto migliorerai la metrica svolgendo il minor lavoro possibile. Ciò significa, in ordine:
- Stima con una metrica che hai già raccolto o semplicemente con un'intuizione
- Stima con un prototipo rapido e approssimativo
- Implementa una soluzione.
Non dimenticare di stimare gli svantaggi della tua soluzione. Ad esempio, se intendi utilizzare strutture di dati aggiuntive, quanta memoria sei disposto a utilizzare?
Approfondimenti
Senza ulteriori indugi, diamo un'occhiata ad alcune delle modifiche che abbiamo implementato.
Abbiamo implementato una modifica per ottimizzare un metodo denominato FindReferenceInfoOf. Questo metodo eseguiva una ricerca lineare di un vettore per trovare una voce. Abbiamo aggiornato questa struttura di dati in modo che sia indicizzata dall'ID dell'istruzione, in modo che FindReferenceInfoOf sia O(1) anziché O(n). Inoltre, abbiamo preallocato il vettore per evitare il ridimensionamento. Abbiamo aumentato leggermente la memoria perché abbiamo dovuto aggiungere un campo aggiuntivo che contava il numero di voci inserite nel vettore, ma è stato un piccolo sacrificio da fare perché la memoria di picco non è aumentata. In questo modo, la fase LoadStoreAnalysis è stata velocizzata del 34-66%, il che a sua volta comporta un miglioramento del tempo di compilazione di circa lo 0,5-1,8%.
Abbiamo un'implementazione personalizzata di HashSet che utilizziamo in diversi punti. La creazione di questa struttura di dati richiedeva una quantità di tempo considerevole e abbiamo scoperto il perché. Molti anni fa, questa struttura di dati veniva utilizzata solo in pochi punti che utilizzavano HashSet molto grandi ed è stata modificata per essere ottimizzata per questo. Tuttavia, al giorno d'oggi veniva utilizzata nella direzione opposta, con solo poche voci e una durata breve. Ciò significava che stavamo sprecando cicli creando questo enorme HashSet, ma lo abbiamo utilizzato solo per poche voci prima di eliminarlo. Con questa modifica, abbiamo migliorato il tempo di compilazione di circa l'1,3-2%. Come vantaggio aggiuntivo, la memoria utilizzata è diminuita di circa lo 0,5-1% perché non utilizzavamo strutture di dati così grandi come prima.
Abbiamo migliorato il tempo di compilazione di circa lo 0,5-1% passando le strutture di dati per riferimento alla lambda per evitare di copiarle. Questo è stato un errore nella revisione originale ed è rimasto nella nostra base di codice per anni. Grazie all'esame dei profili in pprof, abbiamo notato che questi metodi creavano ed eliminavano molte strutture di dati, il che ci ha portato a esaminarli e ottimizzarli.
Abbiamo velocizzato la fase di scrittura dell'output compilato memorizzando nella cache i valori calcolati, il che si è tradotto in un miglioramento del tempo di compilazione totale di circa l'1,3-2,8%. Purtroppo, la contabilità aggiuntiva era eccessiva e i nostri test automatici ci hanno avvisato della regressione della memoria. In seguito, abbiamo esaminato di nuovo lo stesso codice e abbiamo implementato una nuova versione che non solo ha risolto la regressione della memoria, ma ha anche migliorato il tempo di compilazione di un ulteriore 0,5-1,8%. In questa seconda modifica, abbiamo dovuto eseguire il refactoring e ripensare il funzionamento di questa fase per eliminare una delle due strutture di dati.
Nel nostro compilatore di ottimizzazione, esiste una fase che esegue l'inlining delle chiamate di funzione per ottenere un rendimento migliore. Per scegliere i metodi da inlining, utilizziamo sia le euristiche prima di eseguire qualsiasi calcolo sia i controlli finali dopo aver eseguito il lavoro, ma prima di finalizzare l'inlining. Se uno di questi rileva che l'inlining non vale la pena (ad esempio, verranno aggiunte troppe nuove istruzioni), non eseguiamo l'inlining della chiamata al metodo.
Abbiamo spostato due controlli dalla categoria "controlli finali" alla categoria "euristica" per stimare se un inlining avrà esito positivo o meno prima di eseguire qualsiasi calcolo che richieda molto tempo. Poiché si tratta di una stima, non è perfetta, ma abbiamo verificato che le nostre nuove euristiche coprano il 99,9% di ciò che è stato inlining in precedenza senza influire sul rendimento. Una di queste nuove euristiche riguardava i registri DEX necessari (miglioramento di circa lo 0,2-1,3%), mentre l'altra riguardava il numero di istruzioni (miglioramento di circa il 2%).
Abbiamo un'implementazione personalizzata di BitVector che utilizziamo in diversi punti. Abbiamo sostituito la classe BitVector ridimensionabile con un BitVectorView più semplice per determinati vettori di bit di dimensioni fisse. In questo modo si eliminano alcune indirezioni e controlli dell'intervallo di runtime e si velocizza la creazione degli oggetti vettoriali di bit.
Inoltre, la classe BitVectorView è stata modellata sul tipo di archiviazione sottostante (anziché utilizzare sempre uint32_t come il vecchio BitVector). In questo modo, alcune operazioni, ad esempio Union(), possono elaborare il doppio dei bit contemporaneamente sulle piattaforme a 64 bit. I campioni delle funzioni interessate sono stati ridotti di oltre l'1% in totale durante la compilazione del sistema operativo Android. Questa operazione è stata eseguita in diverse modifiche [1, 2, 3, 4, 5, 6]
Se parlassimo in dettaglio di tutte le ottimizzazioni, saremmo qui tutto il giorno. Se ti interessano altre ottimizzazioni, dai un'occhiata ad alcune altre modifiche che abbiamo implementato:
- Aggiungi la contabilità per migliorare i tempi di compilazione di circa lo 0,6-1,6%.
- Calcola i dati in modo pigro per evitare cicli, se possibile.
- Esegui il refactoring del codice per saltare il lavoro di precalcolo quando non verrà utilizzato.
- Evita alcune catene di caricamento dipendenti quando l'allocatore può essere ottenuto facilmente da altri punti.
- Un altro caso di aggiunta di un controllo per evitare lavoro non necessario.
- Evita ramificazioni frequenti sul tipo di registro (core/FP) nell'allocatore di registri.
- Assicurati che alcuni array vengano inizializzati in fase di compilazione. Non fare affidamento su clang per farlo.
- Libera spazio da alcuni loop. Utilizza loop di intervallo che clang può ottimizzare meglio perché non ha bisogno di ricaricare i puntatori interni del container a causa degli effetti collaterali del loop. Evita di chiamare la funzione virtuale `HInstruction::GetInputRecords()` nel loop tramite `InputAt(.)` inlining per ogni input.
- Evita le funzioni Accept() per il pattern visitor sfruttando un'ottimizzazione del compilatore.
Conclusione
Il nostro impegno per migliorare la velocità di compilazione di ART ha prodotto miglioramenti significativi, rendendo Android più fluido ed efficiente e contribuendo al contempo a una migliore durata della batteria e temperatura del dispositivo. Identificando e implementando diligentemente le ottimizzazioni, abbiamo dimostrato che è possibile ottenere miglioramenti significativi del tempo di compilazione senza compromettere la memoria utilizzata o la qualità del codice.
Il nostro percorso ha comportato la profilazione con strumenti come pprof, la volontà di eseguire l'iterazione e, a volte, persino l'abbandono di strade meno fruttuose. Gli sforzi collettivi del team di ART non solo hanno ridotto il tempo di compilazione di una percentuale notevole, ma hanno anche gettato le basi per i futuri progressi.
Tutti questi miglioramenti sono disponibili nell'aggiornamento di Android di fine anno 2025 e per Android 12 e versioni successive tramite gli aggiornamenti mainline. Ci auguriamo che questo approfondimento sul nostro processo di ottimizzazione fornisca informazioni preziose sulle complessità e sui vantaggi dell'ingegneria del compilatore.
Scritto da:
Continua a leggere
-


Notizie sui prodotti
Siamo felici di annunciare che è arrivato il supporto ufficiale per Unreal Engine e Godot per Android XR. Stiamo anche lanciando nuovi strumenti progettati per aumentare la produttività e abilitare nuove funzionalità XR: Android XR Engine Hub e Android XR Interaction Framework.
Luke Hopkins • Lettura di 4 minuti
-


Notizie sui prodotti
Con il rilascio di Android 17, stiamo passando a uno standard di sviluppo adattivo. Gli utenti non si affidano più a un singolo fattore di forma, ma passano da smartphone, dispositivi pieghevoli, tablet, laptop, display per auto e ambienti XR immersivi durante la giornata.
Fahd Imtiaz • Lettura di 4 minuti
-


Notizie sui prodotti
Siamo felici di condividere le funzionalità di Google TV e gli strumenti per sviluppatori progettati per aumentare la rilevabilità dei tuoi contenuti e preparare la tua app per le future esperienze TV.
Paul Lammertsma • Lettura di 4 minuti
Resta al passo con le novità
Ricevi settimanalmente nella tua casella di posta gli ultimi approfondimenti sullo sviluppo di Android.
