
「Flow」はコルーチンの一種で、返す値が 1 個のみの「suspend 関数」とは異なり、複数の値を順次出力できます。たとえば、データベースからリアルタイムで更新情報を受け取るような場合に使用できます。
Flow はコルーチンの上に作成され、複数の値を提供できます。非同期に処理を行える「データ ストリーム」と考えることもできます。ここで、出力する値はすべて同じ型である必要があります。たとえば、Flow<Int> は整数型の値を出力する Flow です。
Flow は、一連の値を生成する Iterator とよく似ていますが、suspend 関数を使うことで新しい値を非同期に生成して使用します。つまり Flow を使用すれば、メインスレッドをブロックすることなく、安全にネットワーク リクエストを行って後続の値を生成するといったことができます。
データ ストリームには、以下の 3 つのエンティティがあります。
- プロデューサ: ストリームに出力するデータを生成します。コルーチンであるため、Flow は非同期にデータを生成できます。
- (必要な場合)インターミディアリ: ストリームに出力された各値またはストリームそのものを変更できます。
- コンシューマ: ストリームから得られた値を使用します。
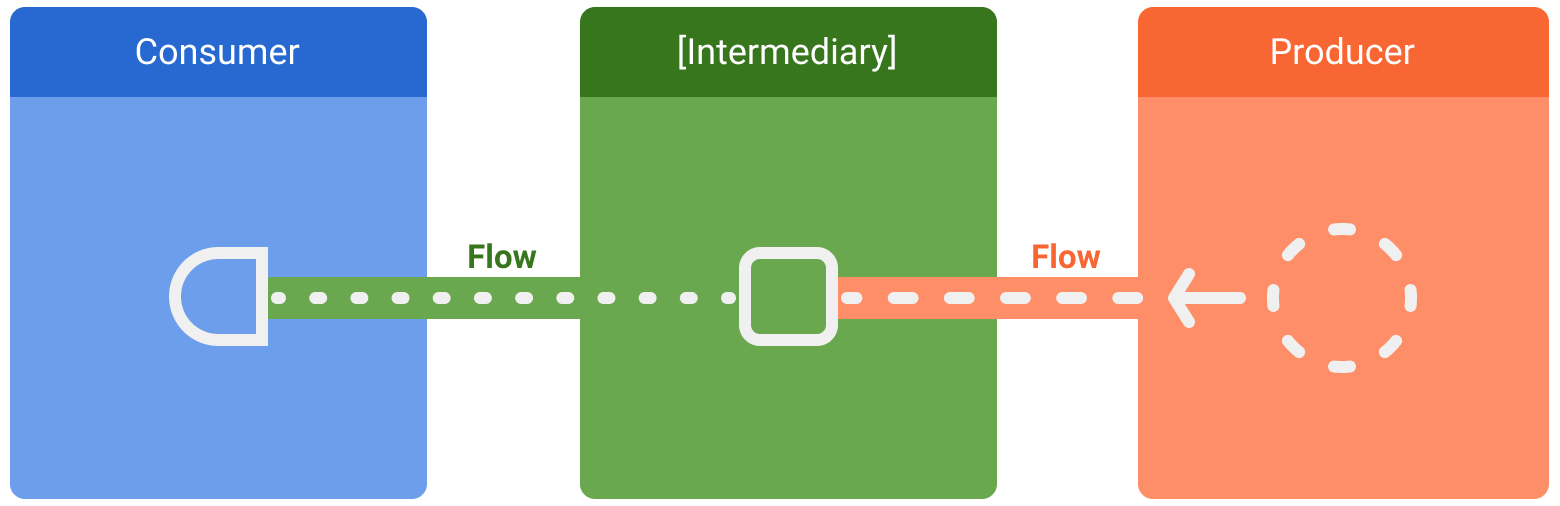
Android の場合、通常は「リポジトリ」が UI データのプロデューサで、最終的にデータを表示するユーザー インターフェース(UI)を備えています。また、UI レイヤがユーザー入力イベントのプロデューサとなり、その他のレイヤがコンシューマになる場合もあります。プロデューサとコンシューマの間のレイヤは通常、後続レイヤの要件に合わせてデータ ストリームを変更するインターミディアリとして機能します。
Flow の作成
フローを作成するには、フロービルダー API を使用します。flow ビルダー関数は新しい Flow を作成します。手動でデータ ストリームに新しい値を出力するには、emit 関数を使用します。
次の例では、データソースが最新のニュースを一定間隔で自動的に取得します。suspend 関数は複数の値を続けて返せないため、データソースはそれが可能な Flow を作成して返します。ここでは、データソースがプロデューサの役割を果たしています。
class NewsRemoteDataSource( private val newsApi: NewsApi, private val refreshIntervalMs: Long = 5000 ) { val latestNews: Flow<List<ArticleHeadline>> = flow { while (true) { val latestNews = newsApi.fetchLatestNews() emit(latestNews) // Emits the result of the request to the flow delay(refreshIntervalMs) // Suspends the coroutine for some time } } } // Interface that provides a way to make network requests with suspend functions interface NewsApi { suspend fun fetchLatestNews(): List<ArticleHeadline> }
flow ビルダーは、コルーチン内で実行されます。したがって、同じ非同期 API を使用するとメリットがありますが、いくつかの制限があります。
- Flow は「直列」に処理されます。プロデューサはコルーチン内にあるため、suspend 関数を呼び出すと、それが戻るまで停止します。この例では、プロデューサは
fetchLatestNewsネットワーク リクエストが完了するまで停止します。リクエストが完了したときにのみ、結果がストリームに出力されます。 flowビルダーを使用して、プロデューサが別のCoroutineContextから値をemitすることはできません。したがって、新しいコルーチンを作成したり、withContextコードブロックを使用したりすることで、別のCoroutineContextでemitを呼び出さないでください。このようなケースには、callbackFlowなどの他の Flow ビルダーを使用します。
ストリームの変更
インターミディアリは中間演算子を使うことで、値を使用することなくデータ ストリームを変更できます。この演算子は、データ ストリームに一連のオペレーションを設定する関数ですが、そのオペレーションは値を使用するときまで実行されません。中間演算子について詳しくは、Flow のリファレンス ドキュメントをご覧ください。
次の例では、リポジトリ レイヤで中間演算子 map を使用してデータを View に表示するための変換を行っています。
class NewsRepository( private val newsRemoteDataSource: NewsRemoteDataSource, private val userData: UserData ) { /** * Returns the favorite latest news applying transformations on the flow. * These operations are lazy and don't trigger the flow. They just transform * the current value emitted by the flow at that point in time. */ val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews // Intermediate operation to filter the list of favorite topics .map { news -> news.filter { userData.isFavoriteTopic(it) } } // Intermediate operation to save the latest news in the cache .onEach { news -> saveInCache(news) } }
中間演算子を順次適用して、アイテムが Flow に出力された場合に遅延実行される一連のオペレーションを形成できます。なお、中間演算子をストリームに適用するだけでは、Flow の収集は開始されません。
Flow からの収集
Flow をトリガーして値のリッスンを開始するには、末端演算子を使用します。ストリーム内のすべての値を出力されたとおりに収集するには、collect を使用します。末端演算子について詳しくは、Flow の公式ドキュメントをご覧ください。
collect は suspend 関数であるため、コルーチン内で実行する必要があります。パラメータとしてラムダを取り、これは新しい値ごとに呼び出されます。また、suspend 関数であるため、collect を呼び出すコルーチンは Flow が終了するまで停止することがあります。
上記の例の続きとして、リポジトリ レイヤからのデータを使用する ViewModel の簡単な実装例を次に示します。
class LatestNewsViewModel( private val newsRepository: NewsRepository ) : ViewModel() { init { viewModelScope.launch { // Trigger the flow and consume its elements using collect newsRepository.favoriteLatestNews.collect { favoriteNews -> // Update UI with the latest favorite news } } } }
Flow を収集するとプロデューサがトリガーされ、一定間隔で最新ニュースを更新してネットワーク リクエストの結果を出力します。プロデューサは while(true) ループで常にアクティブなため、データ ストリームが終了するのは ViewModel がクリアされて viewModelScope がキャンセルされたときです。
Flow の収集は、次の場合に停止する可能性があります。
- 上記の例に示したように、収集中のコルーチンをキャンセルした場合。これにより、収集元のプロデューサも停止します。
- プロデューサがアイテムの出力を終了した場合。この場合はデータ ストリームが終了し、
collectを呼び出したコルーチンが実行を再開します。
他の中間演算子で指定しない限り、Flow は「コールド」かつ「遅延」となります。つまり、Flow の末端演算子が呼び出されるたびにプロデューサ コードが実行されることになります。上記の例では、複数の Flow コレクタがあると、データソースによる一定間隔での最新ニュース取得がさまざまなタイミングで行われます。複数のコンシューマが同時に収集を行う Flow を最適化して共有するには、shareIn 演算子を使用します。
予期しない例外のキャッチ
プロデューサの実装は、サードパーティ ライブラリのものである場合があります。つまり、予期しない例外がスローされる可能性があります。このような例外を処理するには、catch 中間演算子を使用します。
class LatestNewsViewModel( private val newsRepository: NewsRepository ) : ViewModel() { init { viewModelScope.launch { newsRepository.favoriteLatestNews // Intermediate catch operator. If an exception is thrown, // catch and update the UI .catch { exception -> notifyError(exception) } .collect { favoriteNews -> // Update UI with the latest favorite news } } } }
上記の例では、例外が発生した場合、新しいアイテムをまだ受け取っていないため、collect ラムダは呼び出されません。
catch を使用してアイテムを Flow に emit することもできます。次の例のリポジトリ レイヤは、代わりにキャッシュに保存された値を emit します。
class NewsRepository( // ... ) { val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews .map { news -> news.filter { userData.isFavoriteTopic(it) } } .onEach { news -> saveInCache(news) } // If an error happens, emit the last cached values .catch { exception -> emit(lastCachedNews()) } }
この例では、例外が発生すると、それにより新しいアイテムがストリームに出力されて、collect ラムダが呼び出されます。
別の CoroutineContext での実行
デフォルトでは、flow ビルダーのプロデューサは収集を行うコルーチンの CoroutineContext で実行され、前述のとおり、別の CoroutineContext から値を emit することはできません。ただ、これが適切でない場合もあります。たとえば、このトピック全体を通して使用している例では、リポジトリ レイヤは、viewModelScope が使用する Dispatchers.Main でオペレーションを実行しません。
Flow の CoroutineContext を変更するには、中間演算子 flowOn を使用します。flowOn は、「アップストリーム Flow」(つまり、flowOn の「前または上位」に適用されるプロデューサとすべての中間演算子)の CoroutineContext を変更します。「ダウンストリーム Flow」(flowOn の「後」の中間演算子およびコンシューマ)は影響を受けず、その Flow からの collect に使用される CoroutineContext で実行されます。flowOn 演算子が複数ある場合は、それぞれが現在の場所から見たアップストリームを変更します。
class NewsRepository( private val newsRemoteDataSource: NewsRemoteDataSource, private val userData: UserData, private val defaultDispatcher: CoroutineDispatcher ) { val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews .map { news -> // Executes on the default dispatcher news.filter { userData.isFavoriteTopic(it) } } .onEach { news -> // Executes on the default dispatcher saveInCache(news) } // flowOn affects the upstream flow ↑ .flowOn(defaultDispatcher) // the downstream flow ↓ is not affected .catch { exception -> // Executes in the consumer's context emit(lastCachedNews()) } }
このコードでは、onEach 演算子と map 演算子は defaultDispatcher を使用しますが、catch 演算子とコンシューマは viewModelScope が使用する Dispatchers.Main で実行されます。
データソース レイヤは I/O オペレーションを行うため、次のようにして I/O オペレーションに最適化されたディスパッチャを使用します。
class NewsRemoteDataSource( // ... private val ioDispatcher: CoroutineDispatcher ) { val latestNews: Flow<List<ArticleHeadline>> = flow { // Executes on the IO dispatcher // ... } .flowOn(ioDispatcher) }
Jetpack ライブラリの Flow
Flow は多くの Jetpack ライブラリと統合されており、Android サードパーティ ライブラリでも広く使用されています。Flow は、リアルタイムのデータ更新やエンドレスのデータ ストリームに適しています。
Room と Flow を使用して、データベース内の変更について通知を受け取ることができます。データアクセス オブジェクト(DAO)を使用する場合は、Flow 型を返すことでリアルタイムに更新データを取得できます。
@Dao abstract class ExampleDao { @Query("SELECT * FROM Example") abstract fun getExamples(): Flow<List<Example>> }
Example テーブルが変更されるたびに、データベース内の新しいアイテムを含む新しいリストが出力されます。
コールバックベースの API を Flow に変換する
callbackFlow は、コールバックベースの API を Flow に変換できる Flow ビルダーです。たとえば、コールバックを使用する Firebase Firestore Android API があります。
次のコードを使用すると、この API を Flow に変換して Firestore データベースの更新をリッスンできます。
class FirestoreUserEventsDataSource(
private val firestore: FirebaseFirestore
) {
// Method to get user events from the Firestore database
fun getUserEvents(): Flow<UserEvents> = callbackFlow {
// Reference to use in Firestore
var eventsCollection: CollectionReference? = null
try {
eventsCollection = FirebaseFirestore.getInstance()
.collection("collection")
.document("app")
} catch (e: Throwable) {
// If Firebase cannot be initialized, close the stream of data
// flow consumers will stop collecting and the coroutine will resume
close(e)
}
// Registers callback to firestore, which will be called on new events
val subscription = eventsCollection?.addSnapshotListener { snapshot, _ ->
if (snapshot == null) { return@addSnapshotListener }
// Sends events to the flow! Consumers will get the new events
try {
trySend(snapshot.getEvents())
} catch (e: Throwable) {
// Event couldn't be sent to the flow
}
}
// The callback inside awaitClose will be executed when the flow is
// either closed or cancelled.
// In this case, remove the callback from Firestore
awaitClose { subscription?.remove() }
}
}
flow ビルダーとは異なり、callbackFlow を使用すると、send 関数を使用して別の CoroutineContext から、または trySend 関数を使用してコルーチンの外部から値を出力できます。
内部的には、callbackFlow はチャネルを使用します。これは、ブロッキング キューと概念的によく似ています。
チャネルの設定には「容量」を使用しますが、これはバッファリングできる要素の最大数です。callbackFlow で作成されるチャネルのデフォルトの容量は 64 要素です。空きのないチャネルに要素を追加しようとした場合、send はプロデューサを停止して空きができるまで待ちますが、trySend は要素をチャネルに追加せずにすぐ false を返します。
trySend は、容量制限に違反しない場合にのみ、指定された要素をチャネルにすぐに追加し、成功結果を返します。