
이 Codelab에서는 LiveData 빌더를 사용하여 Android 앱에서 Kotlin 코루틴과 LiveData를 결합하는 방법을 알아봅니다. 또한 값의 비동기 시퀀스(또는 스트림)를 나타내는 코루틴 라이브러리의 한 유형인 코루틴 비동기 Flow를 사용하여 동일하게 구현합니다.
Android 아키텍처 구성요소를 사용해 빌드된 기존 앱으로 시작합니다. 이 구성요소는 LiveData를 사용하여 Room 데이터베이스의 객체 목록을 가져와 RecyclerView 그리드 레이아웃에 표시합니다.
실행할 작업에 관한 코드 스니펫은 아래와 같습니다. 다음은 Room 데이터베이스를 쿼리하는 기존 코드입니다.
val plants: LiveData<List<Plant>> = plantDao.getPlants()
추가 정렬 로직과 함께 LiveData 빌더와 코루틴을 사용하여 LiveData가 업데이트됩니다.
val plants: LiveData<List<Plant>> = liveData<List<Plant>> {
val plantsLiveData = plantDao.getPlants()
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsLiveData.map { plantList -> plantList.applySort(customSortOrder) })
}
Flow로도 동일한 로직을 구현합니다.
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
.flowOn(defaultDispatcher)
.conflate()
기본 요건
ViewModel,LiveData,Repository,Room아키텍처 구성요소 사용 경험- 확장 함수 및 람다를 포함한 Kotlin 구문 사용 경험
- Kotlin 코루틴 사용 경험
- Android에서 기본 스레드, 백그라운드 스레드, 콜백을 비롯한 스레드를 사용하는 방법에 관한 기본적인 이해
실행할 작업
- Kotlin 코루틴에 적합한
LiveData빌더를 사용하도록 기존LiveData변환 LiveData빌더에서 로직 추가- 비동기 작업에
Flow사용 Flows를 결합하고 여러 비동기 소스 변환Flows를 사용하여 동시 실행 제어LiveData와Flow.중에서 선택하는 방법 알아보기
필요한 항목
- Android 스튜디오 4.1 이상. 다른 버전에서도 이 Codelab이 작동할 수 있지만 일부 내용이 누락되거나 다르게 표시될 수도 있습니다.
이 Codelab을 진행하는 동안 코드 버그, 문법 오류, 불명확한 문구 등의 문제가 발생하면 Codelab 왼쪽 하단에 있는 '오류 신고' 링크를 통해 신고해 주세요.
코드 다운로드
다음 링크를 클릭하여 이 Codelab의 모든 코드를 다운로드합니다.
또는 다음 명령어를 사용하여 명령줄에서 GitHub 저장소를 클론합니다.
$ git clone https://github.com/googlecodelabs/kotlin-coroutines.git
이 Codelab의 코드는 advanced-coroutines-codelab 디렉터리에 있습니다.
자주 묻는 질문(FAQ)
먼저 시작 샘플 앱이 어떤 모습인지 살펴보겠습니다. 다음 안내에 따라 Android 스튜디오에서 샘플 앱을 엽니다.
kotlin-coroutinesZIP 파일을 다운로드한 경우 파일의 압축을 풉니다.- Android 스튜디오에서
advanced-coroutines-codelab디렉터리를 엽니다. - 구성 드롭다운에서
start가 선택되어 있는지 확인합니다. - Run
 버튼을 클릭하고 에뮬레이션된 기기를 선택하거나 Android 기기를 연결합니다. 기기에서 Android Lollipop을 실행해야 합니다(지원되는 최소 SDK는 21).
버튼을 클릭하고 에뮬레이션된 기기를 선택하거나 Android 기기를 연결합니다. 기기에서 Android Lollipop을 실행해야 합니다(지원되는 최소 SDK는 21).
앱이 처음 실행되면 카드 목록이 나타나고 각 카드에는 특정 식물의 이름과 이미지가 표시됩니다.

각 Plant에는 식물이 잘 자랄 가능성이 가장 높은 지역을 나타내는 growZoneNumber 속성이 있습니다. 사용자는 필터 아이콘  을 탭하여 모든 식물과 특정 생장 영역의 식물(영역 9로 하드코딩됨)을 전환하여 표시할 수 있습니다. 필터 버튼을 몇 번 눌러 실제 작동 모습을 확인하세요.
을 탭하여 모든 식물과 특정 생장 영역의 식물(영역 9로 하드코딩됨)을 전환하여 표시할 수 있습니다. 필터 버튼을 몇 번 눌러 실제 작동 모습을 확인하세요.

아키텍처 개요
이 앱은 아키텍처 구성요소를 사용하여 MainActivity 및 PlantListFragment의 UI 코드를 PlantListViewModel의 애플리케이션 로직과 분리합니다. PlantRepository는 ViewModel과 PlantDao 사이를 연결하고 Room 데이터베이스에 액세스하여 Plant 객체 목록을 반환합니다. 그러면 UI가 이 식물 목록을 가져와 RecyclerView 그리드 레이아웃에 표시합니다.
코드 수정을 시작하기 전에 데이터베이스에서 UI로 데이터가 어떻게 흐르는지 간단히 살펴보겠습니다. ViewModel에 식물 목록이 로드되는 방법은 다음과 같습니다.
PlantListViewModel.kt
val plants: LiveData<List<Plant>> = growZone.switchMap { growZone ->
if (growZone == NoGrowZone) {
plantRepository.plants
} else {
plantRepository.getPlantsWithGrowZone(growZone)
}
}
GrowZone은 영역을 나타내는 Int만 포함하는 인라인 클래스입니다. NoGrowZone은 영역이 없음을 나타내며 필터링에만 사용됩니다.
Plant.kt
inline class GrowZone(val number: Int)
val NoGrowZone = GrowZone(-1)
필터 버튼을 탭하면 growZone이 전환됩니다. switchMap을 사용하여 반환할 식물 목록을 결정합니다.
데이터베이스에서 식물 데이터를 가져오는 데 사용하는 저장소 및 데이터 액세스 객체(DAO)는 다음과 같습니다.
PlantDao.kt
@Query("SELECT * FROM plants ORDER BY name")
fun getPlants(): LiveData<List<Plant>>
@Query("SELECT * FROM plants WHERE growZoneNumber = :growZoneNumber ORDER BY name")
fun getPlantsWithGrowZoneNumber(growZoneNumber: Int): LiveData<List<Plant>>
PlantRepository.kt
val plants = plantDao.getPlants()
fun getPlantsWithGrowZone(growZone: GrowZone) =
plantDao.getPlantsWithGrowZoneNumber(growZone.number)
대부분의 코드 수정은 PlantListViewModel과 PlantRepository에서 이루어지지만, 식물의 데이터를 다양한 데이터베이스 계층을 통해 Fragment에 표시하는 방법을 중심으로 프로젝트의 구조를 숙지하는 것이 좋습니다. 다음 단계에서는 LiveData 빌더를 사용하여 맞춤 정렬을 추가하도록 코드를 수정합니다.
식물 목록이 현재 알파벳순으로 표시되지만, 특정 식물을 먼저 나열한 후 나머지를 알파벳순으로 나열하여 이 목록의 순서를 변경하려고 합니다. 쇼핑 앱에서 구매 가능한 상품 목록 상단에 스폰서 검색결과를 표시하는 것과 비슷합니다. 제품팀은 새 버전의 앱을 제공하지 않고도 정렬 순서를 동적으로 변경할 수 있기를 원하므로, 여기서는 식물 목록을 가져와서 백엔드에서 먼저 정렬하겠습니다.
맞춤 정렬이 적용된 앱은 다음과 같습니다.
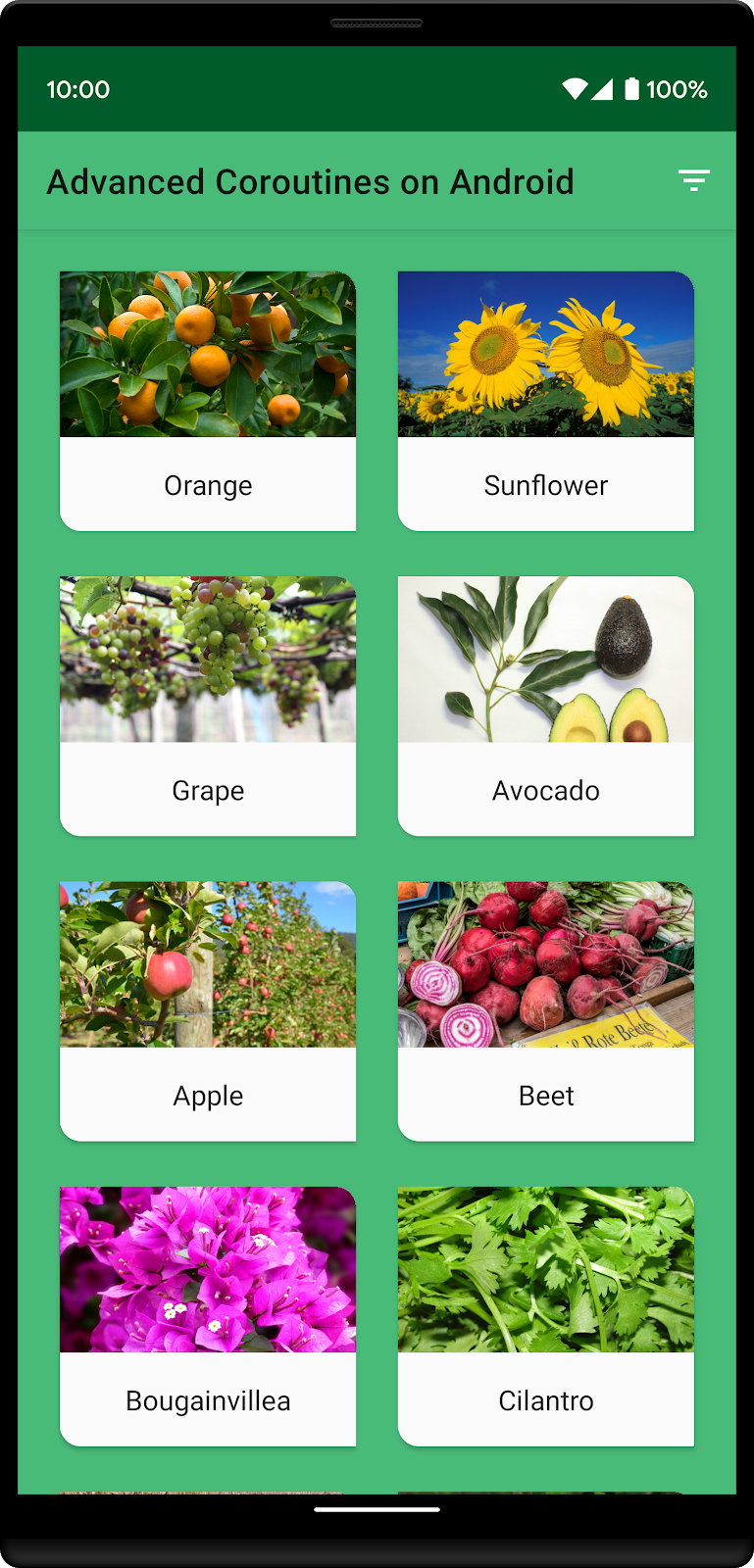
맞춤 정렬 순서의 목록은 오렌지, 해바라기, 포도, 아보카도라는 4가지 식물로 구성됩니다. 목록에서 첫 번째로 나온 식물과 그다음에 알파벳순으로 나머지 식물이 나타나는 방식을 확인해 보세요.
이제 필터 버튼을 누르면(GrowZone 9 식물만 표시됨) GrowZone 9에 속하지 않는 해바라기는 목록에서 사라집니다. 맞춤 정렬 목록의 다른 세 식물은 GrowZone 9에 해당하므로 목록 상단에 남습니다. GrowZone 9에 속한 나머지 식물 하나는 토마토이며 이 목록에서 마지막으로 나타납니다.
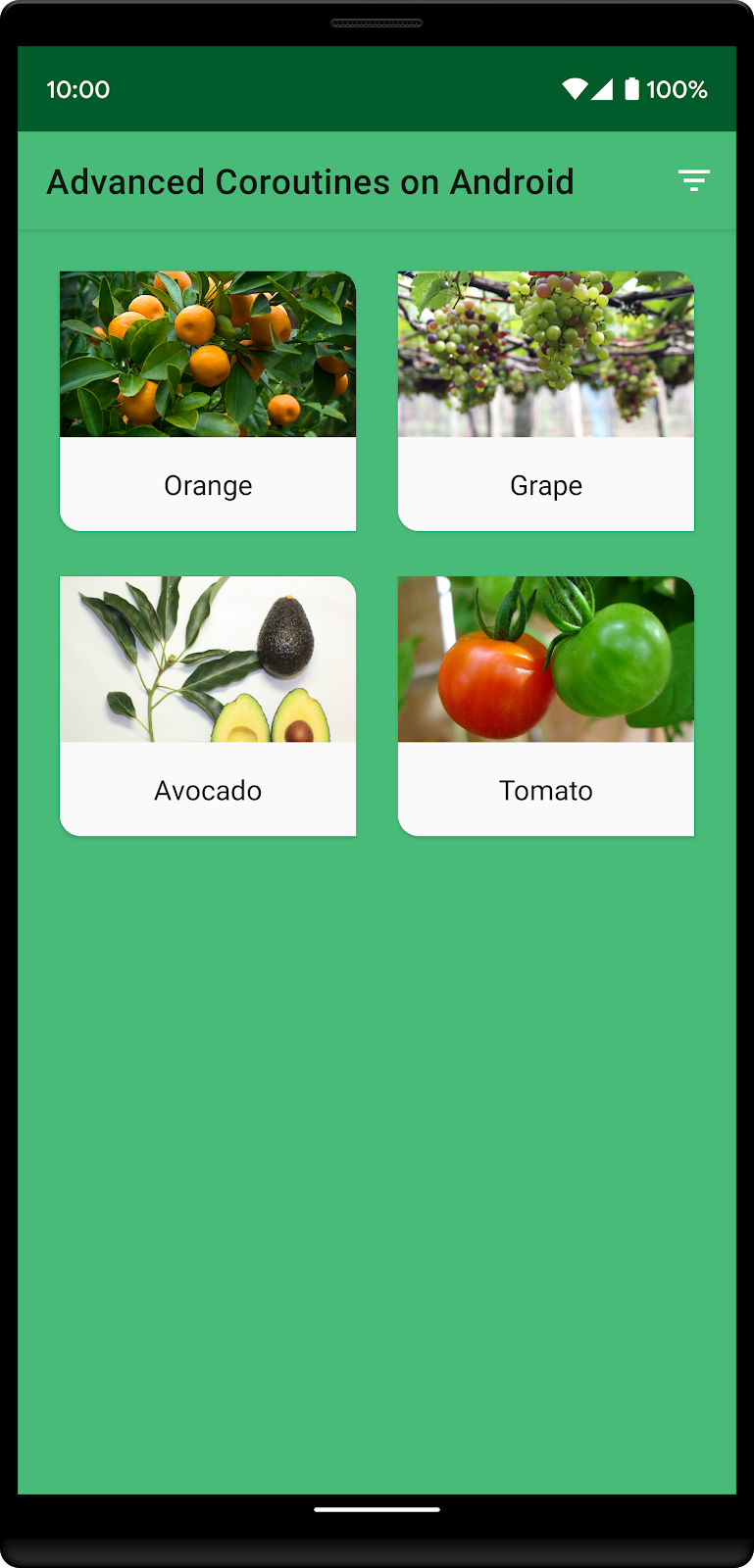
지금부터 맞춤 정렬을 구현하는 코드를 작성해 보겠습니다.
먼저 네트워크에서 맞춤 정렬 순서를 가져와 메모리에 캐시하는 정지 함수를 작성하겠습니다.
다음을 PlantRepository에 추가합니다.
PlantRepository.kt
private var plantsListSortOrderCache =
CacheOnSuccess(onErrorFallback = { listOf<String>() }) {
plantService.customPlantSortOrder()
}
plantsListSortOrderCache는 맞춤 정렬 순서를 위한 메모리 내 캐시로 사용됩니다. 네트워크 오류가 있는 경우 정렬 순서를 가져오지 않았더라도 앱이 데이터를 표시할 수 있도록 빈 목록이 대신 사용됩니다.
이 코드는 sunflower 모듈에 제공된 CacheOnSuccess 유틸리티 클래스를 사용하여 캐싱을 처리합니다. 이와 같은 캐싱 구현의 세부정보를 추상화하면 애플리케이션 코드가 더 간단해질 수 있습니다. CacheOnSuccess는 이미 충분한 테스트를 거쳤으므로, 올바른 동작을 보장하기 위해 저장소의 테스트를 그리 많이 작성할 필요는 없습니다. kotlinx-coroutines를 사용할 때 비슷하게 높은 수준의 추상화를 코드에 도입하는 것이 좋습니다.
이제 식물 목록에 정렬을 적용하는 일부 로직을 통합하겠습니다.
다음을 PlantRepository:에 추가합니다.
PlantRepository.kt
private fun List<Plant>.applySort(customSortOrder: List<String>): List<Plant> {
return sortedBy { plant ->
val positionForItem = customSortOrder.indexOf(plant.plantId).let { order ->
if (order > -1) order else Int.MAX_VALUE
}
ComparablePair(positionForItem, plant.name)
}
}
이 확장 함수는 목록을 다시 정렬하여 customSortOrder에 있는 Plants를 목록 앞부분에 배치합니다.
이제 정렬 로직이 준비되었으므로 아래와 같이 plants 및 getPlantsWithGrowZone의 코드를 LiveData 빌더로 바꿉니다.
PlantRepository.kt
val plants: LiveData<List<Plant>> = liveData<List<Plant>> {
val plantsLiveData = plantDao.getPlants()
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsLiveData.map {
plantList -> plantList.applySort(customSortOrder)
})
}
fun getPlantsWithGrowZone(growZone: GrowZone) = liveData {
val plantsGrowZoneLiveData = plantDao.getPlantsWithGrowZoneNumber(growZone.number)
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsGrowZoneLiveData.map { plantList ->
plantList.applySort(customSortOrder)
})
}
이제 앱을 실행하면 맞춤 정렬된 식물 목록이 표시됩니다.
liveData를 코루틴이 지원하므로 LiveData 빌더를 사용하면 값을 비동기적으로 계산할 수 있습니다. 이 경우에는 데이터베이스에서 식물의 LiveData 목록을 가져오는 정지 함수를 사용하는 동시에 정지 함수를 호출하여 맞춤 정렬 순서를 가져옵니다. 그런 다음 빌더 내에서 이 두 값을 결합하여 식물 목록을 정렬하고 값을 반환합니다.
코루틴이 관찰되면 실행되기 시작하고 코루틴이 성공적으로 완료되거나 데이터베이스 또는 네트워크 호출이 실패하면 실행이 취소됩니다.
다음 단계에서는 Transformation을 사용한 getPlantsWithGrowZone의 변형을 살펴보겠습니다.
이제 각 값이 처리될 때 정지 transform을 구현하도록 PlantRepository를 수정함으로써 LiveData에서 복잡한 비동기 transform을 빌드하는 방법을 알아봅니다. 전제조건으로, 기본 스레드에 안전하게 사용할 수 있는 정렬 알고리즘 버전을 만들어 보겠습니다. withContext를 사용하여 람다 전용의 다른 디스패처로 전환한 후 시작했던 디스패처에서 다시 시작할 수 있습니다.
다음을 PlantRepository에 추가합니다.
PlantRepository.kt
@AnyThread
suspend fun List<Plant>.applyMainSafeSort(customSortOrder: List<String>) =
withContext(defaultDispatcher) {
this@applyMainSafeSort.applySort(customSortOrder)
}
그런 다음 새로운 기본 안전 정렬을 LiveData 빌더에 사용할 수 있습니다. switchMap을 사용하도록 블록을 업데이트합니다. 이렇게 하면 새 값이 수신될 때마다 새 LiveData를 가리키게 됩니다.
PlantRepository.kt
fun getPlantsWithGrowZone(growZone: GrowZone) =
plantDao.getPlantsWithGrowZoneNumber(growZone.number)
.switchMap { plantList ->
liveData {
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emit(plantList.applyMainSafeSort(customSortOrder))
}
}
이전 버전과 비교하면, 네트워크에서 맞춤 정렬 순서가 수신되면 이 순서를 새 기본 안전 applyMainSafeSort와 함께 사용할 수 있습니다. 그런 다음 이 결과는 getPlantsWithGrowZone에 의해 반환된 새 값으로 switchMap에 내보내집니다.
위의 plants LiveData와 유사하게 코루틴은 관찰되면 실행되기 시작하고 완료 시 또는 데이터베이스나 네트워크의 호출이 실패하는 경우 실행이 종료됩니다. 여기서 차이점은 캐시되어 있으므로 매핑에서 네트워크 호출을 실행해도 안전하다는 점입니다.
이제 Flow로 이 코드를 구현하는 방법을 살펴보고 구현을 비교해 봅니다.
kotlinx-coroutines의 Flow를 사용하여 동일한 로직을 작성하겠습니다. 그러기 전에 흐름의 정의 및 앱에 흐름을 통합할 수 있는 방법을 알아보겠습니다.
흐름은 값이 지연 생성되는 컬렉션 유형인 시퀀스의 비동기 버전입니다. 흐름은 시퀀스와 마찬가지로 값이 필요할 때마다 요청 시 각 값을 생성하고, 흐름에 포함할 수 있는 값의 수는 무한합니다.
그렇다면 Kotlin에서 새로운 Flow 유형을 도입한 이유가 무엇이며 이 새 유형은 일반 시퀀스와 어떻게 다를까요? 답은 비동기성의 마법에 있습니다. Flow은 코루틴을 완벽하게 지원합니다. 즉, 코루틴을 사용하여 Flow를 빌드하고 변환하고 사용할 수 있습니다. 동시 실행을 제어할 수도 있습니다. 다시 말해서, Flow를 사용하여 여러 코루틴의 실행을 선언적으로 조정합니다.
이에 따라 많은 흥미로운 가능성이 열립니다.
Flow는 완전 반응형 프로그래밍 스타일로 사용할 수 있습니다. 이전에 RxJava 등을 사용한 적이 있다면 Flow가 제공하는 비슷한 기능을 활용할 수 있습니다. map, flatMapLatest, combine와 같은 함수 연산자로 흐름을 변환하여 애플리케이션 로직을 간결하게 표현할 수 있습니다.
Flow는 또한 대부분의 연산자에서 정지 함수를 지원합니다. 따라서 map과 같은 연산자 내부에서 순차적 비동기 작업을 할 수 있습니다. 흐름 내부에서 정지 작업을 사용하면 완전 반응형 스타일의 상응하는 코드에 비해 코드가 더 짧고 읽기 쉽습니다.
이 Codelab에서는 두 가지 방법을 모두 사용해 살펴보겠습니다.
흐름 실행 방법
Flow가 요청 시 값을 생성하거나 지연 생성하는 방법을 알아보려면 각 항목이 생성되기 전과 도중 그리고 이후에 (1, 2, 3) 값을 내보내고 인쇄하는 다음 흐름을 살펴보세요.
fun makeFlow() = flow {
println("sending first value")
emit(1)
println("first value collected, sending another value")
emit(2)
println("second value collected, sending a third value")
emit(3)
println("done")
}
scope.launch {
makeFlow().collect { value ->
println("got $value")
}
println("flow is completed")
}
이 코드를 실행하면 다음과 같은 출력이 생성됩니다.
sending first value got 1 first value collected, sending another value got 2 second value collected, sending a third value got 3 done flow is completed
collect 람다와 flow 빌더를 오가며 실행되는 방식을 확인할 수 있습니다. flow 빌더는 emit을 호출하면 항상 요소가 완전히 처리될 때까지 suspends 상태가 됩니다. 그런 다음, 흐름에서 다른 값이 요청되면 다시 내보내기를 호출할 때까지 정지했던 위치에서 resumes 처리됩니다. flow 빌더가 완료되면 Flow가 취소되고 collect가 다시 시작되어 호출 코루틴에서 '흐름 완료'가 출력됩니다.
collect 호출은 매우 중요합니다. Flow는 활성 소비 중일 때 항상 인식할 수 있도록 Iterator 인터페이스를 노출하는 대신 collect 같은 정지 연산자를 사용합니다. 무엇보다, 호출자가 값을 더 이상 요청할 수 없을 때 리소스를 정리할 수 있도록 이를 인식합니다.
흐름 실행 시점
위 예시의 Flow는 collect 연산자가 실행되면 실행이 시작됩니다. flow 빌더 또는 다른 API를 호출하여 새로운 Flow를 만들어도 아무 작업이 실행되지 않습니다. 정지 연산자 collect는 Flow에서 터미널 연산자라고 합니다. kotlinx-coroutines에서 제공되는 toList, first, single 같은 다른 정지 터미널 연산자가 있으며, 고유하게 빌드할 수도 있습니다.
기본적으로 Flow가 실행되는 시점:
- 터미널 연산자가 적용될 때마다(그리고 새로운 각 호출이 이전에 시작된 호출과 상관없이 독립적임) 실행
- 포함하는 코루틴이 취소될 때까지 실행
- 마지막 값이 완전히 처리되고 다른 값이 요청되었을 때
이러한 규칙 때문에 Flow는 구조화된 동시 실행 작업에 참여할 수 있으며 Flow에서 장기 실행 코루틴을 시작해도 안전합니다. 호출자가 취소되면 항상 코루틴 협력적 취소 규칙에 따라 리소스가 정리되므로 Flow에서 리소스를 유출할 가능성은 없습니다.
take 연산자를 사용하여 처음 두 요소만 확인한 다음 2회에 걸쳐 수집하도록 위의 흐름을 수정하겠습니다.
scope.launch {
val repeatableFlow = makeFlow().take(2) // we only care about the first two elements
println("first collection")
repeatableFlow.collect()
println("collecting again")
repeatableFlow.collect()
println("second collection completed")
}
이 코드를 실행하면 다음과 같은 출력이 표시됩니다.
first collection sending first value first value collected, sending another value collecting again sending first value first value collected, sending another value second collection completed
collect가 호출될 때마다 맨 위부터 flow 람다가 시작됩니다. 이 동작은 흐름이 네트워크 요청 생성과 같이 리소스를 많이 사용하는 작업을 실행한 경우 중요합니다. 또한 take(2) 연산자를 적용했으므로 흐름은 값을 두 개만 생성합니다. emit에 관한 두 번째 호출 후에 흐름 람다가 다시 시작되지 않으므로 'second value collected...' 줄이 인쇄되지 않습니다.
Flow는 Sequence처럼 지연 처리되지만 어떻게 비동기 방식이기도 할까요? 비동기 시퀀스와 데이터베이스 변경 관찰의 예를 살펴보겠습니다.
이 예시에서는 기본 스레드나 UI 스레드와 같은 다른 스레드에 있는 관찰자와 데이터베이스 스레드 풀에서 생성된 데이터를 조정해야 합니다. 또한 데이터 변화에 따라 반복적으로 결과를 내보낼 것이므로 이 시나리오는 비동기 시퀀스 패턴에 적합합니다.
Room의 Flow 통합을 작성하는 업무를 맡았다고 가정해 보세요. Room에서 지원되는 기존 정지 쿼리로 시작한 경우 다음과 같이 작성할 수 있습니다.
// This code is a simplified version of how Room implements flow
fun <T> createFlow(query: Query, tables: List<Tables>): Flow<T> = flow {
val changeTracker = tableChangeTracker(tables)
while(true) {
emit(suspendQuery(query))
changeTracker.suspendUntilChanged()
}
}
이 코드는 Flow를 생성하기 위해 가상의 정지 함수 두 개를 사용합니다.
suspendQuery- 일반Room정지 쿼리를 실행하는 기본 안전 함수suspendUntilChanged- 테이블 중 하나가 변경될 때까지 코루틴을 정지하는 함수
수집되면 흐름은 처음에는 쿼리의 첫 번째 값을 emits 처리합니다. 이 값이 처리된 후에는 흐름이 다시 시작되고 suspendUntilChanged를 호출합니다. 그러면 이름 그대로 테이블 중 하나가 변경될 때까지 흐름이 정지됩니다. 이 시점에서는 테이블 중 하나가 변경되어 흐름이 다시 시작될 때까지 시스템에서 아무 동작도 발생하지 않습니다.
흐름이 다시 시작되면 기본 안전 쿼리를 하나 더 실행하고 결과를 emits 처리합니다. 이 프로세스는 무한 루프로 영구적으로 진행됩니다.
Flow 및 구조화된 동시 실행
작업을 유출하지 않아야 합니다. 코루틴은 그 자체로 비용이 많이 들지 않지만 반복적으로 작동하여 데이터베이스 쿼리를 실행합니다. 상당한 비용이 드는 유출입니다.
무한 루프를 만들었더라도 Flow에서 지원하는 구조화된 동시 실행은 유용합니다.
값을 소비하거나 흐름을 반복할 수 있는 유일한 방법은 터미널 연산자를 사용하는 것입니다. 모든 터미널 연산자는 정지 함수이므로 작업은 이 연산자를 호출하는 범위의 전체 기간에 바인딩됩니다. 범위가 취소되면 흐름은 일반 코루틴 협력적 취소 규칙을 사용하여 자동으로 취소됩니다. 따라서 흐름 빌더에서 무한 루프를 작성했더라도 구조화된 동시 실행으로 인해 유출 없이 안전하게 소비할 수 있습니다.
이 단계에서는 Flow를 Room과 함께 사용하고 UI에 연결하는 방법을 알아봅니다.
이 단계는 일반적으로 많이 사용되는 Flow의 용도입니다. 이런 방식으로 사용하면 Room의 Flow는 LiveData와 유사하게 관찰 가능한 데이터베이스 쿼리로 작동합니다.
DAO 업데이트
시작하려면 PlantDao.kt를 열고 Flow<List<Plant>>를 반환하는 새 쿼리 두 개를 추가합니다.
PlantDao.kt
@Query("SELECT * from plants ORDER BY name")
fun getPlantsFlow(): Flow<List<Plant>>
@Query("SELECT * from plants WHERE growZoneNumber = :growZoneNumber ORDER BY name")
fun getPlantsWithGrowZoneNumberFlow(growZoneNumber: Int): Flow<List<Plant>>
이러한 함수는 반환 유형을 제외하고는 LiveData 버전과 동일합니다. 그러나 이 함수를 나란히 개발하면서 비교해 보겠습니다.
Flow 반환 유형을 지정하면 Room은 다음 특성으로 쿼리를 실행합니다.
- 기본 안전성 -
Flow반환 유형을 사용하는 쿼리는 항상Room실행기로 실행되므로 항상 기본 안전성이 보장됩니다. 기본 스레드에서 실행하기 위해 코드에 아무 작업도 하지 않아도 됩니다. - 변경사항 관찰 –
Room은 변경사항을 자동으로 관찰하고 흐름에 새 값을 내보냅니다. - 비동기 시퀀스 -
Flow는 각 변경 시 전체 쿼리 결과를 내보내며 어떠한 버퍼도 발생하지 않습니다.Flow<List<T>>를 반환하면 흐름은 쿼리 결과의 모든 행을 포함하는List<T>를 내보냅니다. 시퀀스처럼 실행됩니다. 즉, 쿼리 결과를 한 번에 하나씩 내보내고 다음 쿼리에 대한 요청이 있을 때까지 정지됩니다. - 취소 가능 - 이 흐름을 수집하는 범위가 취소되면
Room은 이 쿼리 관찰을 취소합니다.
전체적으로 이러한 특성 덕분에 Flow는 UI 레이어에서 데이터베이스를 관찰하기 위한 좋은 반환 유형입니다.
저장소 업데이트
계속해서 새 반환 값을 UI에 연결하려면 PlantRepository.kt를 열고 다음 코드를 추가합니다.
PlantRepository.kt
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
fun getPlantsWithGrowZoneFlow(growZoneNumber: GrowZone): Flow<List<Plant>> {
return plantDao.getPlantsWithGrowZoneNumberFlow(growZoneNumber.number)
}
현재는 Flow 값을 호출자에 전달하기만 합니다. 이는 이 Codelab을 시작할 때 LiveData를 ViewModel에 전달한 것과 정확히 같습니다.
ViewModel 업데이트
시작은 간단히 PlantListViewModel.kt에서 plantsFlow를 노출해 보겠습니다. 나중에 돌아와 다음 몇 개 단계에서 흐름 버전에 생장 영역 전환 기능을 추가할 것입니다.
PlantListViewModel.kt
// add a new property to plantListViewModel
val plantsUsingFlow: LiveData<List<Plant>> = plantRepository.plantsFlow.asLiveData()
진행하면서 비교하기 위해 LiveData 버전(val plants)을 유지합니다.
이 Codelab에서는 LiveData를 UI 레이어에 유지하므로 asLiveData 확장 함수를 사용하여 Flow를 LiveData로 변환합니다. 이렇게 하면 LiveData 빌더와 마찬가지로 생성된 LiveData에 구성 가능한 시간 제한이 추가됩니다. 구성이 변경될 때마다(예: 기기 회전) 쿼리를 다시 시작하지 못하게 하므로 유용합니다.
흐름은 기본 안전성과 취소 기능을 제공하므로 LiveData로 변환하지 않고도 Flow를 UI 레이어로 전달할 수 있습니다. 그러나 이 Codelab에서는 UI 레이어에 LiveData를 계속 사용하겠습니다.
또한 ViewModel에서 init 블록에 캐시 업데이트를 추가합니다. 현재는 이 단계가 선택사항이지만 캐시를 지우고 이 호출을 추가하지 않으면 앱에 데이터가 표시되지 않습니다.
PlantListViewModel.kt
init {
clearGrowZoneNumber() // keep this
// fetch the full plant list
launchDataLoad { plantRepository.tryUpdateRecentPlantsCache() }
}
프래그먼트 업데이트
PlantListFragment.kt를 열고 새 plantsUsingFlow LiveData를 가리키도록 subscribeUi 함수를 변경합니다.
PlantListFragment.kt
private fun subscribeUi(adapter: PlantAdapter) {
viewModel.plantsUsingFlow.observe(viewLifecycleOwner) { plants ->
adapter.submitList(plants)
}
}
Flow로 앱 실행
앱을 다시 실행하면 Flow를 사용하여 데이터가 로드되고 있음을 확인할 수 있습니다. switchMap을 아직 구현하지 않았으므로 필터 옵션은 아무 작업도 하지 않습니다.
다음 단계에서는 Flow의 데이터를 변환하는 방법을 알아봅니다.
이 단계에서는 plantsFlow에 정렬 순서를 적용합니다. flow의 선언형 API를 사용하면 됩니다.
map, combine, mapLatest 같은 transform을 사용하면 흐름을 거치는 과정에서 각 요소를 어떻게 변환할지를 선언적으로 표현할 수 있습니다. 그뿐 아니라 동시 실행을 선언적으로 표현할 수도 있어 코드가 매우 단순해질 수 있습니다. 이 섹션에서는 코루틴 두 개를 실행하고 결과를 결합하도록 연산자를 사용해 선언적으로 Flow에 알리는 방법을 보여줍니다.
시작하려면 PlantRepository.kt를 열고 customSortFlow라는 새 비공개 흐름을 정의합니다.
PlantRepository.kt
private val customSortFlow = flow { emit(plantsListSortOrderCache.getOrAwait()) }
이 코드는 수집되면 getOrAwait를 내보내고 정렬 순서를 emit 처리하는 Flow를 정의합니다.
이 흐름은 단일 값만 내보내므로 asFlow를 사용하여 getOrAwait 함수에서 직접 이 흐름을 빌드할 수도 있습니다.
// Create a flow that calls a single function
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
이 코드는 getOrAwait를 호출하고 결과를 첫 번째이자 유일한 값으로 내보내는 새 Flow를 만듭니다. ::을 사용하여 결과 Function 객체에서 asFlow를 호출하는 getOrAwait 메서드를 참조하면 됩니다.
두 흐름 모두 동일한 작업을 합니다. getOrAwait를 호출하고 결과를 내보낸 후 완료합니다.
여러 흐름을 선언적으로 결합
이제 customSortFlow와 plantsFlow의 두 흐름이 있으며 이들 흐름을 선언적으로 결합해 보겠습니다.
plantsFlow에 combine 연산자를 추가합니다.
PlantRepository.kt
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
// When the result of customSortFlow is available,
// this will combine it with the latest value from
// the flow above. Thus, as long as both `plants`
// and `sortOrder` are have an initial value (their
// flow has emitted at least one value), any change
// to either `plants` or `sortOrder` will call
// `plants.applySort(sortOrder)`.
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
combine 연산자는 두 흐름을 결합합니다. 두 흐름 모두 자체 코루틴에서 실행되고, 각 흐름에서 새 값이 생성될 때마다 각 흐름의 최신 값으로 변환이 호출됩니다.
combine을 사용하면 캐시된 네트워크 조회를 데이터베이스 쿼리와 결합할 수 있습니다. 두 가지 모두 서로 다른 코루틴에서 동시에 실행됩니다. 즉, Room에서 네트워크 요청을 시작하는 동안 Retrofit에서 네트워크 쿼리를 시작할 수 있습니다. 그런 다음 두 흐름 모두에서 결과가 나오는 즉시 combine 람다를 호출하여 로드된 식물에 로드된 정렬 순서를 적용합니다.
combine 연산자의 작동 방식을 살펴보려면 onStart에 상당한 지연을 포함하여 두 번 내보내도록 다음과 같이 customSortFlow를 수정합니다.
// Create a flow that calls a single function
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
.onStart {
emit(listOf())
delay(1500)
}
onStart transform은 관찰자가 다른 연산자 이전에 수신하면 발생합니다. 자리표시자 값을 내보낼 수 있습니다. 위 코드는 빈 목록을 내보내고 getOrAwait 호출을 1,500밀리초 지연한 후에 원래 흐름을 계속합니다. 지금 앱을 실행하면 Room 데이터베이스 쿼리가 즉시 반환되어 빈 목록과 결합됩니다(알파벳순으로 정렬됨). 그런 다음 약 1500밀리초 후에 맞춤 정렬이 적용됩니다.
Codelab을 계속 진행하기 전에 customSortFlow에서 onStart transform을 삭제합니다.
Flow 및 기본 안전성
Flow는 여기서 실행하는 것처럼 기본 안전 함수를 호출할 수 있으며 코루틴의 일반적인 기본 안전 보장을 유지합니다. Room과 Retrofit에서는 모두 기본 안전성이 보장되므로 Flow를 사용한 네트워크 요청이나 데이터베이스 쿼리를 실행하기 위해 다른 조치를 취할 필요가 없습니다.
이 흐름은 이미 다음 스레드를 사용합니다.
plantService.customPlantSortOrder가 Retrofit 스레드에서 실행됨(Call.enqueue호출)getPlantsFlow가 Room Executor에서 쿼리를 실행함applySort가 수집 디스패처(이 경우Dispatchers.Main)에서 실행됨
따라서 Retrofit에서 정지 함수를 호출하고 Room 흐름을 사용했다면 기본 안전성을 우려하여 이 코드를 복잡하게 만들 필요가 없습니다.
그러나 데이터 세트의 규모가 커질수록 applySort 호출 시 기본 스레드를 차단할 정도로 속도가 떨어질 수도 있습니다. Flow는 flowOn이라는 선언적 API를 제공하여 흐름이 실행되는 스레드를 제어합니다.
다음과 같이 plantsFlow에 flowOn을 추가합니다.
PlantRepository.kt
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
.flowOn(defaultDispatcher)
.conflate()
flowOn을 호출하면 코드 실행 방식에 중요한 두 가지 영향을 미칩니다.
defaultDispatcher(이 경우Dispatchers.Default)에서 새 코루틴을 실행하여flowOn을 호출하기 전에 흐름을 실행하고 수집합니다.- 버퍼를 도입하여 새 코루틴의 결과를 이후 호출로 전송합니다.
- 이 버퍼의 값을
flowOn이후의Flow에 내보냅니다. 이 경우에는ViewModel에 있는asLiveData입니다.
이는 withContext가 디스패처를 전환하기 위해 작동하는 방식과 매우 유사하지만 변환 도중에 흐름의 작동 방식을 변경하는 버퍼가 도입된다는 점에 차이가 있습니다. flowOn에서 실행된 코루틴은 호출자가 소비하는 속도보다 빠르게 결과를 생성할 수 있으며 기본적으로 다량의 결과를 버퍼링합니다.
여기서는 결과를 UI에 전송할 계획이므로 최근 결과에만 관심이 있습니다. 이것이 conflate 연산자의 역할입니다. 이 연산자는 마지막 결과만 저장하도록 flowOn의 버퍼를 수정합니다. 이전 결과를 읽기 전에 다른 결과가 제공되면 이전 결과를 덮어씁니다.
앱 실행
앱을 다시 실행하면 이제 데이터가 로드되고 Flow를 사용하여 맞춤 정렬 순서가 적용되는 것을 확인할 수 있습니다. switchMap을 아직 구현하지 않았으므로 필터 옵션은 아무 작업도 하지 않습니다.
다음 단계에서는 flow를 사용하여 기본 안전성을 제공하는 다른 방법을 알아봅니다.
이 API의 Flow 버전을 완료하려면 PlantListViewModel.kt를 열고 LiveData 버전에서와 마찬가지로 GrowZone을 기반으로 흐름 간에 전환합니다.
plants liveData 아래에 다음 코드를 추가합니다.
PlantListViewModel.kt
private val growZoneFlow = MutableStateFlow<GrowZone>(NoGrowZone)
val plantsUsingFlow: LiveData<List<Plant>> = growZoneFlow.flatMapLatest { growZone ->
if (growZone == NoGrowZone) {
plantRepository.plantsFlow
} else {
plantRepository.getPlantsWithGrowZoneFlow(growZone)
}
}.asLiveData()
이 패턴은 이벤트(생장 영역 변경)를 흐름에 통합하는 방법을 보여줍니다. LiveData.switchMap 버전과 정확히 동일하게 동작합니다. 즉, 이벤트에 기반하여 두 데이터 소스 간에 전환합니다.
코드 단계별 처리
PlantListViewModel.kt
private val growZoneFlow = MutableStateFlow<GrowZone>(NoGrowZone)
이 코드는 NoGrowZone의 초깃값을 사용하여 새 MutableStateFlow를 정의합니다. 특별한 종류의 Flow 값 홀더로서, 제공된 마지막 값만 보유합니다. 스레드로부터 안전한 동시 실행 프리미티브이므로 동시에 여러 스레드에서 쓸 수 있습니다('마지막'으로 인정되는 값이 채택됨).
구독을 통해 현재 값에 관한 업데이트를 받을 수도 있습니다. 전체적으로 LiveData와 비슷하게 동작합니다. 즉, 마지막 값을 보유하며 변경사항을 관찰할 수 있습니다.
PlantListViewModel.kt
val plantsUsingFlow: LiveData<List<Plant>> = growZoneFlow.flatMapLatest { growZone ->
StateFlow도 일반적인 Flow이므로 모든 연산자를 평소처럼 사용할 수 있습니다.
여기서는 LiveData의 switchMap과 정확히 동일한 flatMapLatest 연산자를 사용합니다. growZone이 값을 변경할 때마다 이 람다가 적용되며 Flow를 반환해야 합니다. 그런 다음 반환된 Flow는 모든 다운스트림 연산자의 Flow로 사용됩니다.
기본적으로 growZone의 값을 기반으로 서로 다른 흐름 간에 전환할 수 있습니다.
PlantListViewModel.kt
if (growZone == NoGrowZone) {
plantRepository.plantsFlow
} else {
plantRepository.getPlantsWithGrowZoneFlow(growZone)
}
flatMapLatest내에서 growZone을 기반으로 전환합니다. 이 코드는 LiveData.switchMap 버전과 거의 같으며 LiveDatas 대신 Flows를 반환한다는 점만 다릅니다.
PlantListViewModel.kt
}.asLiveData()
마지막으로, Fragment에서 ViewModel의 LiveData를 노출해야 하므로 Flow를 LiveData로 변환합니다.
StateFlow 값 변경
앱에 필터 변경을 알리려면 MutableStateFlow.value를 설정합니다. 이렇게 하면 여기서와 마찬가지로 이벤트를 코루틴에 쉽게 전달할 수 있습니다.
PlantListViewModel.kt
fun setGrowZoneNumber(num: Int) {
growZone.value = GrowZone(num)
growZoneFlow.value = GrowZone(num)
launchDataLoad {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(GrowZone(num)) }
}
fun clearGrowZoneNumber() {
growZone.value = NoGrowZone
growZoneFlow.value = NoGrowZone
launchDataLoad {
plantRepository.tryUpdateRecentPlantsCache()
}
}
앱 다시 실행
앱을 다시 실행하면 이제 LiveData 버전과 Flow 버전 모두에 필터가 작동합니다.
다음 단계에서는 getPlantsWithGrowZoneFlow에 맞춤 정렬을 적용합니다.
Flow의 가장 흥미로운 기능 중 하나는 정지 함수를 최고 수준으로 지원한다는 점입니다. flow 빌더와 거의 모든 transform은 정지 함수를 호출할 수 있는 suspend 연산자를 노출합니다. 따라서 네트워크 및 데이터베이스 호출에 관한 기본 안전성이 보장될 뿐만 아니라 흐름 내에서 일반 정지 함수 호출을 사용하여 여러 비동기 작업을 조정할 수도 있습니다.
실제로, 선언적 transform을 명령 코드와 자연스럽게 혼합할 수 있습니다. 이 예에서 볼 수 있듯이 추가 변환을 적용하지 않고 일반 map 연산자 내부에서 여러 비동기 작업을 조정할 수 있습니다. 많은 사례에서 이 방법을 사용하면 완전한 선언적 접근 방식보다 코드가 훨씬 더 단순해질 수 있습니다.
정지 함수를 사용하여 비동기 작업 조정
Flow에 관해 알아보는 마지막 단계로, 정지 연산자를 사용하여 맞춤 정렬을 적용합니다.
PlantRepository.kt를 열고 매핑 transform을 getPlantsWithGrowZoneNumberFlow에 추가합니다.
PlantRepository.kt
fun getPlantsWithGrowZoneFlow(growZone: GrowZone): Flow<List<Plant>> {
return plantDao.getPlantsWithGrowZoneNumberFlow(growZone.number)
.map { plantList ->
val sortOrderFromNetwork = plantsListSortOrderCache.getOrAwait()
val nextValue = plantList.applyMainSafeSort(sortOrderFromNetwork)
nextValue
}
}
일반 정지 함수를 사용하여 비동기 작업을 처리하면 이 map 작업은 비동기 작업 두 개를 결합하더라도 기본 안전성이 보장됩니다.
데이터베이스의 각 결과가 반환되면 캐시된 정렬 순서를 가져옵니다. 아직 준비가 되지 않았다면 비동기 네트워크 요청을 대기합니다. 정렬 순서를 가져온 후에는 applyMainSafeSort를 호출해도 안전합니다. 기본 디스패처에서 정렬이 실행됩니다.
이 코드는 기본 안전성 우려를 일반 정지 함수에 맡김으로써 이제 기본 안전성이 완전히 보장됩니다. plantsFlow에서 구현된 동일한 변환보다 훨씬 더 단순합니다.
그러나 실행 방식은 약간 다릅니다. 데이터베이스가 새 값을 내보낼 때마다 캐시된 값을 가져옵니다. plantsListSortOrderCache에서 올바르게 캐시하므로 이 동작은 문제가 되지 않지만, 동작으로 인해 새 네트워크 요청이 시작된다면 이 구현에서 불필요한 네트워크 요청이 많이 발생합니다. 또한 .combine 버전에서는 네트워크 요청과 데이터베이스 쿼리가 동시에 실행되지만 이 버전에서는 순차적으로 실행됩니다.
이러한 차이점으로 인해 이 코드를 구성하는 명확한 규칙이 없습니다. 많은 경우 여기서 실행하는 것처럼 정지 변환을 사용해 모든 비동기 작업을 순차적 작업으로 만들어도 좋습니다. 하지만 어떤 경우에는 연산자를 사용하여 동시 실행을 제어하고 기본 안전성을 제공하는 것이 더 좋습니다.
거의 완료되었습니다. 마지막 단계로(선택사항) 네트워크 요청을 흐름 기반 코루틴으로 이동하겠습니다.
이렇게 하면 onClick에서 호출된 핸들러에서 네트워크 호출을 실행하는 로직이 삭제되고 growZone에서 구동됩니다. 그러면 단일 소스 저장소(SSOT)를 만들어 코드 중복을 방지할 수 있습니다. 어떤 코드도 캐시 새로고침 없이 필터를 변경할 수 없습니다.
PlantListViewModel.kt를 열고 init 블록에 다음을 추가합니다.
PlantListViewModel.kt
init {
clearGrowZoneNumber()
growZone.mapLatest { growZone ->
_spinner.value = true
if (growZone == NoGrowZone) {
plantRepository.tryUpdateRecentPlantsCache()
} else {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(growZone)
}
}
.onEach { _spinner.value = false }
.catch { throwable -> _snackbar.value = throwable.message }
.launchIn(viewModelScope)
}
이 코드는 growZoneChannel에 전송된 값을 관찰하는 새 코루틴을 실행합니다. 네트워크 호출이 LiveData 버전에만 필요하므로 이제 아래 메서드에서 호출에 주석을 달 수 있습니다.
PlantListViewModel.kt
fun setGrowZoneNumber(num: Int) {
growZone.value = GrowZone(num)
growZoneFlow.value = GrowZone(num)
// launchDataLoad {
// plantRepository.tryUpdateRecentPlantsForGrowZoneCache(GrowZone(num))
// }
}
fun clearGrowZoneNumber() {
growZone.value = NoGrowZone
growZoneFlow.value = NoGrowZone
// launchDataLoad {
// plantRepository.tryUpdateRecentPlantsCache()
// }
}
앱 다시 실행
앱을 다시 실행하면 이제 네트워크 새로고침이 growZone에 의해 제어되는 것을 확인할 수 있습니다. 필터를 크게 개선했습니다. 더 다양한 필터 변경 방법이 도입되었으며 채널은 필터 활성화를 위한 단일 소스 저장소(SSOT)의 역할을 합니다. 덕분에 네트워크 요청과 현재 필터가 전혀 동기화될 수 없습니다.
코드 단계별 처리
사용되는 모든 새 함수를 외부에 있는 것부터 시작해 한 번에 하나씩 살펴보겠습니다.
PlantListViewModel.kt
growZone
// ...
.launchIn(viewModelScope)
이번에는 launchIn 연산자를 사용하여 ViewModel 내에서 흐름을 수집합니다.
연산자 launchIn은 새 코루틴을 만들고 흐름에서 모든 값을 수집합니다. 제공된 CoroutineScope(이 경우 viewModelScope)에서 실행됩니다. 이렇게 되면 이 ViewModel이 삭제되면 수집이 취소되므로 유용합니다.
다른 연산자가 제공되지 않으면 그리 많은 작업을 하지 못합니다. 하지만 Flow에서는 모든 연산자에 정지 람다를 제공하므로 모든 값을 기반으로 비동기 작업을 쉽게 실행할 수 있습니다.
PlantListViewModel.kt
.mapLatest { growZone ->
_spinner.value = true
if (growZone == NoGrowZone) {
plantRepository.tryUpdateRecentPlantsCache()
} else {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(growZone)
}
}
여기서 놀라운 일이 일어납니다. mapLatest는 각 값의 매핑 함수를 적용합니다. 그러나 일반 map과 달리 매핑 transform을 호출할 때마다 새 코루틴이 실행됩니다. 그런 다음, 이전 코루틴이 완료되기 전에 growZoneChannel에서 새 값을 내보내면 이전 코루틴을 취소한 후에 새 코루틴을 시작합니다.
mapLatest를 사용하여 동시 실행을 제어할 수 있습니다. 취소/다시 시작 로직을 직접 작성하는 대신 흐름 transform에서 처리할 수 있습니다. 이 코드는 동일한 취소 로직을 직접 작성하는 경우에 비해 복잡성과 작성할 코드 양을 크게 줄여 줍니다.
Flow를 취소할 때는 코루틴의 일반 협력적 취소 규칙을 따릅니다.
PlantListViewModel.kt
.onEach { _spinner.value = false }
.catch { throwable -> _snackbar.value = throwable.message }
onEach는 그 이전의 흐름에서 값을 내보낼 때마다 호출됩니다. 여기서는 처리가 완료된 후 스피너를 초기화하는 데 사용합니다.
catch 연산자는 흐름에서 그 이전에 발생한 예외를 캡처합니다. 오류 상태와 같은 새 값을 흐름에 내보내거나, 예외를 흐름에 다시 반환하거나, 여기서와 같이 작업을 실행할 수 있습니다.
오류가 발생하면 오류 메시지를 표시하도록 _snackbar에 지시합니다.
요약
이 단계에서는 Flow를 사용하여 동시 실행을 제어하는 방법과 UI 관찰자에 의존하지 않고 ViewModel 내에서 Flows를 소비하는 방법을 알아봤습니다.
도전과제 단계로, 다음 서명을 사용하여 이 흐름의 데이터 로드를 캡슐화하는 함수를 정의해 보세요.
fun <T> loadDataFor(source: StateFlow<T>, block: suspend (T) -> Unit) {