
WorkManager की मदद से, काम की चेन बनाई और उसे एनक्वी किया जा सकता है. इसमें, एक-दूसरे पर निर्भर कई टास्क शामिल किए जा सकते हैं. साथ ही, यह भी तय किया जा सकता है कि उन्हें किस क्रम में पूरा किया जाना चाहिए. यह सुविधा तब काम की होती है, जब आपको कई टास्क को किसी खास क्रम में पूरा करना हो.
काम की चेन बनाने के लिए,
WorkManager.beginWith(OneTimeWorkRequest)
या
WorkManager.beginWith(List<OneTimeWorkRequest>)
का इस्तेमाल किया जा सकता है. इन दोनों से ही
WorkContinuationका इंस्टेंस मिलता है.
इसके बाद, WorkContinuation का इस्तेमाल करके, एक-दूसरे पर निर्भर OneTimeWorkRequest
इंस्टेंस जोड़े जा सकते हैं. इसके लिए, then(OneTimeWorkRequest)
या
then(List<OneTimeWorkRequest>)
का इस्तेमाल किया जा सकता है.
WorkContinuation.then(...) को हर बार कॉल करने पर, नया इंस्टेंस मिलता है WorkContinuation का. अगर OneTimeWorkRequest इंस्टेंस की List जोड़ी जाती है, तो ये अनुरोध एक साथ पूरे किए जा सकते हैं.
आखिर में,
WorkContinuation.enqueue()
तरीके का इस्तेमाल करके, enqueue() की चेन को WorkContinuation किया जा सकता है.
आइए, एक उदाहरण देखते हैं. इस उदाहरण में, Worker के तीन अलग-अलग टास्क को एक साथ पूरा करने के लिए कॉन्फ़िगर किया गया है. इसके बाद, इन वर्कर के नतीजों को जोड़ा जाता है और उन्हें कैशिंग वर्कर के टास्क को पास किया जाता है. आखिर में, उस टास्क का आउटपुट, अपलोड वर्कर को पास किया जाता है. यह वर्कर, नतीजों को रिमोट सर्वर पर अपलोड करता है.
Kotlin
WorkManager.getInstance(myContext) // Candidates to run in parallel .beginWith(listOf(plantName1, plantName2, plantName3)) // Dependent work (only runs after all previous work in chain) .then(cache) .then(upload) // Call enqueue to kick things off .enqueue()
Java
WorkManager.getInstance(myContext) // Candidates to run in parallel .beginWith(Arrays.asList(plantName1, plantName2, plantName3)) // Dependent work (only runs after all previous work in chain) .then(cache) .then(upload) // Call enqueue to kick things off .enqueue();
इनपुट मर्ज करने वाले टूल
OneTimeWorkRequest इंस्टेंस को चेन करने पर, पैरंट वर्क के अनुरोधों का आउटपुट, चाइल्ड को इनपुट के तौर पर पास किया जाता है. इसलिए, ऊपर दिए गए उदाहरण में, plantName1, plantName2, और plantName3 के आउटपुट, cache अनुरोध को इनपुट के तौर पर पास किए जाएंगे.
एक से ज़्यादा पैरंट वर्क के अनुरोधों से मिले इनपुट को मैनेज करने के लिए, WorkManager,
InputMerger का इस्तेमाल करता है.
WorkManager, InputMerger के दो अलग-अलग टाइप उपलब्ध कराता है:
OverwritingInputMerger, सभी इनपुट की सभी कुंजियों को आउटपुट में जोड़ने की कोशिश करता है. अगर कुंजियों में कोई टकराव होता है, तो यह पहले से सेट की गई कुंजियों को ओवरराइट कर देता है.ArrayCreatingInputMerger, इनपुट को मर्ज करने की कोशिश करता है. ज़रूरत पड़ने पर, यह ऐरे बनाता है.
अगर आपके पास कोई खास इस्तेमाल का उदाहरण है, तो InputMerger को सबक्लास करके, अपना उदाहरण लिखा जा सकता है.
OverwritingInputMerger
OverwritingInputMerger, मर्ज करने का डिफ़ॉल्ट तरीका है. अगर मर्ज करने के दौरान, कुंजियों में कोई टकराव होता है, तो किसी कुंजी की सबसे नई वैल्यू, आउटपुट डेटा में मौजूद पिछली सभी वैल्यू को ओवरराइट कर देगी.
उदाहरण के लिए, अगर प्लांट के इनपुट में हर एक की, उसके वैरिएबल के नाम ("plantName1", "plantName2", और "plantName3") से मैच करती है, तो
डेटा पास किए गए cache वर्कर में, तीन की-वैल्यू पेयर होंगे.
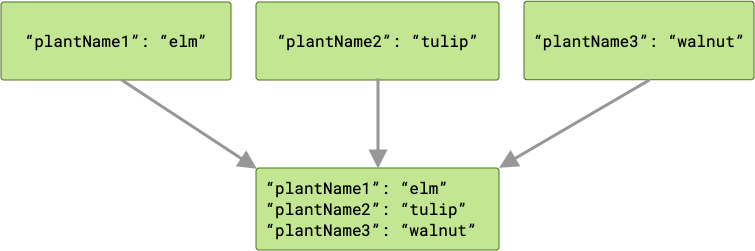
अगर कोई टकराव होता है, तो “जीत” उस वर्कर की होती है जो सबसे आखिर में काम पूरा करता है. उसकी वैल्यू, cache को पास की जाती है.
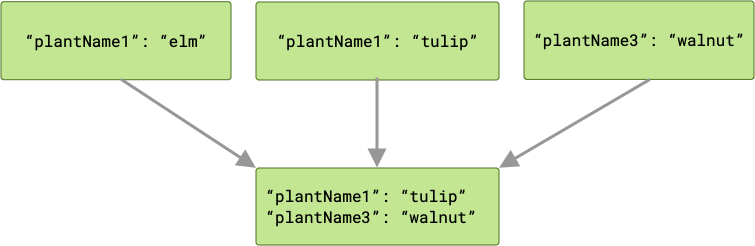
आपके काम के अनुरोध एक साथ पूरे किए जाते हैं. इसलिए, इस बात की कोई गारंटी नहीं होती कि वे किस क्रम में पूरे किए जाएंगे. ऊपर दिए गए उदाहरण में, plantName1 की वैल्यू "tulip" या "elm" हो सकती है. यह इस बात पर निर्भर करता है कि सबसे आखिर में कौनसी वैल्यू लिखी गई है. अगर कुंजी के टकराव की संभावना है और आपको मर्ज करने के दौरान, सभी आउटपुट डेटा को सुरक्षित रखना है, तो ArrayCreatingInputMerger एक बेहतर विकल्प हो सकता है.
ArrayCreatingInputMerger
ऊपर दिए गए उदाहरण के लिए, हमें प्लांट के नाम वाले सभी वर्कर के आउटपुट को सुरक्षित रखना है. इसलिए, हमें ArrayCreatingInputMerger का इस्तेमाल करना चाहिए.
Kotlin
val cache: OneTimeWorkRequest = OneTimeWorkRequestBuilder<PlantWorker>() .setInputMerger(ArrayCreatingInputMerger::class) .setConstraints(constraints) .build()
Java
OneTimeWorkRequest cache = new OneTimeWorkRequest.Builder(PlantWorker.class) .setInputMerger(ArrayCreatingInputMerger.class) .setConstraints(constraints) .build();
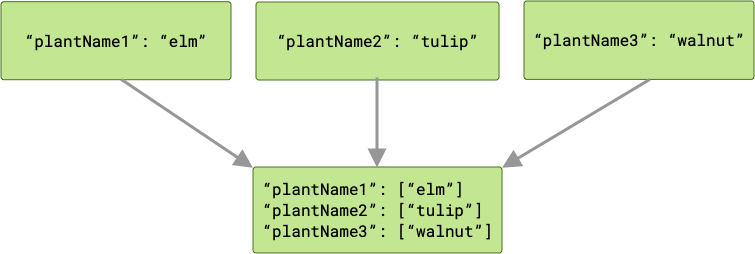
ArrayCreatingInputMerger, हर कुंजी को एक ऐरे के साथ पेयर करता है. अगर हर कुंजी यूनीक है, तो आपका नतीजा, एक-एक एलिमेंट वाले ऐरे की सीरीज़ होगा.
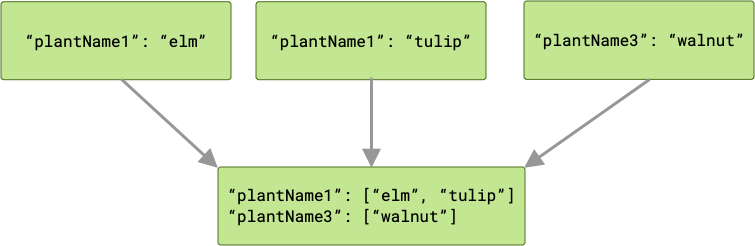
अगर कुंजियों में कोई टकराव होता है, तो उनसे जुड़ी सभी वैल्यू को एक ऐरे में ग्रुप किया जाता है.
चेन बनाना और काम की स्थितियां
OneTimeWorkRequest की चेन, क्रम से तब तक काम करती हैं, जब तक उनका काम सफलतापूर्वक पूरा नहीं हो जाता. इसका मतलब है कि वे Result.success() दिखाती हैं. काम के अनुरोध, काम करते समय फ़ेल हो सकते हैं या रद्द किए जा सकते हैं. इसका असर, एक-दूसरे पर निर्भर काम के अनुरोधों पर पड़ता है.
काम के अनुरोधों की चेन में, जब पहला OneTimeWorkRequest एनक्वी किया जाता है, तो उसके बाद के सभी काम के अनुरोध तब तक ब्लॉक रहते हैं, जब तक पहले काम का अनुरोध पूरा नहीं हो जाता.
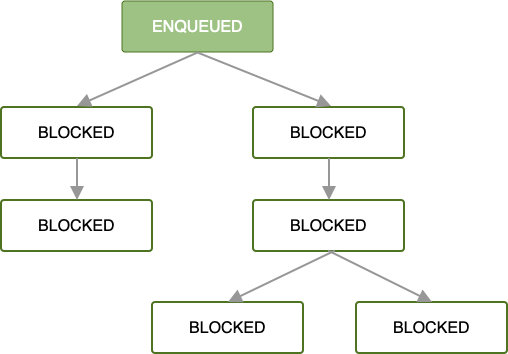
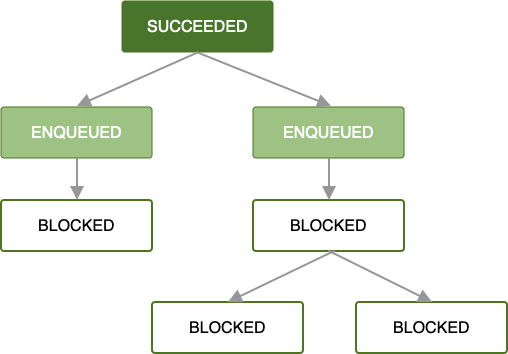
एनक्वी होने और काम की सभी ज़रूरी शर्तें पूरी होने के बाद, पहले काम का अनुरोध पूरा होना शुरू हो जाता है. अगर रूट
OneTimeWorkRequest या List<OneTimeWorkRequest> में काम सफलतापूर्वक पूरा हो जाता है, तो एक-दूसरे पर निर्भर काम के अनुरोधों का अगला सेट
एनक्वी किया जाएगा. इसका मतलब है कि यह
Result.success() दिखाता है.
जब तक हर काम का अनुरोध सफलतापूर्वक पूरा नहीं हो जाता, तब तक काम के अनुरोधों की चेन में यही पैटर्न चलता रहता है. हालांकि, यह सबसे आसान और अक्सर पसंद किया जाने वाला तरीका है. साथ ही, गड़बड़ी की स्थितियों को मैनेज करना भी उतना ही ज़रूरी है.
अगर वर्कर, आपके काम के अनुरोध को प्रोसेस करते समय कोई गड़बड़ी होती है, तो उस अनुरोध को फिर से पूरा किया जा सकता है. इसके लिए, आपको बैकऑफ़ नीति तय करनी होगी. चेन में शामिल किसी अनुरोध को फिर से पूरा करने का मतलब है कि सिर्फ़ उस अनुरोध को, उसे दिए गए इनपुट डेटा के साथ फिर से पूरा किया जाएगा. एक साथ पूरे किए जा रहे किसी भी काम पर कोई असर नहीं पड़ेगा.
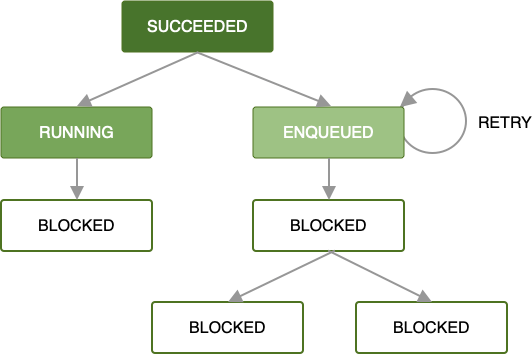
फिर से कोशिश करने की कस्टम रणनीतियां तय करने के बारे में ज़्यादा जानने के लिए, फिर से कोशिश करने और बैकऑफ़ की नीति देखें.
अगर फिर से कोशिश करने की नीति तय नहीं की गई है या वह खत्म हो गई है या किसी वजह से OneTimeWorkRequest, Result.failure() दिखाता है, तो उस काम के अनुरोध और एक-दूसरे पर निर्भर सभी काम के अनुरोधों को FAILED. के तौर पर मार्क किया जाता है.
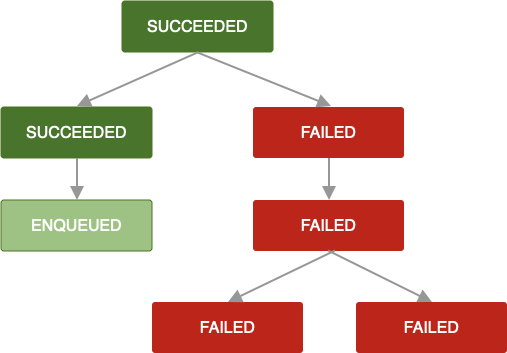
जब OneTimeWorkRequest रद्द किया जाता है, तब भी यही लॉजिक लागू होता है. एक-दूसरे पर निर्भर काम के अनुरोधों को भी CANCELLED के तौर पर मार्क किया जाता है. साथ ही, उनका काम पूरा नहीं किया जाएगा.
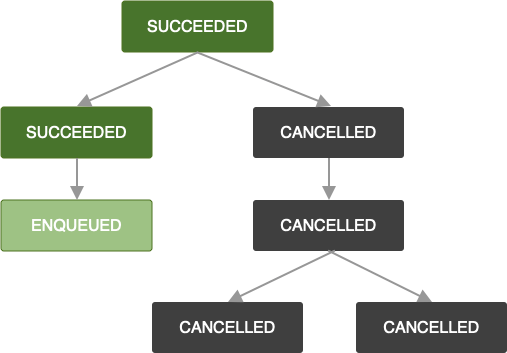
ध्यान दें कि अगर आपने किसी ऐसी चेन में काम के और अनुरोध जोड़े हैं जो फ़ेल हो गई है या जिसमें काम के अनुरोध रद्द किए गए हैं, तो आपके नए जोड़े गए काम के अनुरोध को भी क्रमशः FAILED या CANCELLED के तौर पर मार्क किया जाएगा. अगर आपको किसी मौजूदा चेन के काम को बढ़ाना है, तो APPEND_OR_REPLACE को ExistingWorkPolicy में देखें.
काम के अनुरोधों की चेन बनाते समय, एक-दूसरे पर निर्भर काम के अनुरोधों के लिए, फिर से कोशिश करने की नीतियां तय की जानी चाहिए. इससे यह पक्का किया जा सकेगा कि काम हमेशा समय पर पूरा हो. काम के अनुरोध फ़ेल होने पर, चेन पूरी नहीं हो सकती हैं और/या अनचाही स्थिति आ सकती है.
ज़्यादा जानकारी के लिए, काम रद्द करना और रोकना देखें.