
本文可協助您找出並修正應用程式的主要效能問題。
主要效能問題
許多問題都可能導致應用程式效能低落,以下列舉幾種應注意的常見問題:
- 啟動延遲
啟動延遲時間是指從輕觸應用程式圖示、通知或其他進入點開始,直到使用者資料顯示在畫面上所需的時間。
請在應用程式中確立下列啟動目標:
- 在 500 毫秒內完成冷啟動。如果系統記憶體中沒有啟動應用程式的記錄,就會出現「冷啟動」。這是應用程式自重新啟動,或使用者/系統終止應用程式的程序後,首次啟動時會出現的情形。冷啟動需要系統處理大部分作業,因為系統必須從儲存空間載入各種項目並初始化應用程式。因此,請設法將冷啟動的時間設為在 500 毫秒以下。
- 暖啟動時間少於 200 毫秒,熱啟動時間少於 150 毫秒。暖啟動是指應用程式程序已在背景執行,但系統需要重新初始化 UI 或將活動帶回前景,例如使用者離開應用程式後不久又重新開啟。熱啟動速度更快,因為應用程式的活動已快取在記憶體中,只需要帶到前景,不需要重新建立檢視區塊階層。目標是將暖啟動時間控制在 200 毫秒內,熱啟動時間則控制在 150 毫秒內。
- 讓 P95 和 P99 延遲時間非常接近中位數延遲時間。P95 和 P99 代表啟動時間的第 95 和第 99 個百分位數,中位數則是第 50 個百分位數。如果應用程式需要很長的時間才能啟動,會導致使用者體驗不佳。此外,在應用程式啟動的重要路徑中,處理序間通訊 (IPC) 和不必要的 I/O 可能會遭遇鎖定爭用的情況,並造成這些不一致的問題。
- 捲動時卡頓
「卡頓」一詞是指系統無法依要求的頻率 (例如 60 Hz 或更高) 及時建構和提供影格,導致畫面出現斷斷續續的情況。卡頓問題在捲動時最容易出現,舉例來說,因為應用程式轉譯內容所需的時間比系統畫面的持續時間還長,所以畫面移動時會在一或多個畫面中暫停,導致原本應該流暢的動畫流程變得斷斷續續。如果應用程式轉譯內容所需的時間比系統畫面的持續時間還長,畫面移動時就會在一或多個畫面中暫停,導致卡頓。
在應用程式中將刷新率設為 90 Hz。傳統的轉譯率為 60 Hz,但許多新型的裝置在使用者互動 (例如捲動) 時都是在 90 Hz 的模式下運作,而且有些裝置甚至支援更高的頻率 (最高 120 Hz)。
如要查看裝置在特定時間的刷新率,請依序輕觸「偵錯」部分的「開發人員選項」>「顯示刷新率」,啟用在畫面上疊加顯示刷新率的功能。
- 轉換不順暢
這個問題會在互動期間發生,例如切換分頁或載入新活動時。此類轉換的動畫應自然流暢,不得出現延遲或視覺效果閃爍的情況。
- 電源效率不佳
執行作業會消耗電池電力,最終降低電池續航力。
記憶體配置 (在程式碼中建立新物件) 會導致系統作業負載增加。配置作業不僅須透過 Android 執行階段 (ART) 完成,稍後釋出這些物件 (「垃圾收集」) 也需要時間與操作。
記憶體配置和垃圾回收的速度都比以前更快,效率也更高,對於暫存物件而言更是如此。因此,儘管以往的最佳做法是盡可能避免配置物件,現在我們會建議您以最適合應用程式和架構的方式執行操作;考量到 ART 的能力,冒著風險使用無法維護的程式碼來減少配置,並不是最理想的做法。
不過,配置作業需要耗費一定工夫,因此請留意若在內部迴圈中配置多個物件,可能會導致效能問題。
辨別問題
如要解決效能問題,請找出並檢查下列關鍵使用者歷程:
- 常見的啟動流程,包括透過啟動器和通知啟動的情形。
- 使用者捲動資料的畫面。
- 畫面之間的轉換。
- 長時間執行的流程,例如導航或播放音樂。
針對上述每個流程,使用下列偵錯工具檢查發生了什麼事:
- Perfetto:可讓您利用精確的時間資料瞭解整部裝置中的運作情況。
- 記憶體分析器:可讓您查看堆積上的記憶體配置情形。
- Simpleperf:透過火焰圖檢視在特定時間之內占用大多數 CPU 的函式呼叫。如果發現某些項目在 Systrace 中花費的時間較長,但又不知道原因為何,Simpleperf 就可以提供其他資訊。
如要瞭解這些效能問題並進行偵錯,請務必手動對個別測試偵錯。以上步驟無法以分析匯總資料取代。不過,在自動化測試和實際環境中設定指標收集作業也很重要,因為這可協助您瞭解使用者實際可看到的畫面,並找出可能發生迴歸的時間點:
- 啟動流程
- 實際環境指標:Play 管理中心啟動時間
- 實驗室測試:使用 Macrobenchmark 測試啟動作業
- 卡頓
- 實際環境指標
- Play 管理中心影格指標:您無法在 Play 管理中心將指標範圍縮小至特定使用者歷程,回報內容僅會說明應用程式的整體卡頓情形。
- 使用
FrameMetricsAggregator自訂評估:您可以在特定工作流程中使用FrameMetricsAggregator記錄卡頓指標。
- 研究室測試
- 使用 Macrobenchmark 捲動。
- Macrobenchmark 會使用包含單一使用者歷程的
dumpsys gfxinfo指令收集影格時間。如要瞭解特定使用者歷程中卡頓的不同情況,這是可行的方式。RenderTime指標會醒目顯示影格的繪製時間,這對辨識迴歸或改善而言,比資源浪費影格的計數要更為重要。
- 實際環境指標
應用程式連結驗證問題
應用程式連結是以網站網址為依據的深層連結,且經驗證屬於您的網站。應用程式連結驗證失敗的原因如下:
- 意圖篩選器範圍不正確:只為應用程式可回應的網址新增
autoVerify意圖篩選器。 - 未經驗證的通訊協定切換:未經驗證的伺服器端和子網域重新導向會被視為安全風險,因此無法通過驗證。導致所有
autoVerify連結都失敗。舉例來說,如果將連結從 HTTP 重新導向至 HTTPS (例如從 example.com 重新導向至 www.example.com),但未驗證 HTTPS 連結,可能會導致驗證失敗。請務必新增意圖篩選器,驗證應用程式連結。 - 無法驗證的連結:新增無法驗證的連結以進行測試,可能會導致系統無法驗證應用程式的應用程式連結。
- 伺服器不可靠:請確認伺服器可以連線至用戶端應用程式。
設定應用程式進行效能分析
應用程式的基準測試必須正確設定,才能獲得可重現的正確結果並做出後續行動。請盡可能使用最接近實際工作環境的系統,同時抑制雜訊來源。下列各節說明準備測試設定時可以採用的 APK 與系統步驟,其中有些步驟僅適用於特定用途。
追蹤點
應用程式可以透過自訂追蹤記錄事件檢測程式碼。
系統擷取追蹤記錄時,追蹤記錄在每個區段中都會產生少許額外負荷 (約 5 μs),因此請避免在每種方法中都加入追蹤記錄。追蹤記錄大型工作區塊 (>0.1 毫秒),就足以提供重要的瓶頸深入分析。
APK 注意事項
偵錯變化版本可協助您進行疑難排解,還可以透過符號方式提供堆疊樣本,但這會對效能造成嚴重影響。在搭載 Android 10 (API 級別 29) 以上版本的裝置中,您可以使用裝置資訊清單中的 profileable android:shell="true",啟用發布子版本的剖析功能。
請使用實際執行等級的程式碼縮減設定。視應用程式使用的資源而定,這可能會對效能產生重大影響。部分 ProGuard 設定會移除追蹤點,因此建議您針對要執行測試的設定移除這些規則。
編譯
請將裝置端應用程式編譯為已知狀態 (通常是 speed,或 speed-profile,以更貼近正式版效能,但這需要暖身應用程式並傾印設定檔,或編譯應用程式的基準設定檔)。
speed 和 speed-profile 都會減少從 DEX 執行的解譯程式碼量,因此可減少即時 (JIT) 編譯的背景作業量,避免造成重大干擾。只有 speed-profile
才能減少 DEX 執行階段類別載入的影響。
下列指令會使用 speed 模式編譯應用程式:
adb shell cmd package compile -m speed -f com.example.packagename
speed 編譯模式會完整編譯應用程式的方法。speed-profile 模式會根據設定檔編譯應用程式的方法和類別,此設定檔中含有應用程式使用期間所收集的已用程式碼路徑。持續以正確方式收集設定檔可能並不容易,因此如果您決定使用這些設定檔,請確認設定檔收集的內容符合您預期。設定檔位於以下位置:
/data/misc/profiles/ref/[package-name]/primary.prof
系統注意事項
如要進行低層級和高保真的評估,請校準裝置。建議您在相同的裝置和相同的 OS 版本中執行 A/B 版本比較作業,因為即便使用同樣的裝置類型,效能也可能會有顯著變化。
在已解鎖裝置中,請考慮使用 lockClocks 指令碼進行 Microbenchmark 測試。此外,指令碼也可以執行以下操作:
- 將 CPU 設為固定頻率。
- 停用小型核心並設定 GPU。
- 停用熱節流。
使用 lockClocks 指令碼的這個方法不適合以使用者體驗為重的測試 (例如應用程式啟動、DoU 測試和卡頓測試),但對減少 Microbenchmark 測試中的雜訊而言,卻是不可或缺的一環。
建議盡可能使用測試架構,例如 Macrobenchmark,以減少評估中的雜訊,避免評估不準確。
應用程式啟動速度緩慢:非必要的 Trampoline 活動
Trampoline 活動可能會無端延長應用程式啟動時間,因此請務必瞭解應用程式是否涉及這類活動。在以下追蹤記錄範例中,activityStart 後面緊接著令另一個 activityStart,且第一個活動沒有繪製任何影格。
 圖 1. 顯示 Trampoline 活動的追蹤記錄。
圖 1. 顯示 Trampoline 活動的追蹤記錄。
這種情況在通知進入點和一般應用程式的啟動進入點都可能發生,而且通常可以透過重構來解決。舉例來說,如果您使用該活動在另一個活動執行前執行設定,請將這個程式碼分解到可重複使用的元件或程式庫中。
非必要配置觸發常用 GC
您可能會發現垃圾收集 (GC) 的發生頻率比 Systrace 中預期的高。
以下範例顯示,在長時間執行的作業期間,每 10 秒進行一次垃圾回收,代表應用程式可能遭到不必要的分配,但有時仍會持續運作:
 圖 2. 顯示 GG 事件間隔的追蹤記錄。
圖 2. 顯示 GG 事件間隔的追蹤記錄。
您可能也會在記憶體分析器中發現,特定呼叫堆疊會占據大部分的分配比例。您不需要主動刪除所有配置,因為這樣可能會導致程式碼更難以維護。不妨改從使用分配熱點開始。
Janky 頁框
圖形管線的複雜度相對較高,為了判斷使用者最後是否看見捨棄的影格,可能會有些許細微的影響。在某些情況下,平台可以使用緩衝功能來「找回」影格。不過您可以忽略大部分的細微差異,直接從應用程式的角度找出有問題的影格。
如果繪製的影格幾乎都不是在應用程式中完成,Choreographer.doFrame() 追蹤點的間隔在 60 FPS 裝置上就會是 16.7 毫秒:
 圖 3. 顯示頻繁快速影格的追蹤記錄。
圖 3. 顯示頻繁快速影格的追蹤記錄。
縮小並瀏覽追蹤記錄時,有時會發現影格完成處理的時間比較長,但沒有超過配額的 16.7 毫秒。以下影格沒問題:
 圖 4. 顯示頻繁快速影格,且有定期突發工作的追蹤記錄。
圖 4. 顯示頻繁快速影格,且有定期突發工作的追蹤記錄。
如果您在規律的間隔中看到一處突然中斷,那就是卡頓的影格,如圖 5 和圖 6 所示:
 圖 5.顯示卡頓影格的追蹤記錄。
圖 5.顯示卡頓影格的追蹤記錄。
 圖 6. 顯示更多卡頓影格的追蹤記錄。
圖 6. 顯示更多卡頓影格的追蹤記錄。
在某些情況下,您需要放大檢視追蹤點,才能進一步瞭解哪些 UI 元件正在由 Compose 更新,或如圖 6 所示,LazyColumn 正在執行哪些操作。診斷這些 UI 瓶頸時,標準系統追蹤可能不會顯示哪些可組合函式是根本原因。在這些情況下,請使用 Jetpack Compose 合成追蹤,這項工具會在追蹤記錄中直接顯示確切的可組合函式,方便您找出非預期的重組。圖 5 和圖 6 顯示組合追蹤結果。
如要進一步瞭解如何提升 Compose 效能,請參閱「Jetpack Compose 效能」。如要進一步瞭解如何識別卡頓影格、偵錯並找出原因,請參閱「轉譯速度緩慢」。
常見的延遲版面配置錯誤
無故使整個延遲版面配置的備份狀態失效,可能會導致過度重組、影格轉譯時間過長,以及卡頓。如要盡量減少需要更新的清單項目數量,請為項目使用項目鍵,並只變更會變動的特定狀態元素。
請參閱「使用延遲版面配置鍵」,瞭解如何避免成本高昂的完整清單重新配置,這類配置會導致內容更新而非全面取代。
如果巢狀捲動清單的實作方式不當,可能會導致效能下降。 請避免在沒有明確限制的情況下,將捲動延遲版面配置巢狀內嵌至其他捲動容器。詳情請參閱「避免以巢狀方式嵌入可往相同方向捲動的元件」。
如果預先擷取的資料量不足,或是未及時預先擷取,使用者就可能需要等候伺服器傳來更多資料,才能流暢捲動到清單底部。雖然技術上來說這不算卡頓,因為操作仍然符合影格顯示期限,但仍建議您修改預先擷取的時間和數量,讓使用者不必等候資料顯示。這麼一來,使用者體驗也就能大幅提升。
為應用程式偵錯
以下是偵錯應用程式效能的方法。
使用 Systrace 對應用程式啟動進行偵錯
如要瞭解應用程式啟動程序,請參閱「應用程式啟動時間」一文。如要瞭解系統追蹤和使用 Android Studio 分析器,請觀看以下影片。
您可以在下列階段消除啟動類型歧義:
- 冷啟動:從建立新程序開始,沒有暫存狀態。
- 暖啟動:重新建立活動 (重複使用程序),或利用暫存狀態重新建立程序。
- 熱啟動:重新啟動活動,並從膨脹開始。
建議您使用裝置上的「系統追蹤」應用程式擷取系統追蹤記錄。如果是 Android 10 以上版本,請使用 Perfetto。如果是 Android 9 以下版本,請使用 Systrace。此外,我們也建議使用網頁式 Perfetto 追蹤記錄檢視器查看追蹤記錄檔案。詳情請參閱「系統追蹤總覽」一文。
請注意以下幾點:
- 監控爭用:受監控保護的資源如果發生內部競爭,可能會造成應用程式的啟動作業大幅延遲。
同步綁定資料傳輸:從應用程式的主要路徑中找出不必要的資料傳輸。如果必要交易的費用高昂,請考慮與相關聯的平台團隊合作進行改善。
即時 GC:這種情況很常見,影響程度相對較低,但如果經常發生,建議利用 Android Studio 記憶體分析器進行調查。
I/O:檢查啟動期間執行的 I/O,並尋找較嚴重的停頓問題。
其他執行緒的重大作業:這些作業會干擾 UI 執行緒,因此請留意啟動期間的背景作業。
建議您在應用程式啟動完成時呼叫 reportFullyDrawn,以改善應用程式啟動指標回報。如要進一步瞭解如何使用 reportFullyDrawn,請參閱「完整顯示時間」一節。您可以透過 Perfetto 追蹤記錄處理器擷取 RFD 定義的開始時間,並發出使用者可見的追蹤記錄事件。
在裝置上使用系統追蹤
您可以使用名為「系統追蹤」的系統層級應用程式,在裝置上擷取系統追蹤記錄。這個應用程式可讓您直接從裝置錄製追蹤記錄,不必插入裝置或連結至 adb。
使用 Android Studio 記憶體分析器
您可以使用 Android Studio 記憶體分析器,檢查記憶體流失或不當使用模式造成的記憶體壓力。可讓您即時查看物件配置情況。
您可以使用記憶體分析器追蹤垃圾收集進行的原因和頻率,藉此修正應用程式的記憶體問題。
如要剖析應用程式記憶體,請按照下列步驟操作:
偵測記憶體問題。
錄製要著重的使用者歷程的記憶體剖析工作階段。 如圖 7 所示,請注意物件計數是否增加,這最終會導致 GC,如圖 8 所示。
 圖 7. 物件數量增加。
圖 7. 物件數量增加。 圖 8. 垃圾收集作業。
圖 8. 垃圾收集作業。找出會增加記憶體壓力的使用者歷程後,請分析記憶體壓力的根本原因。
診斷記憶體空間壓力熱點。
選取時間軸範圍,以便視覺化呈現「分配」和「淺層大小」,如圖 9 所示。
 圖 9. 「Allocations」和「Shallow Size」的值。
圖 9. 「Allocations」和「Shallow Size」的值。這些資料的分類方式有很多種。以下提供幾個範例,說明如何運用不同檢視畫面分析問題。
依類別編排:如要搜尋會產生物件的類別,依類別編排是很實用的做法。系統會從記憶體集區快取或反覆使用這類物件。
舉例來說,如果應用程式每秒建立 2,000 個特定類別的物件,配置計數就會每秒增加 2,000 個,您可以在依類別排序時看到這種狀況。如要重複使用這些物件,避免產生垃圾資訊,請實作記憶體集區。
依呼叫堆疊編排:如要找出記憶體配置到熱路徑的位置,例如位於迴圈內或有特定功能需配置多項工作,依呼叫堆疊編排會是實用做法。
淺層大小:只會追蹤物件本身占用的記憶體。這項指標適合追蹤主要由原始值組成的簡單類別。
保留大小:顯示物件本身所佔用的記憶體總量,以及物件單獨參照的任何參照。在追蹤複雜物件造成的記憶體壓力時,參考保留大小較為適合。如要取得這個值,請完整傾印記憶體,如圖 10 所示。「保留大小」會新增為資料欄,如圖 11 所示。
 圖 10. 完整記憶體傾印。
圖 10. 完整記憶體傾印。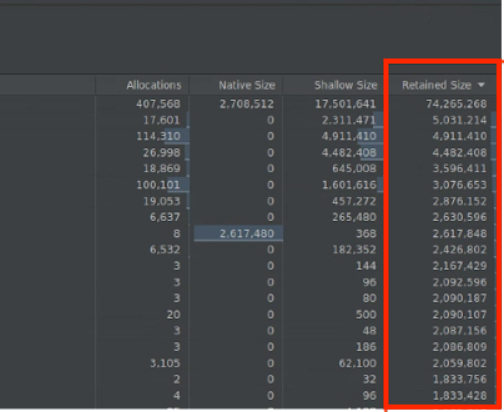
圖 11. 「保留大小」欄。
評估最佳化的影響。
GC 更明顯,也更容易評估記憶體最佳化的影響。當最佳化作業成功釋放記憶體壓力,您會看到次數較少的 GC。
如要評估最佳化的影響,請在分析器時間軸上測量垃圾資訊收集之間的間隔時間長度。正面影響會導致垃圾資訊收集之間的間隔時間較長。
記憶體改善項目的最終影響如下:
- 只要應用程式並非持續受到記憶體壓力,就較不會因記憶體空間不足而遭到系統終止。
- 減少垃圾收集的次數可以改善卡頓相關指標,尤其是 P99。這是因為垃圾收集事件會造成 CPU 爭用情形,導致轉譯工作在垃圾收集期間遭到延遲。
為您推薦
- 注意:系統會在 JavaScript 關閉時顯示連結文字
- 應用程式啟動分析與最佳化 {:#app-startup-analysis-optimization}
- 凍結影格
- 撰寫 Macrobenchmark