
בקורוטינות, Flow הוא סוג שיכול לפלוט כמה ערכים ברצף, בניגוד לפונקציות השהיה שמחזירות רק ערך אחד. לדוגמה, אתם יכולים להשתמש בתהליך כדי לקבל עדכונים בזמן אמת ממסד נתונים.
ה-Flows מבוססים על קורוטינות ויכולים לספק כמה ערכים.
מבחינה מושגית, זרם הוא זרם של נתונים שאפשר לבצע עליו חישובים באופן אסינכרוני. הערכים שמוחזרים צריכים להיות מאותו סוג. לדוגמה, Flow<Int> הוא זרם שפולט ערכים של מספרים שלמים.
ה-Flow דומה מאוד ל-Iterator שמפיק רצף של ערכים, אבל הוא משתמש בפונקציות השהיה כדי להפיק ולצרוך ערכים באופן אסינכרוני. לדוגמה, התהליך יכול לבצע בבטחה בקשת רשת כדי ליצור את הערך הבא בלי לחסום את השרשור הראשי.
יש שלושה ישויות שמעורבות בזרמי נתונים:
- יצרן יוצר נתונים שנוספים לזרם. בזכות קורוטינות, אפשר גם ליצור נתונים באופן אסינכרוני באמצעות רצפי פעולות.
- (אופציונלי) מתווכים יכולים לשנות כל ערך שמועבר לזרם או את הזרם עצמו.
- צרכן צורך את הערכים מהזרם.
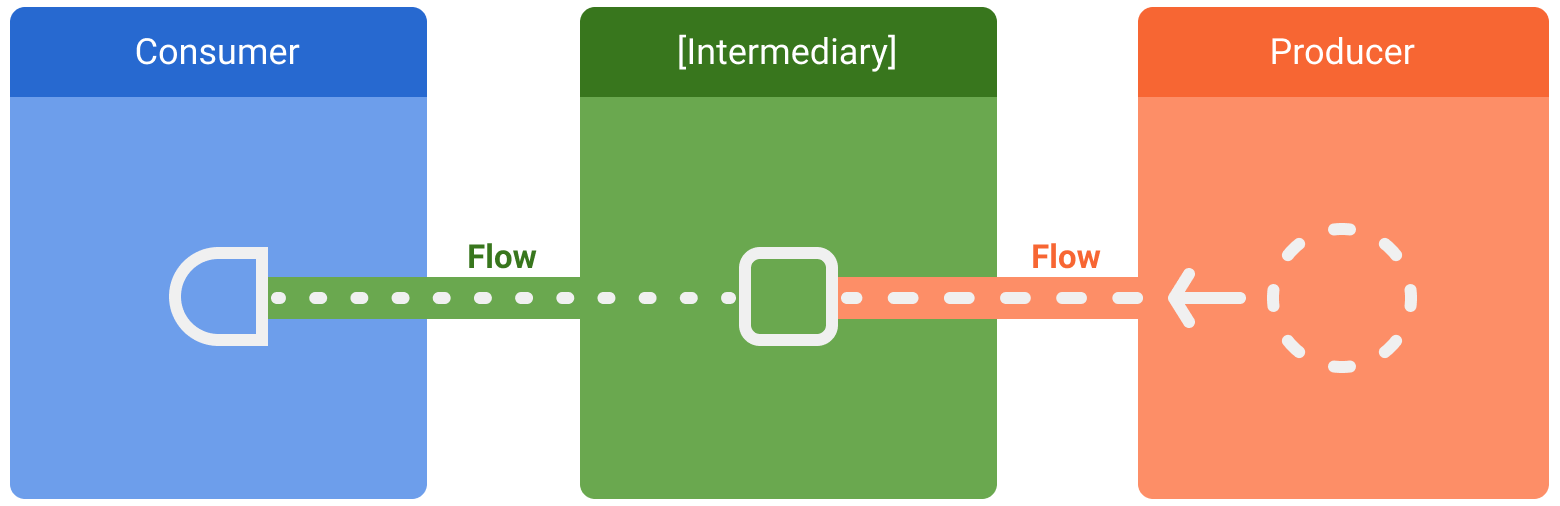
ב-Android, מאגר הוא בדרך כלל מקור של נתוני ממשק משתמש, וממשק המשתמש הוא הצרכן שמציג את הנתונים בסופו של דבר. במקרים אחרים, שכבת ממשק המשתמש היא יצרנית של אירועי קלט משתמשים, ושכבות אחרות בהיררכיה צורכות אותם. שכבות שנמצאות בין היצרן לצרכן משמשות בדרך כלל כמתווכים שמשנים את זרם הנתונים כדי להתאים אותו לדרישות של השכבה הבאה.
יצירת תהליך
כדי ליצור רצפי פעולות, משתמשים בממשקי ה-API של כלי בניית רצפי פעולות. פונקציית ה-builder flow יוצרת זרימה חדשה שבה אפשר להוסיף ערכים חדשים לזרם הנתונים באופן ידני באמצעות הפונקציה emit.
בדוגמה הבאה, מקור נתונים מאחזר את החדשות האחרונות באופן אוטומטי במרווח קבוע. מכיוון שפונקציית השהיה לא יכולה להחזיר כמה ערכים עוקבים, מקור הנתונים יוצר ומחזיר זרם כדי לעמוד בדרישה הזו. במקרה הזה, מקור הנתונים משמש כמפיק.
class NewsRemoteDataSource( private val newsApi: NewsApi, private val refreshIntervalMs: Long = 5000 ) { val latestNews: Flow<List<ArticleHeadline>> = flow { while (true) { val latestNews = newsApi.fetchLatestNews() emit(latestNews) // Emits the result of the request to the flow delay(refreshIntervalMs) // Suspends the coroutine for some time } } } // Interface that provides a way to make network requests with suspend functions interface NewsApi { suspend fun fetchLatestNews(): List<ArticleHeadline> }
הבונה flow מופעל בתוך שגרת המשנה. לכן, הוא נהנה מאותם ממשקי API אסינכרוניים, אבל יש כמה הגבלות:
- רצפי הפעולות הם עוקבים. מכיוון שהפונקציה producer נמצאת בקורוטינה, כשמפעילים פונקציית השהיה, הפונקציה producer מושהית עד שהפונקציה suspend מחזירה ערך. בדוגמה, הבעלים של השירות המנוהל מושעה עד להשלמת בקשת הרשת
fetchLatestNews. רק אז התוצאה מועברת לזרם. - באמצעות הכלי ליצירת
flow, אי אפשרemitערכים מCoroutineContextאחר. לכן, אל תקראו ל-emitב-CoroutineContextאחר על ידי יצירת קורוטינות חדשות או שימוש בבלוקים של קודwithContext. במקרים כאלה, אפשר להשתמש בכלי אחר ליצירת תרשימי זרימה, כמוcallbackFlow.
שינוי השידור
מתווכים יכולים להשתמש באופרטורים של ביניים כדי לשנות את זרם הנתונים בלי לצרוך את הערכים. האופרטורים האלה הם פונקציות שכשמחילים אותן על זרם נתונים, הן מגדירות שרשרת של פעולות שלא מבוצעות עד שהערכים נצרכים בעתיד. מידע נוסף על אופרטורים ביניים זמין במסמכי העיון של Flow.
בדוגמה שלמטה, שכבת המאגר משתמשת באופרטור הביניים map כדי לשנות את הנתונים שיוצגו ב-View:
class NewsRepository( private val newsRemoteDataSource: NewsRemoteDataSource, private val userData: UserData ) { /** * Returns the favorite latest news applying transformations on the flow. * These operations are lazy and don't trigger the flow. They just transform * the current value emitted by the flow at that point in time. */ val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews // Intermediate operation to filter the list of favorite topics .map { news -> news.filter { userData.isFavoriteTopic(it) } } // Intermediate operation to save the latest news in the cache .onEach { news -> saveInCache(news) } }
אפשר להחיל אופרטורים ביניים אחד אחרי השני, וליצור שרשרת של פעולות שמופעלות באופן עצלני כשפריט מועבר לזרימה. חשוב לזכור שפשוט להחיל אופרטור ביניים על זרם לא מתחיל את איסוף הנתונים של התהליך.
איסוף מתוך זרימה
משתמשים באופרטור טרמינל כדי להפעיל את התהליך ולהתחיל להאזין לערכים. כדי לקבל את כל הערכים בזרם כשהם מופקים, משתמשים ב-collect.
במסמכי התיעוד הרשמיים של התהליך מפורט מידע נוסף על מפעילי מסופים.
מכיוון ש-collect היא פונקציית השהיה, צריך להריץ אותה בתוך קורוטינה. היא מקבלת פונקציית lambda כפרמטר, שמופעלת על כל ערך חדש. מכיוון שזו פונקציית השעיה, יכול להיות שהקורוטינה שקוראת ל-collect תושעה עד שהזרימה תיסגר.
בהמשך לדוגמה הקודמת, הנה הטמעה פשוטה של ViewModel שצורכת את הנתונים משכבת המאגר:
class LatestNewsViewModel( private val newsRepository: NewsRepository ) : ViewModel() { init { viewModelScope.launch { // Trigger the flow and consume its elements using collect newsRepository.favoriteLatestNews.collect { favoriteNews -> // Update UI with the latest favorite news } } } }
האיסוף של הנתונים מפעיל את המפיק שמרענן את החדשות האחרונות ופולט את התוצאה של בקשת הרשת במרווח קבוע. ה-Producer נשאר תמיד פעיל בלולאה while(true), לכן זרם הנתונים ייסגר כשה-ViewModel ינוקה ו-viewModelScope יבוטל.
יכולות להיות כמה סיבות לכך שהאיסוף של נתוני זרימת התנועה ייפסק:
- הקורוטינה שאוספת מבוטלת, כמו בדוגמה הקודמת. הפעולה הזו גם מפסיקה את ההפקה הבסיסית.
- הבעלים של השירות המנוהל מסיים לשלוח פריטים. במקרה כזה, זרם הנתונים נסגר והקורוטינה שקראה ל-
collectממשיכה את הביצוע.
הזרימות הן קרות ועצלניות אלא אם מציינים אותן עם אופרטורים אחרים של ביניים. כלומר, קוד היצירה מופעל בכל פעם שמפעילים את האופרטור הסופי בתהליך. בדוגמה הקודמת, אם יש כמה אוספי נתונים של זרימת נתונים, מקור הנתונים יאחזר את החדשות האחרונות כמה פעמים במרווחי זמן קבועים שונים. כדי לבצע אופטימיזציה ולשתף נתונים כשכמה צרכנים אוספים נתונים בו-זמנית, משתמשים באופרטור shareIn.
תפיסת חריגים לא צפויים
ההטמעה של ה-producer יכולה להתבצע באמצעות ספרייה של צד שלישי.
כלומר, יכול להיות שהיא תציג חריגות לא צפויות. כדי לטפל בחריגים האלה, משתמשים באופרטור הביניים catch.
class LatestNewsViewModel( private val newsRepository: NewsRepository ) : ViewModel() { init { viewModelScope.launch { newsRepository.favoriteLatestNews // Intermediate catch operator. If an exception is thrown, // catch and update the UI .catch { exception -> notifyError(exception) } .collect { favoriteNews -> // Update UI with the latest favorite news } } } }
בדוגמה הקודמת, כשמתרחש חריג, לא מתבצעת קריאה ל-collect
lambda, כי לא התקבל פריט חדש.
אפשר גם catch פריטים לזרם.emit שכבת מאגר הדוגמאות יכולה emit את הערכים שנשמרו במטמון במקום זאת:
class NewsRepository( // ... ) { val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews .map { news -> news.filter { userData.isFavoriteTopic(it) } } .onEach { news -> saveInCache(news) } // If an error happens, emit the last cached values .catch { exception -> emit(lastCachedNews()) } }
בדוגמה הזו, כשמתרחשת חריגה, מתבצעת קריאה לפונקציית ה-lambda collect, כי פריט חדש הועבר לזרם בגלל החריגה.
הרצה בהקשר אחר של קורוטינה
כברירת מחדל, הפונקציה היוצרת של flow builder מופעלת ב-CoroutineContext של הקורוטינה שאוספת ממנה, וכמו שצוין קודם, היא לא יכולה emit ערכים מ-CoroutineContext אחר. במקרים מסוימים, יכול להיות שההתנהגות הזו לא רצויה.
לדוגמה, בדוגמאות שמופיעות לאורך המאמר הזה, שכבת המאגר לא אמורה לבצע פעולות ב-Dispatchers.Main שמשמש את viewModelScope.
כדי לשנות את CoroutineContext של תהליך, משתמשים באופרטור הביניים flowOn.
flowOn משנה את CoroutineContext של הזרימה במעלה הזרם, כלומר
היצרן וכל האופרטורים הביניים שמוחלים לפני (או מעל)
flowOn. הזרימה במורד הזרם (האופרטורים המתווכים after flowOn
יחד עם הצרכן) לא מושפעת ומופעלת ב-CoroutineContext שמשמש ל-collect מהזרימה. אם יש כמה אופרטורים של flowOn, כל אחד מהם משנה את הזרם במעלה מהמיקום הנוכחי שלו.
class NewsRepository( private val newsRemoteDataSource: NewsRemoteDataSource, private val userData: UserData, private val defaultDispatcher: CoroutineDispatcher ) { val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews .map { news -> // Executes on the default dispatcher news.filter { userData.isFavoriteTopic(it) } } .onEach { news -> // Executes on the default dispatcher saveInCache(news) } // flowOn affects the upstream flow ↑ .flowOn(defaultDispatcher) // the downstream flow ↓ is not affected .catch { exception -> // Executes in the consumer's context emit(lastCachedNews()) } }
בקוד הזה, האופרטורים onEach ו-map משתמשים ב-defaultDispatcher, ואילו האופרטור catch והצרכן מופעלים ב-Dispatchers.Main שמשמש את viewModelScope.
מכיוון ששכבת מקור הנתונים מבצעת פעולות קלט/פלט, צריך להשתמש ב-dispatcher שעבר אופטימיזציה לפעולות קלט/פלט:
class NewsRemoteDataSource( // ... private val ioDispatcher: CoroutineDispatcher ) { val latestNews: Flow<List<ArticleHeadline>> = flow { // Executes on the IO dispatcher // ... } .flowOn(ioDispatcher) }
Flows בספריות Jetpack
Flow משולב בספריות רבות של Jetpack, והוא פופולרי בספריות של צד שלישי ב-Android. Flow מתאים מאוד לעדכוני נתונים בזמן אמת ולזרמי נתונים אינסופיים.
אתם יכולים להשתמש ב-Flow עם Room כדי לקבל הודעה על שינויים במסד נתונים. כשמשתמשים באובייקטים של גישה לנתונים (DAO), צריך להחזיר סוג Flow כדי לקבל עדכונים בזמן אמת.
@Dao abstract class ExampleDao { @Query("SELECT * FROM Example") abstract fun getExamples(): Flow<List<Example>> }
בכל פעם שיש שינוי בטבלה Example, רשימה חדשה מופקת עם הפריטים החדשים במסד הנתונים.
המרת ממשקי API מבוססי-callback ל-Flows
callbackFlow
הוא כלי ליצירת תהליכים שמאפשר להמיר ממשקי API מבוססי קריאה חוזרת לתהליכים.
לדוגמה, ממשקי ה-API של Android ב-Firebase Firestore משתמשים בפונקציות קריאה חוזרת.
snapshots()
כדי להמיר את ממשקי ה-API האלה לזרימות ולהאזין לעדכונים במסד הנתונים של Firestore, אפשר להשתמש בקוד הבא:
class FirestoreUserEventsDataSource(
private val firestore: FirebaseFirestore
) {
// Method to get user events from the Firestore database
fun getUserEvents(): Flow<UserEvents> = callbackFlow {
// Reference to use in Firestore
var eventsCollection: CollectionReference? = null
try {
eventsCollection = FirebaseFirestore.getInstance()
.collection("collection")
.document("app")
} catch (e: Throwable) {
// If Firebase cannot be initialized, close the stream of data
// flow consumers will stop collecting and the coroutine will resume
close(e)
}
// Registers callback to firestore, which will be called on new events
val subscription = eventsCollection?.addSnapshotListener { snapshot, _ ->
if (snapshot == null) { return@addSnapshotListener }
// Sends events to the flow! Consumers will get the new events
try {
trySend(snapshot.getEvents())
} catch (e: Throwable) {
// Event couldn't be sent to the flow
}
}
// The callback inside awaitClose will be executed when the flow is
// either closed or cancelled.
// In this case, remove the callback from Firestore
awaitClose { subscription?.remove() }
}
}
בניגוד לבונה flow, הפונקציה callbackFlow מאפשרת להפיק ערכים מ-CoroutineContext אחר באמצעות הפונקציה send או מחוץ לקורוטינה באמצעות הפונקציה trySend.
באופן פנימי, callbackFlow משתמש בערוץ, שדומה מאוד מבחינה קונספטואלית לתור חוסם.
ערוץ מוגדר עם קיבולת, מספר האלמנטים המקסימלי שאפשר לשמור במאגר. הקיבולת של הערוץ שנוצר ב-callbackFlow היא 64 אלמנטים כברירת מחדל. כשמנסים להוסיף אלמנט חדש לערוץ מלא, send משעה את ההפקה עד שיש מקום לאלמנט החדש, ואילו trySend לא מוסיף את האלמנט לערוץ ומחזיר את false באופן מיידי.
trySend מוסיף מיד את האלמנט שצוין לערוץ, רק אם זה לא מפר את מגבלות הקיבולת שלו, ואז מחזיר את התוצאה של הפעולה שבוצעה בהצלחה.
מקורות מידע נוספים על תהליכי עבודה
- בדיקת תהליכים ב-Kotlin ב-Android
-
StateFlowו-SharedFlow - מקורות מידע נוספים על שגרות משנה (coroutines) ועל Flow ב-Kotlin