
WorkManager umożliwia tworzenie i dodawanie do kolejki łańcucha zadań, który określa wiele zadań zależnych i definiuje kolejność ich wykonywania. Ta funkcja jest szczególnie przydatna, gdy trzeba wykonać kilka zadań w określonej kolejności.
Aby utworzyć łańcuch zadań, możesz użyć
WorkManager.beginWith(OneTimeWorkRequest)
lub
WorkManager.beginWith(List<OneTimeWorkRequest>)
, które zwracają instancję
WorkContinuation.
Następnie za pomocą WorkContinuation możesz dodać zależne OneTimeWorkRequest
instancje za pomocą
then(OneTimeWorkRequest)
lub
then(List<OneTimeWorkRequest>)
.
Każde wywołanie WorkContinuation.then(...) zwraca nową instancję WorkContinuation. Jeśli dodasz List instancji OneTimeWorkRequest, te żądania mogą być wykonywane równolegle.
Na koniec możesz użyć metody
WorkContinuation.enqueue(), aby enqueue() łańcuch WorkContinuation.
Przyjrzyjmy się przykładowi. W tym przykładzie skonfigurowano 3 różne zadania Worker, które mają być wykonywane (potencjalnie równolegle). Wyniki tych zadań są następnie łączone i przekazywane do zadania Worker dotyczącego buforowania. Na koniec dane wyjściowe tego zadania są przekazywane do zadania Worker dotyczącego przesyłania, które przesyła wyniki na serwer zdalny.
Kotlin
WorkManager.getInstance(myContext) // Candidates to run in parallel .beginWith(listOf(plantName1, plantName2, plantName3)) // Dependent work (only runs after all previous work in chain) .then(cache) .then(upload) // Call enqueue to kick things off .enqueue()
Java
WorkManager.getInstance(myContext) // Candidates to run in parallel .beginWith(Arrays.asList(plantName1, plantName2, plantName3)) // Dependent work (only runs after all previous work in chain) .then(cache) .then(upload) // Call enqueue to kick things off .enqueue();
Łączenie danych wejściowych
Gdy połączysz instancje OneTimeWorkRequest, dane wyjściowe żądań zadań nadrzędnych są przekazywane jako dane wejściowe do zadań podrzędnych. W powyższym przykładzie dane wyjściowe plantName1, plantName2 i plantName3 zostałyby przekazane jako dane wejściowe do żądania cache.
Aby zarządzać danymi wejściowymi z wielu żądań zadań nadrzędnych, WorkManager używa
InputMerger.
WorkManager udostępnia 2 różne typy InputMerger:
OverwritingInputMergerpróbuje dodać wszystkie klucze ze wszystkich danych wejściowych do danych wyjściowych. W przypadku konfliktów zastępuje wcześniej ustawione klucze.ArrayCreatingInputMergerpróbuje połączyć dane wejściowe, tworząc w razie potrzeby tablice.
Jeśli masz bardziej konkretny przypadek użycia, możesz napisać własny, tworząc podklasę InputMerger.
OverwritingInputMerger
OverwritingInputMerger to domyślna metoda łączenia. Jeśli w przypadku łączenia wystąpią konflikty kluczy, najnowsza wartość klucza zastąpi wszystkie poprzednie wersje w wynikowych danych wyjściowych.
Jeśli na przykład dane wejściowe roślin mają klucz pasujący do odpowiednich
nazw zmiennych ("plantName1", "plantName2", i "plantName3"), dane przekazywane do zadania cache będą zawierać 3 pary klucz-wartość.
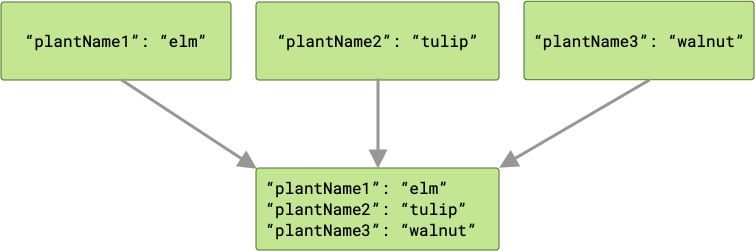
W przypadku konfliktu „wygrywa” ostatnie zadanie, które zostało wykonane, a jego wartość jest przekazywana do cache.
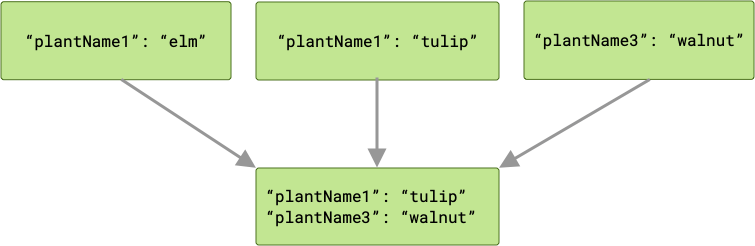
Ponieważ żądania zadań są wykonywane równolegle, nie masz gwarancji kolejności ich wykonywania. W powyższym przykładzie plantName1 może mieć
wartość "tulip" lub "elm", w zależności od tego, która wartość zostanie zapisana
jako ostatnia. Jeśli istnieje ryzyko konfliktu kluczy i musisz zachować wszystkie dane wyjściowe w przypadku łączenia, lepszym rozwiązaniem może być ArrayCreatingInputMerger.
ArrayCreatingInputMerger
W powyższym przykładzie, ponieważ chcemy zachować dane wyjściowe wszystkich zadań dotyczących nazw roślin, powinniśmy użyć ArrayCreatingInputMerger.
Kotlin
val cache: OneTimeWorkRequest = OneTimeWorkRequestBuilder<PlantWorker>() .setInputMerger(ArrayCreatingInputMerger::class) .setConstraints(constraints) .build()
Java
OneTimeWorkRequest cache = new OneTimeWorkRequest.Builder(PlantWorker.class) .setInputMerger(ArrayCreatingInputMerger.class) .setConstraints(constraints) .build();
ArrayCreatingInputMerger łączy każdy klucz z tablicą. Jeśli każdy klucz jest unikalny, wynikiem jest seria tablic jednoelementowych.
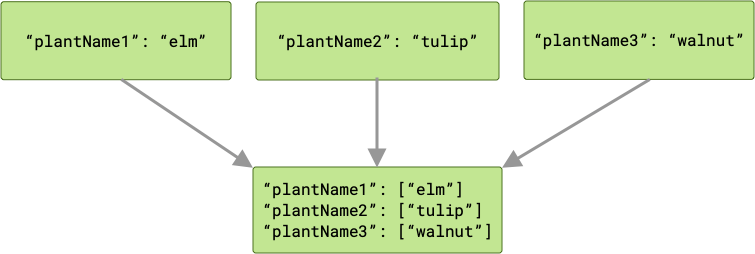
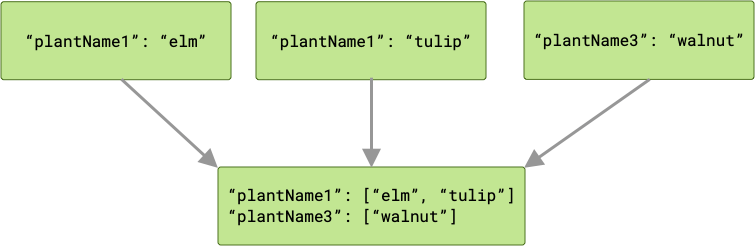
Jeśli wystąpią kolizje kluczy, wszystkie odpowiednie wartości zostaną zgrupowane w tablicy.
Łączenie i stany zadań
Łańcuchy OneTimeWorkRequest są wykonywane sekwencyjnie, o ile ich zadania zostaną wykonane (czyli zwrócą Result.success()). Żądania zadań mogą się nie powieść lub zostać anulowane podczas wykonywania, co ma wpływ na zależne żądania zadań.
Gdy pierwsze OneTimeWorkRequest zostanie dodane do kolejki w łańcuchu żądań zadań, wszystkie kolejne żądania zadań zostaną zablokowane do czasu wykonania zadania pierwszego żądania.
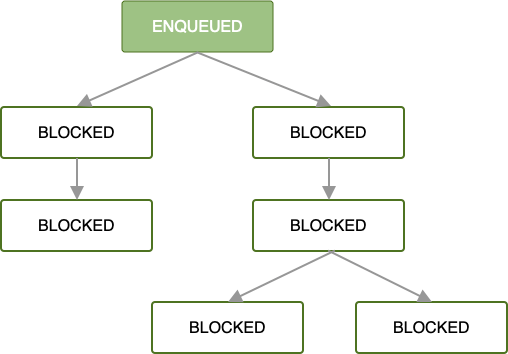
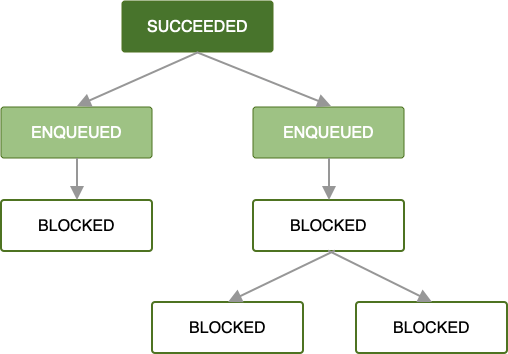
Gdy pierwsze żądanie zadania zostanie dodane do kolejki i spełnione zostaną wszystkie ograniczenia zadania, zacznie się wykonywać. Jeśli zadanie zostanie wykonane w głównym
OneTimeWorkRequest lub List<OneTimeWorkRequest> (czyli zwróci
Result.success()), do kolejki zostanie dodany następny zestaw zależnych żądań zadań.
Dopóki każde żądanie zadania zostanie wykonane, ten sam wzorzec będzie się powtarzać w pozostałej części łańcucha żądań zadań, aż wszystkie zadania w łańcuchu zostaną wykonane. Jest to najprostszy i często preferowany przypadek, ale równie ważne jest obsługiwanie stanów błędów.
Gdy podczas przetwarzania żądania zadania przez worker wystąpi błąd, możesz ponowić próbę wykonania tego żądania zgodnie z zdefiniowaną przez siebie strategią wycofywania. Ponowienie próby wykonania żądania, które jest częścią łańcucha, oznacza, że ponowiona zostanie tylko próba wykonania tego żądania z przekazanymi do niego danymi wejściowymi. Nie wpłynie to na żadne zadania wykonywane równolegle.
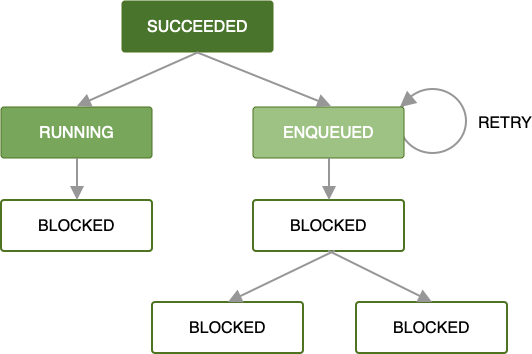
Więcej informacji o definiowaniu niestandardowych strategii ponawiania prób znajdziesz w sekcji Strategia ponawiania prób i czas do ponowienia Policy.
Jeśli strategia ponawiania prób jest niezdefiniowana lub wyczerpana albo w inny sposób osiągniesz jakiś
stan, w którym OneTimeWorkRequest zwraca Result.failure(), to to
żądanie zadania i wszystkie zależne żądania zadań zostaną oznaczone jako FAILED.
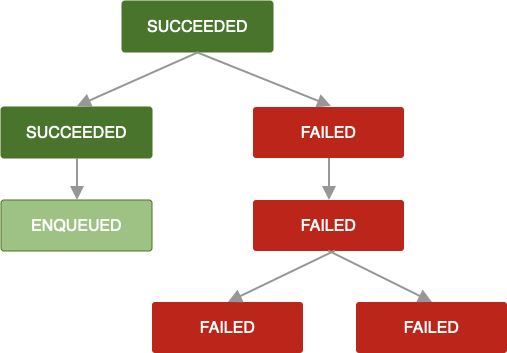
Ta sama logika obowiązuje, gdy OneTimeWorkRequest zostanie anulowane. Wszystkie zależne żądania zadań są również oznaczane jako CANCELLED, a ich zadania nie będą wykonywane.
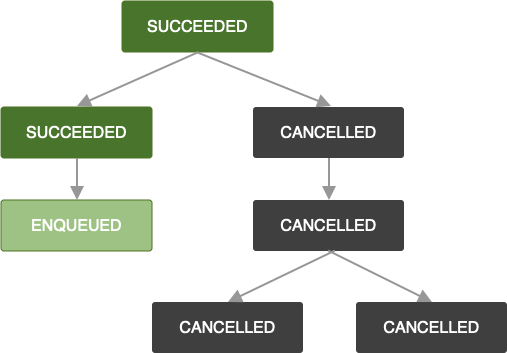
Pamiętaj, że jeśli dodasz więcej żądań zadań do łańcucha, w którym wystąpił błąd lub który został anulowany, nowo dodane żądanie zadania również zostanie oznaczone odpowiednio jako FAILED lub CANCELLED. Jeśli chcesz rozszerzyć zadanie
istniejącego łańcucha, zapoznaj się z sekcją APPEND_OR_REPLACE w
ExistingWorkPolicy.
Podczas tworzenia łańcuchów żądań zadań zależne żądania zadań powinny definiować strategie ponawiania prób, aby zapewnić terminowe wykonanie zadania. Nieudane żądania zadań mogą spowodować niekompletne łańcuchy lub nieoczekiwany stan.
Więcej informacji znajdziesz w sekcji Anulowanie i zatrzymywanie zadań.