


צוות Android Runtime (ART) קיצר את משך הזמן לקימפול ב-18% בלי לפגוע בקוד המהודר או בנסיגות בזיכרון השיא. השיפור הזה הוא חלק מהיוזמה שלנו לשנת 2025 לשיפור משך הזמן לקימפול בלי להתפשר על שימוש בזיכרון או על איכות הקוד המהודר.
אופטימיזציה של מהירות ההידור חיונית ל-ART. לדוגמה, כשמבצעים קומפילציה בזמן אמת (JIT), היא משפיעה ישירות על היעילות של האפליקציות ועל הביצועים הכוללים של המכשיר. הידור מהיר יותר מקצר את הזמן עד שהאופטימיזציות מתחילות לפעול, וכך חוויית המשתמש חלקה ומגיבה יותר. בנוסף, גם ב-JIT וגם ב-AOT, שיפורים במהירות בזמן ההידור מובילים לצריכת משאבים מופחתת במהלך תהליך ההידור, מה שמשפר את חיי הסוללה ואת הטמפרטורה של המכשיר, במיוחד במכשירים ברמה נמוכה.
חלק מהשיפורים האלה במהירות ההידור הושקו בגרסת Android מיוני 2025, והשאר יהיו זמינים בגרסת Android שתצא בסוף השנה. בנוסף, כל משתמשי Android בגרסה 12 ומעלה יכולים לקבל את השיפורים האלה באמצעות עדכונים ראשיים.
אופטימיזציה של מהדר האופטימיזציה
אופטימיזציה של קומפיילר היא תמיד משחק של פשרות. אי אפשר לקבל מהירות בחינם, צריך לוותר על משהו. הצבנו לעצמנו מטרה ברורה ומאתגרת: להאיץ את המקמפל, אבל לעשות את זה בלי לגרום לנסיגות בזיכרון, וחשוב מכך, בלי לפגוע באיכות הקוד שהוא מייצר. אם הקומפיילר מהיר יותר אבל האפליקציות פועלות לאט יותר, נכשלנו.
המשאב היחיד שהיינו מוכנים להשקיע היה זמן הפיתוח שלנו, כדי לחקור לעומק ולמצוא פתרונות חכמים שעומדים בקריטריונים המחמירים האלה. בואו נבחן מקרוב איך אנחנו פועלים כדי למצוא תחומים לשיפור, וגם כדי למצוא את הפתרונות הנכונים לבעיות השונות.
איתור אופטימיזציות אפשריות שכדאי לבצע
כדי להתחיל לבצע אופטימיזציה של מדד, צריך קודם למדוד אותו. אחרת, לא תוכלו לדעת אם שיפרתם אותו או לא. למזלנו, משך הזמן לקימפול די עקבי כל עוד נוקטים אמצעי זהירות מסוימים, כמו שימוש באותו מכשיר למדידה לפני ואחרי שינוי, ולוודא שלא מתבצעת הגבלת מהירות (throttling) תרמית במכשיר. בנוסף, יש לנו גם מדידות דטרמיניסטיות כמו נתונים סטטיסטיים של קומפיילר שעוזרים לנו להבין מה קורה מתחת לפני השטח.
המשאב שהקרבנו לטובת השיפורים האלה היה זמן הפיתוח שלנו, ולכן רצינו לבצע איטרציות מהר ככל האפשר. המשמעות היא שלקחנו כמה אפליקציות מייצגות (שילוב של אפליקציות מצד ראשון, אפליקציות מצד שלישי ומערכת ההפעלה Android עצמה) כדי ליצור אב טיפוס של פתרונות. בהמשך, אימתנו שההטמעה הסופית הייתה משתלמת באמצעות בדיקות ידניות ואוטומטיות נרחבות.
עם קבוצת קובצי ה-APK שנבחרו בקפידה, הפעלנו קומפילציה ידנית באופן מקומי, קיבלנו פרופיל של הקומפילציה והשתמשנו ב-pprof כדי להמחיש איפה אנחנו משקיעים את הזמן שלנו.
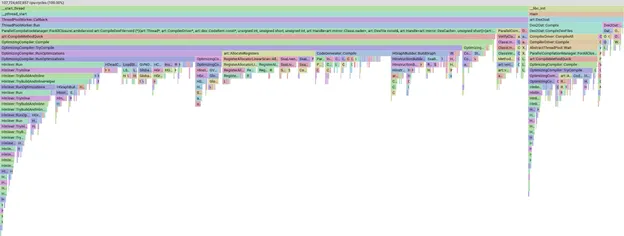
דוגמה לתרשים להבות של פרופיל ב-pprof
הכלי pprof הוא כלי רב עוצמה שמאפשר לנו לפלח, לסנן ולמיין את הנתונים כדי לראות, לדוגמה, אילו שלבים או שיטות של קומפיילר צורכים הכי הרבה זמן. לא נפרט על pprof עצמו, רק נציין שאם הסרגל גדול יותר, המשמעות היא שהקומפילציה ארכה יותר זמן.
אחת מהתצוגות האלה היא התצוגה 'מלמטה למעלה', שבה אפשר לראות אילו שיטות צורכות הכי הרבה זמן. בתמונה שלמטה אפשר לראות שיטה בשם Kill, שמהווה יותר מ-1% ממשך הזמן לקימפול. בהמשך הפוסט בבלוג נדון גם בכמה מהשיטות המובילות האחרות.
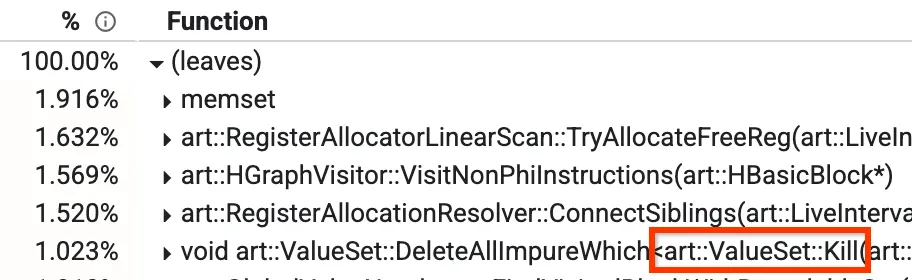
תצוגה של פרופיל מלמטה למעלה
במהדר האופטימיזציה שלנו יש שלב שנקרא Global Value Numbering (מספור ערכים גלובלי, GVN). לא צריך לדאוג לגבי מה שהיא עושה באופן כללי, אבל החלק הרלוונטי הוא לדעת שיש לה שיטה שנקראת Kill, והיא תמחק חלק מהצמתים בהתאם למסנן. הפעולה הזו אורכת זמן רב כי צריך לעבור על כל הצמתים ולבדוק אותם אחד אחד. שמנו לב שיש מקרים שבהם אנחנו יודעים מראש שהבדיקה תחזיר ערך שקר, לא משנה אילו צמתים פעילים לנו באותו רגע. במקרים כאלה, אנחנו יכולים לדלג על איטרציות לגמרי, ולהקטין את שיעור השגיאות מ-1.023% לכ-0.3%, ולשפר את זמן הריצה של GVN בכ-15%.
הטמעה של אופטימיזציות משתלמות
הסברנו איך למדוד ואיך לזהות איפה הזמן מנוצל, אבל זו רק ההתחלה. השלב הבא הוא אופטימיזציה של הזמן שמוקדש לקומפילציה.
בדרך כלל, במקרה כמו `Kill` שמופיע למעלה, נבדוק איך אנחנו חוזרים על הצמתים וננסה לעשות את זה מהר יותר. למשל, על ידי ביצוע פעולות במקביל או שיפור האלגוריתם עצמו. למעשה, זה מה שניסינו בהתחלה, ורק כשלא מצאנו מה לעשות, הייתה לנו תובנה שהפתרון הוא (במקרים מסוימים) לא לחזור על הפעולה בכלל. כשמבצעים אופטימיזציות מהסוג הזה, קל להתמקד בפרטים הקטנים ולפספס את התמונה הגדולה.
במקרים אחרים, השתמשנו בכמה טכניקות שונות, כולל:
- שימוש בהיוריסטיקה כדי להחליט אם אופטימיזציה מסוימת לא תניב תוצאות משמעותיות ולכן אפשר לדלג עליה
- שימוש במבני נתונים נוספים כדי לשמור במטמון נתונים מחושבים
- שינוי מבני הנתונים הנוכחיים כדי לשפר את המהירות
- חישוב התוצאות מתבצע רק כשצריך, כדי למנוע מקרים של לולאות אינסופיות
- להשתמש בהפשטה הנכונה – תכונות מיותרות עלולות להאט את הקוד
- כדי שלא תצטרכו לרדוף אחרי סמן שמשתמשים בו לעיתים קרובות במהלך טעינות רבות
איך אפשר לדעת אם כדאי לבצע את האופטימיזציות?
החלק הכי טוב הוא שלא צריך. אחרי שמזהים שאזור מסוים צורך הרבה זמן קומפילציה, ואחרי שמשקיעים זמן פיתוח בניסיון לשפר אותו, לפעמים פשוט לא מוצאים פתרון. יכול להיות שאין מה לעשות, שייקח יותר מדי זמן להטמיע את השינוי, שהוא יגרום לירידה משמעותית ברגרסיה אחרת, שהוא יגדיל את מורכבות ה-code base וכו'. כל אופטימיזציה מוצלחת שמופיעה בפוסט הזה היא אחת מתוך אינספור אופטימיזציות שלא יצאו לפועל.
אם אתם במצב דומה, נסו להעריך עד כמה תשפרו את המדד על ידי ביצוע כמה שפחות עבודה. כלומר, בסדר הבא:
- הערכה באמצעות מדדים שכבר אספתם, או סתם תחושת בטן
- הערכה באמצעות אב-טיפוס מהיר ופשוט
- הטמעת פתרון.
אל תשכחו להעריך את החסרונות של הפתרון. לדוגמה, אם אתם מתכוונים להסתמך על מבני נתונים נוספים, כמה זיכרון אתם מוכנים להקצות?
בחינה מעמיקה
בלי הקדמות מיותרות, נבחן כמה מהשינויים שהטמענו.
יישמנו שינוי כדי לבצע אופטימיזציה של שיטה שנקראת FindReferenceInfoOf. השיטה הזו ביצעה חיפוש לינארי של וקטור כדי למצוא רשומה. עדכנו את מבנה הנתונים כך שיעבור אינדוקס לפי מזהה ההוראה, כדי ש-FindReferenceInfoOf יהיה O(1) במקום O(n). בנוסף, הקצנו מראש את הווקטור כדי למנוע שינוי גודל. הגדלנו קצת את הזיכרון כי היינו צריכים להוסיף שדה נוסף שסופר כמה רשומות הוספנו לווקטור, אבל זה היה שינוי קטן כי השימוש בזיכרון לא גדל. כך קיצרנו את שלב LoadStoreAnalysis ב-34-66%, מה שמוביל לשיפור של כ-0.5-1.8% במשך הזמן לקימפול.
יש לנו הטמעה מותאמת אישית של HashSet שבה אנחנו משתמשים בכמה מקומות. יצירת מבנה הנתונים הזה ארכה זמן רב, וגילינו למה. לפני שנים רבות, מבנה הנתונים הזה שימש רק בכמה מקומות שבהם נעשה שימוש ב-HashSet גדול מאוד, והוא עבר שינויים כדי להיות מותאם לשימוש הזה. אבל כיום משתמשים בו בכיוון ההפוך, עם כמה רשומות בלבד ועם משך חיים קצר. המשמעות היא שבזבזנו מחזורים ביצירת HashSet ענק, אבל השתמשנו בו רק לכמה רשומות לפני שהשלכנו אותו. השינוי הזה שיפר את משך הזמן לקימפול בכ-1.3-2%. בנוסף, השימוש בזיכרון ירד בכ-0.5-1% כי לא השתמשנו במבני נתונים גדולים כמו קודם.
שיפרנו את משך הזמן לקימפול בכ-0.5% עד 1% על ידי העברת מבני נתונים באמצעות הפניה אל פונקציית ה-lambda כדי להימנע מהעתקה שלהם. זה היה משהו שפספסנו בבדיקה המקורית, והוא נשאר בבסיס הקוד שלנו במשך שנים. בזכות בדיקת הפרופילים ב-pprof, שמנו לב שהשיטות האלה יוצרות ומבטלות הרבה מבני נתונים, ולכן חקרנו אותן וביצענו אופטימיזציה שלהן.
האצנו את השלב שבו נכתבת התוצאה המהודרת על ידי שמירת ערכים מחושבים במטמון, מה שהוביל לשיפור של כ-1.3% עד 2.8% ב משך הזמן לקימפול הכולל. לצערנו, העומס של ניהול החשבונות היה גדול מדי, והבדיקות האוטומטיות שלנו התריעו על רגרסיה בזיכרון. בהמשך, בדקנו שוב את אותו קוד והטמענו גרסה חדשה שטיפלה לא רק בנסיגה בזיכרון אלא גם שיפרה את משך הזמן לקימפול בעוד כ-0.5-1.8%! בשינוי השני הזה נאלצנו לשנות את המבנה של השלב הזה ולחשוב מחדש איך הוא צריך לפעול, כדי להיפטר מאחד משני מבני הנתונים.
יש לנו שלב בקומפיילר האופטימיזציה שבו מתבצעת החלפה של קריאות לפונקציות כדי לשפר את הביצועים. כדי לבחור אילו שיטות להטמיע, אנחנו משתמשים בהיוריסטיקה לפני שאנחנו מבצעים חישובים, ובבדיקות סופיות אחרי שאנחנו מבצעים עבודה אבל לפני שאנחנו מסיימים את ההטמעה. אם אחד מהם יזהה שההטמעה לא כדאית (לדוגמה, אם יתווספו יותר מדי הוראות חדשות), לא נבצע הטמעה של קריאת השיטה.
העברנו שתי בדיקות מהקטגוריה 'בדיקות סופיות' לקטגוריה 'היוריסטיקה' כדי להעריך אם ההטמעה תצליח או לא, לפני שנבצע חישובים יקרים מבחינת זמן. מכיוון שמדובר באומדן, הוא לא מושלם, אבל וידאנו שהיוריסטיקות החדשות שלנו מכסות 99.9% ממה שהיה מוטבע לפני כן, בלי להשפיע על הביצועים. אחת מהשיטות ההיוריסטיות החדשות הייתה לגבי הרישומים הנדרשים של DEX (שיפור של כ-0.2% עד 1.3%), והשנייה לגבי מספר ההוראות (שיפור של כ-2%).
יש לנו הטמעה מותאמת אישית של BitVector שבה אנחנו משתמשים בכמה מקומות. החלפנו את המחלקה BitVector שניתן לשנות את הגודל שלה במחלקה BitVectorView פשוטה יותר עבור וקטורים מסוימים של ביטים בגודל קבוע. כך נמנעים משימוש בכמה הפניות עקיפות ומבדיקות של טווחים בזמן הריצה, ומאיצים את יצירת האובייקטים של וקטור הביטים.
בנוסף, המחלקה BitVectorView עברה שימוש בתבניות (templatized) בסוג האחסון הבסיסי (במקום להשתמש תמיד ב-uint32_t כמו ב-BitVector הישן). ההגדרה הזו מאפשרת לבצע פעולות מסוימות, כמו Union(), על כמות כפולה של ביטים בפלטפורמות 64-bit. המדגמים של הפונקציות המושפעות קוצצו ביותר מ-1% בסך הכול במהלך קומפילציה של Android OS. השינוי הזה בוצע בכמה שלבים [1, 2, 3, 4, 5, 6]
אם היינו מדברים בפירוט על כל האופטימיזציות, היינו נשארים כאן כל היום. אם תרצה לבצע אופטימיזציות נוספות, כדאי לעיין בשינויים אחרים שהטמענו:
- הוספת ניהול ספרים כדי לשפר את זמני הקומפילציה בכ-0.6% עד 1.6%.
- מחשבים נתונים בצורה עצלה כדי להימנע ממחזורים, אם אפשר.
- שכתוב הקוד כדי לדלג על עבודת חישוב מראש אם לא נעשה בה שימוש.
- כדאי להימנע משרשרות טעינה תלויות מסוימות אם אפשר להשיג את המקצה בקלות ממקומות אחרים.
- מקרה נוסף של הוספת בדיקה כדי למנוע עבודה מיותרת.
- מומלץ להימנע מפיצול תכופות בסוג הרישום (ליבה/FP) בהקצאת הרישום.
- מוודאים שחלק מהמערכים מאותחלים בזמן ההידור. אל תסתמכו על clang כדי לעשות זאת.
- מנקים כמה לולאות. כדאי להשתמש בלולאות טווח שאפשר לבצע בהן אופטימיזציה טובה יותר באמצעות clang, כי לא צריך לטעון מחדש את המצביעים הפנימיים של הקונטיינר בגלל תופעות לוואי של הלולאה. מומלץ להימנע מקריאה לפונקציה הווירטואלית `HInstruction::GetInputRecords()` בלולאה באמצעות `InputAt(.)` מוטמעת לכל קלט.
- הימנעו מפונקציות Accept() עבור תבנית המבקר על ידי ניצול אופטימיזציה של קומפיילר.
סיכום
ההתמקדות שלנו בשיפור מהירות ההידור של ART הניבה שיפורים משמעותיים, שהופכים את Android לזורם ויעיל יותר, וגם תורמים לשיפור חיי הסוללה והתכונות התרמיות של המכשיר. באמצעות זיהוי קפדני של אופטימיזציות והטמעה שלהן, הראינו שאפשר להשיג שיפורים משמעותיים בזמן ההידור בלי לפגוע בשימוש בזיכרון או באיכות הקוד.
התהליך שלנו כלל יצירת פרופילים באמצעות כלים כמו pprof, נכונות לחזור על התהליך, ולפעמים אפילו נטישה של דרכים פחות יעילות. המאמצים המשותפים של צוות ART לא רק קיצרו את משך הזמן לקימפול באחוזים משמעותיים, אלא גם הניחו את הבסיס לשיפורים עתידיים.
כל השיפורים האלה זמינים בעדכון Android של סוף שנת 2025, וב-Android מגרסה 12 ומעלה דרך עדכונים ראשיים. אנחנו מקווים שהמידע המעמיק הזה על תהליך האופטימיזציה שלנו מספק תובנות חשובות לגבי המורכבות והיתרונות של הנדסת קומפיילרים.
נכתב על ידי:
להמשך הקריאה
-


חדשות על מוצרים
אנחנו שמחים להודיע על השקת תמיכה רשמית ב-Unreal Engine וב-Godot ל-Android XR. אנחנו משיקים גם כלים חדשים שנועדו לשפר את הפרודוקטיביות ולאפשר יכולות XR חדשות: Android XR Engine Hub ו-Android XR Interaction Framework.
Luke Hopkins • משך הקריאה: 4 דקות
-


חדשות על מוצרים
עם השקת Android 17, אנחנו עוברים לסטנדרט פיתוח ראשון אדפטיבי. המשתמשים שלכם כבר לא מסתמכים על גורם צורה יחיד. במהלך היום הם עוברים בין טלפונים, מכשירים מתקפלים, טאבלטים, מחשבים ניידים, מסכים ברכב וסביבות XR סוחפות.
Fahd Imtiaz • משך הקריאה: 4 דקות
-


חדשות על מוצרים
אנחנו שמחים לשתף אתכם בתכונות של Google TV ובכלים למפתחים שנועדו להגדיל את החשיפה של התוכן שלכם ולהכין את האפליקציה שלכם לחוויות צפייה עתידיות בטלוויזיה.
Paul Lammertsma • משך הקריאה: 4 דקות
כדאי תמיד להיות בעניינים
רוצים לקבל טיפים עדכניים לפיתוח Android ישירות לאימייל כל שבוע?
