
Anúncio do Gemma 4 na prévia para desenvolvedores do AICore
Leitura de 3 minutos


No Google, temos o compromisso de levar os modelos de IA mais eficientes diretamente aos dispositivos Android que você tem no bolso. Hoje, temos o prazer de anunciar o lançamento do nosso modelo aberto de última geração: Gemma 4.
Esses modelos são a base da próxima geração do Gemini Nano. Portanto, o código que você escrever hoje para o Gemma 4 vai funcionar automaticamente em dispositivos com o Gemini Nano 4, que estarão disponíveis ainda este ano. Com o Gemini Nano 4, você vai se beneficiar das nossas otimizações de desempenho adicionais para poder enviar para produção em todo o ecossistema Android com a inferência no dispositivo mais eficiente.
Você pode ter acesso antecipado a esse modelo hoje mesmo na prévia para desenvolvedores do AICore.
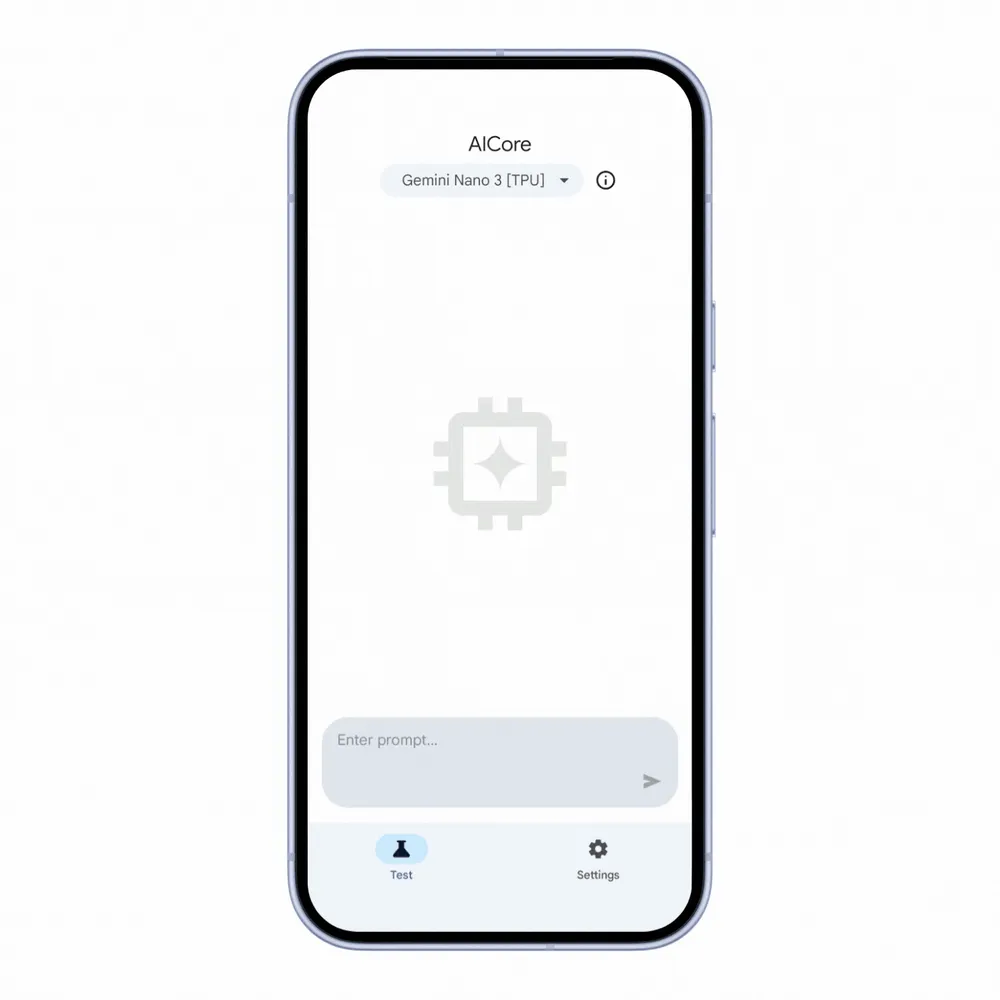
Selecione o modelo rápido do Gemini Nano 4 na interface da prévia para desenvolvedores para conferir a velocidade de inferência incrivelmente rápida em ação antes de escrever qualquer código
Como o Gemma 4 oferece suporte nativo a mais de 140 idiomas, você pode esperar experiências multilíngues e localizadas aprimoradas para seu público global. Além disso, o Gemma 4 oferece desempenho líder do setor com compreensão multimodal, permitindo que seus apps entendam e processem texto, imagens e áudio. Para oferecer o melhor equilíbrio entre desempenho e eficiência, o Gemma 4 no Android está disponível em dois tamanhos:
- E4B:projetado para maior capacidade de raciocínio e tarefas complexas.
- E2B:otimizado para velocidade máxima (3 vezes mais rápido que o modelo E4B) e menor latência.
O novo modelo é até 4 vezes mais rápido que as versões anteriores e usa até 60% menos bateria. A partir de hoje, você pode testar recursos aprimorados, incluindo:
- Raciocínio:agora, os comandos de cadeia de pensamento e as instruções condicionais podem retornar resultados de maior qualidade. Por exemplo: "Determine se o comentário a seguir para um tópico de discussão atende às diretrizes da comunidade. O comentário não atende às diretrizes da comunidade se contiver um ou mais destes motivos_para_sinalização: linguagem obscena, linguagem depreciativa, discurso de ódio". Se a análise atender às diretrizes da comunidade, retorne {true}. Caso contrário, retorne {false, reason_for_flag}."
- Matemática:com melhores habilidades matemáticas, o modelo agora pode responder a perguntas com mais precisão. Por exemplo: "Se eu receber 26 pagamentos por ano, quanto devo contribuir em cada pagamento para atingir minha meta de economia de US $10.000 ao longo de um ano?"
- Compreensão de tempo:o modelo agora é mais capaz de raciocinar sobre o tempo, tornando-o mais preciso para casos de uso que envolvem calendários, lembretes e alarmes. Por exemplo: "O evento é às 18h do dia 18 de agosto, e um lembrete deve ser enviado 10 horas antes do evento. Retorne a hora e a data em que o lembrete deve ser enviado."
- Compreensão de imagens:os casos de uso que envolvem OCR (reconhecimento óptico de caracteres), como compreensão de gráficos, extração de dados visuais e reconhecimento de manuscritos, agora vão retornar resultados mais precisos.
Participe da prévia para desenvolvedores hoje mesmo para baixar esses modelos e começar a criar recursos de próxima geração imediatamente.
Começar a testar o modelo
Você pode testar o modelo sem código seguindo o guia da prévia para desenvolvedores. Se quiser integrar esses modelos diretamente ao seu fluxo de trabalho atual, facilitamos isso. Acesse o Android Studio para refinar seu comando e criar com a API Prompt do Kit de ML. Introduzimos um novo recurso para especificar um modelo, permitindo que você escolha as variantes E2B (rápida) ou E4B (completa) para teste.
// Define the configuration with a specific track and preference val previewFullConfig = generationConfig { modelConfig = ModelConfig { releaseTrack = ModelReleaseTrack.PREVIEW preference = ModelPreference.FULL } } // Initialize the GenerativeModel with the configuration val previewModel = GenerativeModel.getClient(previewFullConfig) // Verify that the specific preview model is available val previewModelStatus = previewModel.checkStatus() if (previewModelStatus == FeatureStatus.AVAILABLE) { // Proceed with inference val response = previewModel.generateContent("If I get 26 paychecks per year, how much I should contribute each paycheck to reach my savings goal of $10k over the course of a year? Return only the amount.") } else { // Handle the case where the preview model is not available // (e.g., print out log statements) }
O que esperar durante a prévia para desenvolvedores
O objetivo desta prévia para desenvolvedores é dar a você um início na refinamento da precisão do comando e exploração de novos casos de uso para seus apps específicos.
Vamos fazer várias atualizações durante o período de prévia, incluindo suporte para chamadas de ferramentas, saída estruturada, comandos do sistema e modo de pensamento na API Prompt, facilitando o aproveitamento total dos novos recursos do Gemma 4, bem como otimizações significativas de desempenho.
Os modelos de prévia estão disponíveis para teste em dispositivos com o AICore. Esses modelos serão executados na geração mais recente de aceleradores de IA especializados do Google, da MediaTek e da Qualcomm Technologies. Em outros dispositivos, os modelos serão executados inicialmente em uma implementação de CPU que não é representativa do desempenho de produção final. Se o dispositivo não tiver o AICore ativado, você também poderá testar esses modelos pelo app AI Edge Gallery. Vamos oferecer suporte a mais dispositivos no futuro.
Primeiros passos
Quer saber o que o Gemma 4 pode fazer pelos seus usuários?
- Ativar: inscreva-se na prévia para desenvolvedores do AICore.
- Baixar:depois de ativar, você pode acionar o download dos modelos mais recentes do Gemma 4 diretamente para o dispositivo de teste compatível.
- Criar:atualize a implementação do Kit de ML para segmentar os novos modelos e comece a criar no Android Studio.
-
 Notícias sobre produtos
Notícias sobre produtosPara ajudar ainda mais a levar seus casos de uso da API Prompt do Kit de ML para produção, temos o prazer de anunciar a otimização automática de comandos (APO, na sigla em inglês) para modelos no dispositivo na Vertex AI. A otimização automática de comandos é uma ferramenta que ajuda você a encontrar automaticamente o comando ideal para seus casos de uso.
Chetan Tekur, Chao Zhao, Paul Zhou, Caren Chang • Leitura de 3 minutos -
 Notícias sobre produtos
Notícias sobre produtosA IA está facilitando a criação de experiências de apps personalizadas que transformam o conteúdo no formato certo para os usuários. Anteriormente, permitimos que os desenvolvedores se integrassem ao Gemini Nano usando as APIs GenAI do Kit de ML, personalizadas para casos de uso específicos, como resumo e descrição de imagens.
Caren Chang, Chengji Yan, Penny Li • Leitura de 2 minutos -

 Notícias sobre produtos
Notícias sobre produtosEm março, apresentamos o Android Bench, nosso ranking de LLMs para tarefas de desenvolvimento do Android no mundo real. Desde então, aprimoramos o benchmark com base no seu feedback, incluindo a avaliação de modelos de peso aberto e a adição de dimensões de custo e eficiência ao ranking.
Zoe Lopez-Latorre • Leitura de 3 minutos
Receba os insights mais recentes sobre desenvolvimento Android na sua caixa de entrada semanalmente.
