
Nowości o produktach
Ulepszanie programowania aplikacji na Androida wspomaganego przez AI i udoskonalanie LLM-ów za pomocą Android Bench
2 minuty czytania


Chcemy, aby tworzenie wysokiej jakości aplikacji na Androida było szybsze i łatwiejsze. Jednym ze sposobów na zwiększenie produktywności jest udostępnienie Ci AI. Wiemy, że zależy Ci na AI, która naprawdę rozumie niuanse platformy Android. Dlatego sprawdzamy, jak LLM-y radzą sobie z zadaniami związanymi z programowaniem aplikacji na Androida. Dziś udostępniliśmy pierwszą wersję Android Bench – oficjalnej tabeli wyników LLM-ów do programowania aplikacji na Androida.
Naszym celem jest udostępnienie twórcom modeli testu porównawczego, który pozwoli im ocenić możliwości LLM-ów w zakresie programowania aplikacji na Androida. Ustanawiając jasną i wiarygodną podstawę tego, jak powinno wyglądać wysokiej jakości programowanie aplikacji na Androida, pomagamy twórcom modeli identyfikować luki i przyspieszać ulepszenia. Dzięki temu deweloperzy mogą wydajniej pracować z większą liczbą przydatnych modeli, które mogą wykorzystywać do wspomagania przez AI. W efekcie w ekosystemie Androida będzie więcej aplikacji wysokiej jakości.
Zaprojektowany z myślą o rzeczywistych zadaniach związanych z programowaniem aplikacji na Androida
Test porównawczy został utworzony na podstawie zestawu zadań z różnych typowych obszarów programowania aplikacji na Androida. Składa się on z rzeczywistych wyzwań o różnym stopniu trudności, pochodzących z publicznych repozytoriów Androida w GitHubie. Scenariusze obejmują m.in. rozwiązywanie problemów związanych ze zmianami powodującymi niezgodność w kolejnych wersjach Androida, zadania specyficzne dla danej domeny, takie jak tworzenie sieci na urządzeniach do noszenia, oraz migrację do najnowszej wersji Jetpack Compose.
Każda ocena polega na próbie naprawienia przez LLM problemu zgłoszonego w zadaniu. Następnie weryfikujemy to za pomocą testów jednostkowych lub testów instrumentacji. To podejście niezależne od modelu pozwala nam mierzyć zdolność modelu do poruszania się po złożonych bazach kodu, rozumienia zależności i rozwiązywania problemów, z którymi spotykasz się na co dzień.
Tę metodologię zweryfikowaliśmy z kilkoma twórcami LLM-ów, w tym z JetBrains.
„Określenie wpływu AI na Androida to ogromne wyzwanie, dlatego cieszymy się, że powstała tak solidna i realistyczna struktura. Aktywnie przeprowadzamy testy porównawcze, ale Android Bench jest wyjątkowym i mile widzianym dodatkiem. Ta metodologia to dokładnie taki rygorystyczny test, jakiego potrzebują teraz deweloperzy aplikacji na Androida”
- Kirill Smelov, szef działu integracji AI w JetBrains.
Pierwsze wyniki Android Bench
W tej pierwszej wersji chcieliśmy zmierzyć wyłącznie skuteczność modelu, a nie skupiać się na korzystaniu z agentów lub narzędzi. Modele były w stanie pomyślnie wykonać 16–72% zadań. To szeroki zakres, który pokazuje, że niektóre LLM-y mają już solidną podstawę wiedzy o Androidzie, a inne mają większe możliwości rozwoju. Niezależnie od tego, na jakim etapie rozwoju są obecnie modele, spodziewamy się dalszych ulepszeń, ponieważ zachęcamy twórców LLM-ów do udoskonalania swoich modeli pod kątem programowania aplikacji na Androida.
LLM-em z najwyższym średnim wynikiem w tej pierwszej wersji jest Gemini 3.1 Pro, a tuż za nim plasuje się Claude Opus 4.6. Możesz wypróbować wszystkie modele, które oceniliśmy pod kątem wspomagania przez AI w projektach na Androida, używając kluczy API w najnowszej stabilnej wersji Android Studio.
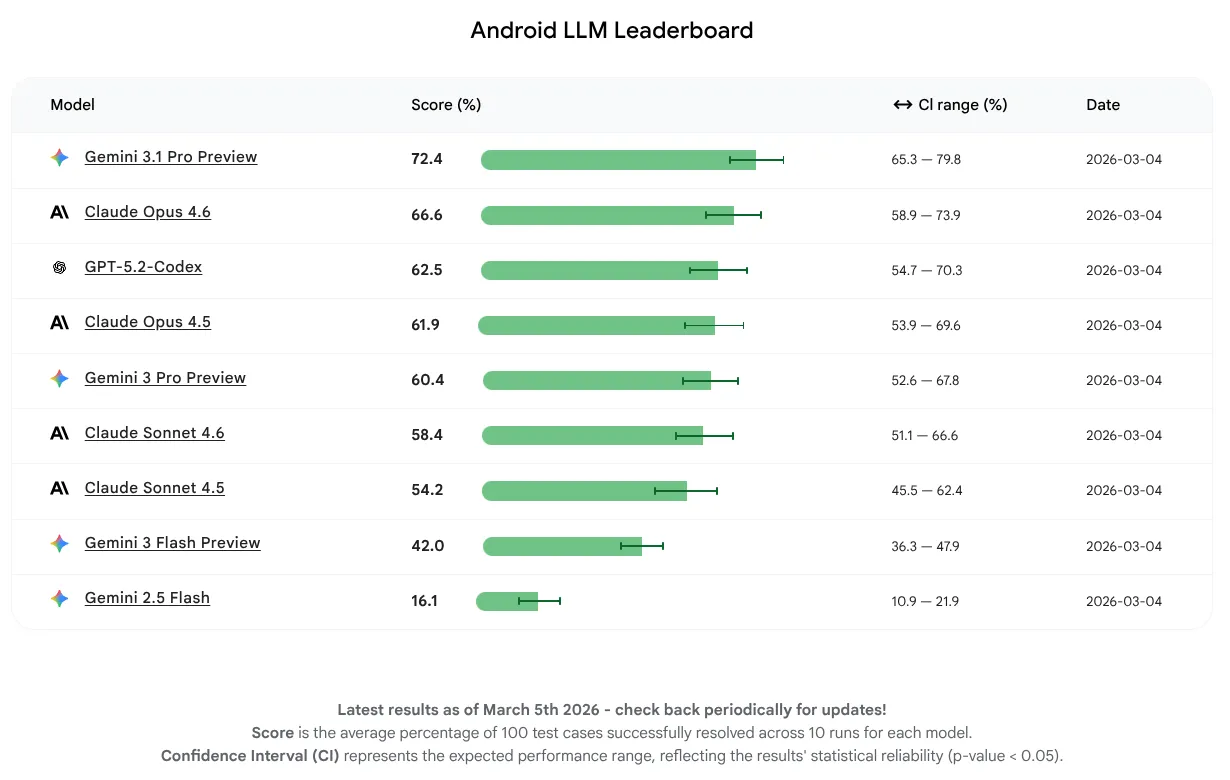
Zapewnianie deweloperom i twórcom LLM-ów przejrzystości
Cenimy sobie otwarte i przejrzyste podejście, dlatego udostępniliśmy naszą metodologię, zbiór danych i platformę testową w GitHubie.
Jednym z wyzwań związanych z każdym publicznym testem porównawczym jest ryzyko zanieczyszczenia danych, czyli sytuacja, w której modele mogły widzieć zadania oceny podczas procesu trenowania. Podjęliśmy środki, aby nasze wyniki odzwierciedlały prawdziwe rozumowanie, a nie zapamiętywanie lub zgadywanie. Obejmują one m.in. dokładną ręczną weryfikację trajektorii agentów oraz integrację ciągu kanarkowego, który ma zniechęcać do trenowania.
W przyszłości będziemy nadal rozwijać naszą metodologię, aby zachować integralność zbioru danych, a także wprowadzać ulepszenia w kolejnych wersjach testu porównawczego, np. zwiększać liczbę i złożoność zadań.
Z niecierpliwością czekamy na to, jak Android Bench może długoterminowo ulepszyć wspomaganie przez AI. Naszą wizją jest wyeliminowanie luki między koncepcją a kodem wysokiej jakości. Budujemy fundamenty przyszłości, w której wszystko, co sobie wyobrazisz, będziesz mógł/mogła stworzyć na Androidzie.
Autor:
Czytaj dalej
-

Nowości o produktach
Podczas Google I/O 2026 ogłosiliśmy 17 najważniejszych nowości dla deweloperów aplikacji na Androida, które dotyczą produktywności opartej na agentach, Compose First jako standardu interfejsu oraz multimediów o wysokiej wydajności i adaptacyjnego programowania dla rozwijającego się ekosystemu.
Matthew McCullough • 8 minut czytania
-

Nowości o produktach
Jak ogłosiliśmy dziś podczas The Android Show, Android przechodzi z systemu operacyjnego do systemu inteligencji, co stwarza więcej możliwości interakcji z Twoimi aplikacjami.
Matthew McCullough • 4 minuty czytania
-
r.r.

Nowości o produktach
Dziś ulepszamy programowanie aplikacji na Androida dzięki Gemma 4, naszemu najnowszemu modelowi open source, który został zaprojektowany z myślą o złożonym rozumowaniu i autonomicznych możliwościach wywoływania narzędzi.
Matthew McCullough • 2 minuty czytania
Bądź na bieżąco
Otrzymuj co tydzień najnowsze informacje o tworzeniu aplikacji na Androida na swoją skrzynkę odbiorczą.
