
La couche d'UI contient l'état lié à l'UI et la logique associée, tandis que la couche de données contient des données d'application et une logique métier. La logique métier donne de la valeur à votre application. Elle se compose de règles métier réelles qui déterminent la manière dont les données d'application doivent être créées, stockées et modifiées.
Cette séparation permet d'utiliser la couche de données sur plusieurs écrans, de partager des informations entre différentes parties de l'application et de reproduire la logique métier en dehors de l'UI pour les tests unitaires. Pour en savoir plus sur les avantages de la couche de données, consultez la page de présentation de l'architecture.
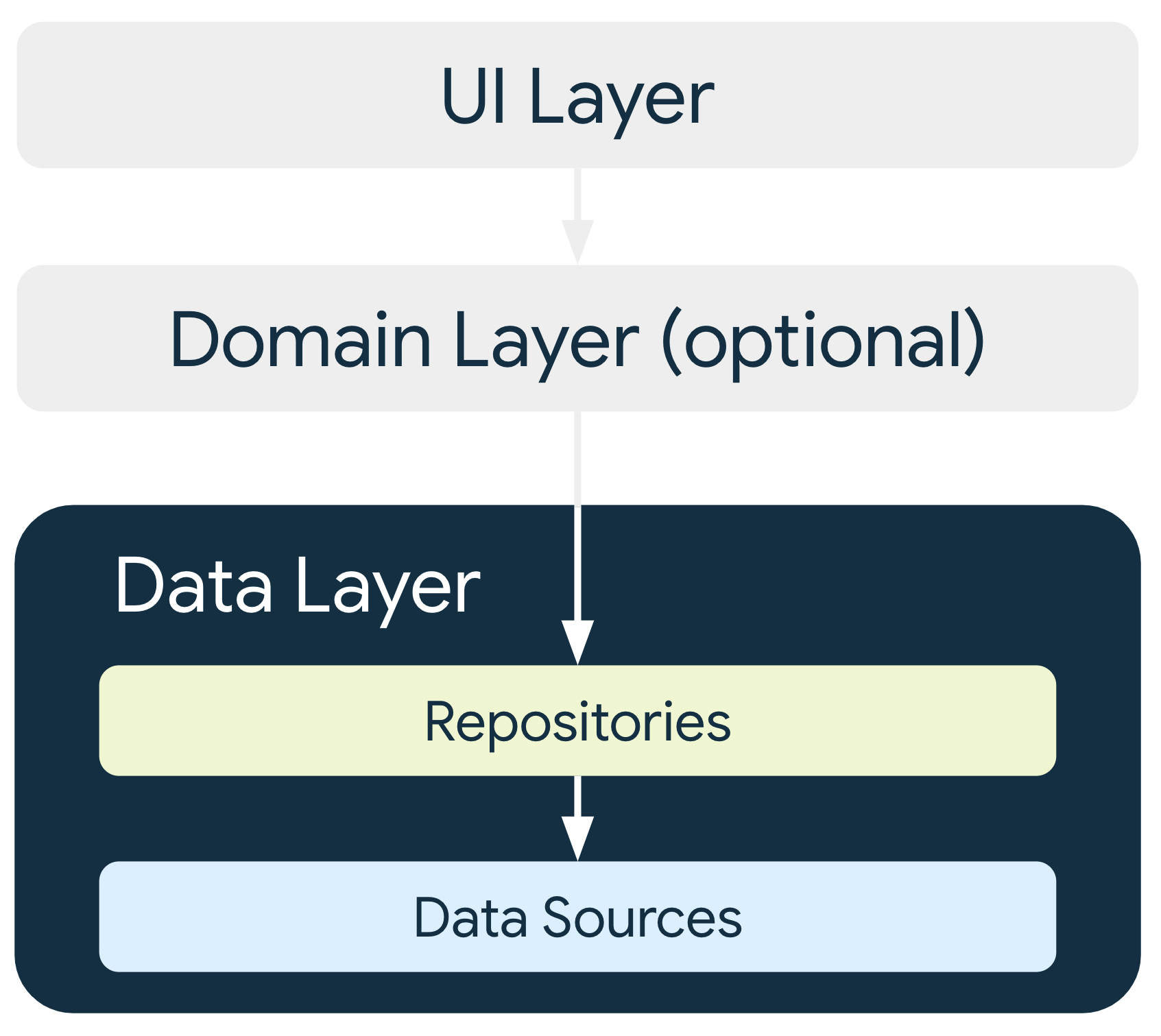
Architecture de la couche de données
La couche de données est constituée de dépôts pouvant contenir de zéro à plusieurs sources de données. Vous devez créer une classe de dépôt pour chaque type de données que vous gérez dans votre application. Par exemple, vous pouvez créer une classe MoviesRepository pour les données liées aux films, ou une classe PaymentsRepository pour les données liées aux paiements.
Les classes de dépôt sont responsables des tâches suivantes :
- Présenter les données au reste de l'application
- Centraliser les modifications apportées aux données
- Résoudre les conflits entre plusieurs sources de données
- Extraire des sources de données du reste de l'application
- Contenir la logique métier
Chaque classe de source de données doit avoir la responsabilité de travailler avec une seule source de données, à savoir un fichier, une source réseau ou une base de données locale. Les classes de sources de données font le lien entre l'application et le système pour les opérations de données.
Les autres couches de la hiérarchie ne doivent jamais disposer d'un accès direct aux sources de données. Les points d'entrée vers la couche de données sont toujours les classes de dépôt. Les classes du conteneur d'état (voir le guide de la couche de l'UI) ou les classes de cas d'utilisation (voir le guide de la couche du domaine) ne doivent jamais avoir de source de données comme dépendance directe. L'utilisation de classes de dépôt comme points d'entrée permet aux différentes couches de l'architecture d'évoluer indépendamment.
Les données exposées par cette couche doivent être immuables afin qu'elles ne puissent pas être altérées par d'autres classes, ce qui risquerait de placer ses valeurs dans un état incohérent. Les données immuables peuvent également être gérées de manière sécurisée par plusieurs threads. Pour en savoir plus, consultez la section d'exécution des threads.
Conformément aux bonnes pratiques d'injection de dépendances, le dépôt accepte les sources de données comme dépendances dans son constructeur :
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) { /* ... */ }
Présenter des API
Les classes de la couche de données présentent généralement des fonctions permettant d'effectuer des appels CRUD (création, lecture, mise à jour et suppression) ponctuels ou d'être averti de modifications de données au fil du temps. La couche de données doit présenter les éléments suivants pour chacun de ces cas :
- Pour les opérations ponctuelles, exposez les fonctions de suspension.
- Pour être informé des modifications de données au fil du temps, exposez les flux.
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) {
val data: Flow<Example> = ...
suspend fun modifyData(example: Example) { ... }
}
Conventions d'attribution de noms dans ce guide
Dans ce guide, les classes de dépôt portent le nom des données dont elles sont responsables. La convention est la suivante :
type de données + dépôt.
Exemples : NewsRepository, MoviesRepository ou PaymentsRepository.
Les classes de sources de données portent le nom des données dont elles sont responsables et de la source qu'elles utilisent. La convention est la suivante :
type de données + type de source + DataSource.
Pour le type de données, utilisez À distance ou Local afin d'être plus large, car les intégrations peuvent changer. Exemples : NewsRemoteDataSource ou NewsLocalDataSource. Pour être plus précis si la source est importante, utilisez le type de la source. Exemples : NewsNetworkDataSource ou NewsDiskDataSource.
Ne nommez pas la source de données en fonction des détails d'intégration (par exemple, UserSharedPreferencesDataSource), car les dépôts qui utilisent cette source de données ne doivent pas savoir comment les données sont enregistrées. Si vous suivez cette règle, vous pouvez modifier l'implémentation de la source de données (en passant de SharedPreferences à DataStore, par exemple) sans affecter la couche qui appelle cette source.
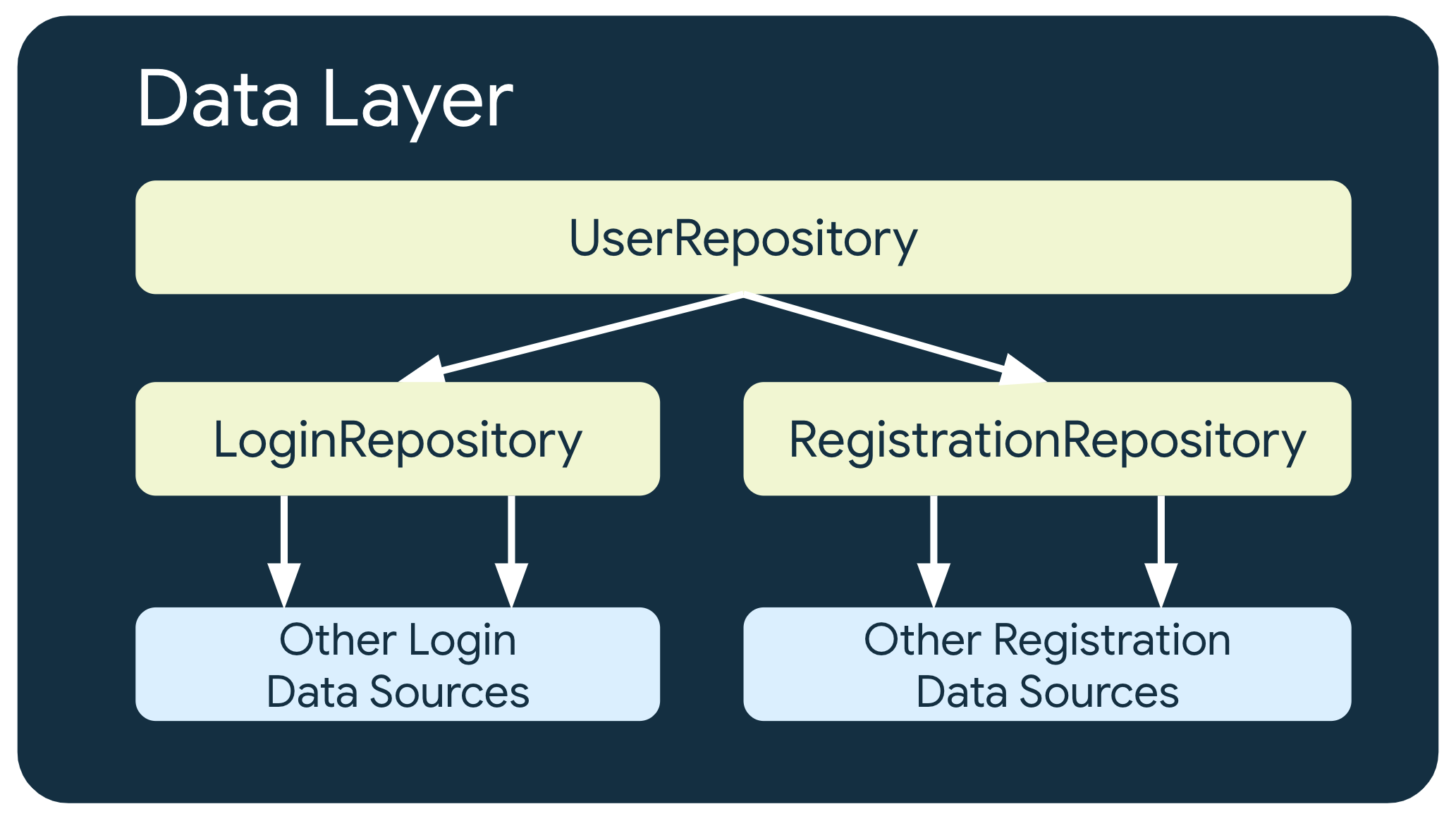
Niveaux multiples de dépôts
Dans certains cas impliquant des exigences d'activités plus complexes, un dépôt peut dépendre d'autres dépôts. Cela peut être dû au fait que les données concernées sont collectées à partir de plusieurs sources ou que la responsabilité doit être encapsulée dans une autre classe de dépôt.
Par exemple, UserRepository, un dépôt qui gère les données d'authentification des utilisateurs, peut dépendre d'autres dépôts tels que LoginRepository et RegistrationRepository pour répondre à ses exigences.
Source de référence
Il est important que chaque dépôt définisse une source unique de référence. La source de référence contient toujours des données cohérentes, correctes et à jour. En fait, les données exposées à partir du dépôt doivent toujours être celles provenant directement de la source de référence.
La source de référence peut être une source de données (par exemple, la base de données) ou même un cache de la mémoire que le dépôt peut contenir. Les dépôts associent différentes sources de données et permettent de résoudre les conflits potentiels entre les sources de données pour mettre à jour la source unique de référence, sur une base régulière ou à la suite d'un événement d'entrée utilisateur.
Les différents dépôts de votre application peuvent avoir différentes sources de référence. Par exemple, la classe LoginRepository peut utiliser son cache comme source de référence et la classe PaymentsRepository peut utiliser la source de données réseau.
Pour fournir une assistance hors connexion en priorité, une source de données locale, telle qu'une base de données, est la source de référence recommandée.
Exécution de threads
Les appels de sources de données et de dépôts doivent être sécurisés en principal, c'est-à-dire sécurisés à partir du thread principal. Ces classes sont chargées de déplacer l'exécution de leur logique vers le thread approprié lorsqu'elles effectuent des opérations de blocage de longue durée. Par exemple, une source de données peut lire à partir d'un fichier ou un dépôt peut effectuer un filtrage coûteux sur une longue liste de manière sécurisée en principal.
Notez que la plupart des sources de données fournissent déjà des API sécurisées en principal, telles que les appels de méthode de suspension fournis par Room, Retrofit ou Ktor. Votre dépôt peut exploiter ces API lorsqu'elles sont disponibles.
Pour en savoir plus sur l'exécution de threads, consultez le guide sur le traitement en arrière-plan. Pour les utilisateurs de Kotlin, il est recommandé d'utiliser des coroutines.
Cycle de vie
Les instances de classes dans la couche de données restent en mémoire tant qu'elles sont accessibles à partir d'une racine de récupération de mémoire, généralement référencées par d'autres objets dans votre application.
Si une classe contient des données en mémoire, par exemple un cache, vous pouvez réutiliser la même instance de cette classe pendant un certain temps. C'est ce que l'on appelle le cycle de vie de l'instance de classe.
Si la responsabilité de la classe est essentielle pour l'ensemble de l'application, vous pouvez étendre une instance de cette classe sur la classe Application. Ainsi, l'instance suit le cycle de vie de l'application. Si vous ne devez réutiliser que la même instance dans un flux particulier de votre application (par exemple, le flux d'inscription ou de connexion), vous devez définir la portée de l'instance à la classe qui détient le cycle de vie de ce flux. Par exemple, vous pouvez définir la portée d'un RegistrationRepository contenant des données en mémoire sur le RegistrationActivity ou sur une pile de retour à l'aide d'un NavEntryDecorator.
Le cycle de vie de chaque instance est un facteur essentiel pour décider comment introduire des dépendances dans votre application. Il est recommandé de suivre les bonnes pratiques d'injection de dépendances qui permettent de gérer les dépendances et où la portée de celles-ci est définie dans des conteneurs de dépendances. Pour en savoir plus sur la portée dans Android, consultez l'article de blog Portée dans Android et Hilt.
Représenter des modèles d'affaires
Les modèles de données que vous souhaitez présenter à partir de la couche de données peuvent constituer un sous-ensemble des informations que vous obtenez à partir des différentes sources de données. Idéalement, les différentes sources de données (en réseau et locales) devraient renvoyer uniquement les informations dont votre application a besoin, mais ce n'est pas souvent le cas.
Par exemple, imaginez un serveur d'API de Google Actualités qui renvoie non seulement les informations de l'article, mais aussi l'historique des modifications, les commentaires des utilisateurs et certaines métadonnées :
data class ArticleApiModel(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val modifications: Array<ArticleApiModel>,
val comments: Array<CommentApiModel>,
val lastModificationDate: Date,
val authorId: Long,
val authorName: String,
val authorDateOfBirth: Date,
val readTimeMin: Int
)
L'application n'a pas besoin d'autant d'informations sur l'article, car elle n'affiche que son contenu à l'écran, avec les informations de base sur son auteur. Il est recommandé de séparer les classes de modèle pour faire en sorte que vos dépôts ne présentent que les données requises par les autres couches de la hiérarchie. Par exemple, voici comment vous pouvez raccourcir l'élément ArticleApiModel du réseau afin de présenter une classe de modèle Article aux couches de domaine et d'interface utilisateur :
data class Article(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val authorName: String,
val readTimeMin: Int
)
Séparer les classes de modèle présente les avantages suivants :
- Économie de mémoire de l'application en limitant les données au strict nécessaire
- Adaptation des types de données externes utilisés par votre application (par exemple, votre application peut utiliser un type de données différent pour représenter des dates)
- Meilleure séparation des préoccupations (par exemple, les membres d'une grande équipe peuvent travailler individuellement sur les couches réseau et d'interface utilisateur d'une fonctionnalité si la classe de modèle est définie au préalable)
Vous pouvez étendre cette pratique et définir des classes de modèle distinctes dans d'autres parties de l'architecture de votre application, par exemple dans les classes de sources de données et les ViewModels. Cependant, cette opération nécessite de définir des classes et une logique supplémentaires que vous devez décrire et tester correctement. Il est au minimum recommandé de créer de nouveaux modèles au cas où une source de données reçoit des données qui ne correspondent pas aux attentes du reste de votre application.
Types d'opérations sur les données
La couche de données peut gérer des types d'opérations qui varient en fonction de leur importance : opérations sur l'interface utilisateur, sur l'application et à des fins professionnelles.
Opérations sur l'interface utilisateur
Les opérations sur l'interface utilisateur ne sont pertinentes que lorsque l'utilisateur se trouve sur un écran spécifique. Elles sont annulées lorsqu'il quitte cet écran. Un exemple affiche certaines données obtenues à partir de la base de données.
Les opérations sur l'interface utilisateur sont généralement déclenchées par la couche d'interface utilisateur et suivent le cycle de vie de l'appelant (par exemple, le cycle de vie de ViewModel). Consultez la section Envoyer une requête réseau pour obtenir un exemple d'opération sur l'interface utilisateur.
Opérations sur l'application
Les opérations sur l'application sont pertinentes tant que l'application est ouverte. Si l'application est fermée ou si le processus est arrêté, ces opérations sont annulées. Par exemple, vous pouvez mettre en cache le résultat d'une requête réseau afin de pouvoir l'utiliser ultérieurement si nécessaire. Pour en savoir plus, consultez la section Implémenter la mise en cache des données en mémoire.
Ces opérations suivent généralement le cycle de vie de la classe Application ou la couche de données. Pour obtenir un exemple, consultez la section Prolonger une opération plus longtemps qu'affiché à l'écran.
Opérations à des fins professionnelles
Les opérations à des fins professionnelles ne peuvent être annulées. Elles doivent survivre à l'arrêt du processus. Il s'agit par exemple de terminer l'importation d'une photo que l'utilisateur souhaite publier sur son profil.
Nous vous recommandons d'utiliser WorkManager pour les opérations à des fins professionnelles. Pour en savoir plus, consultez la section Planifier des tâches à l'aide de WorkManager.
Présenter des erreurs
Les interactions avec des dépôts et des sources de données peuvent réussir ou générer une exception en cas d'erreur. Pour les coroutines et les flux, utilisez le mécanisme intégré de gestion des erreurs de Kotlin. Pour les erreurs susceptibles d'être déclenchées par des fonctions de suspension, utilisez des blocs try/catch, le cas échéant. Pour les flux, utilisez l'opérateur catch. Avec cette approche, la couche d'UI doit gérer les exceptions lorsqu'elle appelle la couche de données.
La couche de données peut comprendre et gérer différents types d'erreurs et les présenter à l'aide d'exceptions personnalisées (UserNotAuthenticatedException, par exemple).
Pour en savoir plus sur les erreurs dans les coroutines, consultez l'article de blog Exceptions dans les coroutines.
Tâches courantes
Les sections suivantes présentent des exemples d'utilisation et d'architecture de la couche de données pour effectuer certaines tâches courantes dans les applications Android. Ces exemples sont basés sur l'application typique Google Actualités mentionnée précédemment dans le guide.
Envoyer une requête réseau
L'envoi d'une requête réseau est l'une des tâches les plus courantes d'une application Android. L'application Google Actualités doit présenter à l'utilisateur les dernières actualités extraites depuis le réseau. L'application a donc besoin d'une classe de source de données (NewsRemoteDataSource) pour gérer les opérations réseau. Pour présenter les informations au reste de l'application, le dépôt NewsRepository qui gère les opérations sur les données d'actualités est créé.
La condition est que les dernières actualités doivent toujours être mises à jour lorsque l'utilisateur ouvre l'écran. Il s'agit donc d'une opération sur l'interface utilisateur.
Créer la source de données
La source de données doit présenter une fonction qui renvoie les dernières actualités, à savoir une liste d'instances ArticleHeadline. La source de données doit fournir un moyen sécurisé en principal de récupérer les dernières actualités depuis le réseau. Pour ce faire, elle doit utiliser une dépendance sur CoroutineDispatcher ou Executor pour y exécuter la tâche.
Une requête réseau est un appel ponctuel géré par une nouvelle méthode fetchLatestNews() :
class NewsRemoteDataSource(
private val newsApi: NewsApi,
private val ioDispatcher: CoroutineDispatcher
) {
/**
* Fetches the latest news from the network and returns the result.
* This executes on an IO-optimized thread pool, the function is main-safe.
*/
suspend fun fetchLatestNews(): List<ArticleHeadline> =
// Move the execution to an IO-optimized thread since the ApiService
// doesn't support coroutines and makes synchronous requests.
withContext(ioDispatcher) {
newsApi.fetchLatestNews()
}
}
// Makes news-related network synchronous requests.
interface NewsApi {
fun fetchLatestNews(): List<ArticleHeadline>
}
L'interface NewsApi masque l'implémentation du client API réseau, peu importe que l'interface repose sur Retrofit ou HttpURLConnection. Le recours aux interfaces rend les intégrations d'API interchangeables dans votre application.
Créer le dépôt
Comme aucune logique supplémentaire n'est nécessaire dans la classe de dépôt pour cette tâche, NewsRepository agit comme un proxy pour la source de données réseau. Les avantages de l'ajout de cette couche d'abstraction supplémentaire sont expliqués dans la section Mise en cache de la mémoire.
// NewsRepository is consumed from other layers of the hierarchy.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
suspend fun fetchLatestNews(): List<ArticleHeadline> =
newsRemoteDataSource.fetchLatestNews()
}
Pour découvrir comment utiliser la classe de dépôt directement à partir de la couche de l'interface utilisateur, consultez le guide de couche de l'interface utilisateur.
Intégrer la mise en cache des données en mémoire
Supposons qu'une nouvelle condition soit introduite pour l'application Google Actualités : lorsque l'utilisateur ouvre l'écran, les actualités mises en cache doivent être présentées à l'utilisateur si une requête a été effectuée auparavant. Sinon, l'application doit envoyer une requête réseau pour récupérer les dernières actualités.
La nouvelle condition force l'application à conserver en mémoire les dernières actualités tant qu'elle est ouverte par l'utilisateur. Il s'agit donc d'une opération sur l'application.
Caches
Vous pouvez conserver les données lorsque l'utilisateur est dans votre application en ajoutant la mise en cache des données en mémoire. Les caches sont destinés à conserver certaines informations en mémoire pendant un certain temps (dans le cas présent, tant que l'utilisateur est dans l'application). Les intégrations de cache peuvent prendre différentes formes. Il peut s'agir de simples variables modifiables ou de classes plus sophistiquées qui protègent des opérations de lecture/écriture sur plusieurs threads. Selon le cas d'utilisation, la mise en cache peut être intégrée dans le dépôt ou dans les classes de sources de données.
Mettre en cache le résultat de la requête réseau
Pour plus de simplicité, NewsRepository utilise une variable modifiable pour mettre en cache les dernières actualités. Pour protéger les lectures et les écritures à partir de différents threads, un Mutex est utilisé. Pour en savoir plus sur l'état modifiable et la simultanéité partagés, consultez la documentation Kotlin.
L'intégration suivante met en cache les dernières actualités dans une variable du dépôt protégée en écriture avec un élément Mutex. Si la requête réseau aboutit, les données sont attribuées à la variable latestNews.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
// Mutex to make writes to cached values thread-safe.
private val latestNewsMutex = Mutex()
// Cache of the latest news got from the network.
private var latestNews: List<ArticleHeadline> = emptyList()
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
if (refresh || latestNews.isEmpty()) {
val networkResult = newsRemoteDataSource.fetchLatestNews()
// Thread-safe write to latestNews
latestNewsMutex.withLock {
this.latestNews = networkResult
}
}
return latestNewsMutex.withLock { this.latestNews }
}
}
Prolonger une opération plus longtemps qu'affiché à l'écran
Si l'utilisateur quitte l'écran pendant que la requête réseau est en cours, celle-ci est annulée et le résultat n'est pas mis en cache. NewsRepository ne doit pas utiliser l'élément CoroutineScope de l'appelant pour effectuer cette logique. NewsRepository doit plutôt utiliser un élément CoroutineScope correspondant à son cycle de vie.
L'extraction des actualités doit être une opération sur l'application.
Pour suivre les bonnes pratiques d'injection de dépendances, NewsRepository doit obtenir un champ d'application en tant que paramètre dans son constructeur au lieu de créer son propre CoroutineScope. Étant donné que les dépôts doivent effectuer le plus gros de leur travail en arrière-plan, vous devez configurer CoroutineScope avec Dispatchers.Default ou avec votre propre pool de threads.
class NewsRepository(
...,
// This could be CoroutineScope(SupervisorJob() + Dispatchers.Default).
private val externalScope: CoroutineScope
) { ... }
NewsRepository étant prêt à effectuer des opérations sur l'application avec l'élément CoroutineScope externe, il doit effectuer l'appel à la source de données et enregistrer son résultat avec une nouvelle coroutine lancée par ce champ d'application :
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val externalScope: CoroutineScope
) {
/* ... */
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
return if (refresh) {
externalScope.async {
newsRemoteDataSource.fetchLatestNews().also { networkResult ->
// Thread-safe write to latestNews.
latestNewsMutex.withLock {
latestNews = networkResult
}
}
}.await()
} else {
return latestNewsMutex.withLock { this.latestNews }
}
}
}
async permet de démarrer la coroutine dans le champ d'application externe. await est appelé sur la nouvelle coroutine à suspendre jusqu'au retour de la requête réseau et l'enregistrement du résultat dans le cache. Si, à ce moment-là, l'utilisateur est toujours à l'écran, il verra les dernières actualités. Si l'utilisateur quitte l'écran, await est annulé, mais la logique dans async continue de s'exécuter.
En savoir plus sur les schémas pour CoroutineScope
Enregistrer et récupérer des données du disque
Supposons que vous souhaitiez enregistrer des données telles que des actualités ajoutées aux favoris ou des préférences utilisateur. Ce type de données doit survivre à l'arrêt du processus et rester accessible même si l'utilisateur n'est pas connecté au réseau.
Si les données que vous utilisez doivent survivre à l'arrêt du processus, vous devez les stocker sur le disque de l'une des manières suivantes :
- Pour les ensembles de données volumineux nécessitant une interrogation, une intégrité référentielle ou des mises à jour partielles, enregistrez les données dans une base de données Room. Dans l'application Google Actualités, par exemple, les articles ou les auteurs peuvent être enregistrés dans la base de données.
- Pour les petits ensembles de données qui n'ont besoin que d'être récupérés et définis (sans interrogation ni mise à jour partielle), utilisez DataStore. Dans l'exemple de l'application Google Actualités, le format de date préféré par l'utilisateur ainsi que d'autres préférences d'affichage peuvent être enregistrés dans DataStore.
- Pour les segments de données tels qu'un objet JSON, utilisez un fichier.
Comme indiqué dans la section Source de référence, chaque source de données ne fonctionne qu'avec une seule source et correspond à un type de données spécifique (par exemple, News, Authors, NewsAndAuthors ou UserPreferences). Les classes qui utilisent la source de données ne doivent pas savoir comment les données sont enregistrées (par exemple, dans une base de données ou dans un fichier).
Room comme source de données
Étant donné que chaque source de données doit prendre en charge le travail avec une seule source pour un type spécifique de données, une source de données Room recevrait soit un objet d'accès aux données (DAO), soit la base de données en tant que paramètre. Par exemple, NewsLocalDataSource peut utiliser une instance de NewsDao comme paramètre et AuthorsLocalDataSource une instance de AuthorsDao.
Dans certains cas, si aucune logique supplémentaire n'est nécessaire, vous pouvez injecter le DAO directement dans le dépôt, car il s'agit d'une interface que vous pouvez facilement remplacer dans les tests.
Pour en savoir plus sur l'utilisation des API Room, consultez les guides Room.
DataStore comme source de données
DataStore est la solution idéale pour stocker des paires clé/valeur comme des paramètres utilisateur. Il peut s'agir du format de l'heure, des préférences de notification et de l'affichage ou non des actualités une fois lues par l'utilisateur. DataStore peut également stocker des objets typés avec des tampons de protocole.
Comme pour tout autre objet, une source de données sauvegardée par DataStore doit contenir des données correspondant à un certain type ou à une certaine partie de l'application. C'est encore plus vrai avec DataStore, car les lectures DataStore sont présentées sous la forme d'un flux qui émet chaque fois qu'une valeur est mise à jour. Pour cette raison, vous devez stocker les préférences associées dans le même DataStore.
Par exemple, vous pourriez avoir un flux NotificationsDataStore qui gère uniquement les préférences liées aux notifications et un flux NewsPreferencesDataStore qui gère uniquement celles liées à l'écran d'actualités. Ainsi, vous pouvez mieux limiter les mises à jour, car le flux newsScreenPreferencesDataStore.data n'émet que lorsqu'une préférence liée à cet écran est modifiée. Le cycle de vie de l'objet peut donc être plus court, car il ne peut être actif que tant que l'écran d'actualités est affiché.
Pour en savoir plus sur l'utilisation des API DataStore, consultez les guides DataStore.
Un fichier comme source de données
Lorsque vous utilisez des objets volumineux, tels qu'un objet JSON ou un bitmap, vous devez utiliser un objet File et gérer la transition d'un thread à un autre.
Pour en savoir plus sur l'utilisation du stockage de fichiers, consultez la page Présentation du stockage.
Planifier des tâches à l'aide de WorkManager
Supposons qu'une nouvelle condition soit introduite pour l'application Google Actualités : l'application doit permettre à l'utilisateur d'extraire de manière régulière et automatique les dernières actualités tant que l'appareil est en charge et connecté à un réseau non facturé à l'usage. Il s'agit donc d'une opération à des fins professionnelles. Ainsi, même si l'appareil n'est pas connecté à Internet lorsque l'utilisateur lance l'application, il peut toujours voir les actualités récentes.
WorkManager facilite la planification des tâches asynchrones et fiables et permet de gérer les contraintes. C'est la bibliothèque recommandée pour les tâches persistantes. Pour effectuer la tâche définie ci-dessus, une classe Worker, RefreshLatestNewsWorker, est créée. Cette classe utilise NewsRepository comme dépendance pour extraire les dernières actualités et les mettre en cache sur le disque.
class RefreshLatestNewsWorker(
private val newsRepository: NewsRepository,
context: Context,
params: WorkerParameters
) : CoroutineWorker(context, params) {
override suspend fun doWork(): Result = try {
newsRepository.refreshLatestNews()
Result.success()
} catch (error: Throwable) {
Result.failure()
}
}
La logique métier de ce type de tâche doit être encapsulée dans sa propre classe et traitée comme une source de données distincte. WorkManager ne sera alors responsable que de l'exécution du travail sur un thread en arrière-plan lorsque toutes les conditions sont remplies. En respectant ce modèle, vous pouvez rapidement interchanger si nécessaire les intégrations dans différents environnements.
Dans cet exemple, cette tâche liée à l'actualité doit être appelée à partir de NewsRepository, qui utiliserait une nouvelle source de données en tant que dépendance, NewsTasksDataSource, intégrée comme suit :
private const val REFRESH_RATE_HOURS = 4L
private const val FETCH_LATEST_NEWS_TASK = "FetchLatestNewsTask"
private const val TAG_FETCH_LATEST_NEWS = "FetchLatestNewsTaskTag"
class NewsTasksDataSource(
private val workManager: WorkManager
) {
fun fetchNewsPeriodically() {
val fetchNewsRequest = PeriodicWorkRequestBuilder<RefreshLatestNewsWorker>(
REFRESH_RATE_HOURS, TimeUnit.HOURS
).setConstraints(
Constraints.Builder()
.setRequiredNetworkType(NetworkType.TEMPORARILY_UNMETERED)
.setRequiresCharging(true)
.build()
)
.addTag(TAG_FETCH_LATEST_NEWS)
workManager.enqueueUniquePeriodicWork(
FETCH_LATEST_NEWS_TASK,
ExistingPeriodicWorkPolicy.KEEP,
fetchNewsRequest.build()
)
}
fun cancelFetchingNewsPeriodically() {
workManager.cancelAllWorkByTag(TAG_FETCH_LATEST_NEWS)
}
}
Ces types de classes portent le nom des données dont ils sont responsables, par exemple NewsTasksDataSource ou PaymentsTasksDataSource. Toutes les tâches liées à un certain type de données doivent être encapsulées dans la même classe.
Si la tâche doit être déclenchée au démarrage de l'application, il est recommandé de déclencher la requête WorkManager à l'aide de la bibliothèque App Startup, qui appelle le dépôt depuis une Initializer.
Pour en savoir plus sur l'utilisation des API WorkManager, consultez les guides WorkManager.
Tests
Les bonnes pratiques sur l'injection de dépendances aident à tester votre application. Il est également utile d'exploiter des interfaces pour les classes qui communiquent avec des ressources externes. Lorsque vous testez une unité, vous pouvez injecter de fausses versions de ses dépendances pour rendre le test déterministe et fiable.
Tests unitaires
Les consignes générales relatives aux tests s'appliquent au moment de tester la couche de données. Pour les tests unitaires, utilisez des objets réels si nécessaire et simulez des dépendances qui contactent des sources externes, telles que la lecture à partir d'un fichier ou à partir du réseau.
Tests d'intégration
Les tests d'intégration qui accèdent à des sources externes ont tendance à être moins déterministes, car ils doivent être exécutés sur un appareil réel. Nous vous recommandons d'exécuter ces tests dans un environnement contrôlé pour améliorer leur fiabilité.
Pour les bases de données, Room permet de créer une base de données en mémoire que vous pouvez contrôler entièrement dans vos tests. Pour en savoir plus, consultez la page Tester et déboguer votre base de données.
Pour la mise en réseau, il existe des bibliothèques courantes telles que WireMock ou MockWebServer qui vous permettent de simuler des appels HTTP et HTTPS, et de vérifier que les requêtes ont bien été effectuées comme prévu.
Ressources supplémentaires
Exemples
- Jetcaster
- Modèle de démarrage de l'architecture (multimodule)
- Architecture
- Modèle de démarrage de l'architecture (module unique)
- Application "En ce moment sur Android"
Recommandations personnalisées
- Remarque : Le texte du lien s'affiche lorsque JavaScript est désactivé
- Couche de domaine
- Créer une application orientée hors connexion
- Production de l'état de l'interface utilisateur