
Como a otimização automática de comandos aumenta a qualidade da API GenAI Prompt do Kit de ML
Leitura de 3 minutos
Otimização automática de comandos (APO)
Para ajudar ainda mais a levar seus casos de uso da API Prompt do ML Kit para a produção, temos o prazer de anunciar a Otimização automática de comandos (APO, na sigla em inglês) para modelos no dispositivo na Vertex AI. A Otimização automática de comandos é uma ferramenta que ajuda você a encontrar automaticamente o comando ideal para seus casos de uso.
A era da IA no dispositivo não é mais uma promessa, mas uma realidade de produção. Com o lançamento do Gemini Nano v3, estamos colocando recursos multimodais e de compreensão de linguagem sem precedentes diretamente nas mãos dos usuários. Com a família de modelos Gemini Nano, temos uma ampla cobertura de dispositivos compatíveis em todo o ecossistema Android. Mas, para os desenvolvedores que estão criando a próxima geração de apps inteligentes, o acesso a um modelo eficiente é apenas a primeira etapa. O verdadeiro desafio está na personalização: como adaptar um modelo de fundação para ter uma performance de nível especialista no seu caso de uso específico sem violar as restrições do hardware móvel?
No mundo do lado do servidor, os LLMs maiores tendem a ser altamente capazes e exigem menos adaptação de domínio. Mesmo quando necessário, opções mais avançadas, como o ajuste fino de LoRA (adaptação de classificação baixa), podem ser viáveis. No entanto, a arquitetura exclusiva do Android AICore prioriza um modelo de sistema compartilhado e eficiente em termos de memória. Isso significa que a implantação de adaptadores LoRA personalizados para cada app individual apresenta desafios nesses serviços compartilhados do sistema.
Mas há um caminho alternativo que pode ser igualmente impactante. Ao aproveitar a Otimização automática de comandos (APO, na sigla em inglês) na Vertex AI, os desenvolvedores podem alcançar uma qualidade semelhante ao ajuste refinado, tudo isso trabalhando perfeitamente no ambiente de execução nativo do Android. Ao se concentrar em instruções de sistema superiores, o APO permite que os desenvolvedores personalizem o comportamento do modelo com mais robustez e escalonabilidade do que as soluções tradicionais de ajuste refinado.
Observação : o Gemini Nano V3 é uma versão otimizada para qualidade do modelo Gemma 3N, que é muito aclamado. Todas as otimizações de comandos feitas no modelo de código aberto Gemma 3N também serão aplicadas ao Gemini Nano V3. Em dispositivos compatíveis, as APIs GenAI do Kit de ML usam o modelo nano-v3 para maximizar a qualidade para desenvolvedores Android.
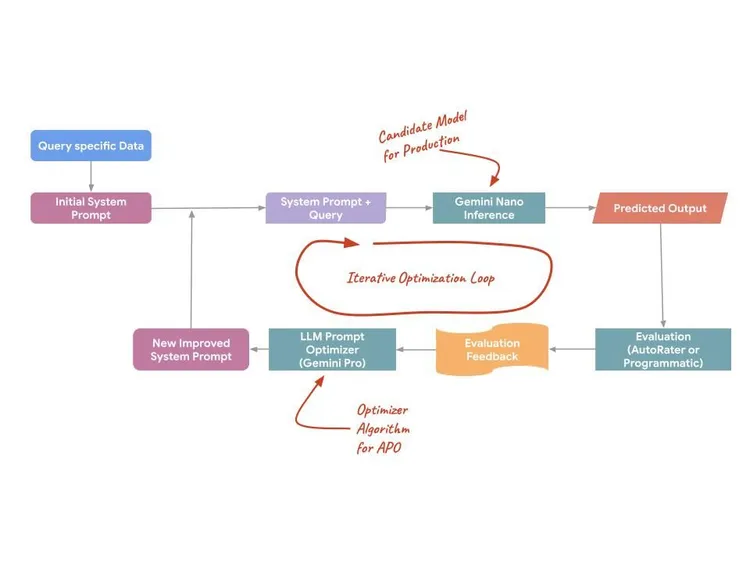
A APO trata o comando não como um texto estático, mas como uma superfície programável que pode ser otimizada. Ele usa modelos do lado do servidor (como o Gemini Pro e o Flash) para sugerir comandos, avaliar variações e encontrar a melhor opção para sua tarefa específica. Esse processo usa três mecanismos técnicos específicos para maximizar a performance:
- Análise de erros automatizada:a APO analisa padrões de erros dos dados de treinamento para identificar automaticamente falhas específicas no comando inicial.
- Destilação de instruções semânticas:analisa exemplos de treinamento em massa para destilar a "verdadeira intenção" de uma tarefa, criando instruções que refletem com mais precisão a distribuição real dos dados.
- Teste paralelo de candidatos:em vez de testar uma ideia por vez, a APO gera e testa vários candidatos de comandos em paralelo para identificar o máximo global de qualidade.
Por que a APO pode se aproximar da qualidade do ajuste de detalhes
É um equívoco comum achar que o ajuste fino sempre gera uma qualidade melhor do que o comando. Para modelos de fundação modernos, como o Gemini Nano v3, a engenharia de comandos pode ser impactante por si só:
- Preservar recursos gerais:o ajuste fino ( PEFT/LoRA) força os pesos de um modelo a indexar demais uma distribuição específica de dados. Isso geralmente leva ao "esquecimento catastrófico", em que o modelo melhora na sua sintaxe específica, mas piora na lógica geral e na segurança. A APO não altera os pesos, preservando os recursos do modelo de base.
- Seguir instruções e descobrir estratégias:o Gemini Nano v3 foi treinado rigorosamente para seguir instruções complexas do sistema. A APO explora isso encontrando a estrutura de instrução exata que desbloqueia as capacidades latentes do modelo, muitas vezes descobrindo estratégias que podem ser difíceis de encontrar para engenheiros humanos.
Para validar essa abordagem, avaliamos a APO em diversas cargas de trabalho de produção. Nossa validação mostrou ganhos de precisão consistentes de 5 a 8% em vários casos de uso.Em vários recursos implantados no dispositivo, a APO proporcionou melhorias significativas na qualidade.
| Caso de uso | Tipo de tarefa | Descrição da tarefa | Métrica | Melhoria da APO |
| Classificação dos temas | Classificação de texto | Classificar uma notícia em temas como finanças, esportes etc. | Precisão | +5% |
| Classificação de intents | Classificação de texto | Classificar uma consulta de atendimento ao cliente em intents | Precisão | +8% |
| Tradução de páginas da Web | Tradução de textos | Traduzir uma página da Web do inglês para um idioma local | BLEU | +8,57% |
Um fluxo de trabalho de desenvolvedor completo e integrado
É um equívoco comum achar que o ajuste fino sempre gera uma qualidade melhor do que o comando. Para modelos de fundação modernos, como o Gemini Nano v3, a engenharia de comandos pode ser impactante por si só:
- Preservar recursos gerais:o ajuste fino ( PEFT/LoRA) força os pesos de um modelo a indexar demais uma distribuição específica de dados. Isso geralmente leva ao "esquecimento catastrófico", em que o modelo melhora na sua sintaxe específica, mas piora na lógica geral e na segurança. A APO não altera os pesos, preservando os recursos do modelo de base.
- Seguir instruções e descobrir estratégias:o Gemini Nano v3 foi treinado rigorosamente para seguir instruções complexas do sistema. A APO explora isso encontrando a estrutura de instrução exata que desbloqueia as capacidades latentes do modelo, muitas vezes descobrindo estratégias que podem ser difíceis de encontrar para engenheiros humanos.
Para validar essa abordagem, avaliamos a APO em diversas cargas de trabalho de produção. Nossa validação mostrou ganhos de precisão consistentes de 5 a 8% em vários casos de uso.Em vários recursos implantados no dispositivo, a APO proporcionou melhorias significativas na qualidade.
Conclusão
O lançamento da Otimização automática de comandos (APO, na sigla em inglês) marca um ponto de virada para a IA generativa no dispositivo. Ao preencher a lacuna entre modelos de fundação e desempenho de nível especialista, estamos oferecendo aos desenvolvedores as ferramentas para criar aplicativos móveis mais robustos. Se você está começando com a otimização zero-shot ou escalonando para produção com o refinamento orientado por dados, o caminho para uma inteligência de alta qualidade no dispositivo agora está mais claro. Lance seus casos de uso no dispositivo para produção hoje mesmo com a API Prompt do ML Kit e a Otimização automática de comandos da Vertex AI.
Links relevantes:



-


 Novidades sobre produtos
Novidades sobre produtosNo Google, nosso objetivo é levar os modelos de IA mais avançados diretamente para os dispositivos Android no seu bolso. Hoje, temos o prazer de anunciar o lançamento do nosso mais recente modelo aberto de última geração: o Gemma 4.
Caren Chang, David Chou • Leitura de 3 minutos -
 Novidades sobre produtos
Novidades sobre produtosA IA está facilitando a criação de experiências personalizadas em apps que transformam o conteúdo no formato certo para os usuários. Antes, permitíamos que os desenvolvedores fizessem a integração com o Gemini Nano usando as APIs GenAI do Kit de ML, personalizadas para casos de uso específicos, como resumo e descrição de imagens.
Caren Chang, Chengji Yan, Penny Li • Leitura de 2 minutos -

 Novidades sobre produtos
Novidades sobre produtosEm março, apresentamos o Android Bench, nosso ranking de LLMs para tarefas de desenvolvimento em Android no mundo real. Desde então, aprimoramos o comparativo com base no seu feedback, incluindo a avaliação de modelos de peso aberto e a adição de dimensões de custo e eficiência ao ranking.
Zoe Lopez-Latorre • Leitura de 3 minutos
Receba os insights mais recentes sobre desenvolvimento Android na sua caixa de entrada semanalmente.
