
Dans cet atelier de programmation, vous allez apprendre à utiliser l'outil de création LiveData pour combiner des coroutines Kotlin avec LiveData dans une application Android. Vous utiliserez également des coroutines asynchrones Flow, un type de routine qui provient de la bibliothèque de coroutines et qui sert à représenter une séquence asynchrone (ou flux) de valeurs, pour implémenter la même chose.
Vous allez commencer à partir d'une application existante, créée à l'aide des composants d'architecture Android. Cette application utilise LiveData pour obtenir une liste d'objets depuis une base de données Room et les affiche dans une mise en page en grille RecyclerView.
Voici quelques extraits de code pour vous donner une idée de ce que vous allez faire. Voici le code existant pour interroger la base de données Room :
val plants: LiveData<List<Plant>> = plantDao.getPlants()
LiveData sera mis à jour à l'aide des coroutines et de l'outil de création LiveData, avec une logique de tri supplémentaire :
val plants: LiveData<List<Plant>> = liveData<List<Plant>> {
val plantsLiveData = plantDao.getPlants()
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsLiveData.map { plantList -> plantList.applySort(customSortOrder) })
}
Vous implémenterez également la même logique avec Flow :
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
.flowOn(defaultDispatcher)
.conflate()
Conditions préalables
- Expérience des composants d'architecture
ViewModel,LiveData,RepositoryetRoom - Expérience de la syntaxe Kotlin, y compris des fonctions d'extension et des lambdas
- Expérience des coroutines Kotlin
- Connaissances de base de l'utilisation des threads sur Android, y compris le thread principal, les threads en arrière-plan et les rappels
Objectifs de l'atelier
- Convertir un
LiveDataexistant pour utiliser l'outil de créationLiveDatacompatible avec les coroutines Kotlin - Ajouter une logique dans un outil de création
LiveData - Utiliser
Flowpour des opérations asynchrones - Combiner
Flowset transformer plusieurs sources asynchrones - Contrôler la simultanéité avec
Flows - Choisir entre
LiveDataetFlow.
Prérequis
- Android Studio 4.1 ou version ultérieure Il se peut que l'atelier de programmation fonctionne avec d'autres versions, mais que des éléments soient manquants ou différents.
Si vous rencontrez des problèmes (bugs de code, erreurs grammaticales, formulation peu claire, etc.) au cours de cet atelier de programmation, veuillez les signaler via le lien "Signaler une erreur" situé dans l'angle inférieur gauche de l'atelier de programmation.
Télécharger le code
Cliquez sur le lien ci-dessous pour télécharger l'ensemble du code de cet atelier de programmation :
Vous pouvez également cloner le dépôt GitHub à partir de la ligne de commande à l'aide de la commande suivante :
$ git clone https://github.com/googlecodelabs/kotlin-coroutines.git
Le code de cet atelier de programmation se trouve dans le répertoire advanced-coroutines-codelab.
Questions fréquentes
Voyons d'abord comment se présente notre exemple d'application de départ. Suivez les instructions ci-dessous pour ouvrir l'exemple d'application dans Android Studio :
- Si vous avez téléchargé le fichier ZIP
kotlin-coroutines, décompressez-le. - Ouvrez le répertoire
advanced-coroutines-codelabdans Android Studio. - Assurez-vous que
startest sélectionné dans la liste déroulante de configuration. - Cliquez sur le bouton Exécuter
 , puis choisissez un appareil émulé ou connectez votre appareil Android. L'appareil doit être en mesure d'exécuter Android Lollipop (SDK 21 au minimum).
, puis choisissez un appareil émulé ou connectez votre appareil Android. L'appareil doit être en mesure d'exécuter Android Lollipop (SDK 21 au minimum).
Lorsque l'application s'exécute pour la première fois, une liste de cartes s'affiche, chacune affichant le nom et l'image d'une plante ou d'un fruit spécifique :

Chaque Plant possède un growZoneNumber, un attribut qui représente la région dans laquelle la plante ou le fruit sont le plus susceptibles de pousser. Les utilisateurs peuvent appuyer sur l'icône de filtrage  pour basculer entre l'affichage de tous les végétaux et l'affichage des végétaux d'une zone de culture particulière, qui est codée en dur sur "zone 9". Appuyez plusieurs fois sur le bouton de filtre pour voir ce basculement en action.
pour basculer entre l'affichage de tous les végétaux et l'affichage des végétaux d'une zone de culture particulière, qui est codée en dur sur "zone 9". Appuyez plusieurs fois sur le bouton de filtre pour voir ce basculement en action.

Présentation de l'architecture
Cette application utilise des composants d'architecture pour séparer le code de l'interface utilisateur dans MainActivity et PlantListFragment de la logique d'application dans PlantListViewModel. PlantRepository crée une passerelle entre ViewModel et PlantDao pour accéder à la base de données Room et renvoyer une liste d'objets Plant. L'interface utilisateur récupère ensuite cette liste de végétaux et l'affiche dans la mise en page en grille RecyclerView.
Avant de commencer à modifier le code, voyons rapidement comment les données sont transmises entre la base de données et l'interface utilisateur. Voici comment la liste des végétaux se charge dans ViewModel :
PlantListViewModel.kt
val plants: LiveData<List<Plant>> = growZone.switchMap { growZone ->
if (growZone == NoGrowZone) {
plantRepository.plants
} else {
plantRepository.getPlantsWithGrowZone(growZone)
}
}
GrowZone est une classe intégrée qui ne contient qu'un Int représentant sa zone. NoGrowZone représente l'absence de zone et n'est utilisé que pour le filtrage.
Plant.kt
inline class GrowZone(val number: Int)
val NoGrowZone = GrowZone(-1)
growZone est activé ou désactivé en appuyant sur le bouton de filtre. Nous utilisons switchMap pour déterminer la liste des végétaux à renvoyer.
Voici à quoi ressemblent le dépôt et l'objet d'accès aux données (DAO) pour récupérer les données des végétaux depuis la base de données :
PlantDao.kt
@Query("SELECT * FROM plants ORDER BY name")
fun getPlants(): LiveData<List<Plant>>
@Query("SELECT * FROM plants WHERE growZoneNumber = :growZoneNumber ORDER BY name")
fun getPlantsWithGrowZoneNumber(growZoneNumber: Int): LiveData<List<Plant>>
PlantRepository.kt
val plants = plantDao.getPlants()
fun getPlantsWithGrowZone(growZone: GrowZone) =
plantDao.getPlantsWithGrowZoneNumber(growZone.number)
Bien que la plupart des modifications du code soient apportées dans PlantListViewModel et PlantRepository, il est judicieux de prendre un moment pour se familiariser avec la structure du projet, en se concentrant sur la manière dont les données sur les végétaux s'affichent à travers les différentes couches entre la base de données et Fragment. À l'étape suivante, nous modifierons le code pour ajouter un tri personnalisé à l'aide de l'outil de création LiveData.
La liste des végétaux s'affiche actuellement dans l'ordre alphabétique, mais nous souhaitons modifier cet ordre et afficher certains végétaux en premier, puis le reste dans l'ordre alphabétique. Ce fonctionnement est semblable à celui des applications de shopping, qui présentent des résultats sponsorisés en haut de la liste des articles disponibles. Notre équipe produit souhaite pouvoir modifier l'ordre de tri de façon dynamique sans envoyer de nouvelle version de l'application. Nous allons donc récupérer depuis le backend la liste des végétaux à afficher en premier.
Voici à quoi ressemblera l'application avec le tri personnalisé :
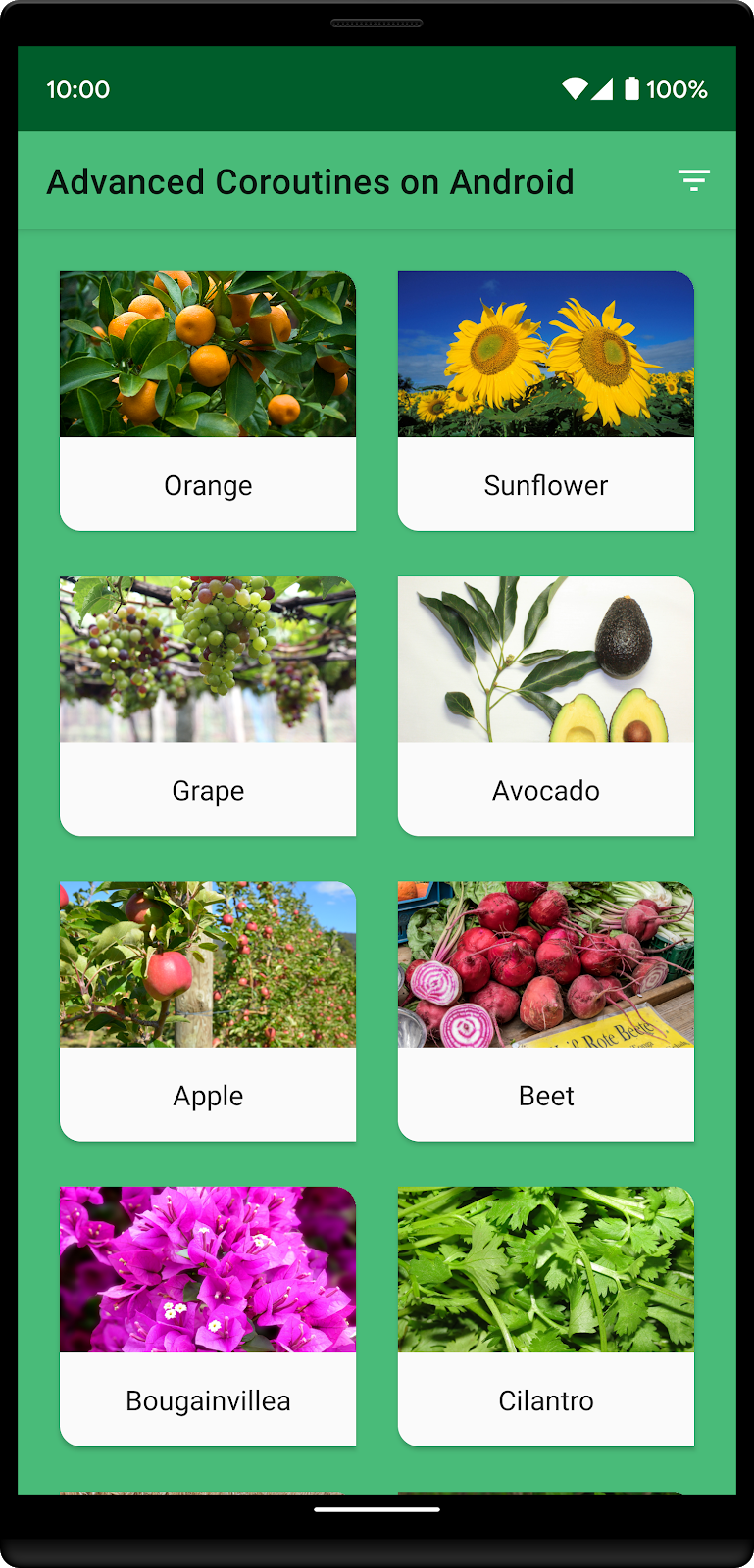
La liste ainsi triée se compose de ces quatre végétaux : oranges, tournesols, raisins et avocats. Remarquez la manière dont ils apparaissent en premier dans la liste, suivis des autres végétaux dans l'ordre alphabétique.
À présent, si vous appuyez sur le bouton de filtre (et que seuls les végétaux de la GrowZone sont affichés), le tournesol disparaît de la liste puisque son GrowZone n'est pas 9. Les trois autres végétaux de la liste de tri personnalisée se trouvant dans la GrowZone 9, ils restent en haut de la liste. Le seul autre végétal de GrowZone 9 est la tomate, qui apparaît en dernier dans cette liste.
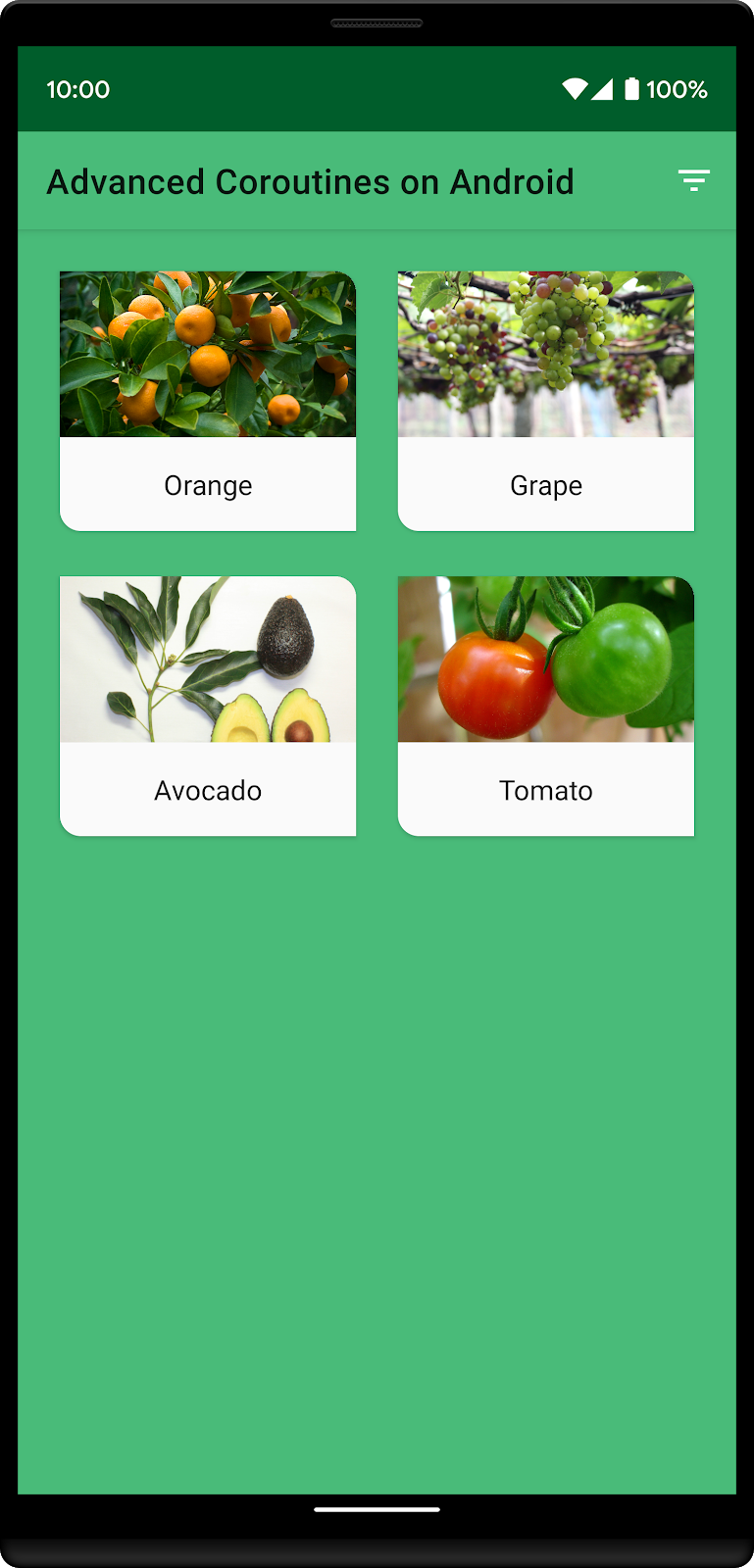
Commençons à écrire le code pour implémenter le tri personnalisé.
Nous allons commencer par écrire une fonction de suspension pour récupérer l'ordre de tri personnalisé sur le réseau, puis le mettre en cache dans la mémoire.
Ajoutez le code suivant à PlantRepository :
PlantRepository.kt
private var plantsListSortOrderCache =
CacheOnSuccess(onErrorFallback = { listOf<String>() }) {
plantService.customPlantSortOrder()
}
plantsListSortOrderCache est utilisé en tant que cache en mémoire pour l'ordre de tri personnalisé. Il sera remplacé par une liste vide en cas d'erreur réseau, afin que notre application puisse toujours afficher les données même si l'ordre de tri n'est pas récupéré.
Ce code utilise la classe d'utilitaire CacheOnSuccess fournie dans le module sunflower pour gérer la mise en cache. L'omission des détails de la mise en cache de cette manière permet de simplifier le code de l'application. Comme CacheOnSuccess a déjà été largement testé, nous n'avons pas besoin d'écrire autant de tests pour notre dépôt afin d'en garantir le bon fonctionnement. Il est judicieux d'introduire des abstractions similaires de niveau supérieur dans votre code lorsque vous utilisez kotlinx-coroutines.
À présent, ajoutons une logique pour appliquer le tri à une liste de végétaux.
Ajoutez le code suivant à PlantRepository:
PlantRepository.kt
private fun List<Plant>.applySort(customSortOrder: List<String>): List<Plant> {
return sortedBy { plant ->
val positionForItem = customSortOrder.indexOf(plant.plantId).let { order ->
if (order > -1) order else Int.MAX_VALUE
}
ComparablePair(positionForItem, plant.name)
}
}
Cette fonction d'extension réorganise la liste en plaçant les Plants qui se trouvent dans customSortOrder au début de la liste.
Maintenant que la logique de tri est en place, remplacez le code de plants et getPlantsWithGrowZone par l'outil de création LiveData ci-dessous :
PlantRepository.kt
val plants: LiveData<List<Plant>> = liveData<List<Plant>> {
val plantsLiveData = plantDao.getPlants()
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsLiveData.map {
plantList -> plantList.applySort(customSortOrder)
})
}
fun getPlantsWithGrowZone(growZone: GrowZone) = liveData {
val plantsGrowZoneLiveData = plantDao.getPlantsWithGrowZoneNumber(growZone.number)
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsGrowZoneLiveData.map { plantList ->
plantList.applySort(customSortOrder)
})
}
Si vous exécutez l'application à présent, la liste personnalisée des végétaux devrait se présenter comme suit :
L'outil de création LiveData nous permet de calculer les valeurs de manière asynchrone, car liveData s'appuie sur des coroutines. Ici, nous avons une fonction de suspension qui récupère une liste LiveData de végétaux depuis la base de données, tout en appelant une fonction de suspension pour obtenir l'ordre de tri personnalisé. Nous combinons ensuite ces deux valeurs pour trier la liste des végétaux et renvoyer la valeur, tout cela dans l'outil de création.
La coroutine commence à s'exécuter lorsqu'elle est observée et est annulée lorsqu'elle se termine ou en cas d'échec de l'appel du réseau ou de la base de données.
À l'étape suivante, nous allons découvrir une variante de getPlantsWithGrowZone en utilisant une transformation.
Nous allons à présent modifier PlantRepository pour implémenter une transformation de suspension lorsque chaque valeur est traitée et apprendre à créer des transformations asynchrones complexes dans LiveData. Avant de commencer, nous allons créer une version de l'algorithme de tri pouvant être utilisée en toute sécurité dans le thread principal. Nous pouvons utiliser withContext pour passer à un autre coordinateur juste pour le lambda, puis reprendre avec le coordinateur avec lequel nous avons commencé.
Ajoutez le code suivant à PlantRepository :
PlantRepository.kt
@AnyThread
suspend fun List<Plant>.applyMainSafeSort(customSortOrder: List<String>) =
withContext(defaultDispatcher) {
this@applyMainSafeSort.applySort(customSortOrder)
}
Nous pouvons ensuite utiliser ce nouveau tri sécurisé avec l'outil de création LiveData. Mettez à jour le bloc pour utiliser switchMap, qui vous permettra de pointer vers un nouveau LiveData chaque fois qu'une nouvelle valeur sera reçue.
PlantRepository.kt
fun getPlantsWithGrowZone(growZone: GrowZone) =
plantDao.getPlantsWithGrowZoneNumber(growZone.number)
.switchMap { plantList ->
liveData {
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emit(plantList.applyMainSafeSort(customSortOrder))
}
}
Par rapport à la version précédente, une fois l'ordre de tri personnalisé reçu du réseau, il peut être utilisé avec le nouveau applyMainSafeSort sécurisé. Ce résultat est ensuite émis vers switchMap en tant que nouvelle valeur renvoyée par getPlantsWithGrowZone.
Comme pour LiveData plants ci-dessus, la coroutine commence à s'exécuter lorsqu'elle est observée et s'arrête une fois terminée ou en cas d'échec de l'appel du réseau ou de la base de données. La différence ici est que l'appel du réseau sur la carte se fait en toute sécurité, puisqu'il est mis en cache.
Voyons maintenant comment ce code est implémenté avec Flow. Ensuite, nous comparerons les méthodes d'implémentation.
Nous allons créer la même logique en utilisant Flow à partir de kotlinx-coroutines. Avant cela, voyons ce qu'est un flux et comment en intégrer un dans votre application.
Un flux est une version asynchrone d'une séquence, un type de collection dont les valeurs sont générées à la demande. À l'instar d'une séquence, un flux produit chaque valeur à la demande, chaque fois que la valeur est nécessaire. Les flux peuvent contenir un nombre infini de valeurs.
Pourquoi Kotlin introduit-il un nouveau type Flow, et en quoi celui-ci diffère-t-il d'une séquence normale ? La réponse se trouve dans la magie de l'asynchronisme. Flow est parfaitement compatible avec les coroutines. Cela signifie que vous pouvez créer, transformer et consommer un Flow en utilisant des coroutines. Vous pouvez également contrôler la simultanéité, ce qui signifie que vous pouvez coordonner l'exécution de plusieurs coroutines de manière déclarative à l'aide de Flow.
Cela ouvre de nombreuses perspectives fascinantes.
Flow peut être utilisé dans un style de programmation entièrement réactif. Si vous avez déjà utilisé RxJava ou outil similaire, Flow propose une fonctionnalité semblable. La logique d'application peut être exprimée de manière succincte en transformant un flux à l'aide d'opérateurs fonctionnels comme map, flatMapLatest, combine, etc.
Flow est également compatible avec les fonctions de suspension sur la plupart des opérateurs. Cela vous permet de réaliser des tâches asynchrones séquentielles dans un opérateur tel que map. En utilisant des opérations de suspension à l'intérieur d'un flux, il est souvent plus rapide et plus facile de lire le code que si le code avait été rédigé dans un style entièrement réactif.
Dans cet atelier de programmation, nous allons utiliser les deux approches.
Fonctionnement du flux
Pour vous familiariser avec la façon dont Flow génère des valeurs à la demande, examinez le flux suivant, qui émet les valeurs (1, 2, 3) et imprime avant, pendant et après la production de chaque élément.
fun makeFlow() = flow {
println("sending first value")
emit(1)
println("first value collected, sending another value")
emit(2)
println("second value collected, sending a third value")
emit(3)
println("done")
}
scope.launch {
makeFlow().collect { value ->
println("got $value")
}
println("flow is completed")
}
Si vous l'exécutez, le résultat suivant est généré :
sending first value got 1 first value collected, sending another value got 2 second value collected, sending a third value got 3 done flow is completed
Vous pouvez voir comment l'exécution bascule entre le lambda collect et l'outil de création flow. Chaque fois que l'outil de création de flux appelle emit, il suspends jusqu'à ce que l'élément soit entièrement traité. Ensuite, lorsqu'une autre valeur est demandée depuis le flux, il resumes là où il s'était arrêté jusqu'à ce qu'il appelle à nouveau la fonction emit(). Lorsque l'outil de création flow se termine, Flow est annulé et collect reprend, ce qui permet à la coroutine d'appeler d'imprimer "flow is completed" (le flux est terminé).
L'appel de collect est très important. Flow utilise des opérateurs de suspension comme collect au lieu d'afficher une interface Iterator pour qu'il sache toujours quand il est utilisé activement. Plus important encore, il sait quand l'appelant n'est plus en mesure de demander de valeurs, et donc quand il peut nettoyer les ressources.
Quand un flux s'exécute-t-il ?
Dans l'exemple ci-dessus, le Flow commence à s'exécuter lorsque l'opérateur collect s'exécute. La création d'un Flow en appelant l'outil de création flow ou d'autres API n'entraîne l'exécution d'aucune tâche. L'opérateur de suspension collect est appelé opérateur terminal dans Flow. Il existe d'autres opérateurs terminaux de suspension, comme toList, first et single, fournis avec kotlinx-coroutines. Vous pouvez également créer les vôtres.
Par défaut, Flow s'exécute :
- chaque fois qu'un opérateur terminal est appliqué (chaque nouvel appel est indépendant de ceux précédemment lancés) ;
- jusqu'à ce que la coroutine qu'il exécute soit annulée ;
- lorsque la dernière valeur a été entièrement traitée et qu'une autre valeur a été demandée.
En raison de ces règles, un Flow peut participer à la simultanéité structurée, et il est possible de démarrer des coroutines de longue durée à partir d'un Flow. Il n'y a aucun risque que des ressources soient perdues depuis un Flow, car celles-ci sont toujours nettoyées à l'aide de règles d'annulation coopérative de coroutines lorsque l'appelant est annulé.
Modifions à présent le flux ci-dessus de manière à ne voir que les deux premiers éléments à l'aide de l'opérateur take, puis collectons-le deux fois.
scope.launch {
val repeatableFlow = makeFlow().take(2) // we only care about the first two elements
println("first collection")
repeatableFlow.collect()
println("collecting again")
repeatableFlow.collect()
println("second collection completed")
}
Le résultat de l'exécution de ce code est le suivant :
first collection sending first value first value collected, sending another value collecting again sending first value first value collected, sending another value second collection completed
Le lambda flow commence au début à chaque appel de collect. C'est important si le flux a effectué un travail coûteux, comme une requête réseau. De plus, comme nous avons appliqué l'opérateur take(2), le flux ne produit que deux valeurs. Il ne reprend pas le lambda du flux après le deuxième appel à emit. La ligne "second value collected…" (deuxième valeur collectée) n'est donc jamais imprimée.
Le Flow génère des valeurs à la demande comme une Sequence, mais comment est-il aussi asynchrone ? Voyons un exemple de séquence asynchrone et observons les modifications apportées à une base de données.
Dans cet exemple, nous devons coordonner les données produites dans un pool de threads de base de données avec des observateurs qui résident dans un autre thread, par exemple le thread principal ou UI. De plus, étant donné que nous allons émettre des résultats de façon répétée à mesure que les données changent, ce scénario est naturellement adapté à un modèle de séquence asynchrone.
Imaginons que vous deviez écrire l'intégration Room pour Flow. Si vous avez commencé avec la prise en charge de requêtes de suspension existante dans Room, vous pouvez écrire le code suivant :
// This code is a simplified version of how Room implements flow
fun <T> createFlow(query: Query, tables: List<Tables>): Flow<T> = flow {
val changeTracker = tableChangeTracker(tables)
while(true) {
emit(suspendQuery(query))
changeTracker.suspendUntilChanged()
}
}
Ce code s'appuie sur deux fonctions de suspension imaginaires pour générer un Flow :
suspendQuery: fonction sécurisée qui exécute une requête de suspensionRoomstandardsuspendUntilChanged: fonction qui suspend la coroutine jusqu'à ce que l'une des tables change
Lorsqu'il est collecté, le flux commence par émettre (emits) la première valeur de la requête. Une fois cette valeur traitée, le flux reprend et appelle suspendUntilChanged, qui suspend le flux jusqu'à ce que l'une des tables change. À ce stade, rien ne se passe au niveau du système tant que l'une des tables n'a pas changé et le flux repris.
Lorsque le flux reprend, il exécute une autre requête sécurisée et emits les résultats. Ce processus se poursuit indéfiniment, en boucle.
Flow et simultanéité structurée
Nous ne voulons pas de pertes de travail. En elle-même la coroutine n'est pas très coûteuse, mais elle se réactive constamment pour exécuter une requête de base de données. Une telle perte est plutôt coûteuse.
Bien que nous ayons créé une boucle infinie, Flow va nous aider grâce à la simultanéité structurée.
Le seul moyen de consommer des valeurs ou de répéter une itération sur un flux consiste à utiliser un opérateur terminal. Comme tous les opérateurs terminaux sont des fonctions de suspension, le travail est lié à la durée de vie de la portée qui les appelle. Lorsque la portée est annulée, le flux s'annule automatiquement selon les règles d'annulation coopérative de coroutines standards. Ainsi, bien que nous ayons écrit une boucle infinie dans notre outil de création de flux, nous pouvons le consommer sans danger, sans pertes, grâce à la simultanéité structurée.
Dans cette étape, vous allez apprendre à utiliser Flow avec Room et à l'associer à l'interface utilisateur.
Cette étape se retrouve fréquemment dans de nombreux usages de Flow. Lorsqu'il est utilisé de cette manière, le Flow de Room fonctionne comme une requête de base de données observable semblable à LiveData.
Mettre à jour le DAO
Pour commencer, ouvrez PlantDao.kt et ajoutez deux nouvelles requêtes qui renvoient Flow<List<Plant>> :
PlantDao.kt
@Query("SELECT * from plants ORDER BY name")
fun getPlantsFlow(): Flow<List<Plant>>
@Query("SELECT * from plants WHERE growZoneNumber = :growZoneNumber ORDER BY name")
fun getPlantsWithGrowZoneNumberFlow(growZoneNumber: Int): Flow<List<Plant>>
Notez que, à l'exception des types renvoyés, ces fonctions sont identiques aux versions LiveData. Nous allons toutefois les développer côte à côte pour les comparer.
En spécifiant un type renvoyé Flow, Room exécute la requête avec les caractéristiques suivantes :
- Sécurité principale : les requêtes dont le type renvoyé est
Flows'exécutent toujours sur les exécuteursRoom. Par conséquent, elles sont toujours sécurisées. Vous n'avez rien à faire dans votre code pour qu'elles s'exécutent sur le thread principal. - Observation des modifications :
Roomdétecte automatiquement les modifications et émet de nouvelles valeurs dans le flux. - Séquence asynchrone :
Flowenvoie le résultat de requête complet à chaque modification, sans introduire de tampon. Si vous renvoyezFlow<List<T>>, le flux émet un élémentList<T>contenant toutes les lignes du résultat de requête. Il s'exécutera comme une séquence, en émettant un résultat de requête à la fois et en se suspendant jusqu'à la prochaine requête. - Annulable : lorsque la portée qui collecte ces flux est annulée,
Roomannule l'observation de cette requête.
Tout cela fait de Flow est un excellent type renvoyé pour observer la base de données depuis la couche UI.
Mettre à jour le dépôt
Pour continuer à associer les nouvelles valeurs renvoyées à l'interface utilisateur, ouvrez PlantRepository.kt et ajoutez le code suivant :
PlantRepository.kt
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
fun getPlantsWithGrowZoneFlow(growZoneNumber: GrowZone): Flow<List<Plant>> {
return plantDao.getPlantsWithGrowZoneNumberFlow(growZoneNumber.number)
}
Pour l'instant, nous n'allons transmettre que les valeurs Flow à l'appelant. C'est exactement ce que nous avons fait au début de cet atelier de programmation lorsque nous avons envoyé LiveData à ViewModel.
Mettre à jour ViewModel
Dans PlantListViewModel.kt, commençons simplement en affichant plantsFlow. Nous y reviendrons lors des prochaines étapes pour ajouter à la version du flux le basculement entre les zones de culture.
PlantListViewModel.kt
// add a new property to plantListViewModel
val plantsUsingFlow: LiveData<List<Plant>> = plantRepository.plantsFlow.asLiveData()
À nouveau, nous allons conserver la version LiveData (val plants) à des fins de comparaison.
Comme nous souhaitons conserver LiveData dans la couche de l'interface utilisateur pour cet atelier de programmation, nous allons utiliser la fonction d'extension asLiveData pour convertir Flow en LiveData. Tout comme l'outil de création LiveData, cela ajoute un délai d'inactivité configurable aux LiveData générées. Nous évitons ainsi d'avoir à redémarrer notre requête chaque fois que la configuration est modifiée (par exemple, lors de la rotation d'un appareil).
Étant donné que le flux assure la sécurité principale et offre la possibilité d'annuler, vous pouvez choisir de transmettre Flow jusqu'à la couche UI sans le convertir en LiveData. Cependant, pour cet atelier de programmation, nous nous bornerons à utiliser LiveData dans la couche UI.
Toujours dans ViewModel, ajoutez une mise à jour du cache dans le bloc init. Cette étape est facultative pour le moment. Toutefois, si vous videz le cache et n'ajoutez pas cet appel, aucune donnée ne s'affichera dans l'application.
PlantListViewModel.kt
init {
clearGrowZoneNumber() // keep this
// fetch the full plant list
launchDataLoad { plantRepository.tryUpdateRecentPlantsCache() }
}
Mettre à jour le fragment
Ouvrez PlantListFragment.kt, puis modifiez la fonction subscribeUi pour qu'elle pointe vers nos nouvelles LiveData plantsUsingFlow.
PlantListFragment.kt
private fun subscribeUi(adapter: PlantAdapter) {
viewModel.plantsUsingFlow.observe(viewLifecycleOwner) { plants ->
adapter.submitList(plants)
}
}
Exécuter l'application avec Flow
Si vous exécutez à nouveau l'application, vous devriez constater que vous chargez à présent les données en utilisant Flow. Comme nous n'avons pas encore implémenté switchMap, l'option de filtrage n'a aucun effet.
Dans l'étape suivante, nous verrons comment transformer les données en Flow.
Dans cette étape, vous allez appliquer l'ordre de tri à plantsFlow. Pour ce faire, nous allons utiliser l'API déclarative de flow.
En utilisant des transformations telles que map, combine ou mapLatest, nous pouvons exprimer comment nous souhaiterions transformer chaque élément qui traverse le flux de manière déclarative. Cela nous permet même d'exprimer la simultanéité de manière déclarative, ce qui peut vraiment simplifier le code. Dans cette section, vous allez découvrir comment utiliser des opérateurs pour demander à Flow de lancer deux coroutines et combiner leurs résultats de manière déclarative.
Pour commencer, ouvrez PlantRepository.kt et définissez un nouveau flux privé appelé customSortFlow :
PlantRepository.kt
private val customSortFlow = flow { emit(plantsListSortOrderCache.getOrAwait()) }
Ce champ définit un Flow qui, lorsqu'il est collecté, appelle getOrAwait et emit l'ordre de tri.
Comme ce flux n'émet qu'une seule valeur, vous pouvez également le créer directement à partir de la fonction getOrAwait en utilisant asFlow.
// Create a flow that calls a single function
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
Ce code crée un nouveau Flow qui appelle getOrAwait et émet le résultat comme première et unique valeur. Pour ce faire, il référence la méthode getOrAwait à l'aide de :: et appelle asFlow sur l'objet Function obtenu.
Ces deux flux produisent le même résultat, appellent getOrAwait et émettent le résultat avant la fin.
Combiner plusieurs flux de manière déclarative
Maintenant que nous avons deux flux, customSortFlow et plantsFlow, combinons-les de manière déclarative.
Ajoutez un opérateur combine à plantsFlow :
PlantRepository.kt
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
// When the result of customSortFlow is available,
// this will combine it with the latest value from
// the flow above. Thus, as long as both `plants`
// and `sortOrder` are have an initial value (their
// flow has emitted at least one value), any change
// to either `plants` or `sortOrder` will call
// `plants.applySort(sortOrder)`.
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
L'opérateur combine combine deux flux. Les deux flux seront exécutés dans leur coroutine, puis, chaque fois que l'un d'eux génère une nouvelle valeur, la transformation sera appelée avec la dernière valeur de l'un ou l'autre des flux.
En utilisant combine, nous pouvons combiner la recherche réseau mise en cache avec notre requête de base de données. Les deux seront exécutées simultanément sur plusieurs coroutines différentes. Cela signifie que, alors que Room lance la requête réseau, Retrofit peut lancer l'interrogation du réseau. Ensuite, dès qu'un résultat est disponible pour les deux flux, le lambda combine est appelé. Nous appliquons alors l'ordre de tri chargé aux végétaux chargés.
Pour voir comment l'opérateur combine fonctionne, modifiez customSortFlow afin de réaliser deux émissions avec un retard important dans onStart, comme ceci :
// Create a flow that calls a single function
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
.onStart {
emit(listOf())
delay(1500)
}
La transformation onStart se produit lorsqu'un observateur écoute avant d'autres opérateurs. Elle peut émettre des valeurs d'espace réservé. Ici, nous émettons une liste vide, retardons l'appel de getOrAwait de 1 500 ms et poursuivons l'exécution du flux d'origine. Si vous exécutez l'application maintenant, vous constaterez que la requête de la base de données Room est renvoyée immédiatement, en se combinant avec la liste vide (ce qui signifie qu'elle est triée par ordre alphabétique). Ensuite, environ 1 500 ms plus tard, le tri personnalisé est appliqué.
Avant de poursuivre l'atelier de programmation, supprimez la transformation onStart de customSortFlow.
Flux et sécurité principale
Flow peut appeler des fonctions sécurisées, comme nous le faisons ici. Il offre les garanties habituelles de sécurité principale des coroutines. Room et Retrofit nous fournissent la sécurité principale. Nous n'avons donc rien d'autre à faire pour créer des requêtes réseau ou de base de données avec Flow.
Ce flux utilise déjà les threads suivants :
plantService.customPlantSortOrders'exécute sur un thread Retrofit (il appelleCall.enqueue)getPlantsFlowexécutera des requêtes sur un exécuteur Room.applySorts'exécutera sur le coordinateur de collecte (dans le cas présent,Dispatchers.Main).
Si nous nous contentions d'appeler des fonctions de suspension dans Retrofit et d'utiliser des flux Room, nous n'aurions pas besoin de compliquer ce code avec ces questions de sécurité principale.
Toutefois, à mesure que la taille de notre ensemble de données augmente, l'appel de applySort risque de devenir suffisamment lent pour bloquer le thread principal. Flow propose une API déclarative appelée flowOn pour contrôler le thread sur lequel le flux s'exécute.
Ajoutez flowOn à plantsFlow, comme suit :
PlantRepository.kt
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
.flowOn(defaultDispatcher)
.conflate()
L'appel de flowOn a deux effets importants sur la façon dont le code s'exécute :
- Lancer une nouvelle coroutine sur le
defaultDispatcher(dans ce cas,Dispatchers.Default) pour exécuter et collecter le flux avant l'appel deflowOn. - Introduire un tampon pour envoyer les résultats de la nouvelle coroutine vers des appels ultérieurs.
- Émettre les valeurs de ce tampon dans
FlowaprèsflowOn. Dans le cas présent,asLiveDatadansViewModel.
Cette méthode est très semblable à la manière dont withContext change de coordinateur, mais elle introduit au milieu de nos transformations un tampon qui modifie le fonctionnement du flux. La coroutine lancée par flowOn est autorisée à générer des résultats plus rapidement que l'appelant les consomme et met en mémoire tampon un grand nombre d'entre eux par défaut.
Dans le cas présent, nous prévoyons d'envoyer les résultats à l'interface utilisateur. C'est pourquoi nous ne nous intéresserons qu'au résultat le plus récent. C'est ce à quoi sert l'opérateur conflate : il modifie le tampon de flowOn pour ne stocker que le dernier résultat. Si un autre résultat arrive avant que le précédent soit lu, il est remplacé.
Exécuter l'application
Si vous exécutez à nouveau l'application, vous devriez constater à présent que les données se chargent et que l'ordre de tri personnalisé est appliqué avec Flow. Comme nous n'avons pas encore implémenté switchMap, l'option de filtrage n'a aucun effet.
À l'étape suivante, nous allons découvrir une autre manière de fournir la sécurité principale à l'aide de flow.
Pour terminer la version de flux de cette API, ouvrez PlantListViewModel.kt, dans lequel nous allons basculer entre les flux en fonction de GrowZone, comme dans la version LiveData.
Ajoutez le code suivant sous liveData plants :
PlantListViewModel.kt
private val growZoneFlow = MutableStateFlow<GrowZone>(NoGrowZone)
val plantsUsingFlow: LiveData<List<Plant>> = growZoneFlow.flatMapLatest { growZone ->
if (growZone == NoGrowZone) {
plantRepository.plantsFlow
} else {
plantRepository.getPlantsWithGrowZoneFlow(growZone)
}
}.asLiveData()
Cet exemple montre comment intégrer des événements (modification de la zone de culture) dans un flux. Le but est le même que celui de la version LiveData.switchMap : basculer d'une source de données à une autre en fonction d'un événement.
Examiner le code
PlantListViewModel.kt
private val growZoneFlow = MutableStateFlow<GrowZone>(NoGrowZone)
Ce code définit un nouveau MutableStateFlow avec la valeur initiale NoGrowZone. C'est un type de conteneur de valeurs Flow qui ne contient que la dernière valeur reçue. Il s'agit d'une primitive de simultanéité à thread sécurisé. Vous pouvez donc l'écrire depuis plusieurs threads en même temps (et le thread vainqueur est celui considéré comme le "dernier").
Vous pouvez aussi vous abonner pour recevoir les mises à jour de la valeur actuelle. De manière générale, le comportement est semblable à celui de LiveData. Il contient simplement la dernière valeur et vous permet d'observer les modifications qui y sont apportées.
PlantListViewModel.kt
val plantsUsingFlow: LiveData<List<Plant>> = growZoneFlow.flatMapLatest { growZone ->
StateFlow est également un Flow standard. Vous pouvez donc utiliser tous les opérateurs comme vous le feriez normalement.
Ici, nous utilisons l'opérateur flatMapLatest, qui est identique à switchMap de LiveData. Chaque fois que growZone change de valeur, ce lambda est appliqué et doit renvoyer un Flow. Ensuite, le Flow renvoyé est utilisé comme Flow pour tous les opérateurs en aval.
En résumé, cela nous permet de passer d'un flux à l'autre en fonction de la valeur de growZone.
PlantListViewModel.kt
if (growZone == NoGrowZone) {
plantRepository.plantsFlow
} else {
plantRepository.getPlantsWithGrowZoneFlow(growZone)
}
Dans flatMapLatest, le changement s'effectue en fonction de growZone. Ce code est assez proche de celui de la version LiveData.switchMap. La seule différence est qu'il renvoie Flows au lieu de LiveDatas.
PlantListViewModel.kt
}.asLiveData()
Enfin, nous convertissons Flow en LiveData, car notre Fragment s'attend à afficher LiveData depuis ViewModel.
Modifier une valeur de StateFlow
Pour informer l'application du changement de filtre, nous pouvons définir MutableStateFlow.value. C'est un moyen simple de communiquer un événement dans une coroutine, comme nous le faisons ici.
PlantListViewModel.kt
fun setGrowZoneNumber(num: Int) {
growZone.value = GrowZone(num)
growZoneFlow.value = GrowZone(num)
launchDataLoad {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(GrowZone(num)) }
}
fun clearGrowZoneNumber() {
growZone.value = NoGrowZone
growZoneFlow.value = NoGrowZone
launchDataLoad {
plantRepository.tryUpdateRecentPlantsCache()
}
}
Exécuter à nouveau l'application
Si vous exécutez à nouveau l'application, le filtre fonctionne à présent à la fois pour la version LiveData et pour la version Flow.
À l'étape suivante, nous allons appliquer le tri personnalisé à getPlantsWithGrowZoneFlow.
L'une des fonctionnalités les plus intéressantes de Flow est sa compatibilité hors pair avec les fonctions de suspension. L'outil de création flow et pratiquement toutes les transformations proposent un opérateur suspend qui peut appeler n'importe quelle fonction de suspension. De ce fait, la sécurité principale pour les appels réseau et de base de données, ainsi que l'orchestration de plusieurs opérations asynchrones peuvent être réalisées en passant des appels à des fonctions de suspension standards depuis un flux.
Dans les faits, cela permet de combiner naturellement des transformations déclaratives avec du code impératif. Comme vous le verrez dans cet exemple, au sein d'un opérateur de mappage standard, vous pouvez orchestrer plusieurs opérations asynchrones sans appliquer de transformations supplémentaires. Dans de nombreux cas, cela peut se traduire par un code beaucoup plus simple que celui d'une approche entièrement déclarative.
Utiliser des fonctions de suspension pour orchestrer le travail asynchrone
Pour conclure notre découverte de Flow, nous allons appliquer le tri personnalisé à l'aide d'opérateurs de suspension.
Ouvrez PlantRepository.kt et ajoutez une transformation de mappage à getPlantsWithGrowZoneNumberFlow.
PlantRepository.kt
fun getPlantsWithGrowZoneFlow(growZone: GrowZone): Flow<List<Plant>> {
return plantDao.getPlantsWithGrowZoneNumberFlow(growZone.number)
.map { plantList ->
val sortOrderFromNetwork = plantsListSortOrderCache.getOrAwait()
val nextValue = plantList.applyMainSafeSort(sortOrderFromNetwork)
nextValue
}
}
Bien qu'elle combine deux opérations asynchrones, cette opération de mappage est sécurisée, car elle repose sur des fonctions de suspension standards pour gérer le travail asynchrone.
À mesure que chaque résultat de la base de données est renvoyé, nous récupérons l'ordre de tri en cache. S'il n'est pas encore prêt, il attend la requête réseau asynchrone. Une fois l'ordre de tri obtenu, vous pouvez appeler applyMainSafeSort en toute sécurité pour exécuter le tri dans le coordinateur par défaut.
Ce code est maintenant entièrement sécurisé en reportant les principales préoccupations liées à la sécurité sur les fonctions de suspension standards. C'est un peu plus simple que la même transformation implémentée dans plantsFlow.
Cependant, il convient de noter qu'elle s'exécutera un peu différemment. La valeur mise en cache sera récupérée à chaque fois que la base de données émettra une nouvelle valeur. Cela n'est pas un problème, car nous la mettons en cache correctement dans plantsListSortOrderCache. Mais si cette opération lançait une nouvelle requête réseau, cette implémentation générerait de nombreuses requêtes réseau inutiles. De plus, dans la version .combine, la requête réseau et la requête de base de données s'exécutent simultanément, alors qu'elles s'exécutent l'une après l'autre dans cette version.
En raison de ces différences, il n'existe pas de règle claire pour structurer ce code. Dans de nombreux cas, l'utilisation de transformations de suspension comme ici, rendant toutes les opérations asynchrones séquentielles, ne pose pas de problème. Toutefois, dans d'autres cas, il est préférable d'utiliser des opérateurs pour contrôler la simultanéité et fournir la sécurité principale.
Vous y êtes presque ! Dernière étape (facultative) : déplaçons à présent les requêtes réseau vers une coroutine basée sur les flux.
En procédant ainsi, nous pouvons supprimer la logique qui permet de passer des appels réseau à partir des gestionnaires appelés par onClick et de les retirer de growZone. Cela nous permet de créer une source de vérité unique et d'éviter une duplication du code : il est impossible pour un code de modifier le filtre sans actualiser le cache.
Ouvrez PlantListViewModel.kt et ajoutez le code suivant au bloc d'initialisation :
PlantListViewModel.kt
init {
clearGrowZoneNumber()
growZone.mapLatest { growZone ->
_spinner.value = true
if (growZone == NoGrowZone) {
plantRepository.tryUpdateRecentPlantsCache()
} else {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(growZone)
}
}
.onEach { _spinner.value = false }
.catch { throwable -> _snackbar.value = throwable.message }
.launchIn(viewModelScope)
}
Ce code lancera une nouvelle coroutine pour observer les valeurs envoyées à growZoneChannel. Vous pouvez désormais commenter les appels réseau dans les méthodes ci-dessous, car ils ne sont nécessaires que pour la version LiveData.
PlantListViewModel.kt
fun setGrowZoneNumber(num: Int) {
growZone.value = GrowZone(num)
growZoneFlow.value = GrowZone(num)
// launchDataLoad {
// plantRepository.tryUpdateRecentPlantsForGrowZoneCache(GrowZone(num))
// }
}
fun clearGrowZoneNumber() {
growZone.value = NoGrowZone
growZoneFlow.value = NoGrowZone
// launchDataLoad {
// plantRepository.tryUpdateRecentPlantsCache()
// }
}
Exécuter à nouveau l'application
Si vous exécutez à nouveau l'application, vous allez constater que l'actualisation du réseau est à présent contrôlée par growZone. Nous avons considérablement amélioré le code, car davantage de façons de modifier le filtre sont à l'origine d'une source unique de vérité pour laquelle le filtre est actif. De cette façon, la requête réseau et le filtre actuel ne risquent jamais de se désynchroniser.
Examiner le code
Examinons une par une toutes les nouvelles fonctions utilisées, en commençant par l'extérieur :
PlantListViewModel.kt
growZone
// ...
.launchIn(viewModelScope)
Cette fois, nous utilisons l'opérateur launchIn pour collecter le flux dans notre ViewModel.
L'opérateur launchIn crée une coroutine et collecte chaque valeur du flux. Elle sera lancée dans le CoroutineScope fourni. Dans le cas présent, viewModelScope. C'est très intéressant, car cela signifie que la collection est supprimée lorsque ViewModel est effacé.
Si vous n'indiquez aucun autre opérateur, il ne se passe pas grand-chose. Mais comme Flow fournit des lambdas de suspension dans tous ses opérateurs, il est facile de réaliser des actions asynchrones basées sur chaque valeur.
PlantListViewModel.kt
.mapLatest { growZone ->
_spinner.value = true
if (growZone == NoGrowZone) {
plantRepository.tryUpdateRecentPlantsCache()
} else {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(growZone)
}
}
C'est là que la magie opère : mapLatest applique cette fonction de mappage pour chaque valeur. Toutefois, contrairement à la méthode map standard, cette fonction lance une nouvelle coroutine pour chaque appel à la transformation de mappage. Ensuite, si une nouvelle valeur est émise par growZoneChannel avant la fin de la coroutine précédente, elle l'annule avant de démarrer une nouvelle.
Nous pouvons utiliser mapLatest pour contrôler la simultanéité. La transformation de flux peut créer la logique d'annulation/redémarrage à notre place. Ce code permet de réduire la taille et la complexité du code par rapport à l'écriture à la main de la même logique d'annulation.
L'annulation d'un Flow suit les règles d'annulation coopérative standards des coroutines.
PlantListViewModel.kt
.onEach { _spinner.value = false }
.catch { throwable -> _snackbar.value = throwable.message }
onEach est appelé à chaque fois que le flux en amont émet une valeur. Nous l'utilisons ici pour réinitialiser l'icône de chargement à la fin du traitement.
L'opérateur catch capture toutes les exceptions générées en amont de celui-ci, dans le flux. Il peut transmettre une nouvelle valeur au flux, par exemple un état d'erreur, renvoyer l'exception dans le flux ou effectuer un travail comme nous le faisons ici.
Lorsqu'une erreur se produit, nous demandons simplement à _snackbar d'afficher le message d'erreur.
Conclusion
Cette étape vous a montré comment contrôler la simultanéité à l'aide de Flow et comment consommer Flows dans un ViewModel sans dépendre d'un observateur d'interface utilisateur.
Défi supplémentaire : essayez de définir une fonction pour encapsuler le chargement de données de ce flux avec la signature suivante :
fun <T> loadDataFor(source: StateFlow<T>, block: suspend (T) -> Unit) {