
Interfejs Gemini Developer API zapewnia dostęp do modeli Gemini Google, dzięki czemu możesz tworzyć najnowocześniejsze funkcje generatywnej AI w swoich aplikacjach na Androida, w tym czat konwersacyjny, generowanie obrazów (za pomocą Nano Banana) i generowanie tekstu na podstawie tekstu, obrazu, dźwięku i filmu.
Aby uzyskać dostęp do modeli Gemini Pro i Flash, możesz użyć interfejsu Gemini Developer API z Firebase AI Logic. Umożliwia to rozpoczęcie pracy bez konieczności podawania karty kredytowej i zapewnia atrakcyjny poziom bezpłatny. Gdy sprawdzisz integrację z niewielką grupą użytkowników, możesz skalować, przechodząc na poziom płatny.

Pierwsze kroki
Zanim zaczniesz korzystać z interfejsu Gemini API bezpośrednio z aplikacji, musisz wykonać kilka czynności, w tym zapoznać się z promptami oraz skonfigurować Firebase i aplikację do korzystania z pakietu SDK.
Eksperymentowanie z promptami
Eksperymentowanie z promptami może pomóc Ci znaleźć najlepsze sformułowanie, treść i format dla aplikacji na Androida. Google AI Studio to zintegrowane środowisko programistyczne (IDE), którego możesz używać do tworzenia prototypów i projektowania promptów na potrzeby przypadków użycia aplikacji.
Tworzenie skutecznych promptów na potrzeby przypadku użycia wymaga szeroko zakrojonych eksperymentów, które są kluczową częścią tego procesu. Więcej informacji o promptach znajdziesz w dokumentacji Firebase.
Gdy uznasz, że prompt jest gotowy, kliknij przycisk <> , aby uzyskać fragmenty kodu , które możesz dodać do swojego kodu.
Konfigurowanie projektu Firebase i łączenie aplikacji z Firebase
Gdy będziesz gotowy(-a) do wywoływania interfejsu API z aplikacji, postępuj zgodnie z instrukcjami w „Kroku 1” przewodnika dla początkujących użytkowników Firebase AI Logic, aby skonfigurować Firebase i włączyć wymagane interfejsy API oraz usługi.
Dodawanie zależności Gradle
Dodaj te zależności Gradle do modułu aplikacji:
Kotlin
dependencies {
// ... other androidx dependencies
// Import the BoM for the Firebase platform
implementation(platform("com.google.firebase:firebase-bom:34.15.0"))
// Add the dependencies for the Firebase AI Logic and App Check libraries
// When using the BoM, you don't specify versions in Firebase library dependencies
implementation("com.google.firebase:firebase-ai")
implementation("com.google.firebase:firebase-appcheck-debug")
}
Java
dependencies {
// Import the BoM for the Firebase platform
implementation(platform("com.google.firebase:34.15.0"))
// Add the dependencies for the Firebase AI Logic and App Check libraries
// When using the BoM, you don't specify versions in Firebase library dependencies
implementation("com.google.firebase:firebase-ai")
implementation("com.google.firebase:firebase-appcheck-debug")
// Required for one-shot operations (to use `ListenableFuture` from Guava Android)
implementation("com.google.guava:guava:31.0.1-android")
// Required for streaming operations (to use `Publisher` from Reactive Streams)
implementation("org.reactivestreams:reactive-streams:1.0.4")
}
Konfigurowanie dostawcy debugowania Sprawdzania aplikacji na potrzeby lokalnego tworzenia aplikacji
Od początku lipca 2026 r. w ramach procesu konfiguracji z przewodnikiem dla AI Logic w konsoli Firebase funkcja Sprawdzanie aplikacji Firebase będzie automatycznie wymuszana w celu ochrony interfejsu Gemini API. Na potrzeby lokalnego tworzenia aplikacji musisz skonfigurować dostawcę debugowania Sprawdzania aplikacji, aby pominąć atestację, ale nadal wymuszać Sprawdzanie aplikacji.
W kompilacji debugowania skonfiguruj Sprawdzanie aplikacji tak, aby używała fabryki dostawcy debugowania:
Kotlin
Firebase.initialize(context = this) Firebase.appCheck.installAppCheckProviderFactory( DebugAppCheckProviderFactory.getInstance(), )Java
FirebaseApp.initializeApp(/*context=*/ this); FirebaseAppCheck firebaseAppCheck = FirebaseAppCheck.getInstance(); firebaseAppCheck.installAppCheckProviderFactory( DebugAppCheckProviderFactory.getInstance());Uzyskaj token debugowania:
Uruchom aplikację w emulatorze lub na urządzeniu testowym.
W dziennikach poszukaj tokena debugowania Sprawdzania aplikacji. Przykład:
D DebugAppCheckProvider: Enter this debug secret into the allow list in the Firebase Console for your project: 123a4567-b89c-12d3-e456-789012345678Skopiuj token (np.
123a4567-b89c-12d3-e456-789012345678).
Zarejestruj token debugowania w Sprawdzaniu aplikacji:
W konsoli Firebase otwórz Zabezpieczenia > Sprawdzanie aplikacji > Aplikacje kartę.
Znajdź swoją aplikację, kliknij menu przepełnienia (), a następnie wybierz Zarządzaj tokenami debugowania.
Postępuj zgodnie z instrukcjami wyświetlanymi na ekranie, aby zarejestrować token debugowania.
Więcej informacji o dostawcy debugowania (w tym o tym, jak uzyskać nowy token debugowania) znajdziesz w oficjalnej dokumentacji Sprawdzania aplikacji.
Inicjowanie modelu generatywnego
Zacznij od utworzenia instancji GenerativeModel i określenia nazwy modelu:
Kotlin
// Start by instantiating a GenerativeModel and specifying the model name: val model = Firebase.ai(backend = GenerativeBackend.googleAI()) .generativeModel("gemini-2.5-flash")
Java
GenerativeModel firebaseAI = FirebaseAI.getInstance(GenerativeBackend.googleAI()) .generativeModel("gemini-2.5-flash"); GenerativeModelFutures model = GenerativeModelFutures.from(firebaseAI);
Dowiedz się więcej o modelach dostępnych do użycia z interfejsem Gemini Developer API. Możesz też dowiedzieć się więcej o konfigurowaniu parametrów modelu.
Korzystanie z interfejsu Gemini Developer API w aplikacji
Po skonfigurowaniu Firebase i aplikacji do korzystania z pakietu SDK możesz już korzystać z interfejsu Gemini Developer API w aplikacji.
Generowanie tekstu
Aby wygenerować odpowiedź tekstową, wywołaj funkcję generateContent() z promptem.
Kotlin
scope.launch { val response = model.generateContent("Write a story about a magic backpack.") }
Java
Content prompt = new Content.Builder() .addText("Write a story about a magic backpack.") .build(); ListenableFuture<GenerateContentResponse> response = model.generateContent(prompt); Futures.addCallback(response, new FutureCallback<GenerateContentResponse>() { @Override public void onSuccess(GenerateContentResponse result) { String resultText = result.getText(); } @Override public void onFailure(Throwable t) { t.printStackTrace(); } }, executor);
Generowanie tekstu na podstawie obrazów i innych multimediów
Możesz też generować tekst na podstawie prompta, który zawiera tekst oraz obrazy lub inne multimedia. Gdy wywołujesz funkcję generateContent(), możesz przekazać multimedia jako dane wbudowane.
Na przykład, aby użyć mapy bitowej, użyj typu treści image:
Kotlin
scope.launch { val response = model.generateContent( content { image(bitmap) text("what is the object in the picture?") } ) }
Java
Content content = new Content.Builder() .addImage(bitmap) .addText("what is the object in the picture?") .build(); ListenableFuture<GenerateContentResponse> response = model.generateContent(content); Futures.addCallback(response, new FutureCallback<GenerateContentResponse>() { @Override public void onSuccess(GenerateContentResponse result) { String resultText = result.getText(); } @Override public void onFailure(Throwable t) { t.printStackTrace(); } }, executor);
Aby przekazać plik audio, użyj typu treści inlineData:
Kotlin
scope.launch { val contentResolver = applicationContext.contentResolver contentResolver.openInputStream(audioUri).use { stream -> stream?.let { val bytes = it.readBytes() val prompt = content { inlineData(bytes, "audio/mpeg") // Specify the appropriate audio MIME type text("Transcribe this audio recording.") } val response = model.generateContent(prompt) } } }
Java
ContentResolver resolver = applicationContext.getContentResolver(); try (InputStream stream = resolver.openInputStream(audioUri)) { File audioFile = new File(new URI(audioUri.toString())); int audioSize = (int) audioFile.length(); byte[] audioBytes = new byte[audioSize]; if (stream != null) { stream.read(audioBytes, 0, audioBytes.length); stream.close(); // Provide a prompt that includes audio specified earlier and text Content prompt = new Content.Builder() .addInlineData(audioBytes, "audio/mpeg") // Specify the appropriate audio MIME type .addText("Transcribe what's said in this audio recording.") .build(); // To generate text output, call `generateContent` with the prompt ListenableFuture<GenerateContentResponse> response = model.generateContent(prompt); Futures.addCallback(response, new FutureCallback<GenerateContentResponse>() { @Override public void onSuccess(GenerateContentResponse result) { String text = result.getText(); Log.d(TAG, (text == null) ? "" : text); } @Override public void onFailure(Throwable t) { Log.e(TAG, "Failed to generate a response", t); } }, executor); } else { Log.e(TAG, "Error getting input stream for file."); // Handle the error appropriately } } catch (IOException e) { Log.e(TAG, "Failed to read the audio file", e); } catch (URISyntaxException e) { Log.e(TAG, "Invalid audio file", e); }
Aby przekazać plik wideo, nadal używaj typu treści inlineData:
Kotlin
scope.launch { val contentResolver = applicationContext.contentResolver contentResolver.openInputStream(videoUri).use { stream -> stream?.let { val bytes = it.readBytes() val prompt = content { inlineData(bytes, "video/mp4") // Specify the appropriate video MIME type text("Describe the content of this video") } val response = model.generateContent(prompt) } } }
Java
ContentResolver resolver = applicationContext.getContentResolver(); try (InputStream stream = resolver.openInputStream(videoUri)) { File videoFile = new File(new URI(videoUri.toString())); int videoSize = (int) videoFile.length(); byte[] videoBytes = new byte[videoSize]; if (stream != null) { stream.read(videoBytes, 0, videoBytes.length); stream.close(); // Provide a prompt that includes video specified earlier and text Content prompt = new Content.Builder() .addInlineData(videoBytes, "video/mp4") .addText("Describe the content of this video") .build(); // To generate text output, call generateContent with the prompt ListenableFuture<GenerateContentResponse> response = model.generateContent(prompt); Futures.addCallback(response, new FutureCallback<GenerateContentResponse>() { @Override public void onSuccess(GenerateContentResponse result) { String resultText = result.getText(); System.out.println(resultText); } @Override public void onFailure(Throwable t) { t.printStackTrace(); } }, executor); } } catch (IOException e) { e.printStackTrace(); } catch (URISyntaxException e) { e.printStackTrace(); }
Podobnie możesz też przekazywać dokumenty PDF (application/pdf) i zwykłe dokumenty tekstowe (text/plain), przekazując ich odpowiedni typ MIME jako parametr.
Czat wieloetapowy
Możesz też obsługiwać rozmowy wieloetapowe. Zainicjuj czat za pomocą funkcji startChat(). Opcjonalnie możesz podać modelowi historię wiadomości. Następnie wywołaj funkcję sendMessage(), aby wysyłać wiadomości czatu.
Kotlin
val chat = model.startChat( history = listOf( content(role = "user") { text("Hello, I have 2 dogs in my house.") }, content(role = "model") { text("Great to meet you. What would you like to know?") } ) ) scope.launch { val response = chat.sendMessage("How many paws are in my house?") }
Java
Content.Builder userContentBuilder = new Content.Builder(); userContentBuilder.setRole("user"); userContentBuilder.addText("Hello, I have 2 dogs in my house."); Content userContent = userContentBuilder.build(); Content.Builder modelContentBuilder = new Content.Builder(); modelContentBuilder.setRole("model"); modelContentBuilder.addText("Great to meet you. What would you like to know?"); Content modelContent = modelContentBuilder.build(); List<Content> history = Arrays.asList(userContent, modelContent); // Initialize the chat ChatFutures chat = model.startChat(history); // Create a new user message Content.Builder messageBuilder = new Content.Builder(); messageBuilder.setRole("user"); messageBuilder.addText("How many paws are in my house?"); Content message = messageBuilder.build(); // Send the message ListenableFuture<GenerateContentResponse> response = chat.sendMessage(message); Futures.addCallback(response, new FutureCallback<GenerateContentResponse>() { @Override public void onSuccess(GenerateContentResponse result) { String resultText = result.getText(); System.out.println(resultText); } @Override public void onFailure(Throwable t) { t.printStackTrace(); } }, executor);
Generowanie obrazów na Androidzie za pomocą Nano Banana
Model Gemini 2.5 Flash Image (znany też jako Nano Banana) może generować i edytować obrazy, wykorzystując wiedzę o świecie i rozumowanie. Generuje obrazy odpowiednie do kontekstu, płynnie łącząc lub przeplatając tekst i obrazy. Może też generować dokładne obrazy z długimi sekwencjami tekstu i obsługuje edycję obrazów w trybie konwersacyjnym, zachowując kontekst.
W tym przewodniku opisujemy, jak używać modeli Gemini Image (modeli Nano Banana) za pomocą pakietu Firebase AI Logic SDK na Androida. Więcej informacji o generowaniu obrazów za pomocą Gemini znajdziesz w dokumentacji Firebase.
Inicjowanie modelu generatywnego
Utwórz instancję GenerativeModel i określ nazwę modelu gemini-2.5-flash-image-preview. Sprawdź, czy skonfigurujesz responseModalities tak, aby zawierały zarówno TEXT, jak i IMAGE.
Kotlin
val model = Firebase.ai(backend = GenerativeBackend.googleAI()).generativeModel( modelName = "gemini-2.5-flash-image-preview", // Configure the model to respond with text and images (required) generationConfig = generationConfig { responseModalities = listOf( ResponseModality.TEXT, ResponseModality.IMAGE ) } )
Java
GenerativeModel ai = FirebaseAI.getInstance(GenerativeBackend.googleAI()).generativeModel( "gemini-2.5-flash-image-preview", // Configure the model to respond with text and images (required) new GenerationConfig.Builder() .setResponseModalities(Arrays.asList(ResponseModality.TEXT, ResponseModality.IMAGE)) .build() ); GenerativeModelFutures model = GenerativeModelFutures.from(ai);
Generowanie obrazów (dane wejściowe tylko tekstowe)
Możesz poprosić model Gemini o wygenerowanie obrazów, podając prompt tylko tekstowy:
Kotlin
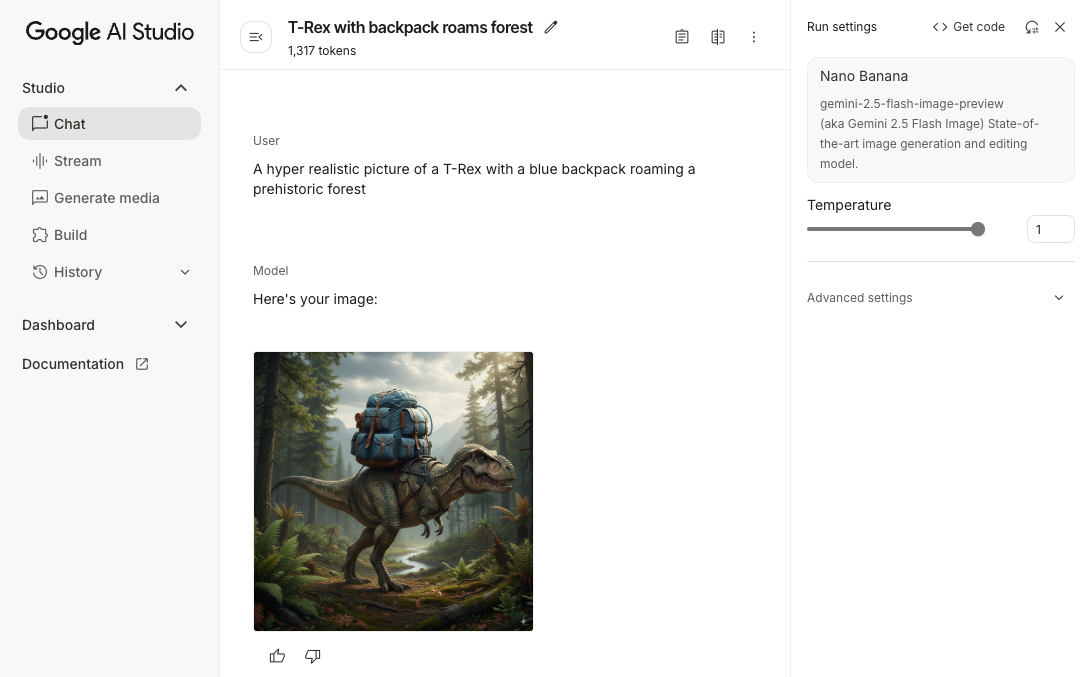
scope.launch { // Provide a text prompt instructing the model to generate an image val prompt = "A hyper realistic picture of a t-rex with a blue bag pack roaming a pre-historic forest." // To generate image output, call `generateContent` with the text input val generatedImageAsBitmap: Bitmap? = model.generateContent(prompt) .candidates.first().content.parts.filterIsInstance<ImagePart>() .firstOrNull()?.image }
Java
// Provide a text prompt instructing the model to generate an image Content prompt = new Content.Builder() .addText("Generate an image of the Eiffel Tower with fireworks in the background.") .build(); // To generate an image, call `generateContent` with the text input ListenableFuture<GenerateContentResponse> response = model.generateContent(prompt); Futures.addCallback(response, new FutureCallback<GenerateContentResponse>() { @Override public void onSuccess(GenerateContentResponse result) { // iterate over all the parts in the first candidate in the result object for (Part part : result.getCandidates().get(0).getContent().getParts()) { if (part instanceof ImagePart) { ImagePart imagePart = (ImagePart) part; // The returned image as a bitmap Bitmap generatedImageAsBitmap = imagePart.getImage(); break; } } } @Override public void onFailure(Throwable t) { t.printStackTrace(); } }, executor);
Edytowanie obrazów (dane wejściowe tekstowe i obrazowe)
Możesz poprosić model Gemini o edytowanie istniejących obrazów, podając w prompcie tekst i co najmniej 1 obraz:
Kotlin
scope.launch { // Provide a text prompt instructing the model to edit the image val prompt = content { image(bitmap) text("Edit this image to make it look like a cartoon") } // To edit the image, call `generateContent` with the prompt (image and text input) val generatedImageAsBitmap: Bitmap? = model.generateContent(prompt) .candidates.first().content.parts.filterIsInstance<ImagePart>().firstOrNull()?.image // Handle the generated text and image }
Java
// Provide an image for the model to edit Bitmap bitmap = BitmapFactory.decodeResource(resources, R.drawable.scones); // Provide a text prompt instructing the model to edit the image Content promptcontent = new Content.Builder() .addImage(bitmap) .addText("Edit this image to make it look like a cartoon") .build(); // To edit the image, call `generateContent` with the prompt (image and text input) ListenableFuture<GenerateContentResponse> response = model.generateContent(promptcontent); Futures.addCallback(response, new FutureCallback<GenerateContentResponse>() { @Override public void onSuccess(GenerateContentResponse result) { // iterate over all the parts in the first candidate in the result object for (Part part : result.getCandidates().get(0).getContent().getParts()) { if (part instanceof ImagePart) { ImagePart imagePart = (ImagePart) part; Bitmap generatedImageAsBitmap = imagePart.getImage(); break; } } } @Override public void onFailure(Throwable t) { t.printStackTrace(); } }, executor);
Iteracyjne edytowanie obrazów za pomocą czatu wieloetapowego
Aby edytować obrazy w trybie konwersacyjnym, możesz użyć czatu wieloetapowego. Umożliwia to wysyłanie kolejnych żądań w celu dopracowania zmian bez konieczności ponownego wysyłania oryginalnego obrazu.
Najpierw zainicjuj czat za pomocą funkcji startChat(), opcjonalnie podając historię wiadomości. Następnie użyj funkcji sendMessage() w przypadku kolejnych wiadomości:
Kotlin
scope.launch { // Create the initial prompt instructing the model to edit the image val prompt = content { image(bitmap) text("Edit this image to make it look like a cartoon") } // Initialize the chat val chat = model.startChat() // To generate an initial response, send a user message with the image and text prompt var response = chat.sendMessage(prompt) // Inspect the returned image var generatedImageAsBitmap: Bitmap? = response .candidates.first().content.parts.filterIsInstance<ImagePart>().firstOrNull()?.image // Follow up requests do not need to specify the image again response = chat.sendMessage("But make it old-school line drawing style") generatedImageAsBitmap = response .candidates.first().content.parts.filterIsInstance<ImagePart>().firstOrNull()?.image }
Java
// Provide an image for the model to edit Bitmap bitmap = BitmapFactory.decodeResource(resources, R.drawable.scones); // Initialize the chat ChatFutures chat = model.startChat(); // Create the initial prompt instructing the model to edit the image Content prompt = new Content.Builder() .setRole("user") .addImage(bitmap) .addText("Edit this image to make it look like a cartoon") .build(); // To generate an initial response, send a user message with the image and text prompt ListenableFuture<GenerateContentResponse> response = chat.sendMessage(prompt); // Extract the image from the initial response ListenableFuture<Bitmap> initialRequest = Futures.transform(response, result -> { for (Part part : result.getCandidates().get(0).getContent().getParts()) { if (part instanceof ImagePart) { ImagePart imagePart = (ImagePart) part; return imagePart.getImage(); } } return null; }, executor); // Follow up requests do not need to specify the image again ListenableFuture<GenerateContentResponse> modelResponseFuture = Futures.transformAsync( initialRequest, generatedImage -> { Content followUpPrompt = new Content.Builder() .addText("But make it old-school line drawing style") .build(); return chat.sendMessage(followUpPrompt); }, executor); // Add a final callback to check the reworked image Futures.addCallback(modelResponseFuture, new FutureCallback<GenerateContentResponse>() { @Override public void onSuccess(GenerateContentResponse result) { for (Part part : result.getCandidates().get(0).getContent().getParts()) { if (part instanceof ImagePart) { ImagePart imagePart = (ImagePart) part; Bitmap generatedImageAsBitmap = imagePart.getImage(); break; } } } @Override public void onFailure(Throwable t) { t.printStackTrace(); } }, executor);
Uwagi i ograniczenia
Pamiętaj o tych kwestiach i ograniczeniach:
- Format wyjściowy: obrazy są generowane jako pliki PNG o maksymalnym wymiarze 1024 pikseli.
- Typy danych wejściowych: model nie obsługuje danych wejściowych audio ani wideo na potrzeby generowania obrazów.
- Obsługa języków: aby uzyskać najlepszą wydajność, używaj tych języków:
angielski (
en), hiszpański meksykański (es-mx), japoński (ja-jp), chiński uproszczony (zh-cn) i hindi (hi-in). - Problemy z generowaniem:
- Generowanie obrazów nie zawsze może się udać, co czasami powoduje, że dane wyjściowe są tylko tekstowe. Spróbuj wyraźnie poprosić o dane wyjściowe w postaci obrazu (np. „wygeneruj obraz”, „podaj obrazy w trakcie”, „zaktualizuj obraz”).
- Model może przestać generować w trakcie procesu. Spróbuj ponownie lub użyj innego prompta.
- Model może wygenerować tekst jako obraz. Spróbuj wyraźnie poprosić o dane wyjściowe w postaci tekstu (np. „wygeneruj tekst narracyjny wraz z ilustracjami”).
Więcej informacji znajdziesz w dokumentacji Firebase.
Dalsze kroki
Po skonfigurowaniu aplikacji rozważ wykonanie tych czynności:
- Zapoznaj się z przykładową aplikacją Firebase na Androida umożliwiającą szybkie rozpoczęcie pracy sample app oraz z katalogiem przykładów AI na Androida na GitHubie.
- Przygotuj aplikację do wersji produkcyjnej, w tym skonfiguruj Sprawdzanie aplikacji Firebase, aby chronić interfejs Gemini API przed nadużyciami ze strony nieautoryzowanych klientów.
- Więcej informacji o Firebase AI Logic znajdziesz w dokumentacji Firebase.