
この Codelab では、LiveData ビルダーを使用して Android アプリで Kotlin コルーチンと LiveData を組み合わせる方法を学習します。また、Coroutines Asynchronous Flow は、値の非同期シーケンス(またはストリーム)を表現するコルーチン ライブラリの型ですが、これを使用して同様の実装を行います。
まず、Android アーキテクチャ コンポーネントを使用して作成された既存のアプリについて説明します。このアプリは、LiveData を使用して Room データベースからオブジェクトのリストを取得し、RecyclerView グリッド レイアウトに表示します。
演習内容を理解しやすいように、いくつかのコード スニペットを紹介します。次に示すのは、Room データベースにクエリを行う既存のコードです。
val plants: LiveData<List<Plant>> = plantDao.getPlants()
LiveData は、LiveData ビルダーと、追加の並べ替えロジックを含むコルーチンを使用して更新されます。
val plants: LiveData<List<Plant>> = liveData<List<Plant>> {
val plantsLiveData = plantDao.getPlants()
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsLiveData.map { plantList -> plantList.applySort(customSortOrder) })
}
また、同じロジックを Flow でも実装します。
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
.flowOn(defaultDispatcher)
.conflate()
前提条件
- アーキテクチャ コンポーネント
ViewModel、LiveData、Repository、Roomの使用経験 - 拡張関数やラムダを含む Kotlin 構文の使用経験
- Kotlin コルーチンの使用経験
- メインスレッド、バックグラウンド スレッド、コールバックなど、Android でのスレッドの使用に関する基本的な知識
演習内容
- Kotlin コルーチンに適した
LiveDataビルダーを使用するように既存のLiveDataを変換する。 LiveDataビルダー内にロジックを追加する。- 非同期オペレーションに
Flowを使用する。 Flowsを組み合わせて、複数の非同期ソースを変換する。Flowsで同時実行を制御する。LiveDataとFlow.の選択方法を学習する。
必要なもの
- Android Studio 4.1 以降。Codelab は他のバージョンでも動作する可能性がありますが、一部が欠けたり、外観が異なったりすることがあります。
この Codelab で問題(コードのバグ、文法的な誤り、不明確な表現など)が見つかった場合は、Codelab の左下隅にある [誤りを報告] から問題を報告してください。
コードをダウンロードする
次のリンクをクリックして、この Codelab のコードをすべてダウンロードします。
または次のコマンドを使用して、コマンドラインから GitHub リポジトリのクローンを作成します。
$ git clone https://github.com/googlecodelabs/kotlin-coroutines.git
この Codelab のコードは advanced-coroutines-codelab ディレクトリにあります。
よくある質問
まず、サンプルアプリがどんなものか見てみましょう。次の手順に沿って、Android Studio でサンプルアプリを開いてください。
kotlin-coroutineszip ファイルをダウンロードした場合は、ファイルを解凍します。- Android Studio で
advanced-coroutines-codelabディレクトリを開きます。 - 設定のプルダウンで
startが選択されていることを確認します。 - Run ボタン
 をクリックして、エミュレートしたデバイスを選択するか、Android デバイスを接続します。Android Lollipop が動作するデバイスである必要があります(対応 SDK は 21 以降)。
をクリックして、エミュレートしたデバイスを選択するか、Android デバイスを接続します。Android Lollipop が動作するデバイスである必要があります(対応 SDK は 21 以降)。
アプリを初めて実行するときに、カードのリストが表示され、それぞれに特定の植物の名前と画像が表示されます。

各 Plant には、植物を最も栽培しやすい地域を表す属性 growZoneNumber があります。フィルタ アイコン  をタップすると、すべての植物の表示と特定の栽培ゾーン(ゾーン 9 にハードコードされています)の植物の表示を切り替えることができます。フィルタボタンを数回押すと、実際の動作を確認できます。
をタップすると、すべての植物の表示と特定の栽培ゾーン(ゾーン 9 にハードコードされています)の植物の表示を切り替えることができます。フィルタボタンを数回押すと、実際の動作を確認できます。

アーキテクチャの概要
このアプリは、アーキテクチャ コンポーネントを使用して、MainActivity と PlantListFragment の UI コードを PlantListViewModel のアプリケーション ロジックから分離します。PlantRepository は ViewModel と PlantDao の間のブリッジを提供します。これは、Room データベースにアクセスして Plant オブジェクトのリストを返します。次に、UI はこの植物のリストを取得し、RecyclerView グリッド レイアウトに表示します。
コードを変更する前に、データベースから UI へのデータフローについて簡単に見てみましょう。以下は、ViewModel に植物のリストを読み込む仕組みです。
PlantListViewModel.kt
val plants: LiveData<List<Plant>> = growZone.switchMap { growZone ->
if (growZone == NoGrowZone) {
plantRepository.plants
} else {
plantRepository.getPlantsWithGrowZone(growZone)
}
}
GrowZone は、ゾーンを表す Int のみを含むインライン クラスです。NoGrowZone はゾーンが存在しないことを表し、フィルタリングにのみ使用されます。
Plant.kt
inline class GrowZone(val number: Int)
val NoGrowZone = GrowZone(-1)
フィルタボタンをタップすると growZone が切り替わります。switchMap を使用して返す植物のリストを決定します。
データベースから植物データを取得するリポジトリとデータアクセス オブジェクト(DAO)は次のようになります。
PlantDao.kt
@Query("SELECT * FROM plants ORDER BY name")
fun getPlants(): LiveData<List<Plant>>
@Query("SELECT * FROM plants WHERE growZoneNumber = :growZoneNumber ORDER BY name")
fun getPlantsWithGrowZoneNumber(growZoneNumber: Int): LiveData<List<Plant>>
PlantRepository.kt
val plants = plantDao.getPlants()
fun getPlantsWithGrowZone(growZone: GrowZone) =
plantDao.getPlantsWithGrowZoneNumber(growZone.number)
コード変更のほとんどは PlantListViewModel と PlantRepository で行いますが、データベースから Fragment までさまざまなレイヤを経て植物データがどのような様相を呈すかに注目しながら、プロジェクトの構造に慣れることをおすすめします。次のステップでは、LiveData ビルダーを使用してカスタム条件による並べ替え機能を追加するようにコードを変更します。
植物のリストは現在アルファベット順に表示されていますが、リストの順序を変更し、特定の植物を最初に表示して、残りをアルファベット順に表示したいと思います。これは、ショッピング アプリで購入可能な商品のリストの一番上にスポンサー検索結果を表示するのと同じです。Google プロダクト チームでは、新しいバージョンのアプリを出荷せずに、並べ替え順を動的に変更できるようにしたいと考えています。そのため、最初に並べ替える植物のリストをバックエンドから取得します。
カスタムの並べ替えを行った場合のアプリの外観は以下のとおりです。
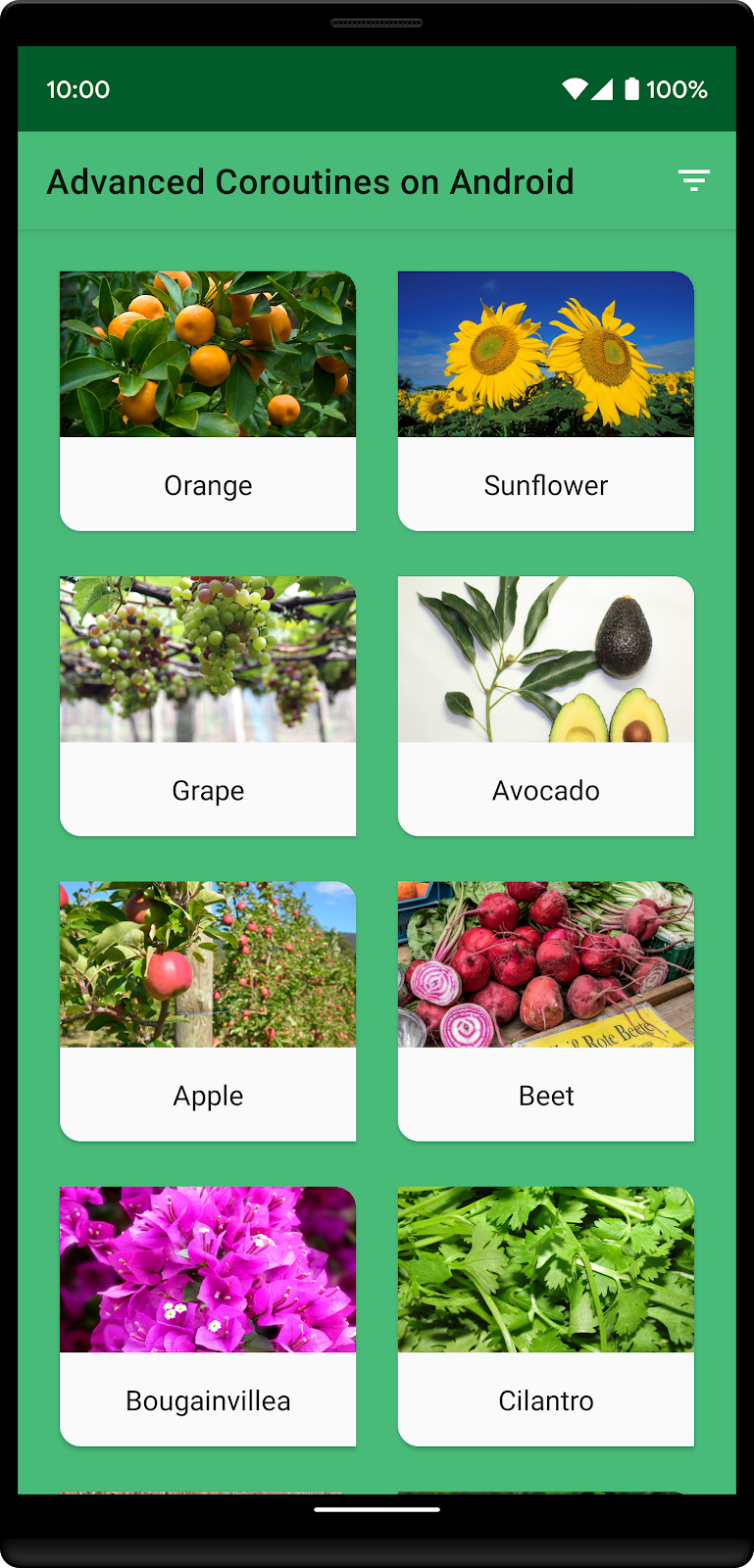
カスタムの並べ替え順リストは、オレンジ、ヒマワリ、ブドウ、アボカドの 4 つの植物で構成されています。この植物がリストの先頭に表示され、その後に他の植物がアルファベット順に表示されます。
ここでフィルタボタンが押されて(GrowZone 9 の植物だけが表示された)場合、GrowZone が 9 でないためにヒマワリがリストから消えます。カスタムの並べ替えリストに含まれる他の 3 つの植物は GrowZone 9 であるため、リストの一番上に残ります。他に GrowZone 9 に含まれる植物は、このリストの最後に出てくるトマトだけです。
カスタムの並べ替えを実装するコードを記述してみましょう。
まず、ネットワークからカスタムの並べ替え順を取得して、メモリにキャッシュする suspend 関数を作成します。
PlantRepository に以下を追加します。
PlantRepository.kt
private var plantsListSortOrderCache =
CacheOnSuccess(onErrorFallback = { listOf<String>() }) {
plantService.customPlantSortOrder()
}
plantsListSortOrderCache は、カスタムの並べ替え順のメモリ内キャッシュとして使用されます。ネットワーク エラーが発生すると空のリストにフォールバックするので、並べ替え順が取得できていない場合でも、引き続きアプリでデータを表示できます。
このコードは、sunflower モジュールで提供される CacheOnSuccess ユーティリティ クラスを使用してキャッシュを処理します。このようなキャッシュの実装の詳細を抽象化することにより、アプリケーション コードはよりシンプルになります。CacheOnSuccess はすでに十分にテストされているため、正しい動作を保証するために、リポジトリ用に大量のテストを作成する必要はありません。kotlinx-coroutines を使用するとき、コードに同様の上位レベルの抽象化を導入することをおすすめします。
次に、植物のリストに並べ替えを適用するロジックを組み込みます。
PlantRepository: に以下を追加します。
PlantRepository.kt
private fun List<Plant>.applySort(customSortOrder: List<String>): List<Plant> {
return sortedBy { plant ->
val positionForItem = customSortOrder.indexOf(plant.plantId).let { order ->
if (order > -1) order else Int.MAX_VALUE
}
ComparablePair(positionForItem, plant.name)
}
}
この拡張関数はリストを並べ替えて、customSortOrder に入っている Plants をリストの先頭に配置します。
これで並べ替えのロジックが設定されたので、plants と getPlantsWithGrowZone のコードを以下の LiveData ビルダーに置き換えます。
PlantRepository.kt
val plants: LiveData<List<Plant>> = liveData<List<Plant>> {
val plantsLiveData = plantDao.getPlants()
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsLiveData.map {
plantList -> plantList.applySort(customSortOrder)
})
}
fun getPlantsWithGrowZone(growZone: GrowZone) = liveData {
val plantsGrowZoneLiveData = plantDao.getPlantsWithGrowZoneNumber(growZone.number)
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsGrowZoneLiveData.map { plantList ->
plantList.applySort(customSortOrder)
})
}
アプリを実行すると、カスタムで並べ替えられた植物リストが表示されます。
liveData はコルーチンでサポートされているため、LiveData ビルダーを使用すると、値を非同期に計算できます。ここでは、データベースから LiveData リストをフェッチする一方で、サスペンド関数を呼び出してカスタムの並べ替え順を取得します。この 2 つの値を組み合わせて植物リストを並べ替え、その値を返します。これはすべてビルダー内で行います。
コルーチンは検出されると実行が開始され、コルーチンが正常に終了するか、データベースまたはネットワークの呼び出しが失敗した場合にキャンセルされます。
次のステップでは、Transformation を使用して getPlantsWithGrowZone のバリエーションについて調べます。
ここでは、PlantRepository を変更して、各値の処理とともに一時停止の変換を実装し、LiveData で複雑な非同期変換を構築する方法を学習します。前提条件として、メインスレッドで安全に使用できる並べ替えアルゴリズムを作成しましょう。withContext を使用して、ラムダのためだけに別のディスパッチャに切り替え、その後で最初に開始したディスパッチャで再開できます。
PlantRepository に以下を追加します。
PlantRepository.kt
@AnyThread
suspend fun List<Plant>.applyMainSafeSort(customSortOrder: List<String>) =
withContext(defaultDispatcher) {
this@applyMainSafeSort.applySort(customSortOrder)
}
これで、LiveData ビルダーでこの新しいメインセーフの並べ替えを使用できます。switchMap を使用するようにブロックを更新して、新しい値を受信するたびに新しい LiveData を指定できるようにします。
PlantRepository.kt
fun getPlantsWithGrowZone(growZone: GrowZone) =
plantDao.getPlantsWithGrowZoneNumber(growZone.number)
.switchMap { plantList ->
liveData {
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emit(plantList.applyMainSafeSort(customSortOrder))
}
}
以前のバージョンと比較すると、ネットワークからカスタム並べ替え順を受信すると、新しいメインセーフの applyMainSafeSort で使用できるようになりました。この結果は、getPlantsWithGrowZone によって返された新しい値として switchMap に出力されます。
上記の plants LiveData と同様、コルーチンは検出されると実行が開始され、完了するか、データベースまたはネットワーク呼び出しが失敗した場合に終了します。違いは、キャッシュされているためマップでネットワークを呼び出しても問題ないということです。
では、このコードが Flow でどのように実装されているかを確認して、実装を比較してみましょう。
これから kotlinx-coroutines の Flow を使用して、同じロジックを構築します。その前に、フローの概要とそのフローをアプリに組み込む方法を見てみましょう。
フローは Sequence の非同期バージョンであり、値が遅延生成されるコレクションの一種です。シーケンスと同様、フローでは、値が必要になるたびにオンデマンドで各値を生成します。フローには無制限の数の値を含めることができます。
では、Kotlin によって新しい Flow 型が導入されたのはなぜでしょうか。また、通常のシーケンスとはどう違うのでしょうか。答えは非同期性にあります。Flow には、コルーチンの完全なサポートが含まれています。つまり、コルーチンを使用して Flow をビルド、変換、使用できます。また、同時実行を制御することもできます。つまり、Flow を使用して複数のコルーチンの実行を宣言的に調整します。
これにより、さまざまな可能性が広がります。
Flow は、完全にリアクティブなプログラミング スタイルで使用できます。RxJava などを使用したことがあるなら、Flow もそれと同様の機能であると考えてください。map、flatMapLatest、combine などの関数演算子でフローを変換することで、アプリケーション ロジックを簡潔に説明できます。
また、Flow はほとんどの演算子の suspend 関数もサポートしています。これにより、map のような演算子内で非同期タスクを逐次的に実行できます。フロー内で一時停止オペレーションを行うと、完全にリアクティブなスタイルの同等のコードよりも、短くて読みやすいコードになることがよくあります。
この Codelab では、両方のアプローチについて説明します。
フローの実行方法
Flow がオンデマンドで(または遅延的に)値を生成する方法に慣れるには、値 (1, 2, 3) を出力して、各アイテムが生成される前、中、後に表示する次のフローを見てみましょう。
fun makeFlow() = flow {
println("sending first value")
emit(1)
println("first value collected, sending another value")
emit(2)
println("second value collected, sending a third value")
emit(3)
println("done")
}
scope.launch {
makeFlow().collect { value ->
println("got $value")
}
println("flow is completed")
}
これを実行すると、次の出力が生成されます。
sending first value got 1 first value collected, sending another value got 2 second value collected, sending a third value got 3 done flow is completed
collect ラムダと flow ビルダーの間で実行がどのようにバウンスするかを確認できます。フロービルダーが emit を呼び出すたびに、要素が完全に処理されるまで suspends になります。その後フローから別の値が要求されると、emit を再度呼び出すまで、中断した位置から resumes によって再開されます。flow ビルダーが完了すると、Flow がキャンセルされ、collect が再開され、呼び出したコルーチンが「flow completed」を表示します。
collect の呼び出しは非常に重要です。Flow は、Iterator インターフェースを公開するのではなく collect のような一時停止演算子を使用することで、アクティブに使用されているタイミングを常に把握できます。さらに重要な点は、呼び出し元がこれ以上値をリクエストできないタイミングを把握することで、リソースをクリーンアップできることです。
フローが実行されるタイミング
上記の例の Flow は、collect 演算子が実行されると実行が開始されます。flow ビルダーまたは他の API を呼び出して新しい Flow を作成しても、実行されることはありません。一時停止演算子 collect は、Flow の終了演算子と呼ばれます。他にも toList、first、single などの一時停止の終了演算子が kotlinx-coroutines で提供されるうえ、独自に作成することもできます。
Flow は以下のタイミングで実行されます:
- 終了演算子が適用されるたび(新しい呼び出しはそれぞれ、開始元の呼び出しとは無関係)
- 実行中のコルーチンがキャンセルされるまで
- 最後の値が完全に処理されて、別の値がリクエストされたとき
このようなルールにより、Flow は構造化された同時実行に参加することができ、Flow から長時間実行されるコルーチンを開始しても安全です。Flow がリソースをリークする可能性はありません。呼び出し元がキャンセルされると、コルーチンによる協調キャンセル ルールにより、リソースが常にクリーンアップされるためです。
上記のフローを変更して、take 演算子を使用して最初の 2 つの要素のみを確認してから、このフローを 2 回収集してみましょう。
scope.launch {
val repeatableFlow = makeFlow().take(2) // we only care about the first two elements
println("first collection")
repeatableFlow.collect()
println("collecting again")
repeatableFlow.collect()
println("second collection completed")
}
このコードを実行すると、次の出力が表示されます。
first collection sending first value first value collected, sending another value collecting again sending first value first value collected, sending another value second collection completed
flow ラムダは、collect が呼び出されるたびに先頭から開始されます。これは、フローがネットワーク リクエストなどの高負荷な処理を実行した場合に重要です。また、take(2) 演算子を適用したため、フローでは 2 つの値のみが生成されます。emit への 2 回目の呼び出しの後にフローラムダが再開することはないため、「second value collected...」という行は表示されません。
Flow は Sequence のように遅延しますが、非同期の場合はどうなるでしょうか。データベースへの変更を非同期で監視する例を見てみましょう。
この例では、データベース スレッドプールで生成したデータを、メインスレッドや UI スレッドなどの別のスレッドに存在するオブザーバーと調整する必要があります。また、データの変更に応じて結果を繰り返し生成するため、このシナリオは非同期シーケンス パターンに適しています。
Flow の Room 統合を作成する仕事があるとします。Room の既存のサスペンド クエリのサポートから始めた場合、次のように記述できます。
// This code is a simplified version of how Room implements flow
fun <T> createFlow(query: Query, tables: List<Tables>): Flow<T> = flow {
val changeTracker = tableChangeTracker(tables)
while(true) {
emit(suspendQuery(query))
changeTracker.suspendUntilChanged()
}
}
このコードは、2 つの架空の suspend 関数に依存して Flow を生成します。
suspendQuery- 通常のRoomのサスペンド クエリを実行するメインセーフ関数suspendUntilChanged- テーブルのいずれかが変更されるまで、コルーチンを停止する関数
収集されると、フローは初めに最初のクエリ値を emits します。その値が処理されると、フローが再開されて suspendUntilChanged が呼び出されます。これは、いずれかのテーブルが変更されるまでフローを停止します。この時点で、テーブルのいずれかが変更されてフローが再開されるまで、システムには何も起こりません。
フローが再開されると、別のメインセーフ クエリを作成して、結果を emits します。このプロセスは無限ループ内で繰り返されます。
フローと構造化された同時実行
しかし、処理漏れは防がなければなりません。コルーチン自体はそれほどコストの高い処理ではありませんが、データベース クエリを実行するために自動的に復帰するため、処理漏れは望ましくありません。
無限ループを作成しましたが、Flow は構造化された同時実行をサポートしてくれます。
値を使用したり、フローを反復したりするには、終了演算子を使用するしかありません。すべての終了演算子は suspend 関数であるため、処理は呼び出し元であるスコープの存続期間にバインドされます。スコープがキャンセルされると、フローは通常のコルーチンの協調キャンセル ルールを使用して自動的に自身をキャンセルします。そのため、フロービルダーに無限ループを記述しても、構造化された同時実行によって処理漏れなく安全に使用できます。
このステップでは、Room で Flow を使用して UI に接続する方法について学びます。
この手順は Flow の多くの用途で共通しています。このように使用すると、Room の Flow は、LiveData と同様に監視可能なデータベース クエリとして動作します。
Dao を更新する
まず、PlantDao.kt を開き、Flow<List<Plant>> を返す 2 つの新しいクエリを追加します。
PlantDao.kt
@Query("SELECT * from plants ORDER BY name")
fun getPlantsFlow(): Flow<List<Plant>>
@Query("SELECT * from plants WHERE growZoneNumber = :growZoneNumber ORDER BY name")
fun getPlantsWithGrowZoneNumberFlow(growZoneNumber: Int): Flow<List<Plant>>
なお、上記の関数は、戻り値の型を除き、LiveData バージョンと同じです。しかし、比較のため一緒に開発します。
戻り値の型 Flow を指定すると、Room は次の特性を持つクエリを実行します。
- メインセーフティ - 戻り値の型が
Flowのクエリは常にRoomエグゼキュータで実行されるため、常にメインセーフとなります。メインスレッドの外部で実行されるように、コードで何かする必要はありません。 - 変更の監視 -
Roomが自動的に変更を監視し、新しい値をフローに送信します。 - 非同期シーケンス -
Flowは、変更のたびにクエリ結果全体を生成します。バッファに取り込むことはありません。Flow<List<T>>を返すと、フローはクエリ結果のすべての行を含むList<T>を生成します。これは、シーケンスと同じように実行されます。つまり、クエリ結果を一度に 1 つずつ生成し、次のクエリ結果が要求されるまで一時停止します。 - キャンセル可能 – このフローを収集するスコープがキャンセルされると、
Roomは、このクエリの監視をキャンセルします。
つまり、Flow は UI レイヤからデータベースを監視するのに適した戻り値の型と言えます。
リポジトリを更新する
新しい戻り値を UI に引き継ぐには、PlantRepository.kt を開いて次のコードを追加します。
PlantRepository.kt
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
fun getPlantsWithGrowZoneFlow(growZoneNumber: GrowZone): Flow<List<Plant>> {
return plantDao.getPlantsWithGrowZoneNumberFlow(growZoneNumber.number)
}
今回は、Flow の値を呼び出し元に渡すだけです。これは、この Codelab を開始したときに LiveData を ViewModel に渡したのとまったく同じです。
ViewModel を更新する
PlantListViewModel.kt では、まずシンプルに plantsFlow を公開しましょう。後で説明しますが、次のステップからフロー バージョンに栽培ゾーンの切り替え機能を追加していきます。
PlantListViewModel.kt
// add a new property to plantListViewModel
val plantsUsingFlow: LiveData<List<Plant>> = plantRepository.plantsFlow.asLiveData()
ここでも、比較のために LiveData バージョン(val plants)を手元に置いて進めていきます。
今回の Codelab では、LiveData を UI レイヤに残すため、asLiveData 拡張関数を使用して Flow を LiveData に変換します。これにより、LiveData ビルダーと同様に、生成された LiveData に設定可能なタイムアウトが追加されます。これは、デバイスのローテーションなどで設定が変更されるたびにクエリが再開されるのを防ぎます。
フローではメインセーフティとキャンセル機能が提供されるため、Flow を LiveData に変換せずにずっと UI レイヤに渡すこともできます。このコードラボでは、引き続き UI レイヤで LiveData を使用します。
また、ViewModel でキャッシュの更新を init ブロックに追加します。現在のところこの手順は省略できますが、キャッシュを削除した後にこの呼び出しを追加しないと、アプリにはデータが表示されません。
PlantListViewModel.kt
init {
clearGrowZoneNumber() // keep this
// fetch the full plant list
launchDataLoad { plantRepository.tryUpdateRecentPlantsCache() }
}
フラグメントを更新する
PlantListFragment.kt を開き、新しい plantsUsingFlow LiveData を指すように subscribeUi 関数を変更します。
PlantListFragment.kt
private fun subscribeUi(adapter: PlantAdapter) {
viewModel.plantsUsingFlow.observe(viewLifecycleOwner) { plants ->
adapter.submitList(plants)
}
}
Flow を使用してアプリを実行する
アプリを再度実行すると、Flow を使用してデータが読み込まれていることがわかります。switchMap はまだ実装されていないため、フィルタ オプションは機能しません。
次のステップでは、Flow 内のデータの変換について説明します。
このステップでは、plantsFlow に並べ替え順を適用します。これは、flow の宣言型 API を使用して行います。
map、combine、mapLatest などの変換を使用することで、フロー内で移動する際の各要素の変換方法を宣言的に指定できます。また、同時実行を宣言的に表現できるため、コードを簡素化できます。このセクションでは、演算子を使用して Flow に 2 つのコルーチンを開始し、結果を宣言的に結合する方法を示します。
まず、PlantRepository.kt を開き、customSortFlow という新しいプライベート フローを定義します。
PlantRepository.kt
private val customSortFlow = flow { emit(plantsListSortOrderCache.getOrAwait()) }
ここでは、収集されると getOrAwait を呼び出して並べ替え順を emit する Flow を定義します。
このフローは 1 つの値しか出力しないため、asFlow を使用して getOrAwait 関数から直接ビルドすることもできます。
// Create a flow that calls a single function
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
このコードでは、getOrAwait を呼び出す新しい Flow を作成し、その結果を最初で唯一の値として出力します。これを行うには、:: を使用して getOrAwait メソッドを参照し、結果の Function オブジェクトで asFlow を呼び出します。
どちらのフローも同じように、getOrAwait を呼び出し、完了する前に結果を生成します。
複数のフローを宣言的に結合する
これで customSortFlow と plantsFlow の 2 つのフローができたので、宣言的に結合してみましょう。
combine 演算子を plantsFlow に追加します。
PlantRepository.kt
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
// When the result of customSortFlow is available,
// this will combine it with the latest value from
// the flow above. Thus, as long as both `plants`
// and `sortOrder` are have an initial value (their
// flow has emitted at least one value), any change
// to either `plants` or `sortOrder` will call
// `plants.applySort(sortOrder)`.
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
combine 演算子は 2 つのフローを結合します。両方のフローが独自のコルーチンで実行されるため、いずれかのフローが新しい値を生成するたびに、いずれかのフローの最新値で変換が呼び出されます。
combine を使用すると、キャッシュされたネットワーク検索とデータベース クエリを結合できます。両者は異なるコルーチン上で同時に実行されます。つまり、Room でネットワーク リクエストを開始する一方で、Retrofit でネットワーク クエリを開始できます。両方のフローで結果が得られるようになるとすぐに、combine ラムダを呼び出し、読み込まれた植物に読み込まれた並べ替え順を適用します。
combine 演算子の仕組みを確認するには、次に示すように customSortFlow を変更して、onStart で大幅な遅延を設けて 2 回生成します。
// Create a flow that calls a single function
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
.onStart {
emit(listOf())
delay(1500)
}
変換 onStart は、オブザーバーが他の演算子の前にリッスンするときに発生し、プレースホルダの値を生成できます。そのため、ここでは空のリストを生成し、getOrAwait の呼び出しを 1,500 ミリ秒遅らせてから元のフローを続行します。このアプリを実行すると、Room データベース クエリがすぐに返され、空のリストと結合していることがわかります(つまり、アルファベット順に並べ替えられます)。約 1,500 ミリ秒後にカスタムの並べ替えが適用されます。
Codelab を続行する前に、customSortFlow から onStart 変換を削除します。
フローとメインセーフティ
Flow は、ここで行っているようにメインセーフの関数を呼び出すことができます。これにより、コルーチンの通常のメインセーフティに関する保証が維持されます。Room と Retrofit の両方がメインセーフティを提供します。そのため、Flow でネットワーク リクエストやデータベース クエリを行うために他に何もする必要はありません。
このフローでは、すでに次のスレッドを使用しています。
plantService.customPlantSortOrderは Retrofit スレッドで実行される(Call.enqueueを呼び出す)getPlantsFlowは Room Executor でクエリを実行するapplySortは収集ディスパッチャ(この場合はDispatchers.Main)で実行される
したがって、Retrofit で suspend 関数を呼び出し、Room フローを使用するだけであれば、メインセーフティの問題でこのコードを複雑化する必要はありません。
ただし、データセットのサイズが増えると、applySort の呼び出しが遅くなり、メインスレッドをブロックする可能性があります。Flow には flowOn という宣言型 API があり、フローを実行するスレッドを制御できます。
次のように plantsFlow に flowOn を追加します。
PlantRepository.kt
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
.flowOn(defaultDispatcher)
.conflate()
flowOn の呼び出しは、コードの実行に以下のような重要な効果があります。
defaultDispatcher(この場合はDispatchers.Default)で新しいコルーチンを起動して、flowOnを呼び出す前にフローを実行して収集できます。- 新しいコルーチンの結果を後の呼び出しに送信するためのバッファを導入します。
flowOnの後に、そのバッファの値をFlowに出力します。この場合はViewModelのasLiveDataです。
これは withContext がディスパッチャを切り替える動作とよく似ていますが、変換の途中でバッファが導入され、フローの動作が変わります。flowOn によって開始されたコルーチンは、呼び出し元が消費するよりも早く結果を生成でき、デフォルトでは多数の結果をバッファリングします。
ここでは結果を UI に送信するため、最新の結果だけを考慮します。これが conflate 演算子の役割で、flowOn のバッファを変更して最後の結果のみを格納します。前の結果を読み取る前に別の結果が届くと、その結果が上書きされます。
アプリを実行する
アプリを再度実行すると、データが読み込まれ、Flow を使用してカスタムの並べ替え順が適用されていることがわかります。switchMap はまだ実装されていないため、フィルタ オプションは機能しません。
次のステップでは、flow を使用してメイン セーフティを確保するもう 1 つの方法を示します。
この API のフロー バージョンを完成させるには、PlantListViewModel.kt を開いて、LiveData バージョンと同様に GrowZone に基づいてフローを切り替えます。
plants の liveData の下に次のコードを追加します。
PlantListViewModel.kt
private val growZoneFlow = MutableStateFlow<GrowZone>(NoGrowZone)
val plantsUsingFlow: LiveData<List<Plant>> = growZoneFlow.flatMapLatest { growZone ->
if (growZone == NoGrowZone) {
plantRepository.plantsFlow
} else {
plantRepository.getPlantsWithGrowZoneFlow(growZone)
}
}.asLiveData()
このパターンでは、イベント(栽培ゾーンの変更)をフローに統合する方法を示しています。これは LiveData.switchMap バージョンとまったく同じことを行います。つまり、イベントに基づいて 2 つのデータソースを切り替えます。
コードのステップ実行
PlantListViewModel.kt
private val growZoneFlow = MutableStateFlow<GrowZone>(NoGrowZone)
これにより、NoGrowZone の初期値を持つ新しい MutableStateFlow が定義されます。これは、最後に渡された値のみを保持する特殊な種類の Flow 値ホルダーです。これはスレッドセーフの同時実行プリミティブであるため、複数のスレッドから同時に書き込むことができます(「最後」とみなされた方が選ばれます)。
最新の現在値を取得できるように登録することもできます。全体として、LiveData と同様の動作になります。つまり、最後の値を保持し、変更を監視できます。
PlantListViewModel.kt
val plantsUsingFlow: LiveData<List<Plant>> = growZoneFlow.flatMapLatest { growZone ->
StateFlow は通常の Flow でもあるため、通常どおりにすべての演算子を使用できます。
ここでは、LiveData の switchMap とまったく同じ flatMapLatest 演算子を使用します。growZone で値が変更されるたびに、このラムダが適用され、Flow を返す必要があります。そして、返された Flow がすべてのダウンストリーム演算子の Flow として使用されます。
基本的には、これにより growZone の値に基づいて別のフローに切り替えられるようになります。
PlantListViewModel.kt
if (growZone == NoGrowZone) {
plantRepository.plantsFlow
} else {
plantRepository.getPlantsWithGrowZoneFlow(growZone)
}
flatMapLatest 内では、growZone に基づいて切り替えます。このコードは、LiveData.switchMap バージョンとほとんど同じですが、LiveDatas ではなく Flows を返す点のみが異なります。
PlantListViewModel.kt
}.asLiveData()
最後に、Fragment が ViewModel から LiveData を公開すると想定しているため、Flow を LiveData に変換します。
StateFlow の値を変更する
アプリにフィルタの変更を通知するには、MutableStateFlow.value を設定します。今回のように、簡単にイベントをコルーチンに伝えることができます。
PlantListViewModel.kt
fun setGrowZoneNumber(num: Int) {
growZone.value = GrowZone(num)
growZoneFlow.value = GrowZone(num)
launchDataLoad {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(GrowZone(num)) }
}
fun clearGrowZoneNumber() {
growZone.value = NoGrowZone
growZoneFlow.value = NoGrowZone
launchDataLoad {
plantRepository.tryUpdateRecentPlantsCache()
}
}
アプリを再度実行する
アプリを再度実行すると、LiveData バージョンと Flow バージョンの両方でフィルタが機能するようになります。
次のステップでは、getPlantsWithGrowZoneFlow にカスタムの並べ替えを適用します。
Flow の特に便利な機能の 1 つは、suspend 関数に対する最高レベルのサポートです。flow ビルダーとほぼすべての変換で、任意の suspend 関数を呼び出すことができる suspend 演算子が公開されます。そのため、フロー内から通常の suspend 関数を呼び出して、ネットワークやデータベース呼び出しのメインセーフティと、複数の非同期オペレーションのオーケストレーションを実現できます。
これにより、宣言型変換と命令型のコードを自然に融合させることができます。この例でわかるように、通常のマップ演算子の内部では、追加の変換を適用しなくても、複数の非同期オペレーションをオーケストレートできます。多くの場合、完全に宣言型のアプローチよりも、コードがかなりシンプルになる可能性があります。
suspend 関数を使用して非同期処理をオーケストレートする
Flow の探索のしめくくりとして、suspend 演算子を使用してカスタムの並べ替えを適用します。
PlantRepository.kt を開き、getPlantsWithGrowZoneNumberFlow へのマップ変換を追加します。
PlantRepository.kt
fun getPlantsWithGrowZoneFlow(growZone: GrowZone): Flow<List<Plant>> {
return plantDao.getPlantsWithGrowZoneNumberFlow(growZone.number)
.map { plantList ->
val sortOrderFromNetwork = plantsListSortOrderCache.getOrAwait()
val nextValue = plantList.applyMainSafeSort(sortOrderFromNetwork)
nextValue
}
}
非同期処理に通常の suspend 関数を活用すると、このマップ オペレーションは 2 つの非同期オペレーションが結合されていてもメインセーフになります。
データベースからの各結果が返されると、キャッシュされた並べ替え順を取得します。まだ準備ができていない場合は、非同期ネットワーク リクエストを待機します。並べ替え順を取得できたら、applyMainSafeSort を呼び出しても安全です。これにより、デフォルトのディスパッチャで並べ替えが行われます。
このコードは、メインセーフティの問題を通常の suspend 関数に委ねることで、完全にメインセーフになっています。plantsFlow に実装されているのと同じ変換よりもはるかにシンプルです。
ただし、実行方法が多少異なるためご注意ください。データベースが新しい値を生成するたびにキャッシュされた値を取得します。これは plantsListSortOrderCache で正しくキャッシュされているため問題ありませんが、新しいネットワーク リクエストを開始した場合、この実装では不要なネットワーク リクエストが多数発生することになります。また、.combine バージョンではネットワーク リクエストとデータベース クエリが同時に実行されていましたが、このバージョンでは順番に実行されます。
このような違いがあるため、このコードを構成する明確なルールはありません。多くの場合、ここで行っているように一時停止の変換を使用して、すべての非同期オペレーションを順次処理することに問題はありません。ただし、それ以外の場合は、演算子を使用して同時実行を制御し、メイン セーフティとすることをおすすめします。
あと少しです。最後のステップ(任意)として、ネットワーク リクエストをフローベースのコルーチンに移動してみましょう。
こうすることで、onClick で呼び出されるハンドラからネットワーク呼び出しのロジックを削除して、growZone から駆動させることができます。これにより、信頼できる唯一の情報源を作成して、コードの重複を回避できます。キャッシュを更新せずにコードでフィルタを変更する方法はありません。
PlantListViewModel.kt を開き、これを init ブロックに追加します。
PlantListViewModel.kt
init {
clearGrowZoneNumber()
growZone.mapLatest { growZone ->
_spinner.value = true
if (growZone == NoGrowZone) {
plantRepository.tryUpdateRecentPlantsCache()
} else {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(growZone)
}
}
.onEach { _spinner.value = false }
.catch { throwable -> _snackbar.value = throwable.message }
.launchIn(viewModelScope)
}
このコードは新しいコルーチンを開始して、growZoneChannel に送信された値を監視します。下記のメソッドのネットワーク呼び出しが必要になるのは LiveData バージョンだけであるため、コメントアウトしても構いません。
PlantListViewModel.kt
fun setGrowZoneNumber(num: Int) {
growZone.value = GrowZone(num)
growZoneFlow.value = GrowZone(num)
// launchDataLoad {
// plantRepository.tryUpdateRecentPlantsForGrowZoneCache(GrowZone(num))
// }
}
fun clearGrowZoneNumber() {
growZone.value = NoGrowZone
growZoneFlow.value = NoGrowZone
// launchDataLoad {
// plantRepository.tryUpdateRecentPlantsCache()
// }
}
アプリを再度実行する
アプリを再度実行すると、ネットワークの更新が growZone によって制御されていることがわかります。フィルタを変更する方法が増え、どのフィルタが有効であるかを示す信頼できる唯一の情報源としてチャネルが機能するように、コードを大幅に改善しました。これにより、ネットワーク リクエストと現在のフィルタの同期が取れなくなることはありません。
コードのステップ実行
外部から始めて、使用されている新しい関数を一度に 1 つずつステップ実行しましょう。
PlantListViewModel.kt
growZone
// ...
.launchIn(viewModelScope)
今回は、launchIn 演算子を使用して ViewModel 内のフローを収集します。
演算子 launchIn は、新規コルーチンを作成し、フローからすべての値を収集します。提供されている CoroutineScope(ここでは viewModelScope)で起動します。この「ViewModel」がクリアされると、収集がキャンセルされるため便利です。
他の演算子を指定しない場合、これはあまり効果がありませんが、Flow はすべての演算子で一時停止のラムダを提供するため、すべての値に基づいて非同期アクションを簡単に作成できます。
PlantListViewModel.kt
.mapLatest { growZone ->
_spinner.value = true
if (growZone == NoGrowZone) {
plantRepository.tryUpdateRecentPlantsCache()
} else {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(growZone)
}
}
ここがポイントです。mapLatest により、各値にこのマップ関数が適用されます。ただし、通常の map とは異なり、マップ変換の呼び出しごとに新しいコルーチンが開始されます。そして、前のコルーチンが完了する前に growZoneChannel によって新しい値が生成されると、新しいコルーチンを開始する前にその値がキャンセルされます。
mapLatest を使用すると同時実行を制御できます。キャンセルや再開のロジックを自分で構築するのではなく、フロー変換で処理できます。このコードの場合、同じキャンセル ロジックを手書きで書くのに比べて、コード量と複雑さが大幅に削減されます。
Flow のキャンセルは、コルーチンの通常の協調キャンセル ルールに従います。
PlantListViewModel.kt
.onEach { _spinner.value = false }
.catch { throwable -> _snackbar.value = throwable.message }
onEach は、上記のフローが値を生成するたびに呼び出されます。ここでは、処理の完了後にスピナーをリセットするために使用します。
catch 演算子は、フローにおいてスローされた例外をキャプチャします。エラー状態などの新しい値をフローに出力したり、例外をフローに戻したり、ここで行っているように処理したりできます。
エラーが発生した場合は、ただエラー メッセージを表示するように _snackbar に指示しています。
まとめ
このステップでは、Flow を使用して同時実行を制御する方法と、UI オブザーバーを使用せずに ViewModel 内で Flows を使用する方法を紹介しました。
試しに、このフローのデータ読み込みを以下のシグネチャでカプセル化する関数を定義してみてください。
fun <T> loadDataFor(source: StateFlow<T>, block: suspend (T) -> Unit) {