
التفاصيل المتقدّمة: MessageQueue في Android 17 بدون قفل
يستغرق الاطّلاع على المقال 16 دقيقة

في الإصدار 17 من نظام التشغيل Android، ستتلقّى التطبيقات التي تستهدف الإصدار 37 من حزمة تطوير البرامج (SDK) أو إصدارًا أحدث عملية تنفيذ جديدة لفئة MessageQueue لا تتطلّب قفلًا. يؤدي التنفيذ الجديد إلى تحسين الأداء وتقليل اللقطات التي لم يتم عرضها، ولكن قد يؤدي إلى تعطّل العملاء الذين يعتمدون على الحقول والأساليب الخاصة في MessageQueue. لمزيد من المعلومات عن تغيير السلوك وكيفية الحدّ من التأثير، راجِع مستندات تغيير سلوك MessageQueue. تقدّم مشاركة المدونة الفنية هذه نظرة عامة على إعادة تصميم MessageQueue وكيفية تحليل مشاكل تعارض القفل باستخدام Perfetto.
يُشغّل Looper سلسلة واجهة المستخدم لكل تطبيق Android. يستردّ العمل من MessageQueue، ويرسله إلى Handler، ثم يكرّر العملية. على مدار عقدَين من الزمن، استخدمت MessageQueue قفل شاشة واحدًا (أي synchronized مجموعة رموز) لحماية حالتها.
يقدّم نظام التشغيل Android 17 تحديثًا مهمًا لهذا المكوّن، وهو تنفيذ خالٍ من الأقفال يُسمى DeliQueue.
توضّح هذه المشاركة كيف تؤثّر عمليات القفل في أداء واجهة المستخدم، وكيفية تحليل هذه المشاكل باستخدام Perfetto، والخوارزميات والتحسينات المحدّدة المستخدَمة لتحسين سلسلة التعليمات الرئيسية في Android.
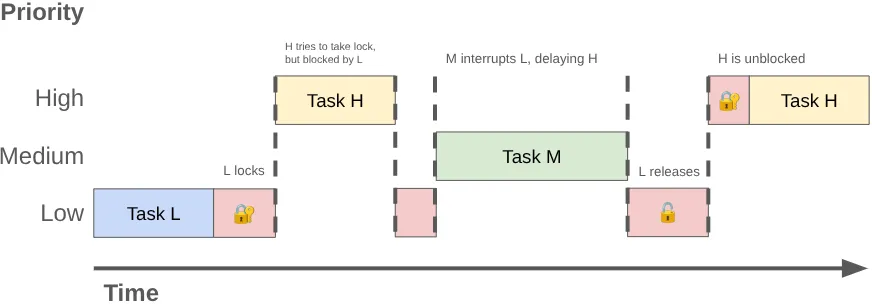
المشكلة: تعارض القفل وعكس الأولوية
كانت وظيفة MessageQueue القديمة تعمل كقائمة انتظار ذات أولوية محمية بقفل واحد. إذا نشرت سلسلة محادثات في الخلفية رسالة أثناء إجراء سلسلة المحادثات الرئيسية لصيانة قائمة الانتظار، ستحظر سلسلة المحادثات في الخلفية سلسلة المحادثات الرئيسية.
عندما تتنافس سلسلتان أو أكثر من سلاسل التعليمات البرمجية على الاستخدام الحصري للقفل نفسه، يُعرف ذلك باسم التنازع على القفل. يمكن أن يؤدي هذا التعارض إلى انعكاس الأولوية، ما يؤدي إلى حدوث إيقاف مؤقت لعرض واجهة المستخدم ومشاكل أخرى في الأداء.
يمكن أن تحدث مشكلة "قلب الأولويات" عندما يتم إجبار سلسلة تعليمات ذات أولوية عالية (مثل سلسلة واجهة المستخدم) على انتظار سلسلة تعليمات ذات أولوية منخفضة. لنفترض التسلسل التالي:
- يحصل مؤشر ترابط الخلفية منخفض الأولوية على قفل
MessageQueueلنشر نتيجة العمل الذي نفّذه. - تصبح سلسلة المحادثات ذات الأولوية المتوسطة قابلة للتنفيذ، ويخصّص لها برنامج جدولة النواة وقتًا لوحدة المعالجة المركزية، ما يؤدي إلى إيقاف سلسلة المحادثات ذات الأولوية المنخفضة.
- تُنهي سلسلة تعليمات واجهة المستخدم ذات الأولوية العالية مهمتها الحالية وتحاول القراءة من قائمة الانتظار، ولكن يتم حظرها لأنّ سلسلة التعليمات ذات الأولوية المنخفضة تحتفظ بدالة الاستبعاد المتبادل.
يؤدي مؤشر الترابط ذو الأولوية المنخفضة إلى حظر سلسلة واجهة المستخدم، ويؤدي العمل ذو الأولوية المتوسطة إلى تأخيره أكثر.
تحليل التنازع باستخدام Perfetto
يمكنك تشخيص هذه المشاكل باستخدام Perfetto. في عملية تتبُّع عادية، ينتقل مؤشر ترابط محظور على قفل مراقبة إلى حالة السكون، ويعرض Perfetto شريحة تشير إلى مالك القفل.
عند طلب بيانات التتبُّع، ابحث عن شرائح باسم "مراقبة التعارض مع …" متبوعة باسم سلسلة التعليمات البرمجية التي تملك القفل وموقع الرمز البرمجي الذي تم فيه الحصول على القفل.
دراسة حالة: بطء "مشغّل التطبيقات"
لتوضيح ذلك، لنحلّل عملية تتبُّع واجه فيها المستخدم إيقافًا مؤقتًا لعرض واجهة المستخدم أثناء التنقّل إلى الشاشة الرئيسية على هاتف Pixel بعد التقاط صورة مباشرةً في تطبيق "الكاميرا". في ما يلي لقطة شاشة من Perfetto تعرض الأحداث التي أدّت إلى فقدان الإطار:
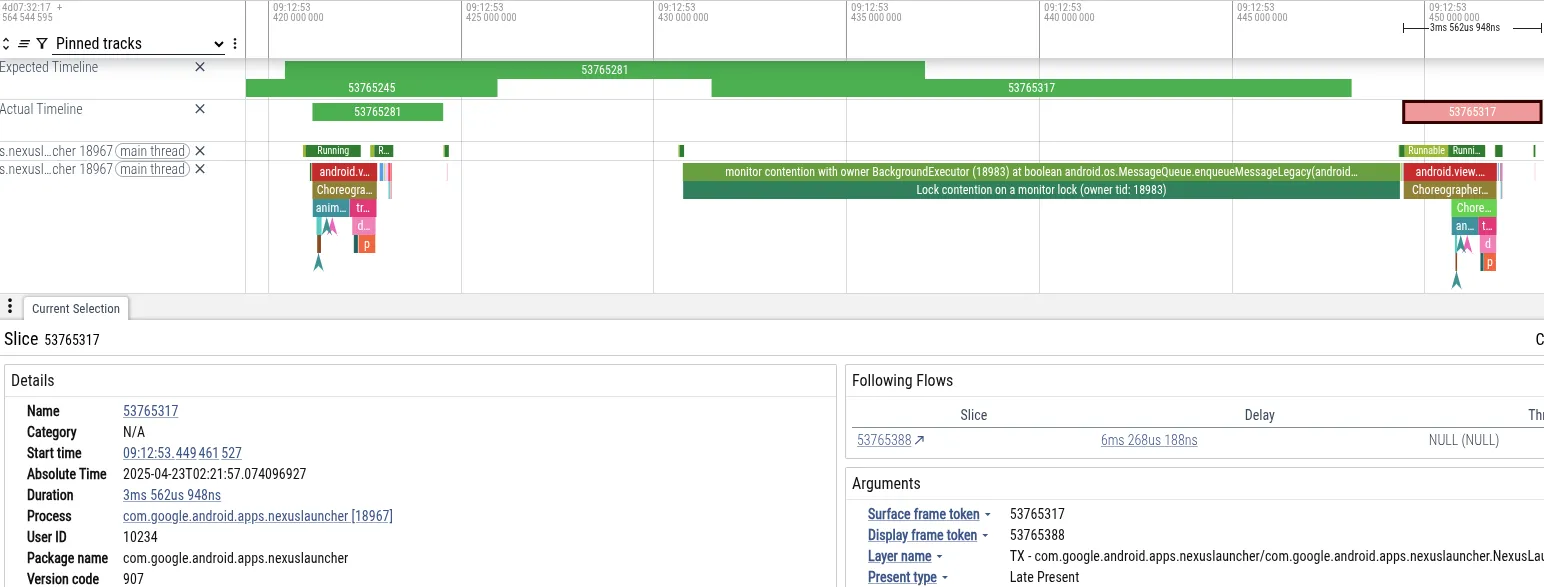
- العَرَض: تجاوز مؤشر ترابط Launcher الرئيسي الموعد النهائي لعرض اللقطة. تم حظرها لمدة 18 ملي ثانية، ما يتجاوز المهلة النهائية البالغة 16 ملي ثانية المطلوبة للعرض بمعدل 60 لقطة في الثانية.
- التشخيص: أظهرت أداة Perfetto أنّ سلسلة المحادثات الرئيسية محظورة على قفل
MessageQueue. كانت سلسلة محادثات باسم BackgroundExecutor تمتلك القفل. - السبب الأساسي: يتم تشغيل BackgroundExecutor على Process.THREAD_PRIORITY_BACKGROUND (أولوية منخفضة جدًا). نفّذ مهمة غير عاجلة (التحقّق من المدد القصوى لاستخدام التطبيقات). في الوقت نفسه، كانت سلاسل العمل ذات الأولوية المتوسطة تستخدم وقت وحدة المعالجة المركزية لمعالجة البيانات من الكاميرا. أوقف برنامج جدولة نظام التشغيل مؤقتًا سلسلة BackgroundExecutor لتشغيل سلاسل الكاميرا.
تسبّب هذا التسلسل في حظر سلسلة واجهة المستخدم في Launcher (ذات الأولوية العالية) بشكل غير مباشر من خلال سلسلة الوحدات العاملة (worker thread) للكاميرا (ذات الأولوية المتوسطة)، ما منع سلسلة الخلفية في Launcher (ذات الأولوية المنخفضة) من تحرير القفل.
الاستعلام عن عمليات التتبُّع باستخدام PerfettoSQL
يمكنك استخدام PerfettoSQL للاستعلام عن بيانات التتبُّع بحثًا عن أنماط معيّنة. يكون هذا الإجراء مفيدًا إذا كان لديك مجموعة كبيرة من عمليات التتبُّع من أجهزة المستخدمين أو الاختبارات، وكنت تبحث عن عمليات تتبُّع معيّنة توضّح مشكلة.
على سبيل المثال، يعثر طلب البحث هذا على MessageQueue التنازع المتزامن مع اللقطات التي تم إسقاطها (التقطيع):
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
في هذا المثال الأكثر تعقيدًا، ادمج بيانات التتبُّع التي تتضمّن جداول متعدّدة لتحديد MessageQueue التنازع أثناء بدء تشغيل التطبيق:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
يمكنك استخدام "النموذج اللغوي الكبير" المفضّل لديك لكتابة طلبات بحث PerfettoSQL للعثور على أنماط أخرى.
في Google، نستخدم BigTrace لتنفيذ طلبات بحث PerfettoSQL على ملايين عمليات التتبُّع. ومن خلال ذلك، تأكّدنا من أنّ ما لاحظناه بشكل غير رسمي كان في الواقع مشكلة منهجية. كشفت البيانات أنّ MessageQueue تؤثّر في المستخدمين في جميع أنحاء النظام المتكامل، ما يؤكّد الحاجة إلى تغيير أساسي في البنية.
الحلّ: التزامن بدون قفل
لقد عالجنا مشكلة MessageQueue التنازع من خلال تنفيذ بنية بيانات غير قابلة للقفل، وذلك باستخدام عمليات ذاكرة ذرية بدلاً من عمليات قفل حصرية لمزامنة الوصول إلى الحالة المشتركة. تكون بنية البيانات أو الخوارزمية غير قابلة للإغلاق إذا كان بإمكان مؤشر ترابط واحد على الأقل إحراز تقدّم دائمًا بغض النظر عن سلوك الجدولة لمؤشرات الترابط الأخرى. من الصعب عادةً تحقيق هذه السمة، ولا يُنصح عادةً بمحاولة تحقيقها لمعظم الرموز البرمجية.
الأنواع الأولية الذرية
تعتمد البرامج غير المتزامنة غالبًا على عناصر Read-Modify-Write الأساسية التي توفّرها الأجهزة.
في وحدات المعالجة المركزية ARM64 القديمة، كانت العمليات الذرية تستخدم حلقة Load-Link/Store-Conditional (LL/SC). تحمّل وحدة المعالجة المركزية قيمة وتضع علامة على العنوان. إذا كتب مؤشر ترابط آخر إلى هذا العنوان، سيتعذّر الوصول إلى المتجر، وستتم إعادة محاولة تنفيذ الحلقة. وبما أنّ سلاسل التعليمات يمكنها مواصلة المحاولة والنجاح بدون انتظار سلسلة تعليمات أخرى، فإنّ هذه العملية لا تتطلّب قفلًا.
ARM64 LL/SC loop example
retry:
ldxr x0, [x1] // Load exclusive from address x1 to x0
add x0, x0, #1 // Increment value by 1
stxr w2, x0, [x1] // Store exclusive.
// w2 gets 0 on success, 1 on failure
cbnz w2, retry // If w2 is non-zero (failed), branch to retrتتيح بنى ARM الأحدث (ARMv8.1) إضافات النظام الكبيرة (LSE) التي تتضمّن تعليمات على شكل Compare-And-Swap (CAS) أو Load-And-Add (كما هو موضّح أدناه). في Android 17، أضفنا إمكانية إلى برنامج التحويل البرمجي في "وقت تشغيل Android" (ART) لرصد ما إذا كان LSE متاحًا وإصدار تعليمات محسّنة:
/ ARMv8.1 LSE atomic example
ldadd x0, x1, [x2] // Atomic load-add.
// Faster, no loop required.في مقاييس الأداء، تحقّق التعليمات البرمجية التي تتضمّن معدّل تزاحم مرتفعًا وتستخدم CAS زيادة في السرعة بمقدار 3 أضعاف تقريبًا مقارنةً بالتعليمات البرمجية التي تستخدم LL/SC.
توفّر لغة برمجة Java عناصر أولية ذرية من خلال java.util.concurrent.atomic التي تعتمد على هذه التعليمات وغيرها من تعليمات وحدة المعالجة المركزية المتخصصة.
بنية البيانات: DeliQueue
لإزالة تعارض القفل من MessageQueue، صمّم مهندسونا بنية بيانات جديدة تُعرف باسم DeliQueue. يفصل DeliQueue Message الإدراج عن Message المعالجة:
- قائمة
Messages(حزمة Treiber): هي حزمة لا تتطلّب قفل. يمكن لأي سلسلة محادثات إرسالMessagesجديدة هنا بدون تعارض. - قائمة الانتظار حسب الأولوية (Min-heap): مجموعة من
Messagesيتم التعامل معها، وهي مملوكة حصريًا لسلسلة Looper (وبالتالي لا يلزم إجراء أي مزامنة أو استخدام أي أقفال للوصول إليها).
إضافة إلى قائمة الانتظار: الدفع إلى حزمة Treiber
يتم الاحتفاظ بقائمة Messages في حزمة Treiber [1]، وهي حزمة غير قابلة للقفل تستخدم حلقة CAS لتعديل مؤشر العنوان.
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}رمز المصدر المستند إلى Java Concurrency in Practice [2]، المتاح على الإنترنت والذي تم إصداره إلى النطاق العام
يمكن لأي منتج إضافة Message جديدة إلى الحزمة في أي وقت. يشبه ذلك الحصول على تذكرة في محل لبيع الأطعمة الجاهزة، حيث يتم تحديد رقمك حسب وقت وصولك، ولكن لا يجب أن يتطابق ترتيب حصولك على الطعام مع رقمك. بما أنّها حزمة مرتبطة، فإنّ كل Message هي حزمة فرعية، ويمكنك الاطّلاع على شكل قائمة انتظار Message في أي وقت من خلال تتبُّع الرأس والتكرار للأمام، ولن ترى أي Message جديدة يتم دفعها في الأعلى، حتى إذا تمت إضافتها أثناء عملية الانتقال.
إزالة من قائمة الانتظار: نقل مجمّع إلى كومة الحد الأدنى
للعثور على Message التالي المطلوب معالجته، يعالج Looper Messages جديدة من حزمة Treiber من خلال الانتقال إلى الحزمة بدءًا من الأعلى والتكرار إلى أن يعثر على آخر Message تمت معالجته سابقًا. أثناء اجتياز Looper للمكدّس، يتم إدراج Message في الحد الأدنى من الكومة المرتبة حسب الموعد النهائي. بما أنّ Looper يملك الكومة حصريًا، فهو يرتب ويعالج Message بدون أقفال أو عمليات ذرية.

عند النزول إلى أسفل الحزمة، ينشئ Looper أيضًا روابط من Message المكدّسة إلى العناصر السابقة، وبالتالي يتم تكوين قائمة مرتبطة بشكل مضاعف. إنشاء القائمة المرتبطة آمن لأنّه تتم إضافة الروابط التي تشير إلى أسفل حزمة البيانات باستخدام خوارزمية حزمة بيانات Treiber مع CAS، ولا تتم قراءة الروابط التي تشير إلى أعلى حزمة البيانات وتعديلها إلا من خلال سلسلة المحادثات Looper. بعد ذلك، يتم استخدام هذه الروابط الخلفية لإزالة Message من نقاط عشوائية في الحزمة في وقت O(1).
يتيح هذا التصميم إمكانية إدراج O(1) للمنتجين (سلاسل المحادثات التي تنشر العمل في قائمة الانتظار) ومعالجة O(log N) مستهلكة (Looper).
يؤدي استخدام الحد الأدنى من الكومة الثنائية لترتيب Message أيضًا إلى معالجة عيب أساسي في MessageQueue القديم، حيث كانت Message تُحفظ في قائمة مرتبطة بشكل فردي (مُحدَّدة في الأعلى). في عملية التنفيذ القديمة، كانت الإزالة من الرأس O(1)، ولكن كان للإدراج أسوأ حالة O(N)، ما يؤدي إلى توسيع نطاق سيئ للصفوف المحمّلة بشكل زائد. في المقابل، يتم إدراج البيانات في min-heap وإزالتها منها بشكل لوغاريتمي، ما يؤدي إلى تحقيق أداء تنافسي في المتوسط، ولكنّه يتفوّق حقًا في حالات الكمون المتأخر.
الإصدار القديم (مغلق) MessageQueue | DeliQueue | |
| إدراج | O(N) | O(1) لسلسلة المحادثات الخاصة بالمكالمات O(logN) لسلسلة محادثات |
| إزالة من الرأس | O(1) | O(logN) |
في عملية تنفيذ قائمة الانتظار القديمة، استخدم المنتجون والمستهلك قفلًا لتنسيق الوصول الحصري إلى القائمة المرتبطة بشكل فردي الأساسية. في DeliQueue، يتعامل حزمة Treiber مع الوصول المتزامن، ويتعامل المستهلك الفردي مع ترتيب قائمة انتظار العمل.
الإزالة: الاتساق من خلال علامات الحذف
DeliQueue هي بنية بيانات مختلطة، تجمع بين حزمة Treiber غير القابلة للتأمين وmin-heap ذات مؤشر ترابط واحد. إنّ الحفاظ على مزامنة هذين البنيتين بدون قفل عام يمثّل تحديًا فريدًا، فقد تكون الرسالة متوفّرة فعليًا في الحزمة ولكن تمت إزالتها منطقيًا من قائمة الانتظار.
لحلّ هذه المشكلة، تستخدم DeliQueue أسلوبًا يُعرف باسم "tombstoning". يتتبّع كل Message موضعه في الحزمة من خلال مؤشرات الرجوع والتقدّم، وفهرسه في مصفوفة الكومة، وعلامة منطقية تشير إلى ما إذا تمت إزالته. عندما يكون Message جاهزًا للتنفيذ، سيقوم مؤشر ترابط Looper بتنفيذ عملية CAS على علامة الإزالة، ثم إزالتها من الكومة والمكدس.
عندما يحتاج إجراء آخر إلى إزالة Message، لا يستخرجه على الفور من بنية البيانات. بدلاً من ذلك، سيحدث ما يلي:
- الإزالة المنطقية: يستخدم مؤشر الترابط CAS لضبط علامة الإزالة الخاصة بـ
Messageبشكل ذري من "خطأ" إلى "صحيح". يظلMessageفي بنية البيانات كدليل على إزالته المعلقة، ويُعرف باسم "حجر القبر". وبمجرد وضع علامة علىMessageلإزالته، يتعامل معه DeliQueue كما لو أنّه لم يعُد موجودًا في قائمة الانتظار كلما تم العثور عليه. - التنظيف المؤجّل: إنّ عملية الإزالة الفعلية من بنية البيانات هي من مسؤولية سلسلة المحادثات
Looper، ويتم تأجيلها إلى وقت لاحق. بدلاً من تعديل الحزمة أو الكومة، يضيف مؤشر الإزالةMessageإلى حزمة أخرى من قوائم التحرير المجانية غير المقفلة. - الإزالة البنيوية: يمكن
Looperفقط التفاعل مع الذاكرة المؤقتة أو إزالة العناصر من الحزمة. وعندما يتم تنشيطه، يمحو قائمة العناصر الحرة ويعالجMessageالتي كانت تحتوي عليها. بعد ذلك، يتم إلغاء ربط كلMessageبالحزمة وإزالته من الذاكرة المؤقتة.
تتيح هذه الطريقة إدارة جميع عمليات التجميع في سلسلة محادثات واحدة. ويقلّل من عدد العمليات المتزامنة وحواجز الذاكرة المطلوبة، ما يجعل المسار الحرج أسرع وأبسط.
التنقّل: أخطاء بسيطة في نموذج ذاكرة Java
تتضمّن معظم واجهات برمجة التطبيقات المتزامنة، مثل Future في مكتبة Java العادية أو Job وDeferred في Kotlin، آلية لإلغاء العمل قبل اكتماله. يتطابق مثيل أحد هذه الصفوف مع وحدة عمل أساسية بنسبة 1:1، ويؤدي استدعاء cancel على عنصر إلى إلغاء العمليات المحدّدة المرتبطة به.
تتضمّن أجهزة Android الحالية وحدات معالجة مركزية متعددة النواة وعملية جمع البيانات المُهمَلة حسب الأجيال بشكل متزامن. ولكن عندما تم تطوير Android لأول مرة، كان من المكلف جدًا تخصيص عنصر واحد لكل وحدة عمل. نتيجةً لذلك، يتيح نظام التشغيل Android Handler إمكانية الإلغاء من خلال العديد من عمليات التحميل الزائد removeMessages، فبدلاً من إزالة Message معيّن، تتم إزالة جميع Message التي تتطابق مع المعايير المحدّدة. من الناحية العملية، يتطلّب ذلك تكرار جميع Message التي تم إدراجها قبل استدعاء removeMessages وإزالة العناصر المطابقة.
عند التكرار للأمام، لا يتطلّب أحد مؤشرات الترابط سوى عملية ذرية واحدة منظَّمة لقراءة رأس المكدّس الحالي. بعد ذلك، يتم استخدام عمليات قراءة الحقول العادية للعثور على Message التالي. إذا عدّل سلسلة Looper حقول next أثناء إزالة Message، ستكون عملية الكتابة في Looper وعملية القراءة في سلسلة أخرى غير متزامنتَين، وهذا ما يُعرف باسم تضارب البيانات. عادةً، يكون تعارض البيانات خطأً فادحًا يمكن أن يتسبّب في حدوث مشاكل كبيرة في تطبيقك، مثل تسريب البيانات والحلقات اللانهائية والأعطال والتجميد وغير ذلك. ومع ذلك، في ظل شروط ضيقة معيّنة، يمكن أن تكون تعارضات البيانات غير ضارة ضمن نموذج ذاكرة Java. لنفترض أنّنا نبدأ بمجموعة من:

ننفّذ عملية قراءة ذرية للرأس، ونرى A. يشير مؤشر A التالي إلى B. في الوقت نفسه الذي تتم فيه معالجة الرسالة B، قد يزيل برنامج Looper الرسالتين B وC من خلال تعديل الرسالة A لتشير إلى الرسالة C ثم إلى الرسالة D.
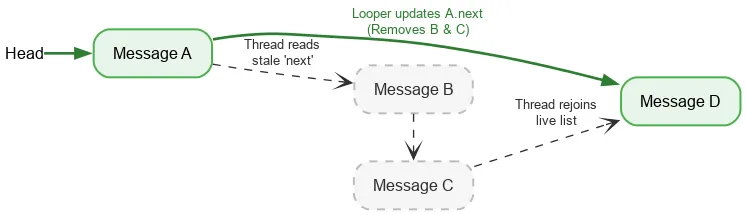
على الرغم من إزالة B وC منطقيًا، يحتفظ B بمؤشره التالي إلى C، وC إلى D. يستمرّ مسار القراءة في التنقّل عبر العُقد التي تمت إزالتها وفصلها، ثم يعود في النهاية إلى الحزمة النشطة في D.
من خلال تصميم DeliQueue للتعامل مع حالات التنافس بين اجتياز العناصر وإزالتها، يمكننا إجراء تكرار آمن بدون الحاجة إلى قفل.
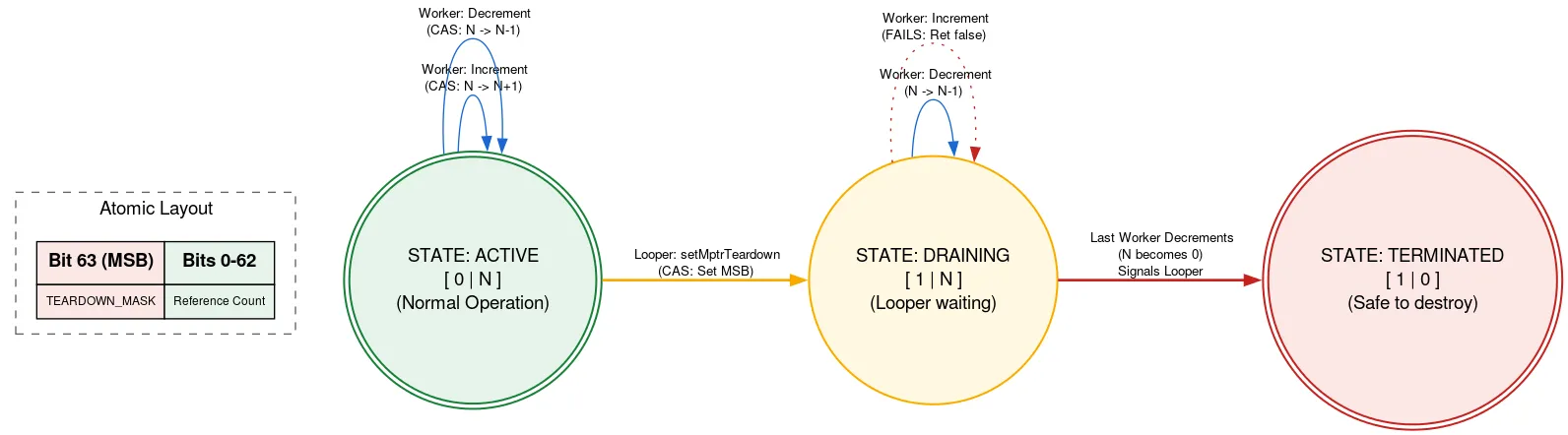
الخروج: Native refcount
يتم الاحتفاظ بنسخة احتياطية من Looper في عملية تخصيص أصلية يجب تحريرها يدويًا بعد إغلاق Looper. إذا كان هناك سلسلة محادثات أخرى تضيف Message أثناء إنهاء Looper، يمكن أن تستخدم التخصيص الأصلي بعد تحريره، ما يؤدي إلى انتهاك أمان الذاكرة. نمنع حدوث ذلك باستخدام tagged refcount، حيث يتم استخدام جزء واحد من الذرة للإشارة إلى ما إذا كان Looper سيتم إيقافه.
قبل استخدام التخصيص الأصلي، يقرأ أحد مؤشرات الترابط refcount atomic. إذا تم ضبط بت الإيقاف، سيتم عرض رسالة تفيد بأنّ Looper سيتم إيقافه ويجب عدم استخدام عملية التخصيص الأصلية. إذا لم يكن الأمر كذلك، تحاول CAS زيادة عدد سلاسل المحادثات النشطة باستخدام التخصيص الأصلي. وبعد تنفيذ ما يجب تنفيذه، يتم إنقاص العدد. إذا تم ضبط بت الإيقاف بعد الزيادة ولكن قبل الإنقاص، وأصبح العدد الآن صفرًا، سيتم تنبيه سلسلة المحادثات Looper.
عندما يكون مؤشر ترابط Looper جاهزًا للخروج، يستخدم CAS لضبط بت الخروج في الذرة. إذا كان عدد المراجع 0، يمكنه المتابعة لتحرير التخصيص الأصلي. بخلاف ذلك، يتم إيقافها مؤقتًا، مع العلم أنّه سيتم تنشيطها عندما يخفّض آخر مستخدم للتخصيص الأصلي عدد المراجع. يعني هذا الأسلوب أنّ سلسلة التعليمات Looper تنتظر تقدّم سلاسل التعليمات الأخرى، ولكن فقط عند إيقافها. يحدث ذلك مرة واحدة فقط ولا يتأثر بالأداء، ويحافظ على الرمز الآخر لاستخدام التخصيص الأصلي بدون أي قفل.
هناك الكثير من الحيل والتعقيدات الأخرى في التنفيذ. يمكنك الاطّلاع على مزيد من المعلومات حول DeliQueue من خلال مراجعة رمز المصدر.
التحسين: البرمجة بدون فروع
أثناء تطوير DeliQueue واختبارها، أجرى الفريق العديد من مقاييس الأداء ووضعوا بعناية ملفات تعريف للتعليمات البرمجية الجديدة. إحدى المشاكل التي تم رصدها باستخدام أداة simpleperf هي عمليات إفراغ ذاكرة التخزين المؤقت لخطوط الأنابيب التي تسبّب فيها رمز أداة المقارنة Message.
يستخدم برنامج المقارنة العادي عمليات الانتقال الشرطية، مع تبسيط الشرط الخاص بتحديد Message الذي يأتي أولاً على النحو التالي:
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
if (m1 == m2) {
return 0;
}
// Primary queue order is by when.
// Messages with an earlier when should come first in the queue.
final long whenDiff = m1.when - m2.when;
if (whenDiff > 0) return 1;
if (whenDiff < 0) return -1;
// Secondary queue order is by insert sequence.
// If two messages were inserted with the same `when`, the one inserted
// first should come first in the queue.
final long insertSeqDiff = m1.insertSeq - m2.insertSeq;
if (insertSeqDiff > 0) return 1;
if (insertSeqDiff < 0) return -1;
return 0;
}يتم تجميع هذا الرمز في عمليات انتقال شرطية (التعليمات b.le وcbnz). عندما تواجه وحدة المعالجة المركزية فرعًا شرطيًا، لا يمكنها معرفة ما إذا كان سيتم تنفيذ الفرع إلى أن يتم حساب الشرط، وبالتالي لا تعرف التعليمات التي يجب قراءتها بعد ذلك، وعليها التخمين باستخدام تقنية تُعرف باسم توقّع الفروع. في حالة مثل البحث الثنائي، سيكون اتجاه الفرع مختلفًا بشكل غير متوقّع في كل خطوة، لذا من المحتمل أن تكون نصف التوقعات خاطئة. غالبًا ما تكون عملية توقّع الفروع غير فعّالة في خوارزميات البحث والترتيب (مثل تلك المستخدَمة في الحد الأدنى من الكومة)، لأنّ تكلفة التخمين الخاطئ أكبر من التحسّن الناتج عن التخمين الصحيح. عندما يخمن برنامج توقّع الفروع بشكل خاطئ، يجب أن يتجاهل العمل الذي قام به بعد افتراض القيمة المتوقّعة، وأن يبدأ من جديد من المسار الذي تم اتخاذه فعليًا، ويُعرف ذلك باسم إفراغ خط الأنابيب.
للعثور على هذه المشكلة، حلّلنا مقاييس الأداء باستخدام عدّاد الأداء branch-misses، الذي يسجّل عمليات تتبُّع تسلسل استدعاء الدوال البرمجية التي تخطئ فيها أداة توقّع الفروع. بعد ذلك، عرضنا النتائج باستخدام Google pprof، كما هو موضّح أدناه:
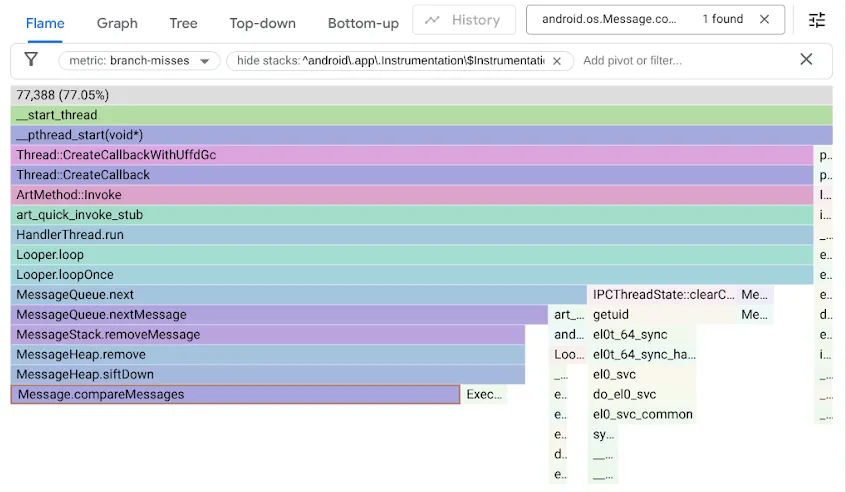
تذكَّر أنّ رمز MessageQueue الأصلي كان يستخدم قائمة مرتبطة بشكل فردي للانتظار المرتّب. سيؤدي الإدراج إلى اجتياز القائمة بترتيب مرتّب كبحث خطي، والتوقّف عند العنصر الأول الذي يتجاوز نقطة الإدراج وربط Message الجديد قبله. ولإزالة الرأس، كان عليك ببساطة إلغاء ربطها. في المقابل، تستخدم DeliQueue الحد الأدنى من الكومة، حيث تتطلّب عمليات التغيير إعادة ترتيب بعض العناصر (الترشيح للأعلى أو للأسفل) مع تعقيد لوغاريتمي في بنية بيانات متوازنة، حيث يكون لأي مقارنة فرصة متساوية لتوجيه الاجتياز إلى عنصر فرعي أيسر أو إلى عنصر فرعي أيمن. الخوارزمية الجديدة أسرع بشكل مقارب، ولكنّها تكشف عن عنق زجاجة جديد لأنّ رمز البحث يتوقف بسبب عدم العثور على الفروع نصف الوقت.
بعد أن لاحظنا أنّ عدم توفّر الفروع كان يؤدي إلى إبطاء رمز الذاكرة المكدّسة، عملنا على تحسين الرمز باستخدام البرمجة بدون فروع:
// Branchless Logic
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
final long when1 = m1.when;
final long when2 = m2.when;
final long insertSeq1 = m1.insertSeq;
final long insertSeq2 = m2.insertSeq;
// signum returns the sign (-1, 0, 1) of the argument,
// and is implemented as pure arithmetic:
// ((num >> 63) | (-num >>> 63))
final int whenSign = Long.signum(when1 - when2);
final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2);
// whenSign takes precedence over insertSeqSign,
// so the formula below is such that insertSeqSign only matters
// as a tie-breaker if whenSign is 0.
return whenSign * 2 + insertSeqSign;
}لفهم عملية التحسين، فكِّك المثالَين في Compiler Explorer واستخدِم LLVM-MCA، وهو محاكي لوحدة المعالجة المركزية يمكنه إنشاء مخطط زمني تقديري لدورات وحدة المعالجة المركزية.
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
لاحظ الفرع الشرطي الوحيد، b.le، الذي يتجنّب مقارنة الحقلَين insertSeq إذا كانت النتيجة معروفة مسبقًا من خلال مقارنة الحقلَين when.
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
في هذه الحالة، يستغرق التنفيذ بدون فروع عددًا أقل من الدورات والتعليمات مقارنةً بأقصر مسار في الرمز البرمجي الذي يتضمّن فروعًا، ما يجعله أفضل في جميع الحالات. وقد أدّى التنفيذ الأسرع بالإضافة إلى إلغاء الفروع التي تم توقّعها بشكل خاطئ إلى تحسين بعض مقاييس الأداء لدينا بمقدار 5 أضعاف.
ومع ذلك، لا يمكن تطبيق هذه التقنية دائمًا. تتطلّب الطرق غير المتفرّعة بشكل عام تنفيذ عمل سيتم تجاهله، وإذا كان الفرع قابلاً للتوقّع في معظم الأوقات، يمكن أن يؤدي هذا العمل الضائع إلى إبطاء الرمز البرمجي. بالإضافة إلى ذلك، يؤدي حذف فرع غالبًا إلى حدوث اعتماد على البيانات. تنفّذ وحدات المعالجة المركزية الحديثة عمليات متعددة في كل دورة، ولكن لا يمكنها تنفيذ تعليمات إلا بعد أن تصبح مدخلاتها من التعليمات السابقة جاهزة. في المقابل، يمكن لوحدة المعالجة المركزية التخمين بشأن البيانات في الفروع، والعمل مسبقًا إذا تم توقّع أحد الفروع بشكل صحيح.
الاختبار والتحقّق من الصحة
من الصعب جدًا التحقّق من صحة الخوارزميات غير المتزامنة.
بالإضافة إلى اختبارات الوحدات القياسية للتحقّق المستمر من الصحة أثناء التطوير، كتبنا أيضًا اختبارات إجهاد صارمة للتحقّق من ثبات قوائم الانتظار ومحاولة إحداث تضارب في البيانات إذا كانت موجودة. في مختبرات الاختبار، يمكننا تشغيل ملايين من حالات الاختبار على الأجهزة المحاكية وعلى الأجهزة الحقيقية.
باستخدام أداة Java ThreadSanitizer (JTSan)، يمكننا استخدام الاختبارات نفسها لرصد بعض حالات تضارب البيانات في الرمز البرمجي أيضًا. لم يعثر JTSan على أي مشاكل في تداخل البيانات في DeliQueue، ولكنّه رصد بشكل مفاجئ خطأين متزامنين في إطار عمل Robolectric، وقد أصلحناهما على الفور.
لتحسين إمكانات تصحيح الأخطاء، أنشأنا أدوات تحليل جديدة. في ما يلي مثال يوضّح مشكلة في رمز منصة Android حيث يؤدي أحد سلاسل التنفيذ إلى إرهاق سلسلة تنفيذ أخرى باستخدام Message، ما يؤدي إلى تراكم كبير في المهام، وهو ما يمكن رصده في Perfetto بفضل ميزة MessageQueue التي أضفناها.
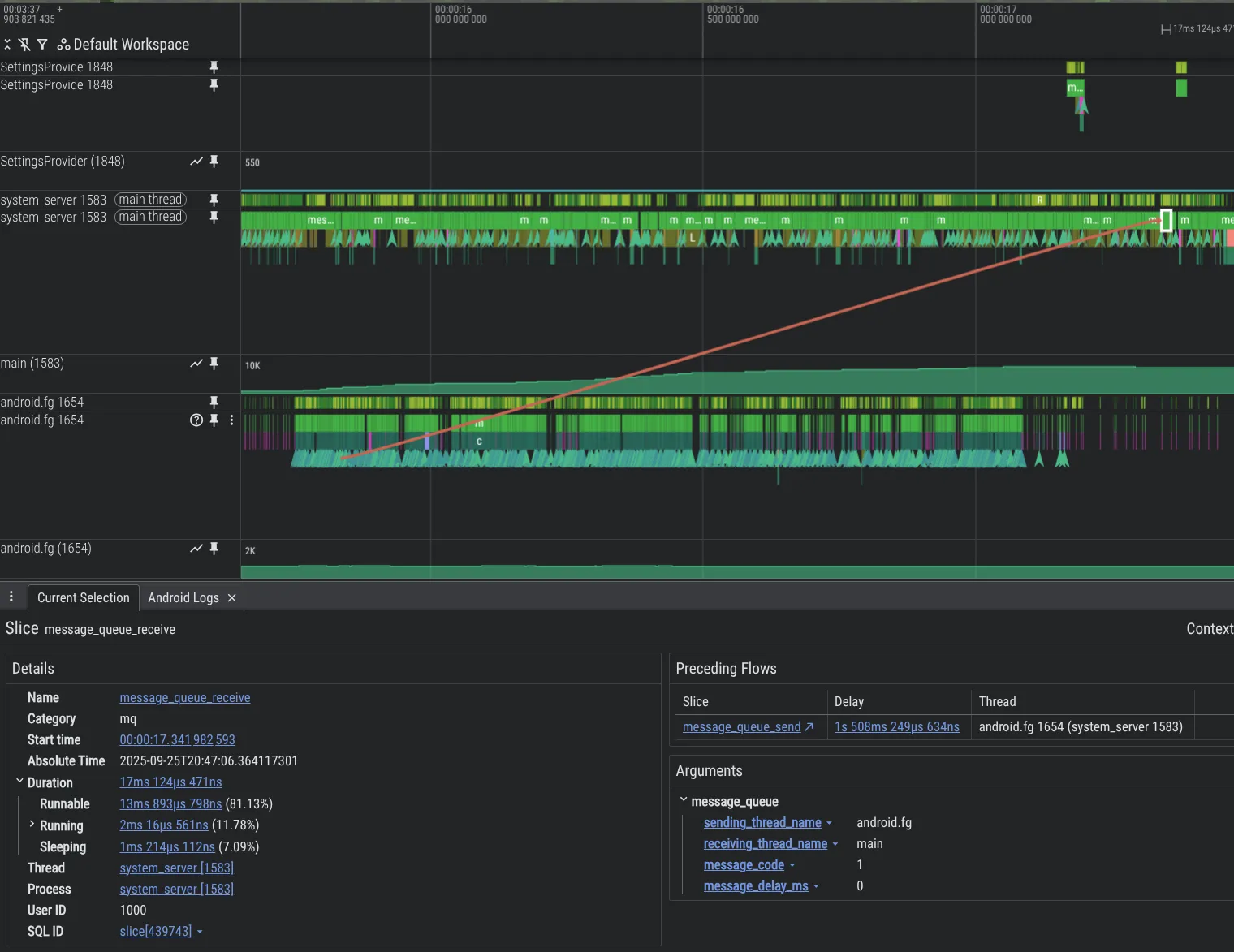
لتفعيل MessageQueue تتبُّع الأخطاء في عملية system_server، أدرِج ما يلي في إعدادات Perfetto:
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}التأثير
يحسّن DeliQueue أداء النظام والتطبيقات من خلال إزالة عمليات القفل من MessageQueue.
- مقاييس الأداء الاصطناعية: عمليات الإدراج المتعددة الخيوط في قوائم الانتظار المشغولة أسرع بما يصل إلى 5,000 مرة من
MessageQueueالقديم، وذلك بفضل التزامن المحسّن (مجموعة Treiber) وعمليات الإدراج الأسرع (min-heap). - في عمليات تتبُّع Perfetto التي تم الحصول عليها من مختبِري الإصدار التجريبي الداخليين، نلاحظ انخفاضًا بنسبة% 15 في الوقت الذي يستغرقه مؤشر ترابط التطبيق الرئيسي في انتظار الحصول على القفل.
- على أجهزة الاختبار نفسها، يؤدي تقليل تعارض الأقفال إلى تحسينات كبيرة في تجربة المستخدم، مثل:
- -4% من اللقطات الفائتة في التطبيقات
- -7.7% من اللقطات التي لم يتم عرضها في تفاعلات واجهة مستخدم النظام و"مشغّل التطبيقات"
- انخفاض بنسبة %9.1 في الوقت المستغرَق منذ بدء تشغيل التطبيق إلى عرض اللقطة الأولى، وذلك عند الشريحة المئوية الخامسة والتسعين.
الخطوات التالية
سيتم طرح DeliQueue في تطبيقات Android 17. على مطوّري التطبيقات مراجعة مقالة "إعداد تطبيقك للوضع الجديد MessageQueue غير المقفل" في مدوّنة "مطوّرو تطبيقات Android" لمعرفة كيفية اختبار تطبيقاتهم.
المراجع
[1] Treiber, R.K., 1986. برمجة الأنظمة: التعامل مع التوازي International Business Machines Incorporated, Thomas J. Watson Research Center
[2] Goetz, B., Peierls, T., Bloch, J., Bowbeer, J., Holmes, D., & Lea, D. (2006). Java Concurrency in Practice. Addison-Wesley Professional.
-

 أخبار المنتجات
أخبار المنتجاتنحن في Google Play ملتزمون بتقديم أفضل تجربة ممكنة للمستخدمين، مع ضمان توفير الأدوات والمرونة اللازمة للمطوّرين لتحقيق النجاح.
Paul Feng • يستغرق الاطّلاع على المقال 3 دقائق -

 أخبار المنتجات
أخبار المنتجاتفي العام الماضي، أطلقنا ميزة التحقّق من هوية مطوّر تطبيقات Android لتعزيز أمان المنظومة المتكاملة ومنع الجهات المسيئة من إخفاء هويتها لنشر تطبيقات ضارة.
Matthew Forsythe • مدّة القراءة: دقيقتان -


 أخبار المنتجات
أخبار المنتجاتبدءًا من التراكبات المعزّزة إلى البيئات الغامرة بالكامل، تتوسّع منظومة Android XR المتكاملة بسرعة، وتتوفّر سماعة الرأس Samsung Galaxy XR اليوم.
Stevan Silva, Vinny DaSilva • يستغرق الاطِّلاع على المقال 3 دقائق
يمكنك تلقّي أحدث الإحصاءات حول تطوير تطبيقات Android في بريدك الوارد أسبوعيًا.
