
שיפור פיתוח אפליקציות ל-Android בעזרת AI ושיפור מודלים גדולים של שפה (LLM) באמצעות Android Bench
משך קריאה: 2 דקות

אנחנו רוצים לעזור לכם ליצור אפליקציות ל-Android באיכות גבוהה בצורה מהירה וקלה יותר, ואחת הדרכים שבהן אנחנו עוזרים לכם לשפר את הפרודוקטיביות היא באמצעות AI. אנחנו יודעים שאתם רוצים AI שמבין באמת את הניואנסים של פלטפורמת Android, ולכן אנחנו בודקים את הביצועים של מודלים גדולים של שפה (LLM) במשימות פיתוח ל-Android. היום השקנו את הגרסה הראשונה של Android Bench, טבלת המובילים הרשמית שלנו של מודלים גדולים של שפה (LLM) לפיתוח ל-Android.
המטרה שלנו היא לספק ליוצרי מודלים נקודת השוואה להערכת היכולות של מודלים גדולים של שפה (LLM) לפיתוח אפליקציות ל-Android. אנחנו עוזרים ליוצרי מודלים לזהות פערים ולשפר את המודלים שלהם מהר יותר, על ידי יצירת בסיס ברור ואמין למה שנחשב לפיתוח איכותי של אפליקציות ל-Android. כך מפתחים יכולים לעבוד בצורה יעילה יותר עם מגוון רחב יותר של מודלים מועילים של AI, ובסופו של דבר ליצור אפליקציות באיכות גבוהה יותר בסביבת Android.
מיועד למשימות פיתוח אמיתיות ל-Android
יצרנו את המדד על ידי אוסף של משימות במגוון תחומים נפוצים בפיתוח ל-Android. הוא מורכב מאתגרים אמיתיים ברמות קושי שונות, שנלקחו ממאגרי GitHub ציבוריים של Android. התרחישים כוללים פתרון של שינויים שעלולים לשבור את התאימות בין גרסאות Android, משימות ספציפיות לדומיין כמו יצירת רשת במכשירים לבישים, ומעבר לגרסה העדכנית של Jetpack Compose.
בכל הערכה, מנסים לגרום למודל LLM לתקן את הבעיה שדווחה במשימה, ואז מאמתים את התיקון באמצעות בדיקות יחידה או בדיקות מכשור. הגישה הזו מתאימה לכל המודלים, והיא מאפשרת לנו למדוד את היכולת של המודל לנווט בבסיסי קוד מורכבים, להבין תלויות ולפתור את סוג הבעיות שאתם נתקלים בהן מדי יום.
אימתנו את המתודולוגיה הזו עם כמה יוצרי LLM, כולל JetBrains.
"מדידת ההשפעה של AI על Android היא אתגר עצום, ולכן נהדר לראות מסגרת שהיא כל כך הגיונית ומציאותית. אנחנו משתמשים באופן פעיל בהשוואה לשוק, אבל Android Bench הוא תוספת ייחודית ומבורכת. המתודולוגיה הזו היא בדיוק סוג ההערכה הקפדנית שמפתחי Android צריכים כרגע".
– קיריל סמילוב (Kirill Smelov), ראש תחום שילובי ה-AI ב-JetBrains.
התוצאות הראשונות של Android Bench
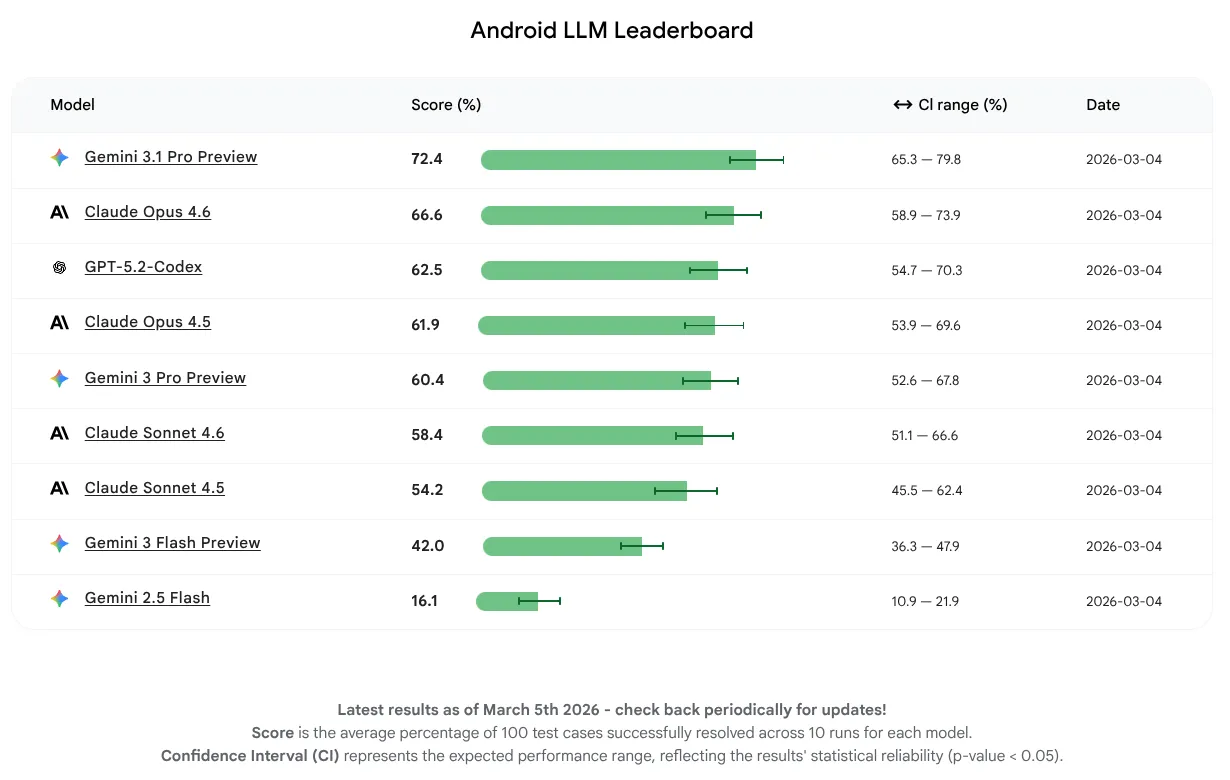
בגרסה הראשונית הזו, רצינו למדוד רק את ביצועי המודל ולא להתמקד בשימוש בסוכנים או בכלים. המודלים הצליחו להשלים 16-72% מהמשימות. זהו טווח רחב שמראה שלחלק מה-LLM כבר יש בסיס חזק של ידע ב-Android, בעוד שלחלקם יש מקום לשיפור. לא משנה מה מצב המודלים כרגע, אנחנו צופים שיפור מתמשך, כי אנחנו מעודדים את יוצרי ה-LLM לשפר את המודלים שלהם לפיתוח לאנדרואיד.
מודל ה-LLM עם הציון הממוצע הכי גבוה בגרסה הראשונה הזו הוא Gemini 3.1 Pro, ואחריו Claude Opus 4.6. אתם יכולים לנסות את כל המודלים שבדקנו כדי לקבל עזרה מ-AI בפרויקטים שלכם ב-Android באמצעות מפתחות API בגרסה היציבה האחרונה של Android Studio.
שקיפות למפתחים וליוצרי מודלים של LLM
אנחנו מעריכים גישה פתוחה ושקופה, ולכן פרסמנו ב-GitHub את המתודולוגיה, מערך הנתונים ומערכת הבדיקה שלנו.
אחד האתגרים בכל מדד השוואה ציבורי הוא הסיכון לזיהום נתונים, שבו יכול להיות שהמודלים ראו משימות הערכה במהלך תהליך האימון שלהם. נקטנו אמצעים כדי לוודא שהתוצאות שלנו משקפות חשיבה רציונלית אמיתית ולא שינון או ניחוש, כולל בדיקה ידנית יסודית של מסלולי הסוכן או שילוב של מחרוזת קנרית כדי למנוע אימון.
בעתיד, נמשיך לפתח את המתודולוגיה שלנו כדי לשמור על השלמות של מערך הנתונים, וגם נבצע שיפורים בגרסאות הבאות של המדד – למשל, נגדיל את כמות המשימות ואת המורכבות שלהן.
אנחנו מצפים לראות איך Android Bench יכול לשפר את העזרה מ-AI בטווח הארוך. החזון שלנו הוא לגשר על הפער בין קונספט לקוד איכותי. אנחנו מניחים את היסודות לעתיד שבו תוכלו לבנות כל דבר שרק תדמיינו ב-Android.
-
 חדשות על מוצרים
חדשות על מוצריםב-Google I/O 2026, נציג 17 הכרזות חשובות למפתחי Android, שמתמקדות בפרודוקטיביות מבוססת-סוכנים, ב-Compose First כסטנדרט ממשק המשתמש שלנו, ובפיתוח מדיה בעל ביצועים גבוהים ופיתוח אדפטיבי עבור המערכת האקולוגית המתרחבת.
Matthew McCullough • משך הקריאה: 8 דקות -
 חדשות על מוצרים
חדשות על מוצריםהיום, במהלך The Android Show, הכרזנו על המעבר של Android ממערכת הפעלה למערכת חכמה, שיוצרת יותר הזדמנויות לאינטראקציה עם האפליקציות שלכם.
Matthew McCullough • משך הקריאה: 4 דקות -
 חדשות על מוצרים
חדשות על מוצריםהיום אנחנו משפרים את פיתוח Android באמצעות Gemma 4, המודל המתקדם ביותר שלנו בקוד פתוח, שנועד לספק יכולות מורכבות של הסקת מסקנות וקריאה אוטונומית לכלים.
Matthew McCullough • משך הקריאה: 2 דקות
רוצים לקבל טיפים עדכניים לפיתוח Android ישירות לאימייל כל שבוע?
