
1. Before you begin
In this codelab, you'll learn how to use the LiveData builder to combine Kotlin coroutines with LiveData in an Android app. We'll also use Coroutines Asynchronous Flow, which is a type from the coroutines library for representing an async sequence (or stream) of values, to implement the same thing.
You'll start with an existing app, built using Android Architecture Components, that uses LiveData to get a list of objects from a Room database and display them in a RecyclerView grid layout.
Here are some code snippets to give you an idea of what you'll be doing. Here is the existing code to query the Room database:
val plants: LiveData<List<Plant>> = plantDao.getPlants()
The LiveData will be updated using the LiveData builder and coroutines with additional sorting logic:
val plants: LiveData<List<Plant>> = liveData<List<Plant>> {
val plantsLiveData = plantDao.getPlants()
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsLiveData.map { plantList -> plantList.applySort(customSortOrder) })
}
You'll also implement the same logic with Flow:
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
.flowOn(defaultDispatcher)
.conflate()
Prerequisites
- Experience with the Architecture Components
ViewModel,LiveData,Repository, andRoom. - Experience with Kotlin syntax, including extension functions and lambdas.
- Experience with Kotlin Coroutines.
- A basic understanding of using threads on Android, including the main thread, background threads, and callbacks.
What you'll do
- Convert an existing
LiveDatato use the Kotlin coroutines-friendlyLiveDatabuilder. - Add logic within a
LiveDatabuilder. - Use
Flowfor asynchronous operations. - Combine
Flowsand transform multiple asynchronous sources. - Control concurrency with
Flows. - Learn how to choose between
LiveDataandFlow.
What you'll need
- Android Studio Arctic Fox. The codelab may work with other versions, but some things might be missing or look different.
If you run into any issues (code bugs, grammatical errors, unclear wording, etc.) as you work through this codelab, please report the issue via the "Report a mistake" link in the lower left corner of the codelab.
2. Getting set up
Download the code
Click the following link to download all the code for this codelab:
... or clone the GitHub repository from the command line by using the following command:
$ git clone https://github.com/googlecodelabs/kotlin-coroutines.git
The code for this codelab is in the advanced-coroutines-codelab directory.
Frequently asked questions
3. Run the starting sample app
First, let's see what the starting sample app looks like. Follow these instructions to open the sample app in Android Studio.
- If you downloaded the
kotlin-coroutineszip file, unzip the file. - Open the
advanced-coroutines-codelabdirectory in Android Studio. - Make sure
startis selected in the configuration drop-down. - Click the Run
 button, and either choose an emulated device or connect your Android device. The device must be capable of running Android Lollipop (the minimum supported SDK is 21).
button, and either choose an emulated device or connect your Android device. The device must be capable of running Android Lollipop (the minimum supported SDK is 21).
When the app first runs, a list of cards appears, each displaying the name and image of a specific plant:

Each Plant has a growZoneNumber, an attribute that represents the region where the plant is most likely to thrive. Users can tap the filter icon 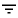 to toggle between showing all plants and plants for a specific grow zone, which is hardcoded to zone 9. Press the filter button a few times to see this in action.
to toggle between showing all plants and plants for a specific grow zone, which is hardcoded to zone 9. Press the filter button a few times to see this in action.

Architecture overview
This app uses Architecture Components to separate the UI code in MainActivity and PlantListFragment from the application logic in PlantListViewModel. PlantRepository provides a bridge between the ViewModel and PlantDao, which accesses the Room database to return a list of Plant objects. The UI then takes this list of plants and displays them in RecyclerView grid layout.
Before we start modifying the code, let's take a quick look at how the data flows from the database to the UI. Here is how the list of plants are loaded in the ViewModel:
PlantListViewModel.kt
val plants: LiveData<List<Plant>> = growZone.switchMap { growZone ->
if (growZone == NoGrowZone) {
plantRepository.plants
} else {
plantRepository.getPlantsWithGrowZone(growZone)
}
}
A GrowZone is an inline class that only contains an Int representing its zone. NoGrowZone represents the absence of a zone, and is only used for filtering.
Plant.kt
inline class GrowZone(val number: Int)
val NoGrowZone = GrowZone(-1)
The growZone is toggled when the filter button is tapped. We use a switchMap to determine the list of plants to return.
Here is what the repository and Data Access Object (DAO) look like for fetching the plant data from the database:
PlantDao.kt
@Query("SELECT * FROM plants ORDER BY name")
fun getPlants(): LiveData<List<Plant>>
@Query("SELECT * FROM plants WHERE growZoneNumber = :growZoneNumber ORDER BY name")
fun getPlantsWithGrowZoneNumber(growZoneNumber: Int): LiveData<List<Plant>>
PlantRepository.kt
val plants = plantDao.getPlants()
fun getPlantsWithGrowZone(growZone: GrowZone) =
plantDao.getPlantsWithGrowZoneNumber(growZone.number)
While most of the code modifications are in PlantListViewModel and PlantRepository, it's a good idea to take a moment to familiarize yourself with the structure of the project, focusing on how the plant data surfaces through the various layers from the database to the Fragment. In the next step, we'll modify the code to add custom sorting using the LiveData builder.
4. Plants with custom sorting
The list of plants are currently displayed in alphabetical order, but we want to change the order of this list by listing certain plants first, and then the rest in alphabetical order. This is similar to shopping apps displaying sponsored results at the top of a list of items available for purchase. Our product team wants the ability to change the sort order dynamically without shipping a new version of the app, so we'll fetch the list of plants to sort first from the backend.
Here's what the app will look like with custom sorting:
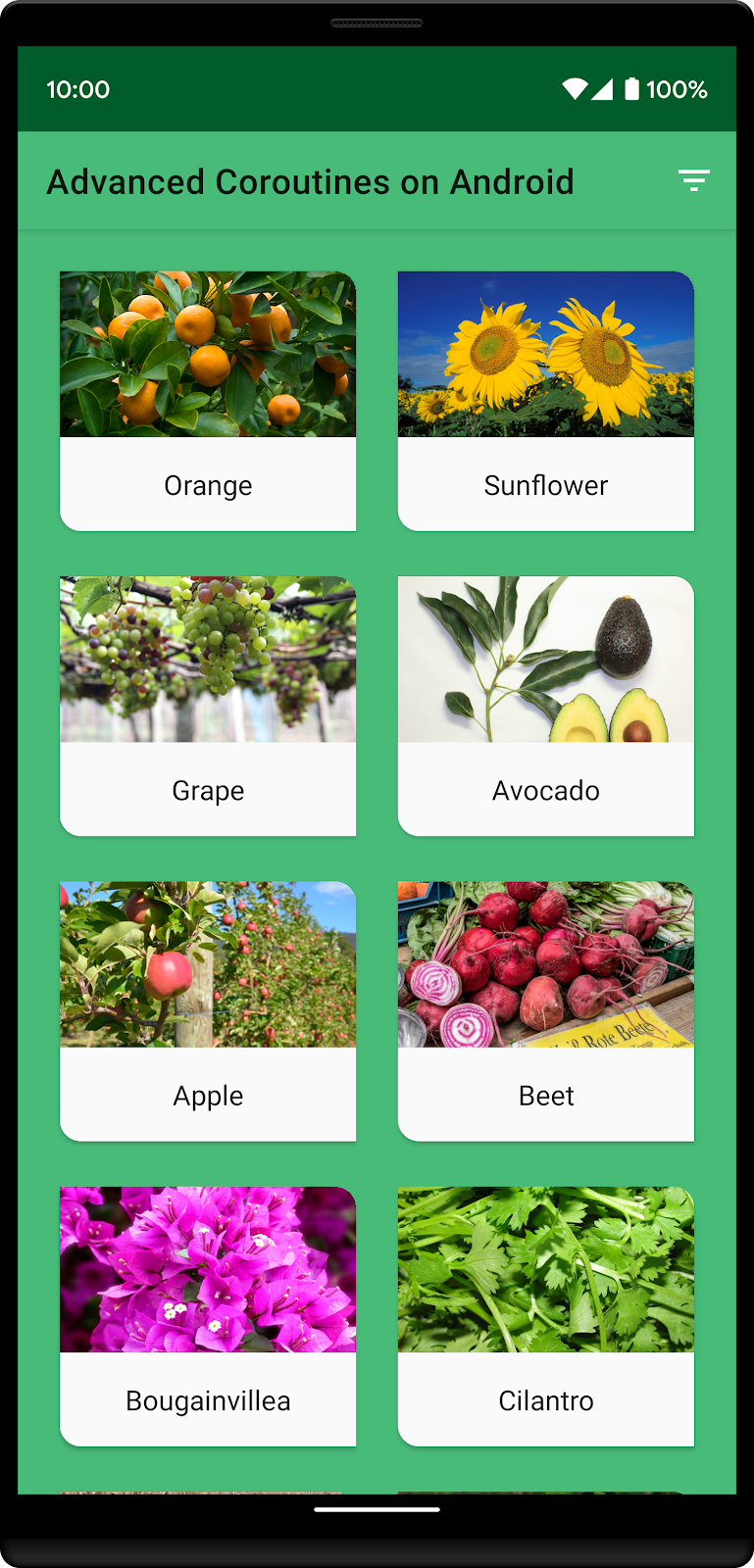
The custom sort order list consists of these four plants: Orange, Sunflower, Grape, and Avocado. Notice how they appear first in the list, then followed by the rest of the plants in alphabetical order.
Now if the filter button is pressed (and only GrowZone 9 plants are displayed), the Sunflower disappears from the list since its GrowZone is not 9. The other three plants in the custom sort list are in GrowZone 9, so they'll remain at the top of the list. The only other plant in GrowZone 9 is the Tomato, which appears last in this list.
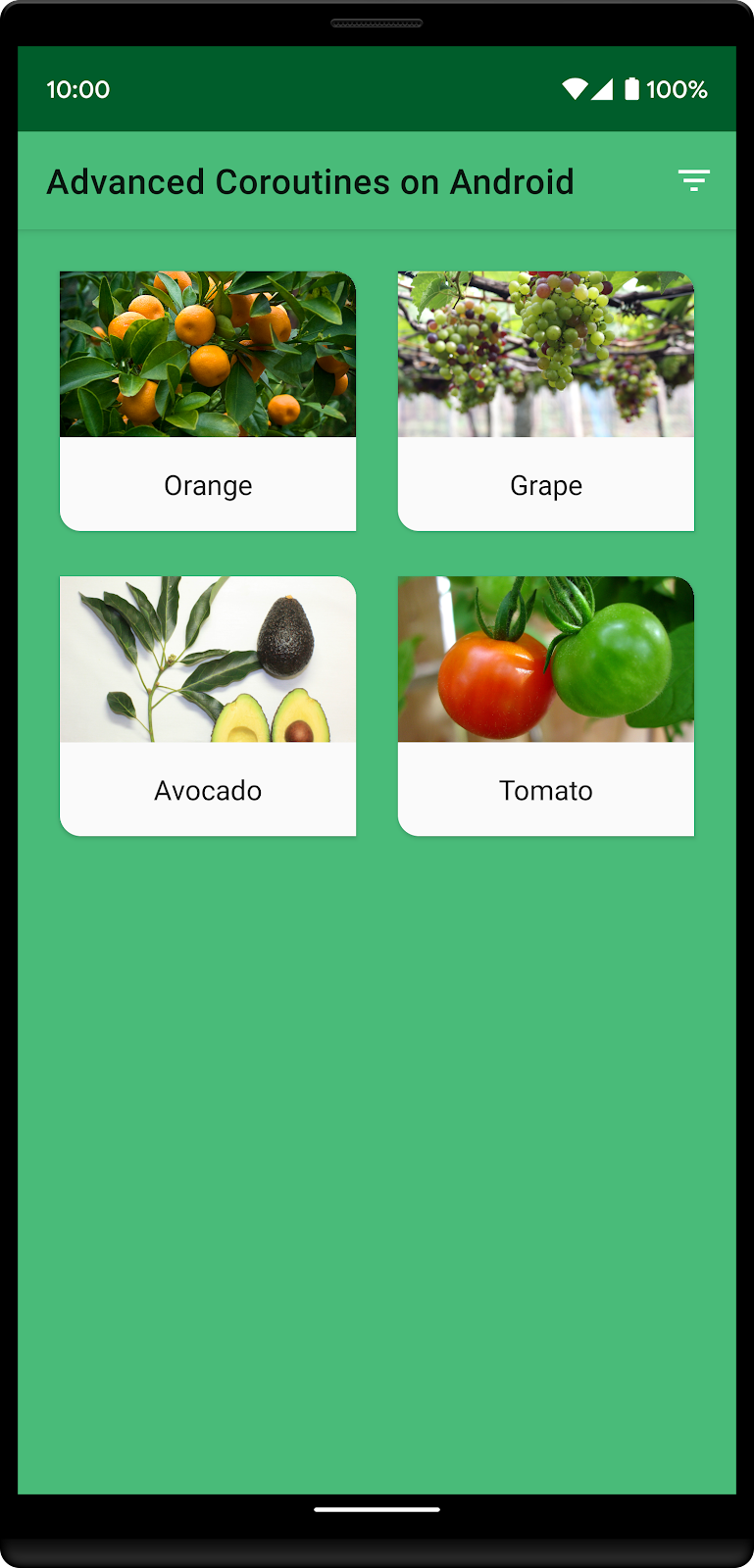
Let's start writing code to implement the custom sort.
5. Fetching sort order
We'll begin by writing a suspending function to fetch the custom sort order from the network and then cache it in memory.
Add the following to PlantRepository:
PlantRepository.kt
private var plantsListSortOrderCache =
CacheOnSuccess(onErrorFallback = { listOf<String>() }) {
plantService.customPlantSortOrder()
}
plantsListSortOrderCache is used as the in-memory cache for the custom sort order. It will fallback to an empty list if there's a network error, so that our app can still display data even if the sorting order isn't fetched.
This code uses the CacheOnSuccess utility class provided in the sunflower module to handle caching. By abstracting away the details of implementing caching like this, the application code can be more straightforward. Since CacheOnSuccess is already well tested, we don't need to write as many tests for our repository to ensure the correct behavior. It's a good idea to introduce similar higher-level abstractions in your code when using kotlinx-coroutines.
Now let's incorporate some logic to apply the sort to a list of plants.
Add the following to PlantRepository:
PlantRepository.kt
private fun List<Plant>.applySort(customSortOrder: List<String>): List<Plant> {
return sortedBy { plant ->
val positionForItem = customSortOrder.indexOf(plant.plantId).let { order ->
if (order > -1) order else Int.MAX_VALUE
}
ComparablePair(positionForItem, plant.name)
}
}
This extension function will rearrange the list, placing Plants that are in the customSortOrder at the front of the list.
6. Building logic with LiveData
Now that the sorting logic is in place, replace the code for plants and getPlantsWithGrowZone with the LiveData builder below:
PlantRepository.kt
val plants: LiveData<List<Plant>> = liveData<List<Plant>> {
val plantsLiveData = plantDao.getPlants()
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsLiveData.map {
plantList -> plantList.applySort(customSortOrder)
})
}
fun getPlantsWithGrowZone(growZone: GrowZone) = liveData {
val plantsGrowZoneLiveData = plantDao.getPlantsWithGrowZoneNumber(growZone.number)
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsGrowZoneLiveData.map { plantList ->
plantList.applySort(customSortOrder)
})
}
Now if you run the app, the custom sorted plant list should appear:
The LiveData builder allows us to calculate values asynchronously, as liveData is backed by coroutines. Here we have a suspend function to fetch a LiveData list of plants from the database, while also calling a suspend function to get the custom sort order. We then combine these two values to sort the list of plants and return the value, all within the builder.
The coroutine starts execution when it is observed, and is cancelled when the coroutine successfully finishes or if either the database or network call fails.
In the next step, we'll explore a variation of getPlantsWithGrowZone using a Transformation.
7. liveData: Modifying values
We'll now modify PlantRepository to implement a suspending transform as each value is processed, learning how to build complex async transforms in LiveData. As a prerequisite, let's create a version of the sorting algorithm that's safe to use on the main thread. We can use withContext to switch to another dispatcher just for the lambda and then resume on the dispatcher we started with.
Add the following to PlantRepository:
PlantRepository.kt
@AnyThread
suspend fun List<Plant>.applyMainSafeSort(customSortOrder: List<String>) =
withContext(defaultDispatcher) {
this@applyMainSafeSort.applySort(customSortOrder)
}
We can then use this new main-safe sort with the LiveData builder. Update the block to use a switchMap, which will let you point to a new LiveData every time a new value is received.
PlantRepository.kt
fun getPlantsWithGrowZone(growZone: GrowZone) =
plantDao.getPlantsWithGrowZoneNumber(growZone.number)
.switchMap { plantList ->
liveData {
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emit(plantList.applyMainSafeSort(customSortOrder))
}
}
Compared to the previous version, once the custom sort order is received from the network, it can then be used with the new main-safe applyMainSafeSort. This result is then emitted to the switchMap as the new value returned by getPlantsWithGrowZone.
Similar to plants LiveData above, the coroutine starts execution when it is observed and is terminated either on completion or if either the database or network call fails. The difference here is that it's safe to make the network call in the map since it is cached.
Now let's take a look at how this code is implemented with Flow, and compare the implementations.
8. Introducing Flow
We're going to build the same logic using Flow from kotlinx-coroutines. Before we do that, let's take a look at what a flow is and how you can incorporate it into your app.
A flow is an asynchronous version of a Sequence, a type of collection whose values are lazily produced. Just like a sequence, a flow produces each value on-demand whenever the value is needed, and flows can contain an infinite number of values.
So, why did Kotlin introduce a new Flow type, and how is it different than a regular sequence? The answer lies in the magic of asynchronicity. Flow includes full support for coroutines. That means you can build, transform, and consume a Flow using coroutines. You can also control concurrency, which means coordinating the execution of several coroutines declaratively with Flow.
This opens up a lot of exciting possibilities.
Flow can be used in a fully-reactive programming style. If you've used something like RxJava before, Flow provides similar functionality. Application logic can be expressed succinctly by transforming a flow with functional operators such as map, flatMapLatest, combine, and so on.
Flow also supports suspending functions on most operators. This lets you do sequential async tasks inside an operator like map. By using suspending operations inside of a flow, it often results in shorter and easier to read code than the equivalent code in a fully-reactive style.
In this codelab, we're going to explore using both approaches.
How does flow run
To get used to how Flow produces values on demand (or lazily), take a look at the following flow that emits the values (1, 2, 3) and prints before, during, and after each item is produced.
fun makeFlow() = flow {
println("sending first value")
emit(1)
println("first value collected, sending another value")
emit(2)
println("second value collected, sending a third value")
emit(3)
println("done")
}
scope.launch {
makeFlow().collect { value ->
println("got $value")
}
println("flow is completed")
}
If you run this, it produces this output:
sending first value got 1 first value collected, sending another value got 2 second value collected, sending a third value got 3 done flow is completed
You can see how execution bounces between the collect lambda and the flow builder. Every time the flow builder calls emit, it suspends until the element is completely processed. Then, when another value is requested from the flow, it resumes from where it left off until it calls emit again. When the flow builder completes, collect can now finish and the calling block prints "flow is completed."
The call to collect is very important. Flow uses suspending operators like collect instead of exposing an Iterator interface so that it always knows when it's being actively consumed. More importantly, it knows when the caller can't request any more values so it can cleanup resources.
When does a flow run
The Flow in the above example starts running when the collect operator runs. Creating a new Flow by calling the flow builder or other APIs does not cause any work to execute. The suspending operator collect is called a terminal operator in Flow. There are other suspending terminal operators such as toList, first and single shipped with kotlinx-coroutines, and you can build your own.
By default Flow will execute:
- Every time a terminal operator is applied (and each new invocation is independent from any previously started ones)
- Until the coroutine it is running in is cancelled
- When the last value has been fully processed, and another value has been requested
Because of these rules, a Flow can participate in structured concurrency, and it's safe to start long-running coroutines from a Flow. There's no chance a Flow will leak resources, since they're always cleaned up using coroutine cooperative cancellation rules when the caller is cancelled.
Lets modify the flow above to only look at the first two elements using the take operator, then collect it twice.
scope.launch {
val repeatableFlow = makeFlow().take(2) // we only care about the first two elements
println("first collection")
repeatableFlow.collect()
println("collecting again")
repeatableFlow.collect()
println("second collection completed")
}
Running this code, you'll see this output:
first collection sending first value first value collected, sending another value collecting again sending first value first value collected, sending another value second collection completed
The flow lambda starts from the top each time collect is called. This is important if the flow performed expensive work like making a network request. Also, since we applied the take(2) operator, the flow will only produce two values. It will not resume the flow lambda again after the second call to emit, so the line "second value collected..." will never print.
9. Going async with flow
OK, so Flow is lazy like a Sequence, but how is it also async? Let's take a look at an example of an async sequence–observing changes to a database.
In this example, we need to coordinate data produced on a database thread pool with observers that live on another thread such as the main or UI thread. And, since we'll be emitting results repeatedly as the data changes, this scenario is a natural fit for an async sequence pattern.
Imagine you're tasked with writing the Room integration for Flow. If you started with the existing suspend query support in Room, you might write something like this:
// This code is a simplified version of how Room implements flow
fun <T> createFlow(query: Query, tables: List<Tables>): Flow<T> = flow {
val changeTracker = tableChangeTracker(tables)
while(true) {
emit(suspendQuery(query))
changeTracker.suspendUntilChanged()
}
}
This code relies upon two imaginary suspending functions to generate a Flow:
suspendQuery– a main-safe function that runs a regularRoomsuspend querysuspendUntilChanged– a function that suspends the coroutine until one of the tables changes
When collected, the flow initially emits the first value of the query. Once that value is processed, the flow resumes and calls suspendUntilChanged, which will do as it says–suspend the flow until one of the tables changes. At this point, nothing is happening in the system until one of the tables changes and the flow resumes.
When the flow resumes, it makes another main-safe query, and emits the results. This process continues forever in an infinite loop.
Flow and structured concurrency
But wait–we don't want to leak work! The coroutine isn't very expensive by itself, but it repeatedly wakes itself up to perform a database query. That's a pretty expensive thing to leak.
Even though we've created an infinite loop, Flow helps us out by supporting structured concurrency.
The only way to consume values or iterate over a flow is to use a terminal operator. Because all terminal operators are suspend functions, the work is bound to the lifetime of the scope that calls them. When the scope is cancelled, the flow will automatically cancel itself using the regular coroutine cooperative cancellation rules. So, even though we've written an infinite loop in our flow builder, we can safely consume it without leaks due to structured concurrency.
10. Using Flow with Room
In this step, you learn how to use Flow with Room and wire it up to the UI.
This step is common for many usages of Flow. When used this way, the Flow from Room operates as an observable database query similar to a LiveData.
Update the Dao
To get started, open up PlantDao.kt, and add two new queries that return Flow<List<Plant>>:
PlantDao.kt
@Query("SELECT * from plants ORDER BY name")
fun getPlantsFlow(): Flow<List<Plant>>
@Query("SELECT * from plants WHERE growZoneNumber = :growZoneNumber ORDER BY name")
fun getPlantsWithGrowZoneNumberFlow(growZoneNumber: Int): Flow<List<Plant>>
Note that except for the return types, these functions are identical to the LiveData versions. But, we'll develop them side-by-side to compare them.
By specifying a Flow return type, Room executes the query with the following characteristics:
- Main-safety – Queries with a
Flowreturn type always run on theRoomexecutors, so they are always main-safe. You don't need to do anything in your code to make them run off the main thread. - Observes changes –
Roomautomatically observes changes and emits new values to the flow. - Async sequence –
Flowemits the entire query result on each change, and it won't introduce any buffers. If you return aFlow<List<T>>, the flow emits aList<T>that contains all rows from the query result. It will execute just like a sequence – emitting one query result at a time and suspending until it is asked for the next one. - Cancellable – When the scope that's collecting these flows is cancelled,
Roomcancels observing this query.
Put together, this makes Flow a great return type for observing the database from the UI layer.
Update the repository
To continue wiring up the new return values to the UI, open up PlantRepository.kt, and add the following code:
PlantRepository.kt
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
fun getPlantsWithGrowZoneFlow(growZoneNumber: GrowZone): Flow<List<Plant>> {
return plantDao.getPlantsWithGrowZoneNumberFlow(growZoneNumber.number)
}
For now, we're just passing the Flow values through to the caller. This is exactly the same as when we started this codelab with passing the LiveData through to the ViewModel.
Update the ViewModel
In PlantListViewModel.kt, let's start simple and just expose the plantsFlow. We'll come back and add the grow zone toggle to the flow version in the next few steps.
PlantListViewModel.kt
// add a new property to plantListViewModel
val plantsUsingFlow: LiveData<List<Plant>> = plantRepository.plantsFlow.asLiveData()
Again, we'll keep the LiveData version (val plants) around for comparison as we go.
Since we want to keep LiveData in the UI layer for this codelab, we'll use the asLiveData extension function to convert our Flow into a LiveData. Just like the LiveData builder, this adds a configurable timeout to the LiveData generated. This is nice because it keeps us from restarting our query every time the configuration changes (such as from device rotation).
Since flow offers main-safety and the ability to cancel, you can choose to pass the Flow all the way through to the UI layer without converting it to a LiveData. However, for this codelab we will stick to using LiveData in the UI layer.
Also in the ViewModel, add a cache update to the init block. This step is optional for now, but if you clear your cache and don't add this call, you will not see any data in the app.
PlantListViewModel.kt
init {
clearGrowZoneNumber() // keep this
// fetch the full plant list
launchDataLoad { plantRepository.tryUpdateRecentPlantsCache() }
}
Update the Fragment
Open PlantListFragment.kt, and change the subscribeUi function to point to our new plantsUsingFlow LiveData.
PlantListFragment.kt
private fun subscribeUi(adapter: PlantAdapter) {
viewModel.plantsUsingFlow.observe(viewLifecycleOwner) { plants ->
adapter.submitList(plants)
}
}
Run the app with Flow
If you run the app again, you should see that you're now loading the data using Flow! Since we haven't implemented the switchMap yet, the filter option doesn't do anything.
In the next step we'll take a look at transforming the data in a Flow.
11. Combining flows declaratively
In this step, you'll apply the sort order to plantsFlow. We'll do this using the declarative API of flow.
By using transforms like map, combine, or mapLatest, we can express how we would like to transform each element as it moves through the flow declaratively. It even lets us express concurrency declaratively, which can really simplify code. In this section, you'll see how you can use operators to tell Flow to launch two coroutines and combine their results declaratively.
To get started, open up PlantRepository.kt and define a new private flow called customSortFlow:
PlantRepository.kt
private val customSortFlow = flow { emit(plantsListSortOrderCache.getOrAwait()) }
This defines a Flow that, when collected, will call getOrAwait and emit the sort order.
Since this flow only emits a single value, you can also build it directly from the getOrAwait function using asFlow.
// Create a flow that calls a single function
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
This code creates a new Flow that calls getOrAwait and emits the result as its first and only value. It does this by referencing the getOrAwait method using :: and calling asFlow on the resulting Function object.
Both of these flows do the same thing, call getOrAwait and emit the result before completing.
Combine multiple flows declaratively
Now that we have two flows, customSortFlow and plantsFlow, let's combine them declaratively!
Add a combine operator to plantsFlow:
PlantRepository.kt
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
// When the result of customSortFlow is available,
// this will combine it with the latest value from
// the flow above. Thus, as long as both `plants`
// and `sortOrder` are have an initial value (their
// flow has emitted at least one value), any change
// to either `plants` or `sortOrder` will call
// `plants.applySort(sortOrder)`.
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
The combine operator combines two flows together. Both flows will run in their own coroutine, then whenever either flow produces a new value the transformation will be called with the latest value from either flow.
By using combine, we can combine the cached network lookup with our database query. Both of them will run on different coroutines concurrently. That means that while Room starts the network request, Retrofit can start the network query. Then, as soon as a result is available for both flows, it will call the combine lambda where we apply the loaded sort order to the loaded plants.
To explore how the combine operator works, modify customSortFlow to emit twice with a substantial delay in onStart like this:
// Create a flow that calls a single function
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
.onStart {
emit(listOf())
delay(1500)
}
The transform onStart will happen when an observer listens before other operators, and it can emit placeholder values. So here we're emitting an empty list, delaying calling getOrAwait by 1500ms, then continuing the original flow. If you run the app now, you'll see that the Room database query returns right away, combining with the empty list (which means it'll sort alphabetically). Then around 1500ms later, it applies the custom sort.
Before continuing with the codelab, remove the onStart transform from the customSortFlow.
Flow and main-safety
Flow can call main-safe functions, like we're doing here, and it will preserve the normal main-safety guarantees of coroutines. Both Room and Retrofit will give us main-safety, and we don't need to do anything else to make network requests or database queries with Flow.
This flow uses the following threads already:
plantService.customPlantSortOrderruns on a Retrofit thread (it callsCall.enqueue)getPlantsFlowwill run queries on a Room ExecutorapplySortwill run on the collecting dispatcher (in this caseDispatchers.Main)
So if all we were doing was calling suspend functions in Retrofit and using Room flows, we wouldn't need to complicate this code with main-safety concerns.
However, as our data set grows in size, the call to applySort may become slow enough to block the main thread. Flow offers a declarative API called flowOn to control which thread the flow runs on.
Add flowOn to the plantsFlow like this:
PlantRepository.kt
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
.flowOn(defaultDispatcher)
.conflate()
Calling flowOn has two important effects on how the code executes:
- Launch a new coroutine on the
defaultDispatcher(in this case,Dispatchers.Default) to run and collect the flow before the call toflowOn. - Introduces a buffer to send results from the new coroutine to later calls.
- Emit the values from that buffer into the
FlowafterflowOn. In this case, that'sasLiveDatain theViewModel.
This is very similar to how withContext works to switch dispatchers, but it does introduce a buffer in the middle of our transforms that changes how the flow works. The coroutine launched by flowOn is allowed to produce results faster than the caller consumes them, and it will buffer a large number of them by default.
In this case, we plan on sending the results to the UI, so we would only ever care about the most recent result. That's what the conflate operator does–it modifies the buffer of flowOn to store only the last result. If another result comes in before the previous one is read, it gets overwritten.
Run the app
If you run the app again, you should see that you're now loading the data and applying the custom sort order using Flow! Since we haven't implemented the switchMap yet, the filter option doesn't do anything.
In the next step we'll take a look at another way to provide main safety using flow.
12. Switching between two flows
To finish up the flow version of this API, open up PlantListViewModel.kt, where we will switch between the flows based on GrowZone like we do in the LiveData version.
Add the following code below the plants liveData:
PlantListViewModel.kt
private val growZoneFlow = MutableStateFlow<GrowZone>(NoGrowZone)
val plantsUsingFlow: LiveData<List<Plant>> = growZoneFlow.flatMapLatest { growZone ->
if (growZone == NoGrowZone) {
plantRepository.plantsFlow
} else {
plantRepository.getPlantsWithGrowZoneFlow(growZone)
}
}.asLiveData()
This pattern shows how to integrate events (grow zone changing) into a flow. It does exactly the same thing as the LiveData.switchMap version–switching between two data sources based on an event.
Stepping through the code
PlantListViewModel.kt
private val growZoneFlow = MutableStateFlow<GrowZone>(NoGrowZone)
This defines a new MutableStateFlow with an initial value of NoGrowZone. This is a special kind of Flow value holder that holds only the last value it was given. It's a thread-safe concurrency primitive, so you can write to it from multiple threads at the same time (and whichever is considered "last" will win).
You can also subscribe to get updates to the current value. Overall, it has similar behavior to a LiveData–it just holds the last value and lets you observe changes to it.
PlantListViewModel.kt
val plantsUsingFlow: LiveData<List<Plant>> = growZoneFlow.flatMapLatest { growZone ->
StateFlow is also a regular Flow, so you can use all the operators as you normally would.
Here we use the flatMapLatest operator which is exactly the same as switchMap from LiveData. Whenever the growZone changes its value, this lambda will be applied and it must return a Flow. Then, the returned Flow will be used as the Flow for all downstream operators.
Basically, this lets us switch between different flows based on the value of growZone.
PlantListViewModel.kt
if (growZone == NoGrowZone) {
plantRepository.plantsFlow
} else {
plantRepository.getPlantsWithGrowZoneFlow(growZone)
}
Inside the flatMapLatest, we switch based on the growZone. This code is pretty much the same as the LiveData.switchMap version, with the only difference being that it returns Flows instead of LiveDatas.
PlantListViewModel.kt
}.asLiveData()
And finally, we convert the Flow into a LiveData, since our Fragment expects us to expose a LiveData from the ViewModel.
Change a value of StateFlow
To let the app know about the filter change, we can set MutableStateFlow.value. It's an easy way to communicate an event into a coroutine like we're doing here.
PlantListViewModel.kt
fun setGrowZoneNumber(num: Int) {
growZone.value = GrowZone(num)
growZoneFlow.value = GrowZone(num)
launchDataLoad {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(GrowZone(num)) }
}
fun clearGrowZoneNumber() {
growZone.value = NoGrowZone
growZoneFlow.value = NoGrowZone
launchDataLoad {
plantRepository.tryUpdateRecentPlantsCache()
}
}
Run the app again
If you run the app again, the filter now works for both the LiveData version and the Flow version!
In the next step, we'll apply the custom sort to getPlantsWithGrowZoneFlow.
13. Mixing styles with flow
One of the most exciting features of Flow is its first-class support for suspend functions. The flow builder and almost every transform exposes a suspend operator that can call any suspending functions. As a result, main-safety for network and database calls as well as orchestrating multiple async operations can be done using calls to regular suspend functions from inside a flow.
In effect, this allows you to naturally mix declarative transforms with imperative code. As you'll see in this example, inside of a regular map operator you can orchestrate multiple async operations without applying any extra transformations. In a lot of places, this can lead to substantially simpler code than that of a fully-declarative approach.
Using suspend functions to orchestrate async work
To wrap up our exploration of Flow, we'll apply the custom sort using suspend operators.
Open up PlantRepository.kt and add a map transform to getPlantsWithGrowZoneNumberFlow.
PlantRepository.kt
fun getPlantsWithGrowZoneFlow(growZone: GrowZone): Flow<List<Plant>> {
return plantDao.getPlantsWithGrowZoneNumberFlow(growZone.number)
.map { plantList ->
val sortOrderFromNetwork = plantsListSortOrderCache.getOrAwait()
val nextValue = plantList.applyMainSafeSort(sortOrderFromNetwork)
nextValue
}
}
By relying on regular suspend functions to handle the async work, this map operation is main-safe even though it combines two async operations.
As each result from the database is returned, we'll get the cached sort order–and if it's not ready yet, it will wait on the async network request. Then once we have the sort order, it's safe to call applyMainSafeSort, which will run the sort on the default dispatcher.
This code is now entirely main-safe by deferring the main safety concerns to regular suspend functions. It's quite a bit simpler than the same transformation implemented in plantsFlow.
However, it is worth noting that it will execute a bit differently. The cached value will be fetched every single time the database emits a new value. This is OK because we're caching it correctly in plantsListSortOrderCache, but if that started a new network request this implementation would make a lot of unnecessary network requests. In addition, in the .combine version, the network request and the database query run concurrently, while in this version they run in sequence.
Due to these differences, there is not a clear rule to structure this code. In many cases, it's fine to use suspending transformations like we're doing here, which makes all async operations sequential. However, in other cases, it's better to use operators to control concurrency and provide main-safety.
14. Controlling concurrency with flow
You're almost there! As one final (optional) step, let's move the network requests into a flow-based coroutine.
By doing so, we'll remove the logic for making the network calls from the handlers called by onClick and drive them from the growZone. This helps us create a single source of truth and avoid code duplication–there's no way any code can change the filter without refreshing the cache.
Open up PlantListViewModel.kt, and add this to the init block:
PlantListViewModel.kt
init {
clearGrowZoneNumber()
growZone.mapLatest { growZone ->
_spinner.value = true
if (growZone == NoGrowZone) {
plantRepository.tryUpdateRecentPlantsCache()
} else {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(growZone)
}
}
.onEach { _spinner.value = false }
.catch { throwable -> _snackbar.value = throwable.message }
.launchIn(viewModelScope)
}
This code will launch a new coroutine to observe the values sent to growZoneChannel. You can comment out the network calls in the methods below now as they're only needed for the LiveData version.
PlantListViewModel.kt
fun setGrowZoneNumber(num: Int) {
growZone.value = GrowZone(num)
growZoneFlow.value = GrowZone(num)
// launchDataLoad {
// plantRepository.tryUpdateRecentPlantsForGrowZoneCache(GrowZone(num))
// }
}
fun clearGrowZoneNumber() {
growZone.value = NoGrowZone
growZoneFlow.value = NoGrowZone
// launchDataLoad {
// plantRepository.tryUpdateRecentPlantsCache()
// }
}
Run the app again
If you run the app again now, you'll see that the network refresh is now controlled by the growZone! We've improved the code substantially, as more ways to change the filter come in the channel acts as a single source of truth for which filter is active. That way the network request and the current filter can never get out of sync.
Stepping through the code
Let's step through all the new functions used one at a time, starting from the outside:
PlantListViewModel.kt
growZone
// ...
.launchIn(viewModelScope)
This time, we use the launchIn operator to collect the flow inside our ViewModel.
The operator launchIn creates a new coroutine and collects every value from the flow. It'll launch in the CoroutineScope provided–in this case, the viewModelScope. This is great because it means when this ViewModel gets cleared, the collection will be cancelled.
Without providing any other operators, this doesn't do very much–but since Flow provides suspending lambdas in all of its operators it's easy to make async actions based on every value.
PlantListViewModel.kt
.mapLatest { growZone ->
_spinner.value = true
if (growZone == NoGrowZone) {
plantRepository.tryUpdateRecentPlantsCache()
} else {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(growZone)
}
}
This is where the magic lies–mapLatest will apply this map function for each value. However, unlike regular map, it'll launch a new coroutine for each call to the map transform. Then, if a new value is emitted by the growZoneChannel before the previous coroutine completes, it'll cancel it before starting a new one.
We can use mapLatest to control concurrency for us. Instead of building cancel/restart logic ourselves, the flow transform can take care of it. This code saves a lot of code and complexity compared to writing the same cancellation logic by hand.
Cancellation of a Flow follows the normal cooperative cancellation rules of coroutines.
PlantListViewModel.kt
.onEach { _spinner.value = false }
.catch { throwable -> _snackbar.value = throwable.message }
onEach will be called every time the flow above it emits a value. Here we're using it to reset the spinner after processing is complete.
The catch operator will capture any exceptions thrown above it in the flow. It can emit a new value to the flow like an error state, rethrow the exception back into the flow, or perform work like we're doing here.
When there's an error we're just telling our _snackbar to display the error message.
Wrapping up
This step showed you how you can control concurrency using Flow, as well as consume Flows inside a ViewModel without depending on a UI observer.
As a challenge step, try to define a function to encapsulate the data loading of this flow with the following signature:
fun <T> loadDataFor(source: StateFlow<T>, block: suspend (T) -> Unit) {